
Our website uses cookies to enhance your browsing experience.
The analyzer detected that a potentially dangerous regular expression is used for processing data from external source. This can make an application vulnerable to a ReDoS attack.
ReDoS is a denial of service attack caused by a vulnerable regular expression. The aim of an attacker is to pass a tainted string to a regular expression. The string is designed in such a way that evaluating it will require the maximum amount of time.
A regular expression is vulnerable if it meets the following conditions:
Therefore, when receiving a warning of this diagnostic rule, you should check a regular expression for presence of subexpressions of the following forms:
Here 'a', 'b', 'c' can be:
It is also important that after these subexpressions there should be at least one subexpression not marked with quantifiers '?' or '*'. For example: '(x+)+y', '(x+)+$', '(x+)+(...)', ' (x+)+[...]'.
Let's analyze this issue on the example of '(x+)+y'. In this expression, the 'x+' pattern can match any number of 'x' characters. The string that matches the '(x+)+y' pattern consists of any number of substrings matched with 'x+'. As a result, there is a large number of options for matching the same string with a regular expression.
You can see several options for matching the 'xxxx' string with the '(x+)+y' template in the table below:

Every time a regular expression fails to find the 'y' character at the end of the string, it starts checking the next option. Only after checking all of them, the regular expression gives the answer – no matches were found. However, this process can be executed for a catastrophically long time, depending on the length of the substring corresponding to the vulnerable pattern.
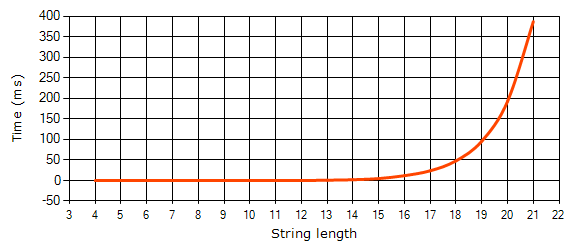
The graph below shows how the (x+)+y regular expression's calculation time depends on the number of characters in the input strings of the 'xx....xx' form:
Look at the code example:
Regex _datePattern = new Regex(@"^(-?\d+)*$");
public bool IsDateCorrect(string date)
{
if (_datePattern.IsMatch(date))
....
}In this example, the date is checked with a regular expression. If the date is correct, the regular expression works as expected. The situation changes if the application receives the following string as the date:
3333333333333333333333333333333333333333333333333333333333333 Hello ReDoS!In this case, processing with a regular expression will take a long time. Receiving several requests with similar data may create a heavy load on the application.
A possible solution is to limit the time a regular expression spends on processing the input string:
Regex _datePattern = new Regex(@"^(-?\d+)*$",
RegexOptions.None,
TimeSpan.FromMilliseconds(10));Look at another example. The '(\d|[0-9]?)' subexpression was intentionally added to the regular expression to show the essence of the problem.
Regex _listPattern = new Regex(@"^((\d|[0-9]?)(,\s|\.))+$(?<=\.)");
public void ProcessItems(string path)
{
using (var reader = new StreamReader(path))
{
while (!reader.EndOfStream)
{
string line = reader.ReadLine();
if (line != null && _listPattern.IsMatch(line))
....
}
}
}Here, the data is read from the file. A regular expression checks the data for compliance with the following pattern: the string should be a list, each element of which is a digit or an empty string. The correct input may look like this:
3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4.When processing such data, the regular expression works in normal time. However, if we pass the same string but without the dot at the end, the application will take much more time to process it.
The regular expression uses the '\d' and '[0-9]?' subexpressions, which can be matched with the same values. Note that the '? ' quantifier is applied to the second subexpression and the '+' quantifier is applied to the '((\d|[0-9]?)(,\s|\.))' parent subexpression. This leads to a large number of possible matches in the string. If we remove at least one of these quantifiers, the ReDoS attack won't happen.
In this example, to eliminate the ReDoS vulnerability, it is enough to remove the unnecessary matches:
Regex _listPattern = new Regex(@"^([0-9]?(,\s|\.))+$(?<=\.)");You can read more about ReDoS vulnerabilities on the OWASP website.
There are several options. Let's inspect them using the '^(-?\d+)*$' regular expression as an example.
Option 1. Add a limit on the processing time a regular expression spends on a string. This can be done by setting the 'matchTimeout' parameter when you create the 'Regex' object or when you call a static method:
RegexOptions options = RegexOptions.None;
TimeSpan timeout = TimeSpan.FromMilliseconds(10);
Regex datePattern = new Regex(@"^(-?\d+)*$", options, timeout);
Regex.IsMatch(date, @"^(-?\d+)*$", options, timeout);Option 2. Use atomic groups '(?>...)'. Atomic groups disable the search for all possible combinations of characters corresponding to a subexpression, being limited to only one:
Regex datePattern = new Regex(@"^(?>-?\d+)*$");Option 3. Rewrite the regular expression by removing the dangerous pattern. Suppose that the '^(-?\d+)*$' expression is designed to search for a date of the '27-09-2022' form. In this case it can be replaced with a more reliable analogue:
Regex datePattern = new Regex (@"^(\d{2}-\d{2}-\d{4})$");Here any substring is matched with no more than one subexpression due to the mandatory check of the '-' character between the '\d{...}' templates.
This diagnostic is classified as:
You can look at examples of errors detected by the V5626 diagnostic. |
Was this page helpful?