
Our website uses cookies to enhance your browsing experience.

Fun is fun, but extra caution never hurts anyone. What if it's not completely clear why some of the tips are terrible? Here you can find the relevant explanations.

Did you come here by accident and do not understand what's going on? Let me explain. These are additional comments to the article "50 terrible coding tips for a C++ developer".
In my opinion, it would be overwhelming to comment on each tip, and I decided to go through only the most controversial ones. If you came here and did not find the explanation that interests you, let me know and I'll update the article.
Meet the extended version of the article: "60 terrible tips for a C++ developer". It provides not only some additional terrible tips but explanations for each of them.
A real programmer only programs in C++!
There's nothing wrong with writing code in C++. The world has many projects written in C++. Well, for example, look at the list of apps from the home page of Bjarne Stroustrup.
Here is a list of systems, applications, and libraries that are completely or mostly written in C++. Naturally, this is not intended to be a complete list. In fact, I couldn't list a 1000th of all major C++ programs if I tried, and this list holds maybe 1000th of the ones I have heard of. It is a list of systems, applications, and libraries that a reader might have some familiarity with, that might give a novice an idea what is being done with C++, or that I simply thought "cool".
It's a problem when people start using this language just because it's "cool" or when it's the only language the team is familiar with.
The variety of programming languages reflects the variety of tasks facing software developers. Different languages help developers solve different classes of problems effectively.
The C++ language claims to be a versatile programming language. However, versatility doesn't guarantee that specific applications will be implemented quickly and easily. There may be languages that are a better fit for projects than others. Appropriate programming language can help implement a project without significant investments of time and effort.
But there's nothing wrong with developing a small additional utility in C++, although it would be more efficient for a team to use another language for this. The costs of learning a new programming language may exceed the benefits of using it.
The situation is different when a team needs to create a new, potentially large project. In this case, the team needs to discuss a few questions before choosing any programming language. Will the well-known C++ be effective for the project maintenance? Wouldn't it be better to choose another programming language for this project?
If the answer is yes, it's clearly more efficient to use another language. Then probably it's better for the team to spend time learning this language. In the future, this can significantly reduce the cost of the project development and maintenance. Or maybe the project should be assigned to another team that already uses a more relevant language in such case.
Use nested macros everywhere. It's a good way to shorten code. You will free up hard drive space. Your teammates will have lots of fun when debugging.
You can read my thoughts on this topic in the following article: "Macro evil in C++ code [RU]".
Use numbers in programming. This way code of your program will look smarter and more impressive. Here's code line example: qw = ty / 65 - 29 * s; Looks hardcore, right?
If the program code contains numbers and their purpose is unknown and unclear, they are called magic numbers. Magic numbers are an example of bad programming practice. They make the code confusing to colleagues and even to the author himself over time.
It's much better to replace magic numbers with named constants and enumerations. However, this does not mean that each constant must be named somehow. Firstly, there are 0 or 1 constants, and their usage is obvious. Secondly, programs where mathematical calculations take place might be affected by the attempt to name each numeric constant. In this case, use comments to explain the formulas.
Unfortunately, one chapter of the article doesn't allow me to describe many ways that help write clean, beautiful code. Therefore, I recommend the readers check out such a thorough work as "Code Complete" by S. McConnell (ISBN 978-0-7356-1967-8).
Moreover, there's a great discussion on Stack Overflow: What is a magic number, and why is it bad?
All old books recommend using integer type variables to store array sizes and to construct loops. Let's keep it up! No reason to break with tradition.
On many common platforms where the C++ language was used, an array could not in practice contain more than INT_MAX elements.
For example, a 32-bit Windows program has 2 GB memory limit (in reality, even less). So the 32-bit int type was more than enough to store the array sizes or to index arrays.
At the time, book authors and programmers confidently used int type counters in loops. And everything was fine.
However, in fact, the size of such types as int, unsigned, and even long may not be enough. At this point, programmers who use Linux may wonder: why is the size of long not enough? And here's the reason. For example, to build an app for the Windows x64 platform, Visual C++ uses LLP64 data model. In this model, the long type remained 32-bit.
And then what types should you use? Memsize-types such as ptrdiff_t, size_t, intptr_t, uintptr_t are safe to store indexes or array sizes.
Let's look at the simple code example. When a large array is processed in a 64-bit program, the use of 32-bit counter leads to the error:
std::vector<char> &bigArray = get();
size_t n = bigArray.size();
for (int i = 0; i < n; i++)
bigArray[i] = 0;If the container contains more than INT_MAX elements, the int signed variable will overflow. This is undefined behavior. Moreover, how the undefined behavior will manifest itself is not as easy to predict as it may seem. I reviewed one interesting case in the following article: "Undefined behavior is closer than you think."
Here's one of the examples of the correct code:
size_t n = bigArray.size();
for (size_t i = 0; i < n; i++)
bigArray[i] = 0;This code example would be even more accurate:
std::vector<char>::size_type n = bigArray.size();
for (std::vector<char>::size_type i = 0; i < n; i++)
bigArray[i] = 0;I agree, this example is a bit long. And it may be tempting to use automatic type inference. Unfortunately, you can get an incorrect code of the following type again:
auto n = bigArray.size();
for (auto i = 0; i < n; i++) // :-(
bigArray[i] = 0;The n variable will have the correct type, but the counter i won't. The 0 constant has the int type, which means that the i variable will also have the int type. And we're back to where we started.
So how to sort through the elements correctly and at the same time write a short code? First, you can use iterators:
for (auto it = bigArray.begin(); it != bigArray.end(); ++it)
*it = 0;Secondly, you can use range-based for loop:
for (auto &a : bigArray)
a = 0;A reader can say that everything is okay, but it's not applicable to their programs. All arrays created in their code, in principle, cannot be large, and it's still possible to use the int and unsigned variables. The reasoning is incorrect for two reasons.
The first reason. This approach is potentially dangerous for the program's future. The fact that the program doesn't work with large arrays now does not mean that it'll always be so. Another scenario: the code can be reused in another application, where the processing of large arrays is common routine. For example, one of the reasons why the Ariane 5 rocket fell was just the reuse of code written for the Ariane 4 rocket. The code was not designed for the new values of "horizontal speed". Here's the article: "A space error: 370.000.000 $ for an integer overflow"
The second reason. The use of mixed arithmetic may lead to problems even if you work with small arrays. Let's look at code that works in the 32-bit version of the program, but not in the 64-bit one:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); // Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); // Access violation on 64-bit platformLet's see how the ptr + (A + B) expression is calculated:
The result of it depends on the pointer size on the particular architecture. If the addition takes place in the 32-bit program, the given expression will be an equivalent of ptr - 1 and we'll successfully print number 3. In the 64-bit program, the 0xFFFFFFFFu value will be added fairly to the pointer. The pointer will leave the array bounds. We'll face problems while getting access to the item of this pointer.
If you find this topic interesting and want to gain a better understanding of it, I recommend the following materials:
A tip for those who develop libraries: when in doubt, immediately terminate the program with the abort or terminate function.
Sometimes programs have very simple error handling — they shutdown. If a program couldn't do something, for example, open a file or allocate memory — the abort, exit or terminate function is immediately called. For some utilities and simple programs, this is acceptable behavior. And actually, it's up to the authors to decide how their programs would handle errors.
However, this approach is unacceptable if you are developing library code. You don't know what applications will use the code. The library code should return an error status or generate an exception. And it is up to the user code to decide how to handle the error.
For example, a client of a graphic editor won't be happy if a library designed to print an image shuts down the application without saving the work results.
What if an embedded developer wants to use the library? Such manuals for embedded system developers as MISRA and AUTOSAR generally prohibit to call the abort and exit functions (MISRA-C-21.8, MISRA-CPP-18.0.3, AUTOSAR-M18.0.3).
If something doesn't work, most likely the compiler is acting up. Try swapping some variables and code lines.
Any skilled programmer understands that this tip sounds absurd. In practice, however, it's not so rare for a programmer to blame the compiler for the incorrect operation of their program.
Of course, errors may occur in compilers, and you can encounter them. However, in 99% of cases, when someone says that "the compiler is buggy", they are wrong, and it's their code that is incorrect.
Most often, developers either don't understand some subtleties of the C++ language or have encountered undefined behavior. Let's look at a couple of such examples.
The first story begins from a discussion [RU] that took place on the linux.org.ru forum.
One developer left a post complaining about GCC's bug. However, as it turned out, it was incorrect code that led to undefined behavior. Let's look at this case.
Note. In the original discussion, the s variable has the const char *s type. At the same time, on the author's target platform, the char type is unsigned. Therefore, for clarity, I use a pointer of the const unsigned char * type in the code.
int foo(const unsigned char *s)
{
int r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return r & 0x7fffffff;
}The compiler does not generate code for the bitwise AND (&) operator. As a result, the function returns negative values. However, this is not the developer's intent and shouldn't be happening.
The developer believes that the compiler is to blame. But actually, it's not the compiler's fault here — the code is incorrect. The function doesn't work as intended because the undefined behavior occurs.
The compiler sees that the r variable is used to calculate and store a sum. It assumes that the r variable cannot overflow. That would be considered undefined behavior, which the compiler should not analyze and take into account whatsoever. So, the compiler assumes that the r variable cannot store a negative value after the loop terminates. Therefore, the r & 0x7fffffff operation, which sets off the sign bit, is unnecessary. So the compiler simply returns the value of the r variable from the function.
It's an interesting story when a programmer hastened to complain about the compiler. Based on this case, we added the V1026 diagnostic to the PVS-Studio analyzer. This diagnostic helps to identify such defects in the code.
To fix the code, you should simply use an unsigned variable to calculate the hash value.
int foo(const unsigned char *s)
{
unsigned r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return (int)(r & 0x7fffffff);
}The second story was previously described here: "The compiler is to blame for everything." Once the PVS-Studio analyzer issued a warning for the following code:
TprintPrefs::TprintPrefs(IffdshowBase *Ideci,
const TfontSettings *IfontSettings)
{
memset(this, 0, sizeof(this)); // This doesn't seem to
// help after optimization.
dx = dy = 0;
isOSD = false;
xpos = ypos = 0;
align = 0;
linespacing = 0;
sizeDx = 0;
sizeDy = 0;
...
}The analyzer is right, and the author of code is not.
According to the comment, when optimization is enabled, the compiler is acting up and does not fill the structure fields with zeroes.
Having scolded the compiler, the programmer leaves an accusing comment and goes on to write a code which zeroes each class member separately. Sadly, but most likely, the programmer will be absolutely sure they have encountered a bug in the compiler. But, in fact, there is a mistake due to the lack of attention.
Pay attention to the third argument of the memset function. The sizeof operator calculates the pointer size, and not the size of the class. As a result, only part of the class is filled with zeroes. In the mode without optimizations, apparently, all fields were always set to zero and it seemed that the memset function worked correctly.
The correct calculation of the class size should look like this:
memset(this, 0, sizeof(*this));However, even the fixed version of the code cannot be called correct and safe. It stays that way as long as the class is trivially copyable. Everything can crash, for example, if you add some virtual function or a field of a non-trivially copied type to the class.
Don't write like that. I gave this example only because previously described nuances pale in comparison to the error of the structure size calculation.
This is how legends about glitchy compilers and brave programmers fighting them are born.
Conclusion. Do not hasten to blame the compiler if your code doesn't work. And do not try to make your program work by using various code modifications in the hope of "bypassing the compiler bug".
What you can do before blaming the compiler:
There's no time to explain — immediately use the command line arguments. For example: char buf[100]; strcpy(buf, argv[1]);. Checks are for those who don't feel too confident about their own or their teammates' coding skills.
It's not just that a buffer overflow may occur. Data processing without prior checks opens a Pandora's box full of vulnerabilities.
The issue of the use of unchecked data is a big topic. It goes beyond this overview article. To understand this topic, you can start with the following material:
Undefined behavior is just a scary bedtime story. Undefined behavior doesn't exist in real life. If the program works as you expected, it doesn't contain bugs. And there's nothing to discuss here, that's that.
Enjoy! :)
Feel free to use the == operator to compare floating point numbers. If there is such an operator, you need to use it.
Floating-point comparison can be tricky. You should keep that in mind. You can read about subtleties of comparison in the PVS-Studio documentation: V550 - Suspicious precise comparison.
memmove is superfluous function. Always and everywhere use memcpy.
The role of memmove and memcpy is the same. However, there is an important difference. If the memory areas passed through the first two parameters partially overlap, the memmove function guarantees the correctness of copy result. In the case of memcpy, the behavior is undefined.
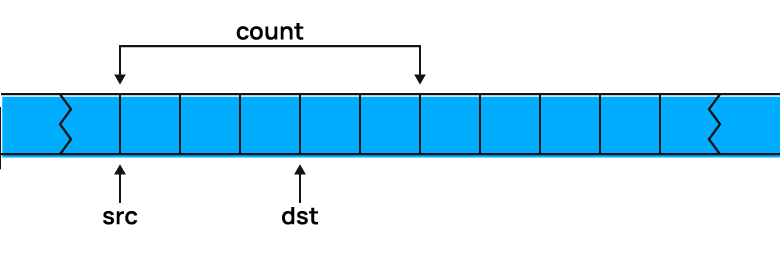
Suppose you need to move five bytes of memory by three bytes, as shown in the picture. Then:
See also the discussion on Stack Overflow "memcpy() vs memmove()".
Since the functions behave so differently, what was the reason to joke about this topic? Turns out that authors of many projects inattentively read the documentation about these functions. Inattentive programmers were saved by the fact that in older versions of glibc, the memcpy function was an alias for memmove. Here's a note on this topic: Glibc change exposing bugs.
And this is how Linux manual page describes it:
Failure to observe the requirement that the memory areas do not overlap has been the source of significant bugs. (POSIX and the C standards are explicit that employing memcpy() with overlapping areas produces undefined behavior.) Most notably, in glibc 2.13 a performance optimization of memcpy() on some platforms (including x86-64) included changing the order in which bytes were copied from src to dest.
This change revealed breakages in a number of applications that performed copying with overlapping areas. Under the previous implementation, the order in which the bytes were copied had fortuitously hidden the bug, which was revealed when the copying order was reversed. In glibc 2.14, a versioned symbol was added so that old binaries (i.e., those linked against glibc versions earlier than 2.14) employed a memcpy() implementation that safely handles the overlapping buffers case (by providing an "older" memcpy() implementation that was aliased to memmove(3)).
The size of int is always 4 bytes. Feel free to use this number. The number 4 looks much more elegant than an awkward expression with the sizeof operator.
The size of an int can differ significantly. On many popular platforms, the int size is really 4 bytes. But many – it doesn't mean all! There are systems with different data models. int can contain 8 bytes, 2 bytes, and even 1 byte!
Formally, here's what can be said about the int size:
1 == sizeof(char) <=
sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)Additional links:
It makes no sense to check if memory was allocated. Modern computers have a great amount of memory. And if there is not enough memory to complete operations, there is no need for the program to continue working. Let the program crash. There's nothing more you can do anyway.
If the memory runs out, a game can crush. It's acceptable sometimes. The crash is unpleasant, but it doesn't feel like the end of the world. Well, unless you are not participating in the gaming championship at this moment :).
But suppose a situation: you spent half a day doing a project in a CAD system. Suddenly, there is not enough memory for the next operation — the application crashes. It's much more unpleasant. It's one thing if an application can't perform an operation, and it's quite another if it crashes without a warning. CAD and similar systems should continue working. At least, to give the opportunity to save the result.
There are several cases when it's unacceptable to write code that crashes if there isn't enough memory:
This topic largely overlaps with my article "Four reasons to check what the malloc function returned". I recommend reading it. Not everything is as simple and obvious as it seems at first glance with memory allocation errors.
Extend the std namespace with various additional functions and classes. After all, for you, these functions and classes are standard and basic.
Despite that such a program is successfully compiled and executed, modification of the std namespace can lead to undefined behavior of the program. Read more: V1061.
Use as few curly brackets and line breaks as possible. Try to write conditional constructs in one line. This will reduce the code size and make the code compile faster.
The code will be shorter — it's undeniable. It's also undeniable that the code will contain more errors.
"Shortened code" is harder to read. This means that typos are more likely not to be noticed by the author of the code, nor by colleagues during code review. Do you want proof? Easy!
A guy sent an email to our support saying that the PVS-Studio analyzer was producing strange false positives for the condition. And I attached this picture:
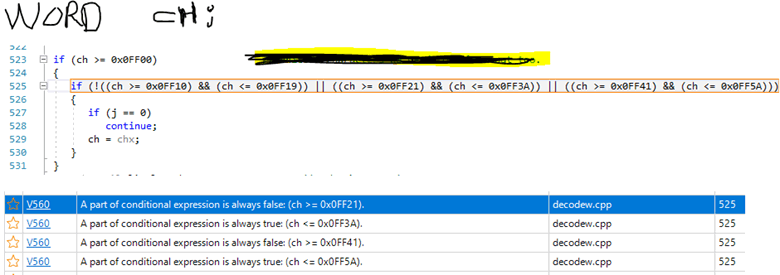
Can you see the bug? Probably not. Do you know why? The answer — we have a big complex expression written in one line. It's difficult for a person to read and understand this code. I bet you did not try to find the bug, but immediately continued reading the article :).
But the analyzer wasn't too lazy to bother trying. It correctly indicated an anomaly: some of the subexpressions are always true or false. Let's refactor the code:
if (!((ch >= 0x0FF10) && (ch <= 0x0FF19)) ||
((ch >= 0x0FF21) && (ch <= 0x0FF3A)) ||
((ch >= 0x0FF41) && (ch <= 0x0FF5A)))Now it's much easier to notice that the logical NOT (!) operator is applied only to the first subexpression. We just need to write additional parentheses. The more detailed story about this bug is here: "How PVS-Studio proved to be more attentive than three and a half programmers."
In our articles, we recommend formatting complex code as a table. Table-style formatting does not guarantee the absence of typos, but it makes them easier and faster to notice. Check out the N13 chapter in the soon-to-be-a-book: "The main question of programming, refactoring and all that."
Never test anything. And don't write tests. Your code is perfect, what's there to test? It's not for nothing that you are real C++ programmers.
I think the reader understands the irony, and no one seriously wonders why this tip is terrible. But there is an interesting point here. By agreeing that programmers make mistakes, you most likely think that this applies to you to a lesser degree. After all, you are an expert, and on average you understand better than others how to program and test.

We all have a condition of cognitive bias — "illusory superiority". Moreover, in my life experience, programmers are more susceptible to it :). Here's an interesting article on this topic: The Problem With 'Above Average Programmers'.
And don't use static analyzers. These are tools for students and losers.
In fact, it's the other way around. First, professional developers use static analyzers to improve the quality of their software projects. They value static analysis because it allows to find bugs and zero-day vulnerabilities at early stages. After all, the earlier a code defect is detected, the cheaper it is to eliminate.
What's interesting is that a student has a chance to write a high-quality program as part of a course project. And they can well do it without static analysis. But it is impossible to write a project of gaming engine level without bugs. The thing is that with the growth of the codebase, the error density increases. To maintain the high quality of code, you need to spend a lot of effort and use various methodologies, including code analysis tools.
Let's find out what the error density increase means. The larger the codebase size, the easier it is to make a mistake. The number of errors increases with the growth of the project size not linearly, but exponentially.
A person can no longer keep the whole project in his head. Each programmer works only with a part of the project and the codebase. As a result, the programmer cannot foresee absolutely all the consequences that may arise if they change some code fragment during the development process. In a simple terms: something is changed in one place, something breaks in another.
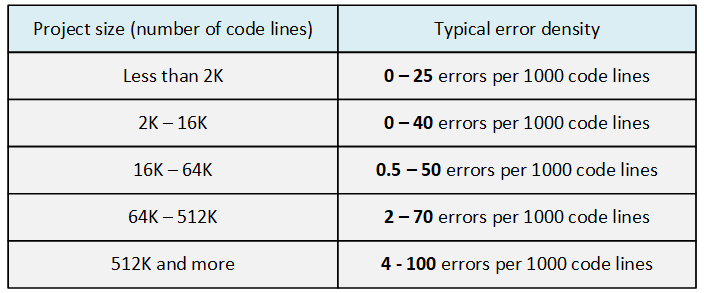
And in general, the more complex the system is, the easier it is to make a mistake. This is confirmed by numbers. Let's look at the following table, taken from the "Code Complete" book by Stephen McConnell.
Static code analysis is a good assistant for programmers and managers who care about the project quality and its speed development. Regular use of analysis tools reduces the error density, and this generally has a positive effect on productivity. From the book by David Anderson "Kanban: Successful Evolutionary Change for Your Technology Business":
Capers Jones reports that in 2000, during the dot-com bubble, he evaluated the quality of programs for North American teams. The quality ranged from six errors per function point to less than three errors per 100 function points — 200 to one. The midpoint is approximately one error per 0.6–1.0 functional point. Thus, teams usually spend more than 90% of their efforts on fixing errors. There is also direct evidence of this. In late 2007, Aaron Sanders, one of the first followers of Kanban, wrote on the Kanbandev mailing list that the team he worked with spent 90% of the available productivity on bug fixes.
Striving for inherently high quality will have a serious impact on the performance and throughput of teams that make many errors. You can expect a two to fourfold increase in throughput. If the team is initially lagging behind, then focusing on quality allows you to increase this indicator tenfold.
Use static code analyzers, for example — PVS-Studio. Your team will be more engaged in interesting and useful programming, rather than guessing why the code doesn't work as planned.
By the way, all written above doesn't mean that it makes no sense for students to use static code analyzers. Firstly, the static analyzer detects errors and low-quality code. It helps to master the programming language faster. Secondly, skills of working with code analyzers may be useful in the future, when you'll work with large projects. The PVS-Studio team understands this and provides students with free license.
Additional links:
Do not use the standard language library. What could be more interesting than writing your own strings and lists with unique syntax and semantics?
Maybe it's really interesting. However, it's a time-consuming process. Moreover, the result is likely to be of lower quality than the existing standard solutions. In practice, it turns out that it's not easy to write even analogues of such simple functions as strdup or memcpy without errors: Starting my collection of bugs found in copy functions.
Use more code in header files. It is much more convenient, and the compilation time increases only slightly.
In the era of the header-only libraries, this tip does not seem so terrible. After all, there is even "A curated list of awesome header-only C++ libraries".
But small libraries are one thing. And the other thing is a big project that involves dozens of people and has been developing for many years. At some point, the compilation time will grow from minutes to hours, and it will be difficult to do something about it. It's not like you will refactor hundreds and thousands of files by transferring the implementation of functions from h to cpp files. And if you refactor, then wouldn't it have been easier to write it properly right away? :)
The implementation of functions in header files may have the worst consequence. For example, a minimum of editing leads to the need to recompile a large number of files in the project. There is a key difference between the code in header-only libraries and the code of your project. You don't touch the code in the libraries, and you constantly edit your code!
Additional useful link: PImp.
Never use enums, they implicitly change to int anyway. Use int directly!
The C++ language evolves and becomes a more and more strongly typed language. Therefore, for example, the enum class appeared. Check out the discussion "Why is enum class preferred over plain enum?".
Our terrible tip, on the contrary, encourage us to return to a situation where it's easy to get confused in data types and accidentally use the wrong variable or the wrong constant.
If there are ordinary enums instead of plain int in code, the PVS-Studio analyzer can still detect the following anomalies.
Show a little respect for programmers of the past — declare all variables at the beginning of functions. It's a tradition!
It's best to declare a variable as close as possible to the place where it is used. It's even better when you declare a variable and also initialize it. Pros:
One need to act consciously. For instance, if there are loops, sometimes it's better to create and initialize a variable outside the loop to increase the program's performance. Examples: V814, V819.
Include as many header files as possible so that each .cpp file opens in a million lines — your teammates will thank you for having more time for a smoke break during rebuild!
At first, I did not plan to comment on this tip. But then I thought that sometimes there are cases when you do need to include a lot of header files. So I want to give a hint on how to speed up the build of such projects. Precompiled header files will help you! You can read the following article "StdAfx.h". I talk about Visual C++ there, but other compilers provide similar functionality.
Additionally, these publications of my colleagues may help you:
What could be wrong with looking at a neighboring variable through a pointer to a variable? I mean, we are within the limits of our memory.
In my practice, I have encountered code fragments similar to the following:
float rgb[3];
float alphaChannel;
....
for (int i = 0; i < 4; i++)
rgb[i] = 0f;Someone was too busy to write zero separately to the variable for the alpha channel. They combined the variable initialization with the initialization of array elements.
Doing so is bad and unsafe for three reasons:
And here is another interesting case. A long time ago, in 2011, I wrote an article on checking the VirtualDub project. The author said that the code worked as intended so it's better to leave everything as it is, rather than changing the code where access outside the array occurs: The "error" in f_convolute.cpp.
There's a risk that this text on the link will get lost over time. For example, comments are already lost. Just in case, I will quote the whole text here.
The "error" in f_convolute.cpp
Okay, Mr. Karpov decided to use VirtualDub again as an example of a detected code defect in his article, and while I respect him and his software, I resent the implication that I don't understand how C/C++ arrays work and that he included this example again without noting that the code actually works. I'd like to clarify this here.
This is the structure and reference in question:
struct ConvoluteFilterData {
long m[9];
long bias;
void *dyna_func;
uint32 dyna_size;
uint32 dyna_old_protect;
bool fClip;
};
long rt0=cfd->m[9], gt0=cfd->m[9], bt0=cfd->m[9];This code is from the general convolution filter, which is one of the oldest filters in VirtualDub. It computes a new image based on the application of a 3x3 grid of coefficients and a bias value. What this code is doing is initializing the color accumulators for the windowing operation with the bias value. The structure in question here is special in that it has a fixed layout that is referenced by many pieces of code, some written in assembly language and some dynamically generated (JITted) code, and so it is known -- and required -- that the element after the coefficient array (m) is the bias value. As such, this code works as intended, and if someone were to correct the array index to 8 thinking it was an off-by-one error, it would break the code.
That leaves the question of why I over-indexed the array. It's been so long that I don't remember why I did this. It was likely either a result of rewriting the asm routine back into C/C++ -- back from when I used to prototype directly in asm -- or from refactoring the structure to replace a 10-long array with a 9-long coefficient array and a named bias field. Indexing the tenth element is likely a violation of the C/C++ standard and there's no reason the code couldn't reference the bias field, which is the correct fix. Problem is, the code works as written: the field is guaranteed to be at the correct address and the most likely source of breakage would be the compiler doing aggressive load/store optimizations on individual structure fields. As it happens, the store and load are very far apart -- the struct is initialized in the filter start phase and read much later in the per-frame filter loop -- and the Visual C++ compiler that I use does not do anything of the sort here, so the generated code works.
The situation at this point is that we're looking at a common issue with acting on static analysis reports, which is making a change to fix a theoretical bug at the risk of introducing a real bug in the process. Any changes to a code base have risk, as the poor guy who added a comment with a backslash at the end knows. As it turns out, this code usually only executes on the image border, so any failures in the field would have been harder to detect, and I couldn't really justify fixing this on the stable branch. I will admit that I have less of an excuse for not fixing it on the dev branch, but honestly that's the least of the problems with that code.
Anyway, that's the history behind the code in f_convolute.cpp, and if you're working with VirtualDub source code, don't change the 9 to an 8.

This unicorn on the picture perfectly shows my reaction to the message. I don't understand why not just take and write code where the value is taken from the bias variable.
The const word just takes up space in code. If you don't want to change a variable, then you just will leave it like that.
Really, if you don't want to change it — don't do that. The only problem is that we all make mistakes. The const qualifier allows you to write more reliable code. The qualifier protects against typos and other misunderstandings that may arise during code writing or refactoring.
Here's the example of the bug we found in the Miranda NG project:
CBaseTreeItem* CMsgTree::GetNextItem(....)
{
....
int Order = TreeCtrl->hItemToOrder(TreeView_GetNextItem(....));
if (Order =- -1)
return NULL;
....
}The programmer's hand slipped and there's '=-' instead of '==' in the condition. A new value is assigned to the variable, although the intention was to perform a comparison. Let's suppose that the programmer would use the const keyword:
const int Order = TreeCtrl->hItemToOrder(TreeView_GetNextItem(....));
if (Order =- -1)
return NULL;In this case, the code wouldn't compile.
However, const isn't that helpful in terms of code optimization. You can find the following reasoning in some articles: if you make a variable as constant, you help a compiler to generate more optimized code. These are high expectations. See the article "Why const Doesn't Make C Code Faster". Another thing — constexpr. This keyword brings up interesting possibilities to perform many calculations even at the code compilation stage: "Design and evolution of constexpr in C++". Read the article, you won't regret it.
Create variables that will differ in names only by numbers: index1, index2. As many as possible.
This tip refers to the "Zero, one, two, Freddy's coming for you" article where I tell how easy it is to make a typo when you use names such as A0, A1, A2.
Write your code as if the chairman of the IOCCC judges will read it and as if they know where you live (to come and give you the prize).
It's a reference to a quote — "Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live". This is John F. Woods's phrase, however it's sometimes credited to Steve McConnell who quoted it in his "Code Complete" book.
The tip tells that you need to write as unusual, weird, and incomprehensible code as possible — like you're going to send it to the IOCCC contest.
IOCCC (International Obfuscated C Code Contest) is a computer programming contest. Participants need to write the most creatively obfuscated C code within code size limit.
Why poorly written code is bad seems obvious. But still — why? A programmer spends most of his time not writing code but reading it. I can't remember the source and the exact numbers, but it seems to say that they spend more than 80% of their time reading.
Accordingly, if the code is hard to read and understand, that greatly slows down the development. That's one of the reason why every team member needs to follow one coding style so it can be read by other developers.
Universal std::string is inefficient. realloc, strlen, strncat work more quickly and effectively.
The fact that the program performance can be significantly increased by giving up the std::string class is a myth. However, the myth didn't appear for no reason.
The thing is that previously common implementations of std::string was far from satisfactory. So, maybe, we are not even dealing with a myth, but with outdated information.
Let me share my own experience. Since 2006, we've been developing the PVS-Studio static analyzer. In 2006, its name was Viva64, but it doesn't matter. Initially, we widely used the standard std::string class in the analyzer.
Time passed. The analyzer developed, more and more diagnostics appeared, and it worked slower and slower with each release :). It was time to think about code optimization. The profiler pointed out at one of the bottlenecks — the work with strings. And then I remembered the quote "in any project, sooner or later, customs string class appears". Unfortunately, I don't remember where this quote came from, or exactly when it happened. I think it was 2008 or 2009.
The analyzer creates many empty or very short strings during its work. We created our own string class — vstring that effectively allocated memory for such strings. From the point of view of the public interface, our class repeated std::string. The custom string class increased the analyzer's speed by about 10%. Cool achievement!
This string class served us for many years, until I listened Anton Polukhin's report at the C++ Russia 2017 conference — "Things not to do: how C++ professionals reinvent the wheels [RU]". In his report, he said that the std::string class has been well optimized for many years. And those who use their own string class are unprogressive dinosaurs :).
Anton told the audience what optimizations are currently used in the std::string class. For example, from the simplest – about the move constructor. I was particularly interested in Short String Optimization.
I didn't want to be a dinosaur anymore. Our team conducted an experiment — we started to switch from a custom vstring class back to std::string. First, we just commented out the vstring class and wrote typedef std::string vstring;. Fortunately, after that, minor code edits were required in other places since the class interfaces still almost completely matched.
And how has the running time changed? It hasn't changed! It means, for our project, the universal std::string has become just as effective as our own custom class that we made about a dozen years ago. Amazing! Minus one pointless invention.
However, let's go back to talking about classes. The terrible tip recommends that we go down to the level of the C language functions. I doubt that these functions will help write faster and more reliable code than in the case of using a string class.
Firstly, the processing of C-strings (null-terminated strings) provokes frequent calculation of their length. If you don't store the length of the strings separately, it's difficult to write high-performance code. And if you store the length, then we again proceed to the string class analog.
Secondly, it is difficult to write reliable code with the use of functions such as realloc, strncat, and so on. We describe errors that we find in various projects. This experience underscores: the code that consists of these functions directly "attracts" errors. Here are error patterns found when strlen, strncat, realloc were used.
If you can refer to the next element outside the array, it means that it's possible to access this element as well. Opps, this is the 51st item on the list, and I promised 50. Sorry, but what a C++ article without an off-by-one error :).
Array overrun leads to undefined behavior. However, there is one point that may confuse a junior programmer.
C++ allows to refer to the element that lays behind the last array element. For example, the following code:
int array[5] = { 0, 1, 2, 3, 4 };
int *P = array + 5;However, the P pointer's value can only be compared with other values, but not dereferenced.
Such permission allows to build an elegant concept of iterators. In classes for working with arrays, the end function returns an iterator that points to a conditional element. This element is located behind the last container element. The end iterator can be compared with other iterators, but it cannot be dereferenced.
In addition, programmers simply inadvertently make a mistake by going 1 element outside the array. Such an error even has a name — off-by-one error. The reason is that the elements in the array are numbered from 0. This may be confusing sometimes, especially when writing code in a hurry.
Most often, the error occurs due to incorrect index validation. Developers checks that the index is not greater than the number of elements in the array. But this is incorrect: if the index is equal to the number of elements, it already refers to an element outside the array. Let's explain this with an example.
The following error was found by the PVS-Studio static analyzer in Clang 11. So, as you can see, not only juniors make such mistakes.
std::vector<Decl *> DeclsLoaded;
SourceLocation ASTReader::getSourceLocationForDeclID(GlobalDeclID ID) {
....
unsigned Index = ID - NUM_PREDEF_DECL_IDS;
if (Index > DeclsLoaded.size()) {
Error("declaration ID out-of-range for AST file");
return SourceLocation();
}
if (Decl *D = DeclsLoaded[Index])
return D->getLocation();
....
}The correct check should be as follows:
if (Index >= DeclsLoaded.size()) {Thank you for attention. Wish you bugless code. And come read other articles in our blog.
0
0
0
0