
Our website uses cookies to enhance your browsing experience.

Imagine: something in code goes wrong, you start searching for a bug and then it turns out that there was another bug behind this. Have you ever been in this situation? Searching for bugs is cool. It's almost like you're Sherlock Holmes and it's a detective story. Something from an extensive list of seemingly harmless classes and functions causes a program's unexpected and undefined behavior. And you, with your sharp eyes and experiments, are trying to find the "criminal".
We published and translated this article with the copyright holder's permission. The author is Eugene Zakharov (fnc12@me.com). The article was originally published on Habr.

There are several stages of bug search:
My name is Eugene, and I'm an open-source developer. I develop the sqlite_orm library in C++ in my free time.
The sqlite_orm library is a more convenient API in C++ than the original SQLite3 library written in pure C. Of course, other contributors and I have not yet covered the whole API SQLite, so the work never stops. I have been asked for a long time to add custom function support to sqlite_orm. This is an opportunity to bind callbacks in pure C as functions available inside SQLite queries. So, I decided that it was enough to pull the cat's tail. Someday I'll have to do it anyway, why not do it right now? Said and done. I started coding. The feature consists of three parts:
I did all three steps. These were three consecutive pull requests. In short, I haven't yet merged the third pull request. To put it mildly, some magic oddities happened to it.
All of a sudden, AppVeyor said that unit tests crashed. Hmm, OK, I started investigating. Of course, this surprised me because locally everything was great.
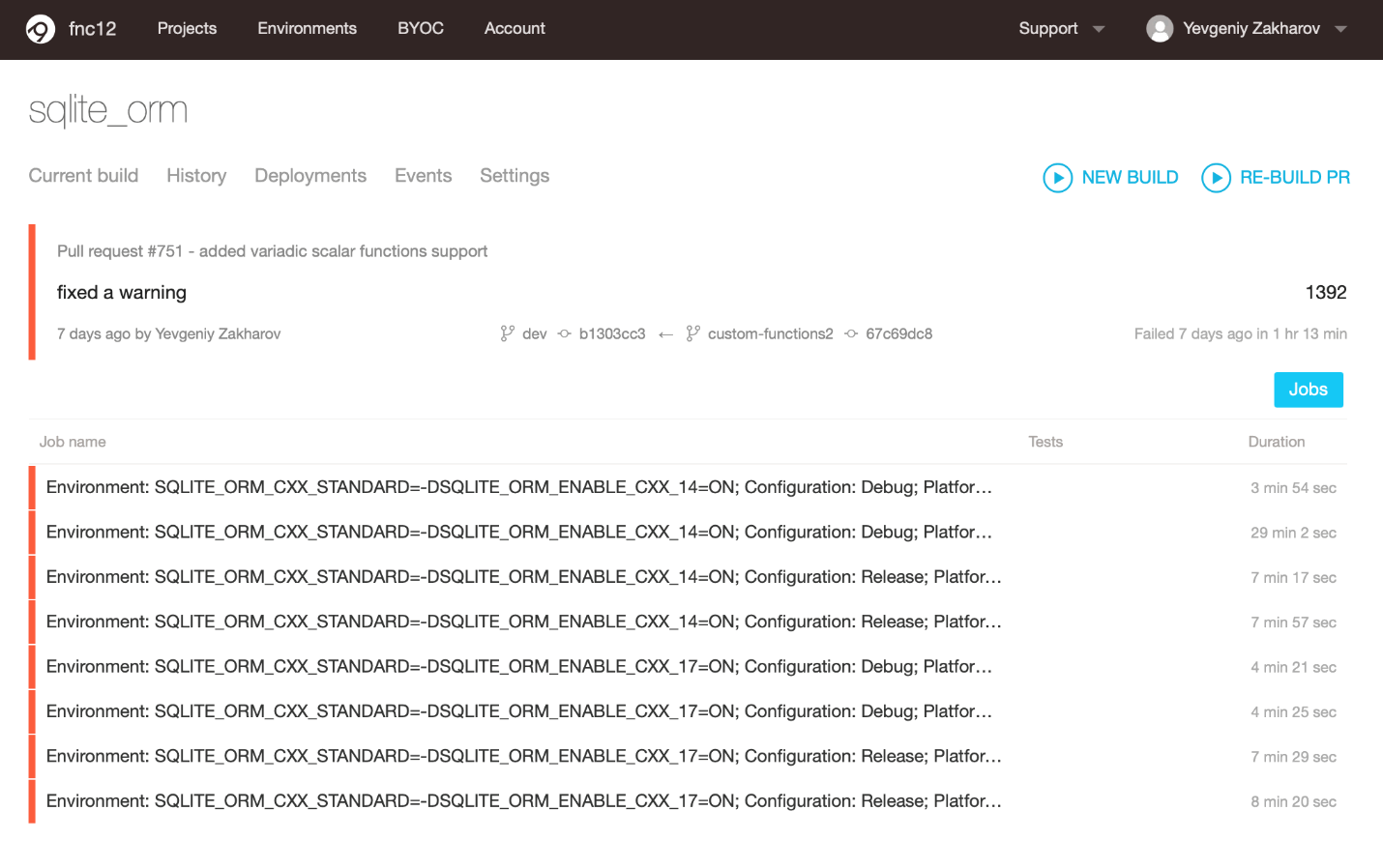
However, locally I worked on macOS. AppVeyor built Windows for me. Thus, the error was platform dependent. This meant that I had a "funny" detective story coming — platform dependent errors are the most harmful. I couldn't even imagine how it would turn out.
OK, I looked at AppVeyor logs. Logs said: 1 test failed. OK, let's see what test failed. It's the same test that I added along with the custom functions. To be more precise, here are the logs:
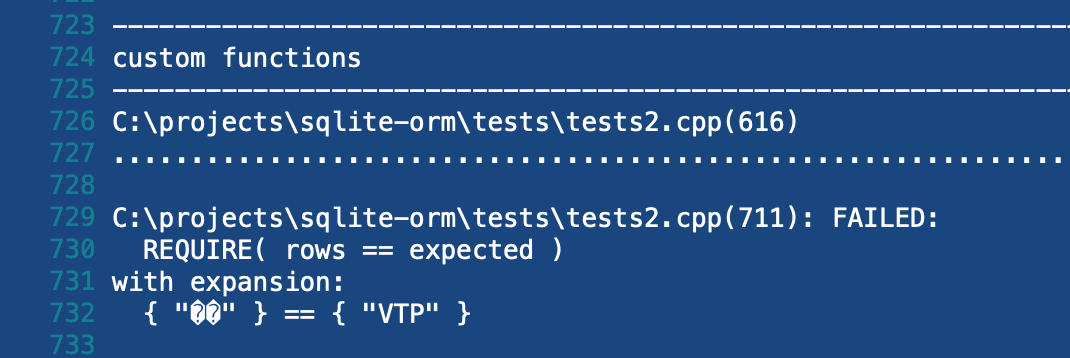
[SPOILER BLOCK BEGINS]
For those who are interested in technical details. Here's what happens:
Look at the SELECT FIRST('Vanotek', 'Tinashe', 'Pitbull') query. The FIRST function is a scalar function with an arbitrary number of arguments. This function accepts strings and returns a string. The returned string consists of the first characters of all arguments in the same order in which they are substituted in the function. On macOS the result equals "VTP" (which is logical), but not on Windows.
[SPOILER BLOCK ENDS]

I was confused, I blamed Windows for this. I even thought about stopping its support, deleting this unit test, and merging the PR as is. But then I calmed down, discarded stupid thoughts, and started trying to find the cause of this problem.
Let me not go into detail of what happened next. I'll keep it short. First, I added cout logs — I wanted to look at what was happening right on AppVeyor and quickly solve the problem. It didn't work out. Then I launched Windows, built my project in Visual Studio and started debugging. Luckily, I reproduced the bug on Windows. In the end, I detected the problem. When I gave the string for the result, I needed to copy it and provide a pointer to the destructor function. The funniest part of this bug — when debugging, I couldn't figure out why integers were perfect as a result, but strings crashed (but only on Windows). macOS consistently output 0 failed tests. I even wrote to one of the SQLite developers about the bug reproduced only in Windows. When I realized what the problem was, I wrote to him again, saying "I was a fool myself" and "sorry I spammed you with code fragments".
This was a very stupid bug, and the fault was mine alone — not the teammates', not GitHub's, not third-party libs', and not the compiler's. I was a fool, I got out of habit of writing in pure C and missed such bugs. If you, my fellow reader, think that a person with a 1000+ stars open-source project is super-smart, I've got bad news for you. Sometimes I write such nonsense, that I'm more interested in why my head produces these cognitive deviations than in writing code. And my code quality doesn't depend on the stars of sqlite_orm. It depends on the simple "I got good/bad sleep" and "I got/haven't got tired from walking in the hot sun of Almaty".
However, if someone told me that simply fixing this bug wouldn't be enough, I wouldn't believe. In fact, the most interesting thing was only waiting for me — I was about to meet the bug boss, the boss of all bug bosses in the history of sqlite_orm.
But let's go back to the time when I just fixed the bug. I felt like a fool and a hero at the same time. A fool because it was a stupid bug. A hero because finally I'd have pull request checks succeed on AppVeyor and I'd support user functions. I was thinking about this bug while unit tests were running. In particular, why it refused to reproduce on macOS. In fact, I often encounter this. I must note that macOS + iOS are more tolerant of undefined behavior than Windows. After all, I was passing a pointer to a string that was already "dead" by the time it was necessary to get this string. However, the memory not only remained in process, but also retained its contents. And it saved the process every time I ran unit tests on macOS. I.e., macOS sometimes turns undefined behavior into defined behavior.
Can you imagine my surprise when the checks failed again? I was sure that "don't trust your eyes" is just a figure of speech, but at that moment I literally couldn't trust my eyes. I was sure my eyes were bugging — just like my brain when I created this stupid bug. I wholeheartedly believed that the checks passed, and I could finally merge the pull request. However, the checks failed, and it was a fact. "Well, it's probably some exterior error", I thought. "Probably the last commit didn't catch up, the AppVeyor network is bugging, a meteorite landed on a build agent. My code is surely bug-free". I was so wrong.
I went to the PR details page in AppVeyor. And I finally saw a familiar picture: all 8 runs were red again. As if I hadn't committed anything! But I had! I replayed the moments of committing in my head. I definitely did it, I wasn't going crazy. OK, let's go to the logs. Here's what the logs showed:
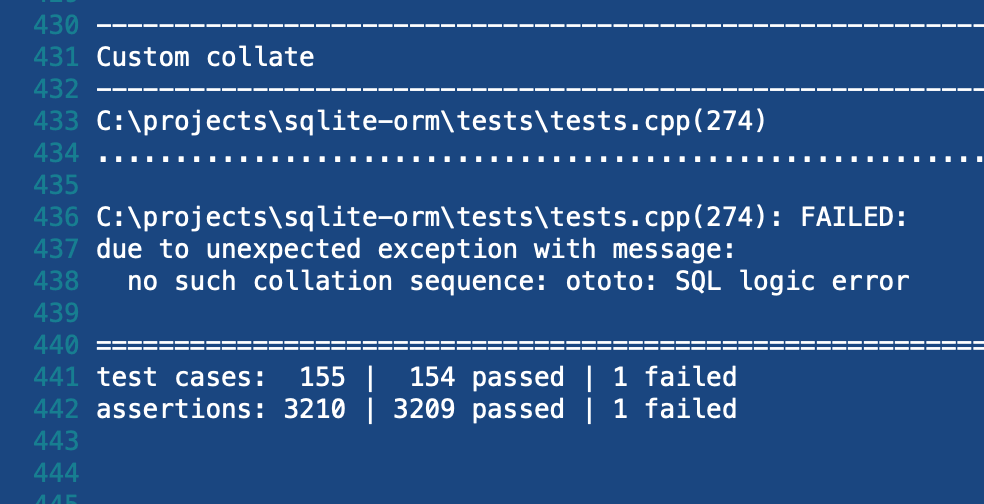
The logs say that custom collations feature tests have crashed. This feature has nothing to do with custom functions. The custom collations feature is similar to custom functions, but it has nothing in common in terms of their implementation. Custom collations allow adding your own collating sequences. Those sequences are called as callbacks for functions (used for strings comparison) in pure C. I repeat: these two features have no connection. I can throw out one of them and the second one will remain functional. The containers that store the information about custom functions and collations are also different — the types are different. This means I couldn't mistakenly pass an iterator to one container to another.
I thought, "OK, my PR with functions has absolutely nothing to do with it". This means that the dev main development branch should also show this error. However, everything was great in the dev branch — 8 green runs. So, it's about custom functions. But how can functions affect collations? And why only on Windows, and not on macOS? I was about to lose my mind, but it was already almost gone. I was about to admit my underqualification and go work somewhere else. What if it's the undefined behavior tolerance again? Twice in a day! But why is everything great in the dev branch on Windows? The custom collations feature was implemented three years ago at a library user's request. It can't be that all these people failed to notice that the collations don't work.
OK, I calmed down and went to look at the code. I'll show it to you too. You are welcome to find an error here.

If you have found it - you are great. I'm not. I've found it recently. And the code has been working wrong for three DAMN years!
[SPOILER BLOCK BEGINS]
What's happening in the code:
In line 323 the std::move function moves the second function argument (f) to the local container. After that f will be empty (f is std::function). In line 335, an alternative result — not the main one — will always be returned in the ternary operator. In this case, instead of creating a collation with the specified name, a collation deletion is called.
[SPOILER BLOCK ENDS]
So, I found the cause of the "no such collating sequence" error. Let's fix the code. I'm still freaking out from the fact that this bug was unveiled by a new non-related feature. So, I implemented a patch to make test finally pass successfully. I pushed the patch and while waiting for the unit tests to build on AppVeyor, I started thinking about this situation. Everything had been great before! On Windows too! Other developers used all of this and no one complained. Well, I had about an hour for my PR's turn. I waited.
You probably think: "Eugene, so what? Is this the most epic bug?" But wait, this is not the end!
When the build completed, what do you think was the result on AppVeyor? That's right, red. Guess which tests failed? Here's the picture:
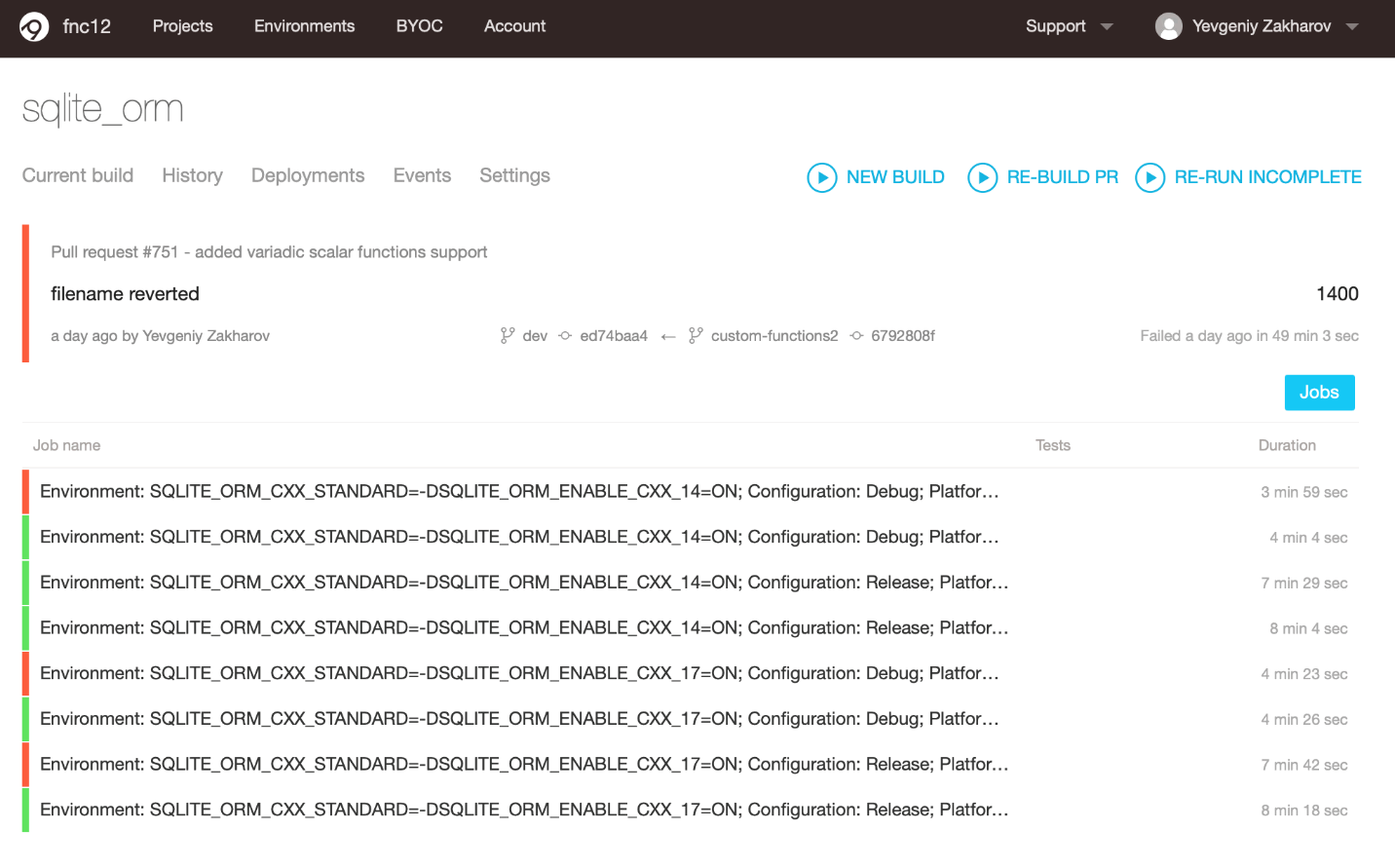
"This is nonsense", I thought immediately. Something went wrong on the build agents. To be serious, sometimes it happens that SQLite could not download — wget failed and because of this the build also failed. But (spoiler) nothing like this happened. In my further commits, where I added log outputs, the result was identical: the same three out of eight configurations failed. You may ask: "What's wrong there?" This:
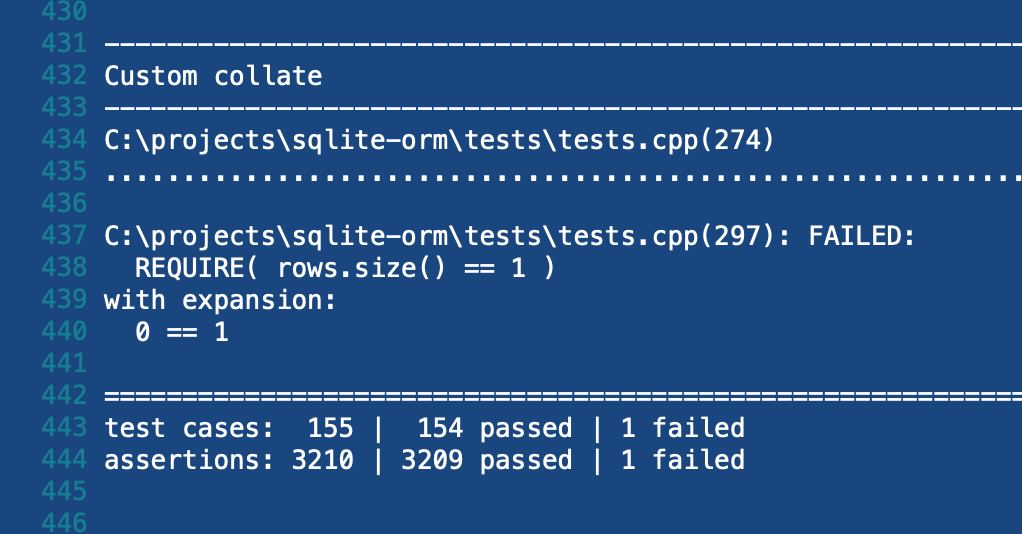
Same test, different error. Earlier, SQLite could not find the collating sequence. Now it found this collating sequence, but it did not work. That's why the rows container was empty, although there should be one entry.
Fuck, fuck, fuck! How so? Why do I make user functions, but collations break? Why such logic? Why does everything work in dev? Why only Windows? Why are there so many "whys"? I love detective stories, but here the Murphy's law is obviously mocking me.
OK, stop worrying, start searching for an error. I can't tell you how long I was searching for an error. I'll just tell you where it was. Here's the code:
This is the code of a test. The lambda should compare strings and return the index of the first mismatched character, similarly to the strcmp function. I ignored the first argument of the int type. This is the length of the data to compare. SQLite does not guarantee that the second and third arguments have null terminators after them. For some reason, these null terminators used to be there. Three whole years! But with the appearance of user functions, three out of eight configurations on Windows suddenly stopped showing tolerance for undefined behavior. I certainly wasn't prepared for this.
By replacing the code with this one, I achieved that all the tests passed as they should:

What do we have in the end? If we omit the stupid error with copying the C string, then the new feature suddenly revealed completely unrelated problems. These problems were in the form of code that behaves vaguely in theory, but in practice behaved very definitely for three years — at least the tests were successful and there were no crashes. I call this feature tolerance to undefined behavior. At the moment, this is the longest-lived undefined behavior in sqlite_orm. This is undefined behavior carried through the years. Perhaps you expect some conclusions and parting words from me. There won't be any. I just shared a story with you as if we were just sitting in for a beer at Oktoberfest or watching the sunset on a hike in Altai or accidentally sat together at the same table in a dining car on the train from Tbilisi to Batumi. In no way did I write this to show how bad C++ is. First of all, I wanted to show what stupid mistakes in the code can lead to. Especially when you're the one making these mistakes, and not your colleagues on the project, not GitHub, not third-party libs and not a compiler.
Thank you all for reading, and I wish everyone green tests!
0
0
0
0