
Our website uses cookies to enhance your browsing experience.


Your attention is invited to the second part of an e-book on undefined behavior. This is not a textbook, as it's intended for those who are already familiar with C++ programming. It's a kind of C++ programmer's guide to undefined behavior and to its most secret and exotic corners. The book was written by Dmitry Sviridkin and edited by Andrey Karpov.

Most written or yet unwritten program code works with numbers anyway. They handle numbers everywhere: when evaluating formulas, when incrementing or decrementing loop counters, recursive calls, and container elements.
A computer can't directly process infinitely "long" numbers and store all their digits. No matter how much RAM we have, it's still finite. It's frustrating to store and handle values that are comparable to the number of atoms in the visible part of the universe, isn't it?
However, when we operate on integers, we still have a chance to be outside the valid range (e.g. [-2^31, 2^31-1] for int32). Here, the specifics of integer support for different programming languages come into play. The specifics of a particular platform implementation may also play a role.
When a program executes the add (iadd) instruction of the x86 platform, a special overflow flag follows an integer overflow. We simply obtain the result value, dropping the most significant bit from the result. That's why we expect that when the following program ends:
x = 2^31 - 1
iadd x 5We get an arithmetic shift, and the x variable turns into a negative value.
Some programming language implementations might have a check for overflow and an error message. Or it might not. There may be the guarantee of a wraparound (-2^31 follows 2^31-1), or there may not be.
Checks and guarantees are extra instructions the compiler generates, and then the processor executes them.
C++ developers decided not to skimp on performance and make compilers generate checks. Instead, they declared the signed integer overflow as undefined, opening up space for optimizations. The compiler can generate any code it wants, following only one rule: there is no overflow.
Many programmers firmly believe that integer overflow operates as expected — "wrap around" — and they write checks like:
if (x > 0 && a > 0 && x + a <= 0) {
// handle overflow
}Alas, it's undefined behavior. The compiler has full right to throw out such a check.
int main() {
int x = 2'000'000'000;
int y = 0;
std::cin >> y;
if (x > 0 && y > 0 && x + y <=0){
return 5;
}
return 0;
}Note that in assembly code, a call to the read-from-stream function is immediately followed by setting the eax (xor eax, eax) register to zero and returning it as the result of the function.
main:
sub rsp, 24
mov edi, OFFSET FLAT:std::cin
lea rsi, [rsp+12]
mov DWORD PTR [rsp+12], 0
call std::basic_istream<char, std::char_traits<char> >::operator>>(int&)
xor eax, eax
add rsp, 24
retThe synthetic example may not convince you. Let's focus on the following real function that evaluates a polynomial string hash:
int hash_code(std::string s) {
int h = 13;
for (char c : s) {
h += h * 27752 + c;
}
if (h < 0) h += std::numeric_limits<int>::max();
return h;
}A function, that shall never return negative numbers, returns a negative number! It's all because of undefined behavior and the compiler-wise meaningless check.
The compiler can be guided by the following logic:
As another great, yet synthetic example, to scare you a bit more: a finite cycle can become infinite! We'll take the example from the post "Shocking Examples of Undefined Behavior":
int main() {
char buf[50] = "y";
for (int j = 0; j < 9; ++j) {
std::cout << (j * 0x20000001) << std::endl;
if (buf[0] == 'x') break;
}
}The compiler amazingly optimizes the constant multiplication using consecutive numbers. It even changes the loop header and the stopping conditions:
for(int j = 0; j < 9*0x20000001; j += 0x20000001) {
....
}The j < 9*0x20000001 condition is always true because the right part is greater than std::numeric_limits<int>::max().
The example is really engaging if we look at modern versions of compilers. GCC can detect an overflow and issue a warning in such loops. But it doesn't happen... However, if we comment the unreachable break and buf, we get the warning:
<source>:6:37: warning:
iteration 4 invokes undefined behavior [-Waggressive-loop-optimizations]
6 | std::cout << (j * 0x20000001) << std::endl;
| ^
<source>:5:23: note: within this loop
5 | for (int j = 0; j < 9; ++j) {If we uncomment the buf declaration, the warning goes away (GCC 13.2).
It happens the other way around, too. We expect the consequences of the overflow to hit us, but they don't. The code just keeps magically working. Here's the example from the article "Undefined behavior is closer than you think":
size_t Count = size_t(5) * 1024 * 1024 * 1024; // 5 Gb
char *array = (char *)malloc(Count);
memset(array, 0, Count);
int index = 0;
for (size_t i = 0; i != Count; i++)
array[index++] = char(i) | 1;When the 32-bit signed index variable is incremented, it'll be overflowed and seems to become negative. After that, the Access Violation occurs during the array overrun. But in the UB case, no one owes anyone anything.
To optimize the code, the compiler uses a 64-bit register for the index variable, which is perfectly incremented—all the array items are filled successfully. It has its right: if the overrun doesn't occur, it's got to use a 32-bit register for the index.
Another, yet better-known and sometimes useful, example of the optimization that such undefined behavior facilitates for the compiler is wrapping around known sums.
For example, when we sum arithmetic progressions and some other known rows, Clang 12 generates completely different code for signed and unsigned numbers.
Here's an example with signed types:
// let's sum squares from 1 to N
int64_t summate_squares(int64_t n) {
int64_t sum = 0;
for (int64_t i = 1; i <= n; ++i) {
sum += i * i;
};
return sum;
}The assembler listing (x86-64 clang 12.0.1, -std=c++20 -O3). Note that there is no loop here. We use the well-known (N * (N + 1)) * (2N + 1) / 6 formula but in a rather complicated way:
summate_squares(long): # @summate_squares(long)
test rdi, rdi
jle .LBB2_1
lea rax, [rdi - 1]
lea rcx, [rdi - 2]
mul rcx
mov r8, rax
mov rsi, rdx
lea rcx, [rdi - 3]
mul rcx
imul ecx, esi
add edx, ecx
shld rdx, rax, 63
movabs rax, 6148914691236517206
shld rsi, r8, 63
imul rax, rdx
lea rcx, [rsi + 4*rsi]
add rcx, rax
lea rax, [rcx + 4*rdi]
add rax, -3
ret
.LBB2_1:
xor eax, eax
ret
*/Here's an example with unsigned types:
uint64_t usummate_squares(uint64_t n) {
uint64_t sum = 0;
for (uint64_t i = 1; i <= n; ++i) {
sum += i * i;
};
return sum;
}Here's the loop. The overflow of unsigned types is defined and is needed to be handled:
usummate_squares(unsigned long): # @usummate_squares(unsigned long)
test rdi, rdi
je .LBB3_1
mov ecx, 1
xor eax, eax
.LBB3_4: # =>This Inner Loop Header: Depth=1
mov rdx, rcx
imul rdx, rcx
add rax, rdx
add rcx, 1
cmp rcx, rdi
jbe .LBB3_4
ret
.LBB3_1:
xor eax, eax
retGCC 13 — at the moment of writing (2024) — basically doesn't optimize that way by default. While the latest versions of Clang 18 have already been able to optimize the sum of squares loop for integers as well:
usummate_squares(unsigned long): # @usummate_squares(unsigned long)
test rdi, rdi
je .LBB3_1
inc rdi
cmp rdi, 3
mov r8d, 2
cmovae r8, rdi
lea rax, [r8 - 2]
lea rcx, [r8 - 3]
mul rcx
mov rsi, rax
mov rcx, rdx
lea rdi, [r8 - 4]
mul rdi
imul edi, ecx
add edx, edi
shld rdx, rax, 63
movabs rax, 6148914691236517206
shld rcx, rsi, 63
imul rax, rdx
lea rcx, [rcx + 4*rcx]
add rcx, rax
lea rax, [rcx + 4*r8]
add rax, -7
ret
.LBB3_1:
xor eax, eax
retIf you're familiar with the Ring theory, you can write simpler and shorter assembly code for the unsigned version as an exercise. All you need to do is to correctly divide by 6.
Correct overflow checks in arithmetic operations are much more complicated than just changing the sign.
So, for C++20, a safe generic code for arithmetic operations on signed integers could look as follows:
#include <concepts>
#include <type_traits>
#include <variant>
#include <limits>
namespace safe {
// All these checks are valid only for signed integers
template <class T>
concept SignedInteger = std::is_signed_v<T>
&& std::is_integral_v<T>;
enum class ArithmeticError {
Overflow,
ZeroDivision
};
template <SignedInteger I>
using ErrorOrInteger = std::variant<I, ArithmeticError>;
template <SignedInteger I>
ErrorOrInteger<I> add(I a, // disable the template parameter output by
std::type_identity_t<I> b) // the second argument
{
if (b > 0 && a > std::numeric_limits<I>::max() - b) {
// positive overflow
return ArithmeticError::Overflow;
}
if (b < 0 && a < std::numeric_limits<I>::min() - b) {
// negative overflow
return ArithmeticError::Overflow;
}
return a + b;
}
template <SignedInteger I>
ErrorOrInteger<I> sub(I a, std::type_identity_t<I> b) {
if (b < 0 && a > std::numeric_limits<I>::max() + b) {
// positive overflow
return ArithmeticError::Overflow;
}
if (b > 0 && a < std::numeric_limits<I>::min() + b) {
// negative overflow
return ArithmeticError::Overflow;
}
return a - b;
}
template <SignedInteger I>
ErrorOrInteger<I> mul(I a, std::type_identity_t<I> b) {
if (a == 0 || b == 0) {
return 0;
}
if (a > 0) {
if (b > 0) {
if (a > std::numeric_limits<I>::max() / b) {
return ArithmeticError::Overflow;
}
} else {
if (b < std::numeric_limits<I>::min() / a) {
return ArithmeticError::Overflow;
}
}
} else {
if (b > 0) {
if (a < std::numeric_limits<I>::min() / b) {
return ArithmeticError::Overflow;
}
} else {
if (b < std::numeric_limits<I>::max() / a) {
return ArithmeticError::Overflow;
}
}
}
return a * b;
}
template <SignedInteger I>
ErrorOrInteger<I> div(I a, std::type_identity_t<I> b) {
if (b == 0) {
return ArithmeticError::ZeroDivision;
}
if (a == std::numeric_limits<I>::min() && b == -1) {
// the [min, max] range is asymmetric to 0.
// if abs(min) > max, here will be an overflow
return ArithmeticError::Overflow;
}
return a / b;
}
template <SignedInteger I>
ErrorOrInteger<I> mod(I a, std::type_identity_t<I> b) {
if (b == 0) {
return ArithmeticError::ZeroDivision;
}
if (b == -1) {
// According to the standard, undefined behavior occurs when
// a == std::numeric_limits<I>::min()
// because the remainder and the partial quotient of division,
// for example, on the x86 platform
// are equal by the same div (idiv) instruction,
// which would require additional handling.
//
// But it's clear that the division remainder of anything by -1 is 0
return 0;
}
return a % b;
}
}If you don't want to return an error or the result, you can use exceptions.
It seems that safe versions of arithmetic operations should be at least twice as slow as the initial unsafe versions. Such a saving on clock rate could be worth it if you're developing a math library, and the whole performance is limited by the CPU and grinding numbers.
However, if your program only pends and performs I/O operations, no one will notice that more clock rates are consumed on addition and multiplication. C++ is not the best choice for such programs.
So, if you work only with unsigned numbers, there is no problem with undefined behavior: everything is defined as modulo 2^N (where N is the number of bits for the selected type of number).
If you work with signed numbers, either use safe "wrappers" that reports errors. Or output limits on the input data of the whole program preventing the overflow. Don't forget to check those limits. It's easy, isn't it?
To output the limits, you need the debug assert macro with the correct overflow checks, which you should write. Or you need to enable the ubsan (the undefined behavior sanitizer) when you're building with Clang or GCC. You also need the test constexpr evaluations.
Also, the issue of undefined behavior during overflows affects the bit shifts to the left for negative numbers (or bit shifting for positive numbers to a sign bit). Starting with C++20, the standard requires a fixed single implementation of negative numbers. Now we should do it through two's complement. As a result, many shift issues evaporated. Nevertheless, we should still follow the general recommendation: perform any bit operations only in the unsigned types.
Two's complement is the most common way to represent signed integers (positive, negative, and zero) on computers. It enables you to replace subtraction with addition, and make addition and subtraction the same for signed and unsigned numbers.
To get the two's complement of the negative binary number, invert the binary modulo (it's the "Ones' complement") and add the value of 1 to the inversion (it's the "Two's complement").
The two's complement of the binary number is defined as the value obtained by subtracting the number from the greatest power of two.
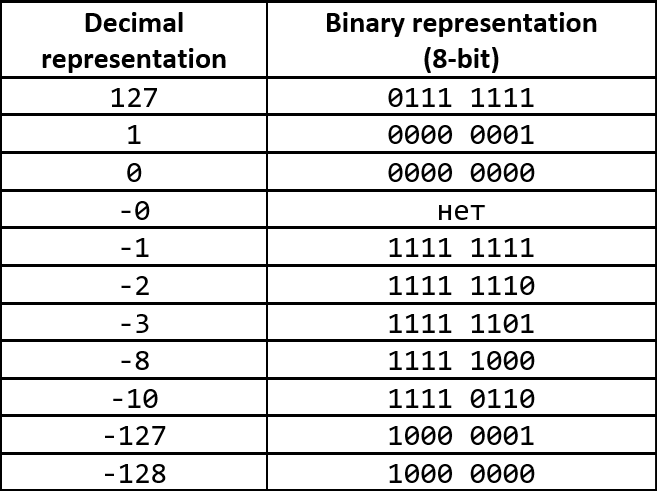
Note that the narrowing conversion from an integer type to another integer type doesn't lead to undefined behavior. There is no point in performing the bitwise AND masked conversion before assigning a variable of a smaller type. However, it's still preferable to avoid compiler warnings:
constexpr int x = 12345678;
constexpr uint8_t first_byte = x; // Implicit cast. WarningIt's very unpleasant when an integer variable overflows because of the integer promotion rules:
constexpr std::uint16_t IntegerPromotionUB(std::uint16_t x) {
x *= x;
return x;
}
// 65535 * 65535 mod 1<<16 = 1
static_assert(IntegerPromotionUB(65535) == 1); // won't compileAlthough an overflow is defined for unsigned types as taking a reminder modulo 2^n, and we use only an unsigned variable because of the integer promotion, in the example we get the overflow of the signed (!) number. As a result, we catch UB.
It happens only on platforms where int is larger than uint16_t. In other words, it happens everywhere these days.
x *= x; // it's rewritten as x = x * x;The uint16 type is smaller than the int type. An implicit conversion to int is performed for multiplication.
It's always complicated with float and double. Especially in C++.
The C++ standard doesn't require compliance with the IEEE 754 standard. So, people also consider the division by zero in real numbers as undefined behavior, even though IEEE 754 defines the x/0.0 expression as -INF, NaN, or INF depending on the sign of x (NaN for zero).
The comparison of real numbers is a favorite headache.
The x == y expression is actually a crooked bitwise comparison for floating-point numbers, which handles the cases -0.0 and +0.0, and NaN in a special way. Developers better forget about it and the operator!= of real numbers. It's better not to remember it ever again.
Just in case you inherited a large project and want to know how it handles the floating-point numbers comparison, you may use the PVS-Studio analyzer. It has the diagnostic rule V550: Suspicious precise comparison.
We should use memcmp for the bitwise comparison. To compare numbers, approximate variants of the form std::abs(x - y) < EPS, where EPS is some absolute or computed value based on x and y. As well as we should use various manipulations with the ULP of compared numbers.
Since the C++ standard does not force IEEE 754, the compiler can remove checks for x == NaN via its (x != x) == true property as obviously false. We should check it using the std::isnan functions designed for this purpose.
Whether IEEE 754 is supported or not can be checked using the predefined std::numeric_limits<FloatType>::is_iec559 constant.
Narrowing conversions from float to signed or unsigned integers may result in undefined behavior if the value is unrepresentable in the integer type. No modulo operation 2^N is assumed.
constexpr uint16_t x = 1234567.0; // CE, undefined behaviorThe reverse conversion (from integer types to float/double) also has its pitfalls, not related to undefined behavior: integers that are large in absolute value lose precision.
static_assert(
static_cast<float>(std::numeric_limits<int>::max()) == // OK
static_cast<float>(static_cast<long long>(
std::numeric_limits<int>::max()) + 1)
);
static_assert(
static_cast<double>((1LL << 53) - 1) == static_cast<double>(1LL << 53) // Fire!
);
static_assert(
static_cast<double>((1LL << 54) - 1) == static_cast<double>(1LL << 54) // OK
);
static_assert(
static_cast<double>((1LL << 55) - 1) == static_cast<double>(1LL << 55) // OK
);
static_assert(
static_cast<double>((1LL << 56) - 1) == static_cast<double>(1LL << 56) // OK
);As a homework assignment, try to think why you should never keep money in floating-point types on your own.
Before C++20, real numbers couldn't be used as non-type template parameters in templates. Now you can. However, you better not expect that you'll evaluate the same thing at run time and compile time.
The code is in C, but the point is the same. The first call to the expl function (raising the e number to the given power arg) is expanded into a constant, and the second is fairly computed:
#include <stdio.h>
#include <string.h>
#include <math.h>
static void printBits(size_t const size, void const * const ptr)
{
unsigned char *b = (unsigned char*) ptr;
unsigned char byte;
int i, j;
for (i = size * 8; i > 0; i--) {
if( i % 8 == 0)
{
printf("%d", i);
if( i >= 100) i-=2;
else if( i >= 10) i-=1;
}
else {printf(" ");}
}
printf("\n");
for (i = size * 8; i > 0; i--) {
if( i%8 == 0) {printf("|");} else {printf(" ");}
}
printf("\n");
for (i = size-1; i >= 0; i--) {
for (j = 7; j >= 0; j--) {
byte = (b[i] >> j) & 1;
printf("%u", byte);
}
}
printf("\n");
}
int main()
{
long double c, r1, r2;
r1 = expl(-1);
c = -1;
r2 = expl(c);
printBits(sizeof(r1), &r1);
printBits(sizeof(r2), &r2);
if( memcmp( &r1, &r2, sizeof(r1)) != 0 )
{
printf("Not equal!\n");
return 1;
}
printf("Equal!\n");
return 0;
}Let's take a look at the code result. There are also differences in run time and compile time evaluation options. Optimization keys also affect the result.
Here's the output using the x86-64 GCC 14.1 compiler:

Here's the output using the x86-64 GCC 14.1 compiler with the -O3 option:

This mechanism can be used for simple parametrization of types by constants without concern. However, it's highly discouraged to build pattern matching on them with a choice of template specializations.
template <double x>
struct X {
static constexpr double val = x;
};
template <>
struct X<+0.> {
static constexpr double val = 1.0;
};
template <>
struct X<-0.> {
static constexpr double val = -1.0;
};
int main() {
constexpr double a = -3.0;
constexpr double b = 3.0;
std::cout << X<a + b>::val << "\n"; // output +1
std::cout << X<-1.0 * (a + b)>::val << "\n"; // output -1
static_assert(a + b == -1.0 * (a + b)); // ok
}For the same reasons, no programming language recommends using floating-point values as keys for associative arrays.
C++ inherited a dead hand from C. One part of it was fixed and mercilessly removed for greater reliability. Developers did the same thing with the implicit const conversions. Another part, though, caused just as much trouble and remained unchanged.
In C and C++, there are many different integer types with different sizes—operations are defined for them. It's true that operations aren't defined for every type of number.
For example, there is no +, -, *, / for uint16_t. However, we can use them, and the result of operations on unsigned numbers will be a number with a sign.
uint16_t x = 1;
uint16_t y = 2;
auto a = x - y; // a is the int type
auto b = x + y; // b is the int type
auto c = x * y; // c is the int type
auto d = x / y; // d is the int typeThough, it's not the whole truth. If int is 16-bit, a, b, c, and d will be unsigned int. If you change the type of at least one argument to uint32_t, the result will immediately lose its sign.
Two implicit operations are going on:
Similar operations are performed on floating-point numbers. If you want to see the full table and chain showing what is implicitly transformed and into whom, you can check the standard.
1. Errors in logic. Implicit conversions are involved in any operation. Did you compare signed with unsigned numbers and forget to explicitly convert types? Be ready that -1 < 1 may return false:
std::vector<int> v = {1};
auto idx = -1;
if (idx < v.size()) {
std::cout << "less!\n";
} else {
std::cout << "oops!\n";
}unsigned short x=0xFFFF;
unsigned short y=0xFFFF;
auto z=x*y;The integer promotion implicitly casts x and y to int, where an overflow occurs. The int overflow is undefined behavior.
3. Problems with program porting from one platform to another. If the int/long size changes, the way the implicit conversion rules are applied to your code also changes:
std::cout << (-1L < 1U);The code outputs different values depending on the size of the long type.
Let's take the following simple structure:
// The example is taken and modified from here:
// https://twitter.com/hankadusikova/status/1626960604412928002
struct CharTable {
static_assert(CHAR_BIT == 8);
std::array<bool, 256> _is_whitespace {};
CharTable() {
_is_whitespace.fill(false);
}
bool is_whitespace(char c) const {
return this->_is_whitespace[c];
}
};This innocuous is_whitespace method is fine, isn't it? We expect that char in C and C++ usually has 8 bits, and Unicode has whitespace characters encoded with 16 bits.
Let's test it:
int main() {
CharTable table;
char c = 128;
bool is_whitespace = table.is_whitespace(c);
std::cout << is_whitespace << "\n";
return is_whitespace;
}When we build with -fsanitize=undefined, we get a marvelous result:
/opt/compiler-explorer/gcc-12.2.0/include/c++/12.2.0/array:61:36:
runtime error: index 18446744073709551488 out of bounds for type 'bool [256]'
/opt/compiler-explorer/gcc-12.2.0/include/c++/12.2.0/array:61:36:
runtime error: index 18446744073709551488 out of bounds for type 'bool [256]'
/app/example.cpp:14:38:
runtime error: load of value 64, which is not a valid value for type 'bool'The specific value in the third line is completely random. It would be really nice to consistently see 42, but alas.
Though, the index isn't random at all in the first two rows.
But wait, char c = 128, and that's definitely less than 256. Where does that 18446744073709551488 come from?
Let's break it down. The case involves two successfully laid traps:
pub fn main() {
let c : i8 = -5;
let c_direct_cast = c as u16;
let c_two_casts = c as u8 as u16;
println!("{c_direct_cast} != {c_two_casts}");
}We'll see 65531 != 251.
When we convert a signed integer of a shorter length to an unsigned integer of a longer length, the sign extension occurs: the most significant bits are filled with a sign bit.
This is the same case in C and C++:
int main() {
int8_t c = -5;
uint16_t c_direct_cast = c;
uint16_t c_two_casts = static_cast<uint8_t>(c);
std::cout << c_direct_cast << " != " << c_two_casts;
}It'll output: 65531 != 251.
Now we just have to look at the std::array::operator[] signature:
reference operator[]( size_type pos );We can see that size_type is an unsigned size_t. In x86, it's definitely larger than char. The direct cast of signed char into size_t occurs, the sign is expanded, and the code breaks. Case closed.
Static analyzers can sometimes help with sign extension. It's important to understand what we're doing when casting numbers and what we want to get. We can often spot the construction, like uint32_t extended_val = static_cast<uint32_t>(byte_val) & 0xFF. This way, we ensure that the upper bytes are zeroed out and avoid sign extension. The same construction can be true for the int32 -> uint64 conversion, and for any other combinations. Just don't forget to write the correct constant.
Since the type is unspecified in terms of characters, the char type is very dangerous when working with it as a number type. It's highly recommended to use the appropriate uint8_t or int8_t types. If your target platform suddenly doesn't have 8 bits in char, you can use other suitable ones instead.
The author: Dmitry Sviridkin
Dmitry has over eight years of experience in high-performance software development in C and C++. From 2019 to 2021, Dmitry Sviridkin has been teaching Linux system programming at SPbU and C++ hands-on courses at HSE. Currently works on system and embedded development in Rust and C++ for edge servers as a Software Engineer at AWS (Cloudfront). His main area of interest is software security.
Editor: Andrey Karpov
Andrey has over 15 years of experience with static code analysis and software quality. Author of many articles devoted to writing quality code in C++. Andrey Karpov has been honored with the Microsoft MVP award in the Developer Technologies category from 2011 to 2021. Andrey is a co-founder of the PVS-Studio project. He has long been the company's CTO and was involved in the development of the C++ analyzer core. Andrey is currently responsible for team management, personnel training, and DevRel activities.
0
0
0


0