
Our website uses cookies to enhance your browsing experience.

Let's imagine you have a perfect project. Tasks get done, your compiler compiles, static analyzers analyze, and releases get released. At some point, you decide to open an ancient file that nobody has opened in years, and you see that it's encoded in Windows-1251. Even though the whole project switched to UTF-8 a long time ago. You think, "That doesn't look right!" and with a flick of the wrist change the encoding. The next day, a local apocalypse hits your test server. Do you think such a thing can't happen? Well, let's discuss it, then.

The story of (not) successes
"That's how the cookie crumbles" is a marvelous phrase. It's a cure-all for junior programmer questions and a harbinger of trouble for experienced devs. In our project, this is the reason why a good part of the source code files is encoded in Windows-1251.
At some point, we got fed up with broken character issues, Doxygen, and so on. After all, it's already 2024! A need to convert files to UTF-8 has arisen. To make it easier for various utilities to automatically determine the encoding, we decided to add the BOM header to the conversion. We created a task and made some progress: the task was running, and files were being converted. No need for b*tthurt, it would seem. Well, it's not that simple.
At the same time, another programmer was working on a different task. The task was simple: we needed to edit some code in a header file. The programmer pitched in to ease their colleagues' workload. To do this, they converted the affected header file to the UTF-8 encoding with BOM and committed it. The consequences of the "small" fix hit the company the very next day: the build and all nightly tests were down, and the team leader was furious. We started looking into it.
When we looked at the compiler output, we found a lot of one definition rule (ODR) violation messages. I was under the impression that someone just forgot to add #pragma once to the header file. We started looking through the commits for the pinpoint where all the issues started, and we couldn't find it. All the fixes were simple and didn't add any new header files. However, after some time, we began to suspect a commit with a header file encoding change. Our suspicion turned to certainty when we created a minimal reproducible example.
It is a sample project with just a few files. The functions.h file is a precompiled header file containing the class and function declarations. It also contains #pragma once that protects against double inclusion. The functions.cpp and main.cpp files are translation units that include a precompiled header file.
The project seems to be a simple and error-free, but still doesn't compile. If we try to build the project using GCC (I checked the 12.2.0 and 13.2.0 versions), we see messages about the ODR violation.
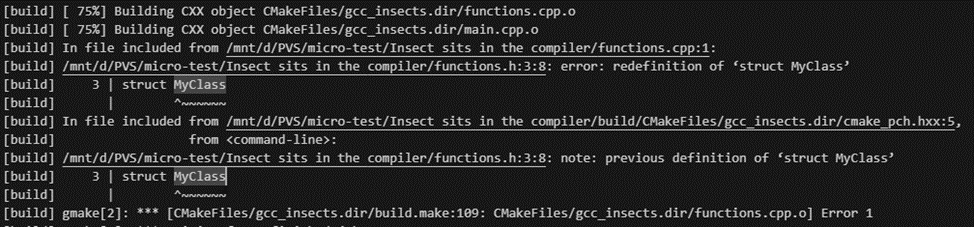
However, if we simply change the encoding of the functions.h file to UTF-8 without the BOM header, all compilation errors disappear. This is how GCC performs a disappearing trick. It's just a shame that #pragma once has gone from the project.
After searching for similar reports in the bug tracker, I found this one. There's even a recent post with a patch that may fix the bug. But it's been nothing so far. There have been no updates in four years, and the ticket status is still unconfirmed. The most interesting thing is that the ticket was created in 2013, and the bug has not been fixed yet.
What is it if not a b*tthurt?

Attentive users may say, "Wait, it's been only 11 years since 2013, so why did you write 13 years in the headline?" The thing is, the ticket has a duplicate, and it's two years older than the original.
GCC users may start defending their compiler by saying, "We have include guards. So, why do we need your pragma? You're just rambling here." Well, if you compile using only GCC and that's enough for you, then I have no questions for you. However, writing macros and #ifdef is less convenient than writing pragma. Although, if your product is cross-platform, and built for different compilers, then you are in trouble: you will either use only guards or write heavy #ifdef specifically for GCC.
Let's also not forget about third-party libraries that may have #pragma once. The header file from the third-party library may be fine. It may even have no BOM header and be in the encoding you need. And it may not even be pre-compiled. Your project will crash anyway, as soon as that header with pragma gets into another precompiled one. Into stdafx.h, for example.
It'd be good if you could find out what file is causing your build to crash. Because very often the precompiled header contains headers that contain headers that contain other headers, and so on. And the problem file may be at the very bottom of that hierarchy. Even if the mere presence of pragma doesn't crash your build, it can slow it down a lot due to the many inclusions of the header in translation units.
It's a "sore spot" for GCC pragma. In addition to the above, you may have problems with templates, and God knows what else. The sheer number of pragma-related bugs and the lack of fixes for them have created a cancel culture for pragma. Supporters of the GCC compiler often project their negative experience on other compilers and urge not to use #pragma once at all. They say it's unpredictable. Although it seems like a handy tool supported by many compilers.
Conclusion
It's been at least 13 years since the bug appeared in the compiler and four years since a possible fix was released. GCC, the time has come, don't you think?
Supporting users and fixing issues they face just in time is critical to business survival. At PVS-Studio, we devote a lot of time to user support. We strive to promptly deliver fixes to users so that they can make full use of the tool's features. For example, you can read another article I co-authored with my colleague about how we checked 278 gigabytes of logs.
If you'd like to learn about different types of bugs and how they can look like in code and in real cases, I invite you to read my colleagues' articles:
0
0
0


0