
Our website uses cookies to enhance your browsing experience.


Here's an interesting story about how one of the questions we ask at job interviews turned out to reach even deeper than intended by its author. You've always got to watch your step with C++ and C++ compilers – there's never a risk of getting bored.
Just like any other software developer company, we have our own lists of questions to ask applicants for C++, C#, and Java developer positions. Many of these questions are tricky, and quite a bit so. Well, we can't guarantee that with questions on C# and Java as they were devised by other authors. But many of the questions on C++ authored by Andrey Karpov were definitely aimed at probing the depth of the applicant's knowledge of language specifics.
There's a simple answer to any of those questions. But it can be elaborated to one degree or another. By the depth of the applicant's answer we can tell how well they know the language peculiarities. This is extremely important to us because developing a code analyzer requires a profound understanding of all the technicalities and "quirks" of the language.
Today's little story is about one of the first questions we ask at interviews and how it turned out to run even deeper than we intended. Now, we show this code to the applicant:
void F1()
{
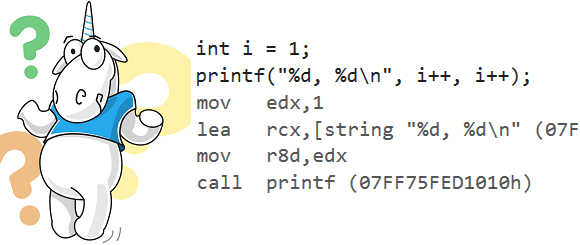
int i = 1;
printf("%d, %d\n", i++, i++);
}and ask him or her, "What do you think this code will print?"
That's a good question. The answer says a lot about the applicant's expertise. Those who are too incompetent to answer at all don't count – we have them filtered off through pre-interview testing on HeadHunter (hh.ru). Oh, wait... We actually had a couple odd applicants who replied something like this:
This code will first print a percent sign, then a d, then percent sign and d again, then backslash and n, and then two ones.
Needless to say, that was the end of the interview.
Now, back to our normal interviews :). Applicants will often say:
This code will print 1 and 2.
This is a trainee's answer. Sure, the program could print these values, but what we want to hear is something along these lines:
You can't say for sure what exactly this code will print. This is unspecified (or undefined) behavior. The order of evaluating the arguments is not defined. All the arguments are to be evaluated before the called function's body executes, but the exact order of their evaluation is compiler-specific. So this code might well output "1, 2" or "2, 1". In any case, it's strongly recommended not to write code like that if you build it with at least two compilers because you risk "shooting yourself in the foot". Many compilers would actually issue a warning on that.
Indeed, Clang may output "1, 2".
And GCC may output "2, 1".
A long time back, we tried the MSVC compiler, and it would print "2, 1" too. There was nothing to worry about.
But some time ago, we needed to compile that sample code using the modern version of Visual C++ for an entirely different reason. We built it in the Release configuration with the /O2 optimization level. We weren't seeking trouble but it found us anyway :). What do you think we got? Ha! We got "1, 1".
We could only wonder at what we saw. The problem turned out to be much more intricate than we could ever think.
Since the C++ standard does not prescribe an exact order of argument evaluation, the compiler interprets this type of unspecified behavior in a very peculiar way. Let's take a look at the assembly generated by the MSVC 19.25 compiler (Microsoft Visual Studio Community 2019, Version 16.5.1), with the standard version flag '/std:c++14' enabled:

Technically, the optimizer turned the code above into the following:
void F1()
{
int i = 1;
int tmp = i;
i += 2;
printf("%d, %d\n", tmp, tmp);
}From the compiler's point of view, this optimization doesn't alter the program's observable behavior. When I look at this, I begin to understand the point of adding the "magic" function make_shared, along with the smart pointers, in C++11 (and make_unique in C++14). Here's another seemingly harmless snippet that gets screwed up too:
void foo(std::unique_ptr<int>, std::unique_ptr<double>);
int main()
{
foo(std::unique_ptr<int> { new int { 0 } },
std::unique_ptr<double> { new double { 0.0 } });
}A crafty compiler may enforce the following evaluation order (which is what MSVC did):
new int { .... };
new double { .... };
std::unique_ptr<int>::unique_ptr
std::unique_ptr<double>::unique_ptrIf the second call of the new operator throws an exception, we'll get a memory leak.
But let's get back to the original example. Even though all was fine from the compiler's point of view, the string "1, 1" still didn't seem to be the right output from the programmer's perspective. So we compiled the source code with MSVC, with the '/std:c++17' flag on. This worked as expected, and the program printed "2, 1". Here's the assembly:

Now the compiler doesn't try to be original and passes the values 2 and 1 for the arguments, as expected. But why did changing the standard flag affect the code so drastically? It turns out the C++17 standard has the following addition:
The postfix-expression is sequenced before each expression in the expression-list and any default argument. The initialization of a parameter, including every associated value computation and side effect, is indeterminately sequenced with respect to that of any other parameter.
The compiler still has the right to evaluate arguments in an arbitrary order, but starting with the C++17 standard, it can move on to evaluate the next argument and its side effects no sooner than it has finished evaluating the previous argument and its side effects.
By the way, the '/std:c++17' flag helps fix that other example with smart pointers too, without having to use std::make_unique.
That's how we discovered another level of depth to the question. It's theory vs practice in the form of a specific compiler or differing interpretations of the standard :). The C++ world has always been much more complex and surprising than you might think.
If you have a more accurate explanation of that behavior, please let us know in the comments. We can't rest until we've figured it all out – if only to know the right answer before asking another applicant! :)
That's a story we all can learn from. I hope you enjoyed reading this, and please don't hesitate to share your opinion. We recommend using the most recent language standard if you don't want to be amazed at the tricks the modern optimizing compilers can do. Or better still – don't write code like that at all :).
P.S. You may think we'll have to drop this question from our list now that we "disclosed" it. But we don't see why we should do that. If the applicant took the trouble to read our articles before going to the interview and used what he or she had learned from this particular one, it would earn them a score for doing a good job and increase their chances to get hired :).
0
0
0
0