In this article, you're going to find 60 terrible coding tips — and explanations of why they are terrible. It's a fun and serious piece at the same time. No matter how terrible these tips look, they aren't fiction, they are real: we saw them all in the real programming world.
This is a new version of 50 terrible coding tips. Last time I wrote a separate article with the explanation of them. This was a mistake. First, the list was boring and tedious. Second, not everyone read the explanation — this fact almost eliminates the benefit of these tips.
I realized that not everyone had read the second article when I saw comments and questions. I had to reply with the same thing I wrote in the article. Now I have combined tips with explanations. Enjoy!
Real developers code only in C++!
There's nothing wrong with writing code in C++. The world has many projects written in C++. Well, for example, look at the list of apps from the home page of Bjarne Stroustrup.
Here is a list of systems, applications, and libraries that are completely or mostly written in C++. Naturally, this is not intended to be a complete list. In fact, I couldn't list a 1000th of all major C++ programs if I tried, and this list holds maybe 1000th of the ones I have heard of. It is a list of systems, applications, and libraries that a reader might have some familiarity with, that might give a novice an idea what is being done with C++, or that I simply thought "cool".
It's bad when developers use this language only because it's "cool" or because it's the only language the team knows.
The variety of programming languages reflects the variety of tasks that software developers face. Different languages help developers solve different classes of problems effectively.
The C++ language claims to be a versatile programming language. However, versatility doesn't guarantee that specific applications will be implemented quickly and easily. There may be languages that are a better fit for projects than others. An appropriate programming language can help implement a project without significant investments of time and effort.
But there's nothing wrong with developing a small additional utility in C++, although it would be more efficient for a team to use another language for this. The costs of learning a new programming language may exceed the benefits of using it.
The situation is different when a team needs to create a new, potentially large project. In this case, the team needs to discuss a few questions before choosing a programming language. Will the well-known C++ be effective for the project maintenance? Wouldn't it be better to choose another programming language for this project?
If the answer is yes, it's clearly more efficient to use another language, then probably it's better for the team to spend time learning this language. In the future, this can significantly reduce the cost of the project development and maintenance. Or maybe the project should be assigned to another team that already uses a more relevant language.
If you need a tab character in a string literal, feel free to press the tab key. Save \t for somebody else. No worries.
I'm talking about string literals where words should be separated from each other with a tab character:
const char str[] = "AAA\tBBB\tCCC";Seems like there's no other way to do it. Nevertheless, sometimes developers just carelessly press the TAB button, instead of using '\t'. This thing happens in real projects.
Such code compiles and even works. However, explicit use of a tab character is bad because:
Moreover, once I saw the code similar to this one in a real application:
const char table[] = "\
bla-bla-bla bla-bla-bla bla-bla-bla bla-bla-bla\n\
bla-bla-bla bla-bla-bla\n\
%s %d\n\
%s %d\n\
%s %d\n\
";The string is split into parts with the '\' character. Explicit tab characters are mixed with space characters. Unfortunately, I don't know how to show it here, but trust me — the code looked bizarre. The alignment from the beginning of the screen. Bingo! I've seen lots of strange things when developing a code analyzer :).
The code should have been written like this:
const char table[] =
"bla-bla-bla bla-bla-bla bla-bla-bla bla-bla-bla\n"
" bla-bla-bla bla-bla-bla\n"
" %s\t %d\n"
" %s\t %d\n"
" %s\t %d\n";You need tab characters to align the table regardless of the length of lines written in it. It is assumed that the lines are always short. For example, the code below:
printf(table, "11", 1, "222", 2, "33333", 3);will print:
bla-bla-bla bla-bla-bla bla-bla-bla bla-bla-bla
bla-bla-bla bla-bla-bla
11 1
222 2
33333 3Use nested macros everywhere. It's a good way to shorten code. You will free up hard drive space. Your teammates will have lots of fun when debugging.
You can read my thoughts on this topic in the following article: "Macro evil in C++ code".
You can open the link in a new tab and save it for later. Keep reading this article — by the end of it you'll have quite a collection of tabs with interesting material. Save it for the further reading :). By the way, make yourself a cup of tea or coffee. We're just getting started.
Disable compiler warnings. They distract from work and prevent you from writing compact code.
Developers know that the compiler warnings are their best friends. They help find errors even at the code compilation stage. Fixing an error found by a compiler is much easier and faster than debugging code.
However, once I discovered that some of the big project's components are compiled with warnings completely disabled.
I wrote new code, ran the application and noticed that it didn't behave as expected. Re-reading my code, I noticed an error and quickly fixed it. However, I was surprised that the compiler did not issue a warning. It was a very gross error, something like using an uninitialized variable. I knew for sure that a warning should be issued for such code, but there was none.
I did my research and found out that compiler warnings were disabled in the compiled DLL module (and some others as well). Then I contacted my senior teammates to investigate this thing.
It turned out that these modules have been compiling with disabled warnings for several years. Once one of the developers was instructed to migrate the build to a new compiler version. And they did it. The updated compiler started issuing new warnings — and lots of them on the legacy code of these modules.
I don't know what motivated the developer, but they simply disabled warnings in some modules. Maybe they wanted to do this temporarily so that warnings would not interfere with fixing compilation errors. But they forgot to turn the warnings back on. Unfortunately, it was impossible to get to the truth — by that time this person was no longer working at the company.
I turned the warnings back on and started refactoring the code so that the compiler wouldn't be triggered by anything. This didn't take me long. I spent one working day on it. But during the analysis of the warnings, I fixed a few more errors in the code that had remained unnoticed up to that point. Please, don't ignore the warnings issued by compilers and code analyzers!
Good tip
Try not to get any warnings when compiling the project. Otherwise, you'll see the broken windows theory in action. If you constantly see the same 10 warnings when compiling the code, then you will not pay attention when the 11th one appears. If not you, then your teammates will write the code for which warnings will be issued. If you think it's ok to have warnings, then this process will soon go out of control. The more warnings are issued during the compilation, the less attention is paid to the new ones.
Moreover, the warnings will gradually become meaningless. If you are used to the compiler constantly issuing warnings, you simply won't notice a new one that will report a real error in the newly written code.
Therefore, another good tip would be to tell the compiler to treat warnings as errors. So, your team will have zero tolerance to warnings. You will always eliminate or explicitly suppress warnings. Otherwise, the code won't compile at all. Such approach is beneficial for the code quality.
Of course, don't push this approach too hard:
Use one or two letters to name variables. This way you'll fit a more complex expression on one line on the screen.
Indeed, this way helps you write much shorter code. However, it'll be hard to read. In fact, the absence of normal variable names makes the code write-only. You can write it and even debug it right away, while you still remember what each variable means. But you won't understand a thing there after a while.
Another way to mess up the code is to use abbreviations instead of the normal variable names. Example: ArrayCapacity vs AC.
In the first case, it is clear that the variable means "capacity" — the size of the reserved memory in the container [1, 2]. In the second case, you'll have to guess what AC means.
Should you always avoid short names and abbreviations? No. Be considerate. You can name counters in loops like i, j, k. This is common practice, and any developer understands code with such names.
Sometimes abbreviations are appropriate. For example, in code implementing numerical methods, process modeling, etc. The code just does calculations using certain formulas described in the comments or documentation. If a variable in the formula is called SC0, then it is better to use this name in the code.
For example, here is the declaration of variables in the COVID-19 CovidSim Model project (I checked it once):
int n; /**< number of people in cell */
int S, L, I, R, D; /**< S, L, I, R, D are numbers of Susceptible,
Latently infected, Infectious,
Recovered and Dead people in cell */This is how you can name variables. The comments describe what they mean. This naming allows you to write formulas compactly:
Cells[i].S = Cells[i].n;
Cells[i].L = Cells[i].I = Cells[i].R = Cells[i].cumTC = Cells[i].D = 0;
Cells[i].infected = Cells[i].latent = Cells[i].susceptible + Cells[i].S;I'm not saying this is a good approach and style. But sometimes it is rational to give short names to variables. However, be careful with any recommendation, rule, and methodology. You should understand when to make an exception and when not.
Steve McConnell gives good arguments about how to name variables, classes, and functions in his book "Code Complete" (ISBN 978-0-7356-1967-8). Highly recommend to read it.
Use invisible characters in your code. Let your code work like magic. That's cool.
There are Unicode characters that may be invisible. Moreover, they can change the code representation in IDEs. Such character sequences may lead to the fact that the developer and the compiler would interpret the code differently. However, this can be done on purpose. This type of attack is called Trojan Source.
You can learn more about this topic in the following article: "Trojan Source attack for introducing invisible vulnerabilities". Truly, horror fiction for developers. You should definitely read it.
Here we analyzed the attack in more detail. Fortunately, the PVS-Studio analyzer can detect suspicious invisible characters.
Take another terrible tip. It might come in handy on April Fool's day. Apparently, there is the Greek question mark — U+037E, which looks like a semicolon (;).
When your teammate turns away, change any semicolon in their code to this character. Sit back and enjoy their reaction :) Everything will seem fine, but the code will not compile.
Use strange numbers. This way, the code of your program will look smarter and more impressive. Doesn't this code line look hardcore: qw = ty / 65 - 29 * s;?
If the program code contains numbers and their purpose is unknown and unclear, they are called magic numbers. Magic numbers are code smell. Over time, such code becomes hard to read, both for other developers and for the authors of the code.
A much better practice is to replace magic numbers with named constants and enumerations. However, this does not mean that each constant must be named. Firstly, there are 0 or 1 constants, whose use cases are obvious. Secondly, programs with mathematical calculations may suffer from naming each numeric constant. In this case, use comments to explain the formulas.
Unfortunately, one chapter isn't enough to describe the many ways to write clean and beautiful code. Want to dive deeper? Do turn to the amazingly thorough work by S. McConnell — "Code Complete" (ISBN 978-0-7356-1967-8). Moreover, there's a great discussion on Stack Overflow: What is a magic number, and why is it bad?
All old books recommend using int type variables to store array sizes and to construct loops. Let's keep it up! No reason to break with tradition.
For a long time, on many common platforms where the C++ language was used, an array could not contain more than INT_MAX elements.
For example, a 32-bit Windows program has a 2GB memory limit (actually, even less). So, the 32-bit int type was more than enough to store array sizes or to index arrays.
There were times when book authors and programmers confidently used int type counters in loops. And everything was fine.
However, in fact, the size of such types as int, unsigned, and even long may be not enough. At this point, programmers who use Linux may wonder: why is the size of long not enough? And here's the reason: for example, to build an app for the Windows x64 platform, MSVC compiler uses the LLP64 data model. In this model, the long type remains 32-bit.
So what types should you use? Memsize-types such as ptrdiff_t, size_t, intptr_t, uintptr_t are safe to store indexes or array sizes.
Let's look at a simple code example where a 32-bit counter that is used to process a large array in a 64-bit app leads to an error.
std::vector<char> &bigArray = get();
size_t n = bigArray.size();
for (int i = 0; i < n; i++)
bigArray[i] = 0;If the container has more than INT_MAX elements, the signed int variable overflows, which leads to undefined behavior. Moreover, you can never know where this undefined behavior will blow up. I reviewed a similarly compelling case in the following article: "Undefined behavior is closer than you think".
Here's one of the examples of correct code:
size_t n = bigArray.size();
for (size_t i = 0; i < n; i++)
bigArray[i] = 0;This code is even better:
std::vector<char>::size_type n = bigArray.size();
for (std::vector<char>::size_type i = 0; i < n; i++)
bigArray[i] = 0;Yeah, this code fragment seems a bit too long. And you may be tempted to use automatic type inference. Unfortunately, you can get incorrect code again:
auto n = bigArray.size();
for (auto i = 0; i < n; i++) // :-(
bigArray[i] = 0;The n variable will have the correct type, but the i counter won't. The 0 constant has the int type, which means that i will also have the int type. And we're back to where we started.
So how to iterate through elements correctly, while also keeping the code short? First, you can use iterators:
for (auto it = bigArray.begin(); it != bigArray.end(); ++it)
*it = 0;Second, you can use a range-based for loop:
for (auto &a : bigArray)
a = 0;The reader may say that all is good and well, but there's no need for this in their programs. Their code does not contain large arrays, so it's still okay to use int and unsigned variables. This may not work for two reasons.
First. This approach may be dangerous for the program's future. If the program doesn't use large arrays now, that does not mean it'll always be so. Another scenario: the code can be reused in another application, where the processing of large arrays is routine. For example, one of the reasons why the Ariane 5 rocket fell was the reuse of code written for the Ariane 4 rocket. The code was not designed for the new values of "horizontal speed". Here's the article: "A space error: 370.000.000 $ for an integer overflow"
Second. The use of mixed arithmetic may cause problems even if you work with small arrays. Let's look at code that works in the 32-bit version of the program, but not in the 64-bit one:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); // Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); // Access violation on 64-bit platformLet's see how the ptr + (A + B) expression is calculated:
The result of it depends on the pointer size on this particular architecture. If the addition takes place in a 32-bit program, the given expression will be an equivalent of ptr – 1, and we'll successfully print number 3. In the 64-bit program, the 0xFFFFFFFFu value will be added fairly to the pointer. The pointer will go out of array bounds. We'll face problems trying to access an element by this pointer.
If you find this topic interesting and would like to gain a better understanding of it, I recommend you explore the following:
Global variables are exceptionally convenient because you can access them from anywhere.
Since you can access global variables from anywhere, it is unclear where and when exactly they are accessed. This makes the program logic confusing, difficult to understand, and causes errors that are difficult to find through debugging. It is also difficult to check functions that use global variables with unit tests, because different functions have couplings between each other.
We're not talking about global constant variables in this case. They are constants, not variables, actually :).
We can endlessly discuss problems that global variables cause, but many books and articles already cover this topic. Here are some helpful materials to read about it:
So, to prove all that is serious, I suggest you read the article "Toyota: 81 514 issues in the code". One of the reasons why the code is so messy and buggy is the use of 9,000 global variables.
A tip for those who develop libraries: when in doubt, immediately terminate the program with the abort or terminate function.
Sometimes programs handle errors in a very simple way — they shutdown. If a program couldn't do something, for example, open a file or allocate memory — the abort, exit or terminate function is immediately called. This is acceptable behavior for some utilities and simple programs. And actually, it's up to the developers to decide how their programs would handle errors.
However, this approach is unacceptable if you are developing library code. You don't know what applications will use the code. The library code should return an error status or throw an exception. And it is up to the user to decide how to handle the error.
For example, a user of a graphic editor won't be happy if a library designed to print an image shuts down the application without saving the work results.
What if an embedded developer wants to use the library? Such manuals for embedded system developers as MISRA and AUTOSAR generally prohibit to call the abort and exit functions (MISRA-C-21.8, MISRA-CPP-18.0.3, AUTOSAR-M18.0.3).
If something doesn't work, most likely the compiler is acting up. Try swapping some variables and code lines.
Any experienced developer realizes that this tip is ridiculous. However, a programmer blaming the compiler for the incorrect operation of their program is not such a rare scene.
Sure, errors may occur in compilers, and you may face them. However, in 99% of cases, when someone says that "the compiler is buggy", they are wrong, and it's their code that is incorrect.
Most often, developers either do not understand some subtleties of the C++ language or have encountered undefined behavior. Let's take a look at the examples.
The first story arises from a discussion [RU] that took place on the linux.org.ru forum.
One developer complained about GCC 8's bug. However, as it turned out, it was incorrect code that led to undefined behavior. Now let's dive deeper in this case.
Note. In the original discussion, the s variable has the const char *s type. At the same time, on the author's target platform, the char type is unsigned. So, for clarity, I use a pointer of the const unsigned char * type in the code.
int foo(const unsigned char *s)
{
int r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return r & 0x7fffffff;
}The compiler does not generate code for the bitwise AND (&) operator. As a result, the function returns negative values. However, this is not the developer's intent, and it shouldn't be happening.
The developer believes that the compiler is to blame. The function doesn't work as intended because the undefined behavior occurs. But in this case, it's not the compiler's fault — the code is incorrect. The function doesn't work as intended because the undefined behavior occurs.
The compiler sees that the r variable is used to calculate and store a sum. It assumes that the r variable cannot overflow (according to the compiler). That would be considered undefined behavior, which the compiler should not analyze and take into account. So, the compiler assumes that the r variable cannot store a negative value after the loop is complete. Therefore, the r & 0x7fffffff operation, which sets off the sign bit, is unnecessary. So, the compiler simply returns the value of the r variable from the function.
That was an amusing story of a programmer who hasted to complain about the compiler. Based on this case, we implemented the new diagnostic rule in the PVS-Studio analyzer – V1026 – that helps to identify similar defects in the code.
To fix the code, you should simply use an unsigned variable to calculate the hash value:
int foo(const unsigned char *s)
{
unsigned r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return (int)(r & 0x7fffffff);
}The second story was previously mentioned here: "The compiler is to blame for everything." Once the PVS-Studio analyzer issued a warning for the following code:
TprintPrefs::TprintPrefs(IffdshowBase *Ideci,
const TfontSettings *IfontSettings)
{
memset(this, 0, sizeof(this)); // This doesn't seem to
// help after optimization.
dx = dy = 0;
isOSD = false;
xpos = ypos = 0;
align = 0;
linespacing = 0;
sizeDx = 0;
sizeDy = 0;
...
}The analyzer is right, while the author of code is not.
According to the comment, when optimization is enabled, the compiler is acting up and does not zero out the class data members.
After cussing the compiler out, the developer goes on to write the code which zeroing each class data member separately. Sadly, but most likely, the developer will be absolutely sure they have encountered a bug in the compiler. But, in fact, there has been a trivial careless mistake.
Pay attention to the third argument of the memset function. The sizeof operator calculates the size of the pointer, and not the size of the class. As a result, only part of the class is zeroed out. Without optimizations, apparently, all data members were always zeroed out and it seemed that the memset function worked correctly.
The correct calculation of the class size should look like this:
memset(this, 0, sizeof(*this));However, even the fixed version of the code cannot be called correct and safe. It stays that way as long as the class is trivially copyable. Everything can crash, for example, if you add some virtual function or a data member of a non-trivially copied type to the class.
Don't write code like that. I gave this example only because the previously described nuances pale in comparison to the error of the class size calculation.
That's exactly how legends about glitchy compilers and brave programmers fighting them are born.
Conclusion. Don't rush to blame the compiler if your code doesn't work. And don't try to make your program work by using various code modifications in the hope to "bypass the compiler's bug".
What you can do before blaming the compiler:
There's no time to explain — immediately use the command line arguments. Like that, for example: char buf[100]; strcpy(buf, argv[1]);. Checks are only for those who don't feel too confident about their own or their teammates' coding skills.
It's not only about a buffer overflow that may occur. Data processing without prior checks opens a Pandora's box full of vulnerabilities.
The problem of using unchecked data is a huge topic that goes beyond this discussion. If you are interested in delving deeper into this topic, you can start with the following:
Undefined behavior is just a scary bedtime story for children. Undefined behavior doesn't exist in real life. If the program works as you expected, it doesn't contain bugs. And there's nothing to discuss here, that's that. Everything is fine.
Enjoy! :)
Feel free to use the operator == to compare floating-point numbers. If there is such an operator, you need to use it.
Well, you can compare, can't you? However, the comparison has some nuances that need to be known and considered. Let's take a look at the example:
double A = 0.5;
if (A == 0.5) // True
foo();
double B = sin(M_PI / 6.0);
if (B == 0.5) // ????
foo();The first comparison A == 0.5 is true. The second comparison B == 0.5 may be both true and false. The result of the B == 0.5 expression depends upon the CPU, the compiler's version and the flags being used. For example, as I am writing this article, my compiler outputs code that calculates the value of the B variable to be 0.49999999999999994.
A better version of the code may look as follows:
double B = sin(M_PI / 6.0);
if (std::abs(b - 0.5) < DBL_EPSILON)
foo();In this case, the comparison with the error presented by DBL_EPSILON is true because the result of the sin function lies within the range [-1, 1]. C numeric limits interface:
DBL_EPSILON - difference between 1.0 and the next representable value for double respectively.
But if we handle values larger than several units, errors like FLT_EPSILON and DBL_EPSILON may be too small. And vice versa, if we handle values like 0.00001, these errors are too large. Each time, it's better to choose an error that is within the range of possible values.
But the question is still here. How do we compare two variables of the double type?
double a = ...;
double b = ...;
if (a == b) // how?
{
}There is no single correct answer. In most cases, you can compare two variables of the double type by writing the following code:
if (std::abs(a - b) <= DBL_EPSILON * std::max(std::abs(a),
std::abs(b)))
{
}But be careful with this formula, it only works for numbers with equal sign. Moreover, in a series with a large number of calculations, an error constantly occurs, and the DBL_EPSILON constant may have a value that is too small.
Well, is it even possible to compare floating-point values precisely?
In some cases, yes. But they are pretty limited. You may perform a comparison if the values being compared are in fact the same values.
Here is a case where a precise comparison is possible:
// -1 - a flag denoting that the variable's value is not set
double val = -1.0;
if (Foo1())
val = 123.0;
if (val == -1.0) // OK
{
}In this case, the comparison with the -1 value is possible because we previously initialized the variable with exactly the same value.
This comparison will be possible even if the number cannot be represented by a finite fraction. The following code will display "V == 1.0/3.0":
double V = 1.0/3.0;
if (V == 1.0/3.0)
{
std::cout << "V == 1.0/3.0" << std::endl;
} else {
std::cout << "V != 1.0/3.0" << std::endl;
}However, you have to be vigilant. If you only replace the type of the V variable with float, the condition will become false:
float V = 1.0/3.0;
if (V == 1.0/3.0)
{
std::cout << "V == 1.0/3.0" << std::endl;
} else {
std::cout << "V != 1.0/3.0" << std::endl;
}Now the code displays "V != 1.0/3.0". Why? The value of the V variable is 0.333333, and the 1.0/3.0 value is 0.33333333333333. Before comparison, the V variable, which has the float type, is expanded to the double type. The comparison is performed:
if (0.333333000000000 == 0.333333333333333)These numbers are obviously not equal. Anyway, be careful.
By the way, the PVS-Studio analyzer can detect all the operator == and operator !=, whose operands have a floating-point type, so that you can check this code again. Take a look at the V550 - Suspicious precise comparison diagnostic.
Here's some additional material:
memmove is a redundant function. Use memcpy always and everywhere.
The role of the memmove and memcpy functions is identical. However, there is an important difference. If the memory areas passed through the first two parameters partially overlap, the memmove function guarantees that the copy result is correct. In the case of memcpy, the behavior is undefined.
Let's say, you need to shift five bytes of memory by three bytes, as shown in the picture. Then:
You can also read the related discussion on Stack Overflow: memcpy() vs memmove().
So, why are there so many jokes about it if the behavior of these functions is so different? Turns out that the authors of many projects overlook some information about these functions in the documentation. Some distracted programmers were saved by the fact that in older versions of glibc, the memcpy function was an alias for memmove. Here's a note on this topic: Glibc change exposing bugs.
And that's how the Linux manual page describes it:
Failure to observe the requirement that the memory areas do not overlap has been the source of significant bugs. (POSIX and the C standards are explicit that employing memcpy() with overlapping areas produces undefined behavior.) Most notably, in glibc 2.13 a performance optimization of memcpy() on some platforms (including x86-64) included changing the order in which bytes were copied from src to dest.
This change revealed breakages in a number of applications that performed copying with overlapping areas. Under the previous implementation, the order in which the bytes were copied had fortuitously hidden the bug, which was revealed when the copying order was reversed. In glibc 2.14, a versioned symbol was added so that old binaries (i.e., those linked against glibc versions earlier than 2.14) employed a memcpy() implementation that safely handles the overlapping buffers case (by providing an "older" memcpy() implementation that was aliased to memmove(3)).
The size of int is always 4 bytes. Feel free to use this number. The number 4 looks much more elegant than an awkward expression with the sizeof operator.
The size of an int can differ significantly. The size of int is really 4 bytes on many popular platforms. But many – it doesn't mean all! There are systems with different data models. The size of int can be 8 bytes, 2 bytes, and even 1 byte!
Formally, here's what can be said about the size of int:
1 == sizeof(char) <=
sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)The pointer can just as easily differ from the size of the int type and 4. For example, on most 64-bit systems, the size of a pointer is 8 bytes, and the size of the int type is 4 bytes.
A fairly common pattern of 64-bit error is related to this. In old 32-bit programs, developers sometimes stored a pointer in variables of such types as int/unsigned. When such programs are ported on 64-bit systems, errors occur — when developers write the pointer value to a 32-bit variable, the highest bits are lost. See "Pointer packing" in "Lessons on the development of 64-bit C/C++ applications".
Additional links:
It makes no sense to check if memory was allocated. Modern computers have a great amount of memory. And if there is not enough memory to complete operations, there is no need for the program to continue working. Let the program crash. There's nothing more you can do anyway.
If the memory runs out, a computer game can crush. It's acceptable sometimes. The crash is unpleasant in this case, but it doesn't feel like the end of the world. Well, unless you are not participating in the gaming championship at this moment :).
But suppose a situation: you spent half a day doing a project in a CAD system. Suddenly, there is not enough memory for the next operation — the application crashes. It's much more unpleasant. If an application can't perform an operation, it's one thing, and it's quite another if it crashes without a warning. CAD and similar systems should continue working. At least, to give the opportunity to save the result.
There are several cases when it's unacceptable to write code that crashes if there isn't enough memory:
This topic largely overlaps with my article "Four reasons to check what the malloc function returned". I recommend reading it. Not everything is as simple and obvious as it seems at first glance with memory allocation errors.
Extend the std namespace with various additional functions and classes. After all, for you, these functions and classes are standard and basic.
Despite that such programs are successfully compiled and executed, the modification of the std namespace can lead to undefined behavior. The same goes for the posix namespace.
To make the situation clear, let me cite the V1061 diagnostic rule, which is designed to detect these invalid namespace extensions.
The contents of the std namespace is defined solely by the ISO committee, and the standard prohibits adding the following to it:
The standard does allow adding the following specializations of templates defined in the std namespace given that they depend on at least one program-defined type:
However, specializations of templates located inside classes or class templates are prohibited.
The most common scenarios when the user extends the std namespace are adding an overload of the std::swap function and adding a full/partial specialization of the std::hash class template.
The following example illustrates the addition of an overload of the std::swap function:
template <typename T>
class MyTemplateClass
{
....
};
class MyClass
{
....
};
namespace std
{
template <typename T>
void swap(MyTemplateClass<T> &a, MyTemplateClass<T> &b) noexcept // UB
{
....
}
template <>
void swap(MyClass &a, MyClass &b) noexcept // UB since C++20
{
....
};
}The first function template adds a new overload of std::swap, so this declaration will lead to undefined behavior. The second function template is a specialization, and the program's behavior is defined up to the C++20 standard. However, there is another way: we could move both functions out of the std namespace and place them to the one where classes are defined:
template <typename T>
class MyTemplateClass
{
....
};
class MyClass
{
....
};
template <typename T>
void swap(MyTemplateClass<T> &a, MyTemplateClass<T> &b) noexcept
{
....
}
void swap(MyClass &a, MyClass &b) noexcept
{
....
};Now, when you need to write a function template that uses the swap function on two objects of type T, you can write the following:
template <typename T>
void MyFunction(T& obj1, T& obj2)
{
using std::swap; // make std::swap visible for overload resolution
....
swap(obj1, obj2); // best match of 'swap' for objects of type T
....
}Now the compiler will select the required overload based on argument-dependent lookup (ADL): the user-defined swap functions for MyClass and for the MyTemplateClass template. The compiler will also select the standard std::swap function for all other types.
The next example demonstrates the addition of a specialization of the class template std::hash:
namespace Foo
{
class Bar
{
....
};
}
namespace std
{
template <>
struct hash<Foo::Bar>
{
size_t operator()(const Foo::Bar &) const noexcept;
};
}According to the standard, this code is valid, and so the analyzer does not issue the warning here. But starting with C++11, there is also another way to do this, namely by writing the class template specialization outside the std namespace:
template <>
struct std::hash<Foo::Bar>
{
size_t operator()(const Foo::Bar &) const noexcept;
};Unlike the std namespace, the C++ standard prohibits any modification of the posix namespace at all.
Here's some additional information:
Your teammates should know your extensive experience with the C language. Don't hesitate to show them your strong skills in manual memory management and in the usage of longjmp.
Another version of this tip: smart pointers and other RAII are from evil. Manage all resources manually — this makes code simple and comprehensible.
There's no reason to refuse smart pointers and use complex constructions when working with memory. Smart pointers in C++ don't require additional processing time. This is not garbage collection. Besides, smart pointers help shorten and simplify code, thus, reducing the risk of making a mistake.
Let's investigate why manual memory management is unreliable and tedious. We'll start with the simplest code in C where the memory is allocated and deallocated.
Note. In the examples, I only inspect memory allocation and deallocation. In fact, this is a huge topic of manual resource management. You can use, for example, fopen instead of malloc.
int Foo()
{
float *buf = (float *)malloc(ARRAY_SIZE * sizeof(float));
if (buf == NULL)
return STATUS_ERROR_ALLOCATE;
int status = Go(buf);
free(buf);
return status;
}The code is simple and clear. The function allocates memory for some purposes, uses it, and then deallocates. Additionally, you have to check whether malloc was able to allocate memory. Terrible tip N17 explains why this check is crucial in code.
Now imagine: you need to perform operations with two different buffers. The code immediately starts to grow — if the next memory allocation fails, you need to take care of the previous buffer. Moreover, now you have to consider the result of the Go_1 function.
int Foo()
{
float *buf_1 = (float *)malloc(ARRAY_SIZE_1 * sizeof(float));
if (buf_1 == NULL)
return STATUS_ERROR_ALLOCATE;
int status = Go_1(buf_1);
if (status != STATUS_OK)
{
free(buf_1);
return status;
}
float *buf_2 = (float *)malloc(ARRAY_SIZE_2 * sizeof(float));
if (buf_2 == NULL)
{
free(buf_1);
return STATUS_ERROR_ALLOCATE;
}
status = Go_2(buf_1, buf_2);
free(buf_1);
free(buf_2);
return status;
}It gets worse. The code grows non-linearly. With three buffers:
int Foo()
{
float *buf_1 = (float *)malloc(ARRAY_SIZE_1 * sizeof(float));
if (buf_1 == NULL)
return STATUS_ERROR_ALLOCATE;
int status = Go_1(buf_1);
if (status != STATUS_OK)
{
free(buf_1);
return status;
}
float *buf_2 = (float *)malloc(ARRAY_SIZE_2 * sizeof(float));
if (buf_2 == NULL)
{
free(buf_1);
return STATUS_ERROR_ALLOCATE;
}
status = Go_2(buf_1, buf_2);
if (status != STATUS_OK)
{
free(buf_1);
free(buf_2);
return status;
}
float *buf_3 = (float *)malloc(ARRAY_SIZE_3 * sizeof(float));
if (buf_3 == NULL)
{
free(buf_1);
free(buf_2);
return STATUS_ERROR_ALLOCATE;
}
status = Go_3(buf_1, buf_2, buf_3);
free(buf_1);
free(buf_2);
free(buf_3);
return status;
}Interestingly, the code is still not that complex. You can easily write and read it. However, something feels wrong about that. More than half of the code is almost useless — it just checks statuses and allocates/deallocates the memory. That's why, manual memory management is bad. A lot of necessary but irrelevant code lines.
Although the code is not complex, developers can easily make a mistake with its growth. For example, they might forget to release a pointer when exiting the function earlier and get a memory leak. We actually encounter this error in projects when we check them with PVS-Studio. Here's a code fragment from the PMDK project:
static enum pocli_ret
pocli_args_obj_root(struct pocli_ctx *ctx, char *in, PMEMoid **oidp)
{
char *input = strdup(in);
if (!input)
return POCLI_ERR_MALLOC;
if (!oidp)
return POCLI_ERR_PARS;
....
}The strdup function creates a copy of a string in a buffer. The buffer must be then released somewhere via the free function. Here, if the oidp argument is a null pointer, a memory leak will happen. The correct code should look like this:
char *input = strdup(in);
if (!input)
return POCLI_ERR_MALLOC;
if (!oidp)
{
free(input);
return POCLI_ERR_PARS;
}Or you can move the argument check to the beginning of the function:
if (!oidp)
return POCLI_ERR_PARS;
char *input = strdup(in);
if (!input)
return POCLI_ERR_MALLOC;Anyway, this is a classic error in code with manual memory management.
Let's return to the synthetic code with three buffers. Can it be simpler? Yes, with a single exit point pattern and goto operators.
int Foo()
{
float *buf_1 = NULL;
float *buf_2 = NULL;
float *buf_3 = NULL;
int status;
buf_1 = (float *)malloc(ARRAY_SIZE_1 * sizeof(float));
if (buf_1 == NULL)
{
status = STATUS_ERROR_ALLOCATE;
goto end;
}
status = Go_1(buf_1);
if (status != STATUS_OK)
goto end;
buf_2 = (float *)malloc(ARRAY_SIZE_2 * sizeof(float));
if (buf_2 == NULL)
{
status = STATUS_ERROR_ALLOCATE;
goto end;
}
status = Go_2(buf_1, buf_2);
if (status != STATUS_OK)
{
status = STATUS_ERROR_ALLOCATE;
goto end;
}
buf_3 = (float *)malloc(ARRAY_SIZE_3 * sizeof(float));
if (buf_3 == NULL)
{
status = STATUS_ERROR_ALLOCATE;
goto end;
}
status = Go_3(buf_1, buf_2, buf_3);
end:
free(buf_1);
free(buf_2);
free(buf_3);
return status;
}The code is much better now, and this is what C developers often do. I cannot call such code good and beautiful, but we have what we have. Manual resource management is scary anyway...
By the way, some compilers support special extension for the C language that can greatly simplify the life of a developer. You can use constructions of the following form:
void free_int(int **i) {
free(*i);
}
int main(void) {
__attribute__((cleanup (free_int))) int *a = malloc(sizeof *a);
*a = 42;
} // No memory leak, free_int is called when a goes out of scopeRead more about this magic here: RAII in C: cleanup gcc compiler extension.
Now let's go back to the terrible tip. The problem is, some developers still use manual memory management in C++ code even when it makes no sense! Don't do this. C++ allows to shorten and simplify the code.
You can use containers like std::vector. Even if you need an array of bytes allocated with the operator new [], you can make the code way better.
int Foo()
{
std::unique_ptr<float[]> buf_1 (new float[ARRAY_SIZE_1]);
if (int status = Go_1(buf_1); status != STATUS_OK)
return status;
std::unique_ptr<float[]> buf_2(new float[ARRAY_SIZE_2]);
if (int status = Go_2(buf_1, buf_2); status != STATUS_OK)
return status;
std::unique_ptr<float[]> buf_3(new float[ARRAY_SIZE_3]);
reutrn Go_3(buf_1, buf_2, buf_3);
}Gorgeous! You don't need to check the result of calling the operator new [] — an exception will be thrown in case of a buffer creation error. Buffers are released automatically if exceptions occur or when the function exits normally.
So, what's the point of writing in C++ the old way? None. Why do we still meet such code? I think there are several answers.
First. The developers do it out of habit. They don't want to learn something new and change their coding patterns. In fact, they write code in C with a bit of additional functionality from C++. It's sad, and I don't know how to fix it.
Second. Below is C++ code that used to be code in C. It was slightly changed, but it wasn't rewritten or refactored. That is, malloc was simply replaced with new, and free was replaced with delete. Such code can be easily recognized by two artifacts.
Firstly, look at these checks — they are atavisms:
in_audio_ = new int16_t[AUDIO_BUFFER_SIZE_W16];
if (in_audio_ == NULL) {
return -1;
}It makes no sense to check the pointer for NULL. In case of a memory allocation error, an exception of the std::bad_alloc type will be thrown. It's a custom atavism. Of course, there's new(std::nothrow), but it's not our case.
Secondly, there's often the following error: memory is allocated using the operator new [], and deallocated using delete. Although it is more correct to use delete []. See "Why do arrays have to be deleted via delete [] in C++". Example:
char *poke_data = new char [length + 2*sizeof(int)];
....
delete poke_data;Third. Fear of overheads. There are no reasons to fear them. Yes, smart pointers can sometimes have overheads, but they are minor compared to simple pointers. However, keep in mind:
Additional links:
Fourth. Developers are simply unaware of how, for example, std::unique_ptr can be used. They probably think like this:
OK, I have std::unique_ptr. It can control a pointer to the object. But I still need to work with arrays of objects. And then there are file descriptors. In some places, I am even forced to continue using malloc/realloc. For all this, unique_ptr is not suitable. So, it's easier to continue managing resources manually everywhere.
Everything that is described can very well be controlled with std::unique_ptr.
// Working with arrays:
std::unique_ptr<T[]> ptr(new T[count]);
// Working with files:
std::unique_ptr<FILE, int(*)(FILE*)> f(fopen("a.txt", "r"), &fclose);
// Working with malloc:
struct free_delete
{
void operator()(void* x) { free(x); }
};
....
std::unique_ptr<int, free_delete> up((int*)malloc(sizeof(int)));That's it. I hope I addressed all the doubts you may have had.
P.S. I haven't written anything about longjmp. And I don't see the point in it. In C++, exceptions should be used for this purpose.
Use as few curly brackets and line breaks as possible. Try to write conditional constructs in one line. This will reduce the code size and make the code compile faster.
The code will be shorter — it's undeniable. It's also undeniable that the code will contain more errors.
"Shortened code" is harder to read. This means that typos are more likely not to be noticed by the author of the code and by colleagues during code review. Do you want proof? Easy!
Once, a user emailed us that the PVS-Studio analyzer was producing strange false positives for the condition. Here's a picture attached to the email:
Can you spot the bug? Probably not. Do you know why? Because we have a big complex expression written in one line. It's difficult to read and understand this code. I bet you did not try to find the bug and continued reading the article :).
But the analyzer wasn't too lazy to bother trying. It correctly indicated an anomaly: some of the subexpressions are always true or false. Let's refactor the code:
if (!((ch >= 0x0FF10) && (ch <= 0x0FF19)) ||
((ch >= 0x0FF21) && (ch <= 0x0FF3A)) ||
((ch >= 0x0FF41) && (ch <= 0x0FF5A)))Now it's much easier to notice that the logical NOT (!) operator is applied only to the first subexpression. Well, we just need to write additional parentheses. A more detailed story about this bug is here: "How PVS-Studio proved to be more attentive than three and a half programmers".
In our articles, we recommend formatting complex code as a table. You can see this formatting style just above. Table-style formatting does not guarantee the absence of typos, but it makes them easier and faster to notice.
I'll illustrate this topic with another example. Let's inspect the code fragment from the ReactOS project. PVS-Studio issued the following warning on it: V560 A part of conditional expression is always true: 10035L.
void adns__querysend_tcp(adns_query qu, struct timeval now) {
...
if (!(errno == EAGAIN || EWOULDBLOCK ||
errno == EINTR || errno == ENOSPC ||
errno == ENOBUFS || errno == ENOMEM)) {
...
}This is a small code fragment — it's not hard to find an error here. However, it may be much harder to notice it in real code. You may simply skip the block of the same type of comparisons and go on.
The reason why we don't notice such errors is that the conditions are poorly formatted. We don't want to read them carefully, it takes effort. We just hope that since the checks are of the same type, then everything will be fine — the author of the code did not make mistakes in the condition.
One of the ways to deal with typos is the table-style formatting.
For those readers who want to know where the error is but don't want to search it themselves — "errno ==" is missing in one place. As a result, the condition is always true, since the EWOULDBLOCK constant is 10035. Here's the correct code:
if (!(errno == EAGAIN || errno == EWOULDBLOCK ||
errno == EINTR || errno == ENOSPC ||
errno == ENOBUFS || errno == ENOMEM)) {Now let's inspect how to refactor this fragment better. First, I'll show you the code designed in the simplest table style. I don't like it.
if (!(errno == EAGAIN || EWOULDBLOCK ||
errno == EINTR || errno == ENOSPC ||
errno == ENOBUFS || errno == ENOMEM)) {It got better but not that much. I don't like this style because of two reasons:
That's why we need to enhance code formatting. Firstly, no more than one comparison per line, then the error is easy to notice. Indeed, the error has become more conspicuous:
a == 1 &&
b == 2 &&
c &&
d == 3 &&Secondly, it's better to write operators &&, ||, etc. rationally — not on the right but on the left.
Notice how much work it is to write spaces:
x == a &&
y == bbbbb &&
z == cccccccccc &&But this way there is much less work:
x == a
&& y == bbbbb
&& z == ccccccccccThe code looks unusual, but you'll get used to it.
Let's combine it all together and write the code given above in a new style:
if (!( errno == EAGAIN
|| EWOULDBLOCK
|| errno == EINTR
|| errno == ENOSPC
|| errno == ENOBUFS
|| errno == ENOMEM)) {Yes, the code now takes up more lines of code, but the error is much more noticeable.
I agree, the code looks unusual. However, I recommend this approach. I have been using it for many years and am very satisfied, so I confidently recommend it to all readers.
The fact that the code has become longer is not a problem at all. I would even write something like this:
const bool error = errno == EAGAIN
|| errno == EWOULDBLOCK
|| errno == EINTR
|| errno == ENOSPC
|| errno == ENOBUFS
|| errno == ENOMEM;
if (!error) {Is someone grumbling that it's long and clutters up the code? I agree. So, let's put it into a function!
static bool IsInterestingError(int errno)
{
return errno == EAGAIN
|| errno == EWOULDBLOCK
|| errno == EINTR
|| errno == ENOSPC
|| errno == ENOBUFS
|| errno == ENOMEM;
}
....
if (!IsInterestingError(errno)) {It may seem that I am exaggerating and that I am too perfectionist, but errors in complex expressions are very common. I wouldn't have remembered them if I hadn't come across them all the time: these errors are everywhere and poorly visible.
Here is another example from the WinDjView project:
inline bool IsValidChar(int c)
{
return c == 0x9 || 0xA || c == 0xD ||
c >= 0x20 && c <= 0xD7FF ||
c >= 0xE000 && c <= 0xFFFD ||
c >= 0x10000 && c <= 0x10FFFF;
}There are only a few lines in the function, and still an error crept into it. The function always returns true. The problem is that it is poorly designed. For many years, developers have been skipping it while reviewing, and haven't noticed a mistake there.
Let's refactor the code in the table style. I'd add more brackets:
inline bool IsValidChar(int c)
{
return
c == 0x9
|| 0xA
|| c == 0xD
|| (c >= 0x20 && c <= 0xD7FF)
|| (c >= 0xE000 && c <= 0xFFFD)
|| (c >= 0x10000 && c <= 0x10FFFF);
}It's not necessary to format the code exactly as I suggest. The point of this note is to draw attention to typos in "chaotic code". By formatting code in table style, you can avoid a lot of silly typos. And this is great. I hope this note will help someone.
A fly in the ointment. I am an honest developer, and that's why, I must mention that sometimes table-style formatting can be harmful. Here is an example:
inline
void elxLuminocity(const PixelRGBi& iPixel,
LuminanceCell< PixelRGBi >& oCell)
{
oCell._luminance = 2220*iPixel._red +
7067*iPixel._blue +
0713*iPixel._green;
oCell._pixel = iPixel;
}This is the eLynx SDK project. The developer wanted to align the code, so they added 0 to 713. Unfortunately, the developer forgot that 0 at the beginning of a number meant it would be represented in octal format.
Array of strings. I hope the concept of table-style formatting is clear now. However, why don't we review it once again? Let's inspect one code fragment. It illustrates that table-style formatting can be applied to all language constructs, not just conditions.
The code fragment is taken from the Asterisk project. The PVS-Studio analyzer issued the following warning: V653 A suspicious string consisting of two parts is used for array initialization. It is possible that a comma is missing. Consider inspecting this literal: "KW_INCLUDES" "KW_JUMP".
static char *token_equivs1[] =
{
....
"KW_IF",
"KW_IGNOREPAT",
"KW_INCLUDES"
"KW_JUMP",
"KW_MACRO",
"KW_PATTERN",
....
};A typo — one comma is forgotten. As a result, two lines different in meaning are combined into one. In fact, that's what is written here:
....
"KW_INCLUDESKW_JUMP",
....The error could have been avoided by using table-style formatting. In this case, the developer can easily notice a missed comma.
static char *token_equivs1[] =
{
....
"KW_IF" ,
"KW_IGNOREPAT" ,
"KW_INCLUDES" ,
"KW_JUMP" ,
"KW_MACRO" ,
"KW_PATTERN" ,
....
};Let me remind you that if we put a separator on the right (in this case, it's a comma), then we have to add a lot of spaces, which is inconvenient. Especially if you add a new long line/expression — you'll have to reformat the whole table.
Therefore, it's better to format the code like this:
static char *token_equivs1[] =
{
....
, "KW_IF"
, "KW_IGNOREPAT"
, "KW_INCLUDES"
, "KW_JUMP"
, "KW_MACRO"
, "KW_PATTERN"
....
};Now you can easily notice a missing comma and avoid adding spaces. The code looks neat and comprehensible. Perhaps, such formatting may be unusual to you, but I urge you to try this format — you'll quickly get used to it.
Remember: beautiful code is correct code.
Never test anything. And don't write tests. Your code is perfect, what's there to test? It's not for nothing that you are real C++ programmers.
I think the reader understands the irony, and no one seriously wonders why this tip is terrible. But there is an interesting point here. By agreeing that programmers make mistakes, you most likely think that this applies to you to a lesser degree. After all, you are an expert, and on average you understand better than others how to program and test.
We all have a condition of cognitive bias — "illusory superiority". Moreover, from my life experience, programmers are more susceptible to it :). Here's an interesting article on this topic: The Problem With 'Above Average Programmers'.
Don't use static analyzers. These are tools for students and losers.
In fact, it's the other way around. First of all, professional developers use static analyzers to improve the quality of their software projects. They value static analysis, because it allows to find bugs and zero-day vulnerabilities at early stages. After all, the earlier a code defect is detected, the cheaper it is to eliminate.
What's interesting is that a student has a chance to write a high-quality program as part of a course project. And they can well do it without static analysis. But it is impossible to write a project as big as a game engine without bugs. The thing is that with the growth of the codebase, the error density increases. To maintain the high quality of code, you need to spend a lot of effort and use various methodologies, including code analysis tools.
Let's find out what the error density increase means. The larger the codebase size, the easier it is to make a mistake. The number of errors increases with the growth of the project size not linearly, but exponentially.
A person can no longer keep the whole project in mind. Each programmer works only with some part of the project and the codebase. As a result, the programmer cannot foresee all the consequences that may arise if they change some code fragment during the development process. In layman's terms: something is changed in one place, something breaks in another.
In general, the more complex the system is, the easier it is to make a mistake. This is confirmed by numbers. Let's look at the following table, taken from the "Code Complete" book by Stephen McConnell.
Static code analysis is a good assistant for programmers and managers who care about the project quality and its speed development. Regular use of analysis tools reduces the error density, and this generally has a positive effect on productivity. From the book by David Anderson "Kanban: Successful Evolutionary Change for Your Technology Business":
Capers Jones reports that in 2000, during the dot-com bubble, he evaluated the quality of programs for North American teams. The quality ranged from six errors per function point to less than three errors per 100 function points — 200 to one. The midpoint is approximately one error per 0.6–1.0 functional point. Thus, teams usually spend more than 90% of their efforts on fixing errors. There is also direct evidence of this. In late 2007, Aaron Sanders, one of the first followers of Kanban, wrote on the Kanbandev mailing list that the team he worked with spent 90% of the available productivity on bug fixes.
Striving for inherently high quality will have a serious impact on the performance and throughput of teams that make many errors. You can expect a two to fourfold increase in throughput. If the team is initially lagging behind, then focusing on quality allows you to increase this indicator tenfold.
Use static code analyzers, for example — PVS-Studio. Your team will be more engaged in interesting and useful programming, rather than guessing why the code doesn't work as planned.
By the way, all written above doesn't mean that static code analyzers are useless for students. Firstly, a static analyzer detects errors and low-quality code. It helps master the programming language faster. Secondly, skills of working with code analyzers may be useful in the future, when you'll work with large projects. The PVS-Studio team understands this and provides students with free license.
Additional links:
Always and everywhere deploy any changes immediately to production. Test servers are a waste of money.
This is a universal terrible tip that is applicable to development in any programming language.
I don't know what else to write here that is clever and helpful. The harm of this approach is obvious. That, however, does not prevent some people from following this approach :)
I think some interesting cautionary tale would be appropriate here. But I don't have one. Maybe some of our readers have something to say on this topic. And then I'll add your responses here :).
Everyone is just dreaming of helping you. So, it's worth asking on Stack Overflow/Reddit "why isn't my code working?", and everyone is ready to overcome any barriers to answer your question.
This terrible tip is meant for those who have come to Stack Overflow, Reddit or some other forum for help. The community is quite loyal to help newcomers, but sometimes it seems that those asking the question do their best to be ignored. Let's look at a question I saw on Reddit.
Subject: Can someone explain to me why I have a segmentation fault?
The question's body: A link to a document located in the OneDrive cloud storage.
This is a good example of how not to ask questions.
It's an extremely inconvenient way to show your code. Instead of reading the necessary code immediately in the body of the question, one need to follow the link. The OneDrive website required me to log in, but I was too lazy to do so. I wasn't that interested in the code. By the lack of answers to the question, I wasn't the only one who was lazy. Moreover, many people don't have an account on OneDrive at all.
It is not even clear what programming language they are talking about. Is it worth looking at the code, if it may turn out that you don't work with this programming language...
The question is not specific. I never found out what the code fragment was, but I suspect the fragment might not have been enough to give an answer. The question does not contain any additional information. Don't do that.
I will try to formulate the question in a way that others can help you.
The main idea. Let those you are asking for an answer be comfortable!
The question should be self-sufficient. It should contain all the necessary information so that those who want to help do not need to ask clarifying questions. Often the questioners fall into a mental error, believing that everything will be clear to everyone anyway. Remember, people who help you don't know what your functions and classes do. Therefore, don't be lazy to describe all the functions/classes that are relevant. I mean, to show how they work and/or describe them in words.
Ideally, you should provide a minimal piece of code so that people can reproduce the problem. Yes, it does not always work out, but it is extremely useful for three reasons:
Additional links:
The C++ language allows to perform virtual inheritance and implement diamond inheritance with it. So why not to use such a cool thing!
You can use it. You just need to know about some subtleties. Let's take a look at them.
First, let's talk about how classes are allocated without virtual inheritance. Here's a code fragment:
class Base { ... };
class X : public Base { ... };
class Y : public Base { ... };
class XY : public X, public Y { ... };That one's easy. The members of the non-virtual base Base class are allocated as common data members of the derived class. It results in the XY object containing two independent Base subobjects. Here is a scheme to illustrate that:
Figure 25.1. Multiple non-virtual inheritance.
An object of a virtual base class is included into the object of a derived class only once. This is also called diamond inheritance:
Figure 25.2. Diamond inheritance
Figure 25.3 shows the layout of the XY object in the code fragment below with diamond inheritance.
class Base { ... };
class X : public virtual Base { ... };
class Y : public virtual Base { ... };
class XY : public X, public Y { ... };Figure 25.3. Multiple virtual inheritance.
The memory for the shared Base subobject is most likely to be allocated at the end of the XY object. The exact implementation of the class depends on the compiler. For example, X and Y classes can store pointers to the shared Base object. But, as I understand, this method is out of use nowadays. More often, a reference to a shared subobject is implemented as an offset or as information that is stored in the vtable.
The "most derived" XY class alone knows where exactly the memory for the subobject of the virtual Base class should be located. Therefore, it is the most derived class which is responsible for initializing all the subobjects of virtual base classes.
The XY constructors initialize the Base subobject and pointers to it in X and Y. After that, the remaining members of X, Y, XY classes are initialized.
Once the Base subobject is initialized in the XY constructor, it will not be re-initialized by the X or Y constructors. The particular way it will be done depends on the compiler. For example, the compiler can pass a special additional argument into X and Y constructors to tell them not to initialize the Base class.
Now the most interesting thing that leads to many misunderstandings and errors. Let's look at the following constructors:
X::X(int A) : Base(A) {}
Y::Y(int A) : Base(A) {}
XY::XY() : X(3), Y(6) {}What number will the base class constructor take as its argument — 3 or 6? None of them.
The XY constructor initializes the Base virtual subobject, but does this implicitly. By default, Base constructor is called.
When the XY constructor calls the X or Y constructor, it does not reinitialize Base. So, there is no explicit reference to Base with some argument.
Troubles with virtual base classes do not end here. Besides constructors, there are also assignment operators. If I'm not mistaken, the standard tells us that the compiler-generated assignment operator can assign to a subobject of a virtual base class multiple times. Or maybe the operator can only do it once. So, you don't know how many times the Base object will be copied.
If you implement your own assignment operator, make sure you have prevented multiple copying of the Base object. Let's look at the incorrect code fragment:
XY &XY::operator =(const XY &src)
{
if (this != &src)
{
X::operator =(*this);
Y::operator =(*this);
....
}
return *this;
}This code leads to double copy of the Base object. To avoid this, we should add special functions into the X and Y classes to prevent copying of the Base class's members. The contents of the Base class are copied once here as well. Here's the fixed code:
XY &XY::operator =(const XY &src)
{
if (this != &src)
{
Base::operator =(*this);
X::PartialAssign(*this);
Y::PartialAssign(*this);
....
}
return *this;
}This code will work well, but it still doesn't look nice and clear. That's the reason why programmers are recommended to avoid multiple virtual inheritance.
Because of the specifics of how virtual base classes are allocated in memory, you can't perform type conversions like this one:
Base *b = Get();
XY *q = static_cast<XY *>(b); // Compilation error
XY *w = (XY *)(b); // Compilation errorHowever, an insistent programmer can still convert the type by employing the 'reinterpret_cast' operator:
XY *e = reinterpret_cast<XY *>(b);However, the result will hardly be of any use. The address of the beginning of the Base object will be interpreted as the beginning of the XY object. And this is not what you need at all. See Figure 25.4 for details.
The only way to perform a type conversion is to use the dynamic_cast operator. But using dynamic_cast too often makes the code smell.
Figure 25.4. Type conversion.
I agree with many authors that one should avoid virtual inheritance by all means, as well as common multiple inheritance.
Virtual inheritance causes troubles with object initialization and copying. Since it is the "most derived" class which is responsible for these operations, it has to be familiar with all the very detail of the structure of base classes. Due to this, a more complex dependency appears between the classes, which complicates the project structure and forces you to make some additional revisions in all those classes during refactoring. All this leads to bugs and complicates the understanding of the project by new developers.
The complexities of type conversion also lead to errors. You can partly solve the issues by using the dynamic_cast operator. However, this is a slow operator. And if the operator begins to widely appear in the program, then, most likely, this indicates a poor project architecture. Project structure can be almost always implemented without multiple inheritance. After all, there are no such exotica in many other languages. And it doesn't prevent programmers writing code in these languages from developing large and complex projects.
We cannot insist on total refusal of virtual inheritance. Sometimes it is useful and convenient. However, it's better to think twice before using it.
Well, we now understand the criticism of multiple virtual inheritance and multiple inheritance as such. But are there any cases where this kind of inheritance is safe and convenient to use?
Yes, I can name at least one: mix-ins. If you don't know what it is, see the book "Enough Rope to Shoot Yourself in the Foot". You can easily find it on the Internet. Start reading at section 101 and further on.
A mix-in class doesn't contain any data. All its functions are usually pure virtual. It has no constructor, and even when if it has, the constructor doesn't do anything. It means that no troubles will occur when creating or copying these classes.
If a base class is a mix-in class, assignment is harmless. So, even if an object is copied many times, it doesn't matter. The program will be free of it after compilation.
Do not use the language's standard library. What could be more interesting than writing your own strings and lists with unique syntax and semantics?
Maybe it's really interesting. However, it's a time-consuming process. Moreover, the result is likely to be of lower quality than the existing standard solutions. In practice, it turns out that it's not easy to write even analogues of such simple functions as strdup or memcpy without errors. Now imagine the number of flaws that are going to be in more complex functions and classes.
Don't believe me about strdup and memcpy? The thing is, I've started collecting errors found in custom data copying functions long ago. Perhaps someday I'll make a separate article about that. And now, a couple of proofs.
In the article about checking Zephyr RTOS, I described an unsuccessful attempt to implement a function similar to strdup:
static char *mntpt_prepare(char *mntpt)
{
char *cpy_mntpt;
cpy_mntpt = k_malloc(strlen(mntpt) + 1);
if (cpy_mntpt) {
((u8_t *)mntpt)[strlen(mntpt)] = '\0';
memcpy(cpy_mntpt, mntpt, strlen(mntpt));
}
return cpy_mntpt;
}PVS-Studio warning: V575 [CWE-628] The 'memcpy' function doesn't copy the whole string. Use 'strcpy / strcpy_s' function to preserve terminal null. shell.c 427
The analyzer detects that the memcpy function copies a string, but doesn't copy terminal null, and it's strange. Seems like terminal null is copied here:
((u8_t *)mntpt)[strlen(mntpt)] = '\0';No, it's a typo that causes null character to be copied into itself. Note that the null character is written into the mntpt array, not in cpy_mntpt. As a result, the mntpt_prepare function returns a non-null-terminated string.
Actually, the developer wanted to write something like this:
((u8_t *)cpy_mntpt)[strlen(mntpt)] = '\0';It's unclear why the code is written in such a confusing way. As a result, a grave error crept into a small function. The code can be simplified like this:
static char *mntpt_prepare(char *mntpt)
{
char *cpy_mntpt;
cpy_mntpt = k_malloc(strlen(mntpt) + 1);
if (cpy_mntpt) {
strcpy(cpy_mntpt, mntpt);
}
return cpy_mntpt;
}And here's another example where developers wonder if they're right:
void myMemCpy(void *dest, void *src, size_t n)
{
char *csrc = (char *)src;
char *cdest = (char *)dest;
for (int i=0; i<n; i++)
cdest[i] = csrc[i];
}We were not analyzing this code fragment with the help of PVS-Studio — I accidentally came across it on Stack Overflow: C and static Code analysis: Is this safer than memcpy?
However, if we check this function with PVS-Studio, it'll issue the following:
Indeed, this code fragment contains a flaw. The users also pointed it out in the replies to the question. You cannot use an int variable as an index. On 64-bit platform, the int variable will most likely be 32-bit (we don't consider exotic architectures here). Therefore, the function cannot copy more than INT_MAX bytes. That is, no more than 2GB.
With a larger size of a copied buffer, an integer overflow will occur, which C and C++ interpret as undefined behavior. Don't try to guess how the error will show itself. This is a complex topic. You can read more about it in the article: "Undefined behavior is closer than you think".
It's especially funny that the code is the result of an attempt to get rid of a Checkmarx warning issued on the memcpy function call. Developers decided to reinvent their own wheel, which, despite the simplicity of the copy function, turned out to be wrong. So, someone did things even worse than they were before. Instead of dealing with the reason for the issued warning, they concealed the issue by writing their own function — and confused the analyzer. Besides, they added an error, using int for the counter. Oh, by the way, such code may disrupt optimization. It's inefficient to use your own function instead of optimized memcpy. Don't do this :).
Get rid of that stupid stdafx.h. It's always causing those weird compilation errors.
"You just don't know how to cook it" (c). Let's find out how precompiled headers work in Visual Studio and how to use them correctly.
Precompiled headers are designed to speed up the project build. Usually developers get acquainted with Visual C++, using small projects. These projects hardly show any benefit from precompiled headers. With or without them, the compile time of the program is the same by eye. This is confusing. A person doesn't see any profit from this mechanism and decides that it's only for specific tasks and will never be needed. And never uses them.
In fact, precompiled headers are a very useful technology. The benefit is clear even if a project consists of a few dozen files. Especially clear if the project uses heavy libraries like boost.
If you look at the *.cpp files in a project, you may notice that many of them include the same sets of header files. For example, <vector>, <string>, <algorithm>. These header files, in turn, include other header files, and so on.
This leads to the fact that the preprocessor performs the same operations over and over again. It should read the same files, insert them into each other, choose #ifdef branches and substitute macro values. This is a colossal duplication of the same operations.
You can significantly reduce the amount of work that the preprocessor should do while compiling the project. The idea is to preprocess a group of files in advance and then just substitute a ready-made text fragment.
Actually, there are some other steps to do. You can store not just text, but a bit more processed information. I don't know how it works in Visual C++. But, for example, you can store there a text already split into tokens. This will speed up the compilation.
The file containing precompiled headers has the ".pch" extension. Usually, the file name matches the project name. Of course, this and other names can be changed in settings. The file can be quite big — it depends on how many header files are in it.
The *.pch file appears after compiling stdafx.cpp. The file is built with the "/Yc" key. This key tells the compiler to create a precompiled header. The stdafx.cpp file may contain only one line: #include "stdafx.h".
The "stdafx.h" file contains the most interesting things. You need to include all header files (that will be preprocessed in advance) in that file. For example, here's how this file may look like:
#pragma warning(push)
#pragma warning(disable : 4820)
#pragma warning(disable : 4619)
#pragma warning(disable : 4548)
#pragma warning(disable : 4668)
#pragma warning(disable : 4365)
#pragma warning(disable : 4710)
#pragma warning(disable : 4371)
#pragma warning(disable : 4826)
#pragma warning(disable : 4061)
#pragma warning(disable : 4640)
#include <stdio.h>
#include <string>
#include <vector>
#include <iostream>
#include <fstream>
#include <algorithm>
#include <set>
#include <map>
#include <list>
#include <deque>
#include <memory>
#pragma warning(pop)The "#pragma warning" directives are necessary to get rid of the warnings issued on standard libraries, if there's a high level of warnings enabled in compiler settings. This is a code fragment from an old project. Perhaps now all these pragmas are not needed. I just wanted to show you how to suppress redundant warnings if such occur.
Now "stdafx.h" should be included in all *.c/*.cpp files. At the same time, you need to remove already included headers with "stdafx.h".
What if similar but different sets of headers are used? For example, these:
Should we create separate precompiled headers? You can do it, but it's not necessary.
It's enough to create one precompiled header, in which <vector>, <string>, and <algorithm> are expanded. The benefit of not having to read lots of files and insert them into each other is much greater than the losses of parsing unnecessary code fragments.
When you create a new project, Visual Studio's Wizard creates two files: stdafx.h and stdafx.cpp. The precompiled headers mechanism is implemented with their help.
In fact, these files can have various names. The name doesn't matter, the compilation parameters in the project settings do.
In *.c/*.cpp files, you can use only one precompiled header. However, one project may have several precompiled headers. For now, we'll assume that our project has only one.
So, if you use a wizard, you already have stdafx.h and stdafx.cpp. Besides, you set all the necessary compilation keys.
If a project doesn't use the precompiled headers mechanism, then let's inspect how to enable it. I suggest the following steps:
So, we enabled the precompiled headers mechanism. Now if we compile a project, the *.pch file will be created. However, then compilation stops because of errors.
For all *.c/*.cpp files we set that they should use precompiled headers. This is not enough. Now you need to add #include "stdafx.h" to each of the files.
The "stdafx.h" header file should be included in the *.c/*.cpp file the very first. Absolutely! Otherwise, compilation errors will appear sooner or later.
If you think of it, it has logic. When "stdafx.h" is placed at the very beginning, you can substitute already preprocessed text. The text is always the same and doesn't depend on anything.
Imagine if we could include another file before "stdafx.h". And write #define bool char in that file. Ambiguity arises. We change the contents of all files in which "bool" occurs. Now you cannot substitute preprocessed text. The whole "precompiled headers" mechanism breaks. I think that's one of the reasons why "stdafx.h" should be located at the beginning. Perhaps, there are others.
Writing #include "stdafx.h" in all *.c/*.cpp files is tedious and boring. Additionally, there will be a revision in the version control system, where a huge number of files will be changed. Not good.
Another inconvenience is standard libraries (in the form of code files) included in a project. It's pointless to edit all these files. The correct option would be to disable the use of precompiled headers. However, if you use several third-party libraries, it's inconvenient. The developers always stumble over precompiled headers.
There is an option how to use precompiled headers easily and simply. This option is not universal but it often helped me.
You can skip writing #include "stdafx.h" in all files, and use the "Forced Included File" mechanism.
Open settings, go to the "Advanced" tab. Select all configurations. In "Forced Included File" write:
StdAfx.h;%(ForcedIncludeFiles)Now "stdafx.h" will automatically be included at the beginning of ALL compiled files. PROFIT!
Now you no longer need to write #include "stdafx.h" at the beginning of *.c/*.cpp files. The compiler will do it itself.
This is a crucial moment. If you mindlessly include everything in "stdafx.h", the compilation will just slow down.
All files that include "stdafx.h" depend on its contents. Let's say that the "X.h" file is included in "stdafx.h". If you change anything in "X.h", this may lead to a full project recompilation.
Rule. Include in "stdafx.h" only those files that will never change or change VERY rarely. Header files of systems and third-party libraries are good candidates.
If you include in "stdafx.h" your own files from the project, be extremely careful. Include only those files that change very, very rarely.
If a *.h file changes monthly, this is too often. Usually, it's almost impossible to make all the edits in the h file in the first try — it takes 2-3 iterations. Agree, recompiling the project 2-3 times a month is not a pleasing task. Besides, not all your teammates need a recompilation process.
Don't get carried away with immutable files. Include only those files that are frequently used. There's no reason to include <set>, if it's needed only in two places. Include this header file only where it's needed.
Why do you need multiple precompiled headers in one project? This doesn't happen often, but let me show you a couple of examples.
The project uses both *.c and *.cpp files. You can't use the *.pch file for both of them. The compiler will issue an error.
You need to create two *.pch files. One is the result of compiling a C file (xx.c), and the other is the result of compiling a C++ file (yy.cpp). Therefore, you need to specify in the settings that one precompiled header is used in C files, and the other — in C++ files.
Note. Don't forget to specify different names for *.pch files. Otherwise, one file will rewrite the other.
Another case. One part of the project uses one big library, and another one uses another big library.
Of course, all code fragments don't need to know about both libraries. Besides, in (bad) libraries, names of some entities may overlap.
It's more logical to create two precompiled headers and use them in different parts of the program. As I mentioned above, you can specify any file names from which *.pch files are generated. You can also change the *.pch file name. Of course, you need to be careful with that, but there's nothing hard in using two precompiled headers.
After reading the material above, you will be able to understand and fix the errors related to stdafx.h. However, let's go through the typical compilation errors and inspect their causes.
Fatal error C1083: Cannot open precompiled header file: 'Debug\project.pch': No such file or directory
You're trying to compile a file that uses a precompiled header. But the *.pch file is missing. Possible reasons:
Fatal error C1010: unexpected end of file while looking for precompiled header. Did you forget to add '#include "stdafx.h"' to your source?
The message is very clear. The file is compiled with the /Yu key. This means you should use precompiled headers. However, the "stdafx.h" file is not included in the file.
You need to write #include "stdafx.h" into a file.
If it's impossible, then you should not use the precompiled header for this *.c/*.cpp file. Just remove the /Yu key.
Fatal error C1853: 'project.pch' precompiled header file is from a previous version of the compiler, or the precompiled header is C++ and you are using it from C (or vice versa)
The project contains both C (*.c) and C++ (*.cpp) files. You can't use the *.pch file for both of them.
Possible solutions:
The compiler is buggy because of the precompiled header
Most likely, something was done wrong. For example, #include "stdafx.h" is not located at the very beginning.
Look at the example:
int A = 10;
#include "stdafx.h"
int _tmain(int argc, _TCHAR* argv[]) {
return A;
}The code won't compile. The compiler will issue a warning which may look strange at first:
error C2065: 'A' : undeclared identifierThe compiler considers that everything that is specified before #include "stdafx.h" (including it), is a precompiled header. When compiling the file, the compiler will replace everything before #include "stdafx.h" to the text from the *.pch file. As a result, the "int A = 10" line is lost.
Here's the correct code:
#include "stdafx.h"
int A = 10;
int _tmain(int argc, _TCHAR* argv[]) {
return A;
}Another example:
#include "my.h"
#include "stdafx.h"The contents of "my.h" won't be used. As a result, you cannot use functions declared in this file. This behavior is very confusing for programmers. They "treat" it by completely disabling precompiled headers and then tell stories about glitches in Visual C++. Remember, the compiler is one of the most rarely buggy tools. In 99.99% of cases, you should not be angry at the compiler but look for the error yourself (see terrible tip N11).
To avoid such situations, ALWAYS write #include "stdafx.h" at the very beginning of the file. You can leave comments before #include "stdafx.h". They don't participate in the compilation in any way.
Another option — use Forced Included File. See the "Life hack!" section above.
Because of precompiled headers, the project is constantly recompiled
stdafx.h has a file that is regularly edited. Or an auto-generated file is accidentally included.
Carefully check the contents of "stdafx.h". It must include only those header files that do not change or change very rarely. Note that included files may not change, but they refer to other changing *.h files.
Something strange is going on
Sometimes it happens that you fix the code, but the warning doesn't go away. The debugger shows something strange.
The *.pch file may be the reason for that. Somehow the compiler does not notice changes in one of the header files and does not rebuild the *.pch file. As a result, the old code is substituted. Perhaps this was due to some failures related to the time of file modification.
This is a VERY rare situation. However, this may happen, and you need to know about that. I have encountered it only 2-3 times over many years of programming. A full project recompilation helps.
Besides, memory allocation is evil. char c[256] is enough for everyone, and if it's not enough, we'll change it to 512. At the very least – to 1024.
Creating an array on the stack does have a number of advantages, compared to allocating memory on the heap using the malloc function or the operator new []:
So, what's wrong with the construction of char c[1024]?
Reason N1. The magic number 1024 implies that the code author doesn't really know how much memory will be needed for data processing. They assume that one kilobyte will always be enough. Doesn't sound very reliable, does it?
If we know that the buffer of a certain size will hold all the necessary data, most likely, we'll see a named constant in the code, for example, char path[MAX_PATH].
The approach of creating a "buffer with a reserve" is unreliable. First, there's a possibility that the "reserve" may not be enough in some cases — and this may lead to a buffer overflow. Second, such code has a potential vulnerability. There's a possibility that certain data can be submitted to the program input. It may overflow the buffer or change the program's behavior in the way desired for an attacker. This is a big topic, and it deserves a separate article. So, here I'll just leave several links:
Reason N2. As we discussed, a fixed buffer size is bad because it may not be enough. Besides, in most cases, the memory allocated in a buffer is much more than needed. Almost always the memory is allocated more than it's then used. If you get carried away with creating such arrays on a stack, the stack may suddenly end. You'll get stack overflow.
The compiler settings allow you to specify how much stack memory is available to the application. For example, in Visual Studio, the /F key is used for this. You can specify a "reserve" here. However, this solution is still unreliable — you can't predict how much stack memory an application will need, especially if many arrays are created on the stack.
Note. Interestingly, some compilers for microcontrollers will issue a compilation error, if they find out that the stack isn't enough for one of the execution branches. In some controllers, the stack is quite small, and such a check helps detect a compilation error at the compilation stage. Compilers can do that because these programs are small and simple. In the case of big applications, it is impossible to calculate at the compilation stage how much stack is needed. The depth of stack usage may depend on the input data, which the compiler knows nothing about.
How to do best?
Creating an array on the stack is neither a good nor a bad solution. Pros: it's the fastest way to allocate memory; you don't need to worry about deallocation. Cons: there's a risk of a stack overflow, especially if you create buffers with a "reserve". Like many other features of C++, creating an array on the stack is a sharp but useful knife that can cut you :).
Can we improve the situation somehow? Yes, we can create arrays on the stack — but arrays of not a fixed size but exactly the one required. They're called Variable Length Arrays (VLA).
First, we can save on stack memory without allocating extra. Second, this reduces the risk of a buffer overflow, since we can allocate as much memory as we need to process data. I wrote "reduces the risk", not "guarantees absence", since if the buffer is enough, an error may hide in the data processing algorithm.
In the C language, we can easily create an array of an arbitrary size on the stack. Just write:
void foo(size_t n)
{
float array[n];
// ....
}This is possible starting from C99. See the "Variable-length arrays" on cppreference.com.
In C++, you can't do that. It doesn't have variable-length arrays. Here are some related discussions:
In fact, some compilers (like GCC), allow that (Arrays of Variable Length). However, this is an extension, it's better not to rely on it, because the code can't be migrated!
So, is there any way to allocate an arbitrary-sized buffer on the stack in C++? Yes, there is. You can use the alloca function. You can use it in both C and C++ programs. It's convenient that the memory automatically deallocates when the function exits.
void foo(size_t n)
{
float *array = (float)alloca(sizeof(float) * n);
// ....
}However, there's bad news. The function is not a part of the C++ standard. Just like in the previous case, this function makes code unfit for migrating. In fact, this is an intrinsic function — the compiler turns this function call into a stack pointer change.
Perhaps, you're suspecting some kind of a "compiler developers' conspiracy", which prevents you from allocating a buffer of arbitrary size on the stack :). Well, you're quite right :). The thing is, such code creates vulnerabilities in programs.
If the input data processing algorithm is written without any error, it doesn't matter whether the buffer is used on the stack or on the heap. However, developers often make mistakes, which can be exploited as vulnerabilities. From this point of view, stack corruption is more malicious and allows performing more attacks than corrupted data on the heap.
Here's a discussion: Why is the use of alloca() not considered good practice?
By the way, index array out of bounds is not the only way to corrupt the program's work. For example, an algorithm may allocate a buffer of sufficient size on the stack and process the data correctly. But it may not consider the size of this data. By giving large data on the input, you can trigger stack overflow and an emergency shutdown of the application. This is a variant of an application-level Dos attack.
Once again, think twice before allocating a buffer on the stack or the heap. Especially if you're developing an application, where safety and security is critical.
By the way, the MISRA standard has a rule (MISRA-C-18.8) that prohibits using VLA. The PVS-Studio analyzer has the appropriate diagnostic rule: V2598 — Variable length array types are not allowed.
Other standards, like SEI CERT C Coding Standard and Common Weakness Enumeration, don't prohibit using these arrays, but urge you to check their size before creating them:
Do not use a version control system. Store the sources directly on the virtual machine server.
I think none of the real developers follow this tip. Those who follow this either don't become developers, or learn from their mistakes by losing the source codes.
Usually this happens with students in universities — suddenly the flash drive with all your work (a program or your coursework) is not readable. And if you're lucky, you're left with just an old copy, otherwise — you don't have anything :).
However, there are some rare species. A person once told me that they got an internship in a state organization. Although it was somewhere in 2010-s, the state workers kept their source code versions in archives. Perplexed, this person asked them how they track changes in code. Instead of an answer, the employees showed them a notebook with detailed entries of every change — written in pen!
Everybody knows that index-to-pointer accesses are commutative. Don't be like everybody else. Make your code unique — use constructions 1[array] = 0.
A professional developer does not write code like "look what I can do!". A professional developer writes code that is easy to read and maintain.
I believe everybody goes through a phase, when you want to use all the knowledge you got. Someone reads books about patterns and starts using them everywhere, overloading code with pointless classes, factories, etc. Someone gets inspired by "Modern C++ Design. Generic Programming and Design Pattern Applied". Then it becomes impossible to understand how this template magic works, and most importantly — why it's used here.
It's useful to learn all that, go through that phase and write simple and understandable code.
Beginners would write a reverse loop like this:
for (int i = n - 1; i >= 0; i--)
// Or this:
int i = n;
while (--i >= 0)Developers with huge egos would write something like this:
int i = n;
while (i-->0)Nice, cool, but useless. Such a construction makes you wonder or suspect if a new "-->" operator was invented :).
In fact, this is just a postfix decrement and the ">" operator. The i variable takes values within range [n - 1 .. 0], just like in the examples above. Think a little and you'll understand how it works.
Have you figured it out? I think yes. Now, the question is: was it worth it? What's the point in figuring out such tricky code, if it executes a simple thing? None.
So, a skilled developer would write the same as a beginner:
for (int i = n - 1; i >= 0; i--)
// Or:
int i = n;
while (--i >= 0)Simplicity and clarity are what matters. Especially if the code works with the same speed.
Note. There's another way how to write this code:
for (int i = n - 1; i >= 0; --i)That's exactly how I would write. In this case, the prefix decrement doesn't change anything. However, this decrement (instead of the postfix one) makes sense for iterators. I write prefix decrement everywhere — this makes code consistent. Does it make sense? Yes. See these posts:
It's much more convenient to use more code in header files. Moreover, the compilation time increases only slightly.
In the era of the header-only libraries, this tip doesn't seem so terrible. After all, there is even "A curated list of awesome header-only C++ libraries".
But small libraries are one thing. And the other thing is a big project that involves dozens of people and has been developing for many years. At some point, the compilation time will grow from minutes to hours, and it will be difficult to do something about it. It's not like you will refactor hundreds and thousands of files by transferring the implementation of functions from *.h to *.cpp files. And if you refactor, then wouldn't it have been easier to write it properly right away? :)
The implementation of functions in header files may have the worst consequence. For example, a minimum of editing leads to the need to recompile a large number of files in the project. There is an important difference between the code in header-only libraries and the code of your project. You don't touch the code in the libraries, and you constantly edit your code!
Here's an additional useful link: Pimpl.
Rumors say that goto is considered a terrible statement, but this is nonsense! This statement is very powerful and even allows you to stop using for, while, do. Long live goto and asceticism!
The use of goto makes the code more difficult to understand. The code filled with goto statements is difficult to read from top to bottom. Especially if the code contains fragments where you need to jump from bottom to top. In this case, you'll have to "jump" on the labels to understand how the logic of the program works. If a large function contains lots of goto statements, it's hard to read it.
There is even a special term for this: spaghetti code. A quote from Wikipedia:
Spaghetti code is a pejorative phrase for unstructured and difficult-to-maintain source code. Spaghetti code can be caused by several factors, such as volatile project requirements, lack of programming style rules, and software engineers with insufficient ability or experience.
Code that overuses GOTO statements rather than structured programming constructs, resulting in convoluted and unmaintainable programs, is often called spaghetti code. Such code has a complex and tangled control structure, resulting in a program flow that is conceptually like a bowl of spaghetti, twisted and tangled.
Well, the goto statement itself is not evil, but it's better to use it carefully. If goto is not evil, then why is it recommended not to use it? After all, in C++, almost every construct is dangerous :).
Actually, you can easily write code without the goto statement. Moreover, the code without goto usually looks better and is easier to read.
Well, it's difficult to give some examples of how to use goto correctly. There's only one that comes to my mind — the pattern with one exit point — we discussed it in the tip N19. All gotos jump to a single label, followed by a memory allocation and error code return from the function. Such code is easy to understand. However, further on, you'll learn why it's even better to use smart pointers. Turns out that goto is useless again.
Never use enums, they implicitly change to int anyway. Use int directly!
C++ evolves and becomes a more and more strongly typed language. Therefore, for example, the enum class appeared. Check out the discussion "Why is enum class preferred over plain enum?".
This terrible tip, on the contrary, encourages us to return to a situation where it's easy to get confused in data types and accidentally use the wrong variable or the wrong constant.
If there are ordinary enums instead of plain int in code, the PVS-Studio analyzer can still detect the following anomalies.
Sometimes it happens that some kind of global constant object is needed everywhere. For example, an instance of an empty string. It's more convenient to place it in the header file where your string class is declared.
As a result, we get something like this:
// MySuperString.h
class MySuperString {
char *m_buf;
size_t m_size, m_capacity;
public:
MySuperString(const char *str);
....
};
const MySuperString GlobalEmptyString("");The trouble is that GlobalEmptyString is a global constant object that exists not in a single instance.
When such a header file is included with the help of #include, multiple copies of the object are created. This will lead to a waste of memory and time used to create a lot of empty strings.
Usually, if a class has a constructor, its code will be executed every time the header file is included. This can lead to adverse side effects.
To avoid multiple object creation, you can declare a variable as inline (starting with C++17) or extern. In this case, initialization and constructor invocation will occur once. Here's a fixed version:
inline const MySuperString GlobalEmptyString("");You can find more information on this topic in the following article: "What Every C++ Developer Should Know to (Correctly) Define Global Constants".
P.S. The PVS-Studio analyzer provides the V1043 diagnostic that will warn you against the described error.
Show a little respect for programmers of the past — declare all variables at the beginning of functions. It's a tradition!
It's better to declare a variable as close as possible to the place where it is used. It's even better when you declare a variable and initialize it right away. Pros:
Of course, we need to act consciously. For example, if there are loops, sometimes it's better to create and initialize a variable outside the loop to increase the program's performance. Examples: V814, V819.
Include as many header files as possible so that each .cpp file opens in a million lines — your teammates will thank you for having more time for a smoke break during rebuild!
Captain Obvious would say "don't do that". But I'm not going to give you such a piece of advice, because sometimes you really need to include a lot of header files. What then should we do to speed up the build of such projects? Precompiled header files will help you! We discussed them in terrible tip N27!
Additionally, these articles of my colleagues may help you:
Write your .h-files so that they depend on other headers, and do not include them in your header file. Let the one who use include guess what header files need to be included in advance before using your file. Entertain your colleagues with quests!
Let me give you an example to explain what I mean. Let's say you have various types declared in the my_types.h file:
// my_types.h
#ifndef MY_TYPES_H
#define MY_TYPES_H
typedef int result_type;
struct mystruct {
int member;
};
#endifAnother header file my_functions.h describes functions that use these types.
// my_functions.h
#ifndef MY_FUNCTIONS_H
#define MY_FUNCTIONS_H
result_type foo(mystruct &s);
result_type doo(mystruct &s);
#endifIf the cpp file needs to use the functions described in my_functions.h, a file with a description of the types should be included before my_functions.h. Otherwise the code will not compile:
// my.cpp
#include "my_types.h"
#include "my_functions.h"It does not look terrible in such a simple synthetic code fragment above. However, in a real application, such dependent header files may become a problem.
Firstly, it's annoying to find out which files a particular header file depends on and what needs to be included before it.
Secondly, this approach creates a desire to include more of the most frequently used header files at once. As they say, "to keep them in reserve". As a result, long lists of header files appear at the beginning of cpp files. Some of these lists are not really necessary and only slow down compilation.
You should follow the principle: each header file should be self-contained. To do this, the header file should include all other header files on which it depends.
For the example we have looked at before, we need to change the files as follows:
// my_types.h
#ifndef MY_TYPES_H
#define MY_TYPES_H
typedef int result_type;
struct mystruct {
int member;
};
#endif
--------------------------------
// my_functions.h
#ifndef MY_FUNCTIONS_H
#define MY_FUNCTIONS_H
#include "my_types.h"
result_type foo(mystruct &s);
result_type doo(mystruct &s);
#endif
--------------------------------
// my.cpp
#include "my_functions.h"Why do we need all these *_casts if there is a reinterpret_cast? And the good old C-style cast — (Type)(expr) — is even better and shorter.
The point is that C-style casts are more "rigid". Using them, you make a type conversion that doesn't make sense. In the case of "gentler" *_cast conversions, such code will not compile, so an error could be detected at the code writing stage.
Let's look at the synthetic code fragment of Windows application:
void ff(char *);
void ff(wchar_t *);
void foo(const TCHAR *str)
{
ff((char *)(str)); // (1) compiles
ff(const_cast<char *>(str)); // (2) does not compile
ff(const_cast<TCHAR *>(str)); // (3) compiles
}Suppose we need to cast away constness from the pointer to characters of the TCHAR type. Depending on the compilation mode the TCHAR type can refer to char or wchar_t. In our case, let's say it refers to the wchar_t type.
Let's look at three different type conversions:
Additional links:
If you decide to write a function, it should be omnipotent and versatile, like a Swiss army knife. The function should take a lot of arguments. To save time, you may not enumerate the arguments, but parse them using va_arg.
Functions with a variable number of arguments allow you to do a lot. Including making a lot of mistakes when implementing and using them :).
It is difficult to write reliable code that is safe from potential vulnerabilities with the use of such functions. Therefore, some standards, for example, SEI CERT C++ Coding Standard, generally recommend not to use them: DCL50-CPP. Do not define a C-style variadic function.
And here's one more link: Ellipsis (and why to avoid them).
We will return to this topic in the tip N58, where we will talk about the printf function.
What could be wrong with looking at a neighboring variable via a pointer to a variable? I mean, we are within the limits of our memory.
In my practice, I have encountered code fragments similar to the following:
float rgb[3];
float alphaChannel;
....
for (int i = 0; i < 4; i++)
rgb[i] = 0f;Someone was too busy to write zero separately to the variable for the alpha channel. They combined the variable initialization with the initialization of array elements.
Doing so is bad and unsafe for three reasons:
And here is another interesting case. A long time ago, in 2011, I wrote an article on checking the VirtualDub project. The author said that the code worked as intended so it's better to leave everything as it is, rather than changing the code where access outside the array occurs: The "error" in f_convolute.cpp.
There's a risk that this text on the link will get lost over time. For example, comments are already lost. Just in case, I will quote the whole text here.
The "error" in f_convolute.cpp
Okay, Mr. Karpov decided to use VirtualDub again as an example of a detected code defect in his article, and while I respect him and his software, I resent the implication that I don't understand how C/C++ arrays work and that he included this example again without noting that the code actually works. I'd like to clarify this here.
This is the structure and reference in question:
struct ConvoluteFilterData {
long m[9];
long bias;
void *dyna_func;
uint32 dyna_size;
uint32 dyna_old_protect;
bool fClip;
};
long rt0=cfd->m[9], gt0=cfd->m[9], bt0=cfd->m[9];This code is from the general convolution filter, which is one of the oldest filters in VirtualDub. It computes a new image based on the application of a 3x3 grid of coefficients and a bias value. What this code is doing is initializing the color accumulators for the windowing operation with the bias value. The structure in question here is special in that it has a fixed layout that is referenced by many pieces of code, some written in assembly language and some dynamically generated (JITted) code, and so it is known -- and required -- that the element after the coefficient array (m) is the bias value. As such, this code works as intended, and if someone were to correct the array index to 8 thinking it was an off-by-one error, it would break the code.
That leaves the question of why I over-indexed the array. It's been so long that I don't remember why I did this. It was likely either a result of rewriting the asm routine back into C/C++ -- back from when I used to prototype directly in asm -- or from refactoring the structure to replace a 10-long array with a 9-long coefficient array and a named bias field. Indexing the tenth element is likely a violation of the C/C++ standard and there's no reason the code couldn't reference the bias field, which is the correct fix. Problem is, the code works as written: the field is guaranteed to be at the correct address and the most likely source of breakage would be the compiler doing aggressive load/store optimizations on individual structure fields. As it happens, the store and load are very far apart -- the struct is initialized in the filter start phase and read much later in the per-frame filter loop -- and the Visual C++ compiler that I use does not do anything of the sort here, so the generated code works.
The situation at this point is that we're looking at a common issue with acting on static analysis reports, which is making a change to fix a theoretical bug at the risk of introducing a real bug in the process. Any changes to a code base have risk, as the poor guy who added a comment with a backslash at the end knows. As it turns out, this code usually only executes on the image border, so any failures in the field would have been harder to detect, and I couldn't really justify fixing this on the stable branch. I will admit that I have less of an excuse for not fixing it on the dev branch, but honestly that's the least of the problems with that code.
Anyway, that's the history behind the code in f_convolute.cpp, and if you're working with VirtualDub source code, don't change the 9 to an 8.
This unicorn on the picture perfectly shows my reaction to the message. I don't understand why not just take and write code where the value is taken from the bias variable. The code is bad, if it requires such a long explanation. The code needs refactoring, not storytelling.
The const word just takes up space in code. If you don't want to change a variable, then you just will leave it like that.
Really, if you don't want to change it — don't do that. The only problem is that we all make mistakes. The const qualifier allows you to write more reliable code. The qualifier protects against typos and other misunderstandings that may arise during code writing or refactoring.
Here's the example of the bug we found in the Miranda NG project:
CBaseTreeItem* CMsgTree::GetNextItem(....)
{
....
int Order = TreeCtrl->hItemToOrder(TreeView_GetNextItem(....));
if (Order =- -1)
return NULL;
....
}The programmer's hand slipped and there's '=-' instead of '==' in the condition. A new value is assigned to the variable, although the intention was to perform a comparison. Let's suppose that the programmer would use the const keyword:
const int Order = TreeCtrl->hItemToOrder(TreeView_GetNextItem(....));
if (Order =- -1)
return NULL;In this case, the code wouldn't compile.
However, const isn't that helpful in terms of code optimization. You can find the following idea in some articles: if you make a variable as constant, you help a compiler to generate more optimized code. These are high expectations. See the article "Why const Doesn't Make C Code Faster". Another thing — constexpr. This keyword brings up interesting possibilities to perform many calculations even at the code compilation stage: "Design and evolution of constexpr in C++". Read the article, you won't regret it.
Did you know that instead of curly brackets, you can use <% and %>? Digraphs and trigraphs can make your code vintage and more unique. Your code will stand out against the code of your teammates. You are not doing anything illegal. Digraphs and trigraphs are in the standard.
In fact, this terrible tip about vintage is vintage itself. The point is that the C++17 standard abolished trigraphs.
However, you can still use digraphs in C++. And there are still trigraphs in C programs. Additionally, for true fans of vintage, the Visual C++ compiler allows you to continue using trigraphs by specifying the /Zc:trigraphs switch.
Why initialize variables if they are already zeroed? I mean, just the other day, I didn't initialized variables and there was zero. Everything worked.
No one will take the advice to use uninitialized variables seriously. This is a mistake of beginners in programming. Of course, professional developers may make such mistakes too, but this is not a widespread phenomenon. At least, this is a rarer error than, for example, dereferencing a null pointer.
Why do beginners make this mistake? I think there are two reasons that confuse them.
Firstly, the value of an uninitialized variable may accidentally turn out to be zero. Since it's usually zero that the variable should have been initialized with, it seems as if the program is working correctly. Of course, this is just luck, and, strictly speaking, the use of an uninitialized variable leads to undefined behavior. In this case, it just so happens that the undefined behavior of the program coincides with the expected correct behavior :).
Secondly, in C++ there is a difference between local and global variables. Local variables are not initialized by default. But global ones are initialized automatically. All this adds to the confusion when you are just learning how to program.
For dessert, here's an article: "Initialization in C++ is Seriously Bonkers. Just Start With C".
Annotation. I was recently reminded of why I think it's a bad idea to teach beginners C++. It's a bad idea because it is an objective mess — albeit a beautiful, twisted, tragic, wondrous mess. Despite the current state of the community, this post is not a polemic against modern C++. This post is partly a follow-up on Simon Brand's article, Initialization in C++ is bonkers, and partly a message to every student who's wanted to begin their education by gazing into the abyss.
Private and protected access modifiers are for those who don't feel confident. These class fields — who needs them anyway?
A newcomer to programming might find it convenient when all members of a class are public. In this case, it is possible to change any variable in the class or to call any function of the class.
The price for this approach is the complexity of maintaining, modifying and debugging the code. Since the data in the classes are changed in different parts of the program, it is very difficult to figure out how it all works, and even more difficult to make any changes to the logic of the program. As a result, the initial simplicity of quickly writing code in the future turns into a large number of errors and difficulties in the development of the program.
In fact, one of the basic OOP principles is violated — encapsulation. The topic of encapsulation and its benefits is beyond the scope of this text. So, experienced programmers saying: "It all makes sense," can continue reading :). And if you are a newbie, I invite you to read Grady Booch's excellent fundamental book "Object-Oriented Analysis and Design with Applications.".
Create variables that will differ in names only by numbers: index1, index2.
This tip refers to the "Zero, one, two, Freddy's coming for you" article where I tell how easy it is to make a typo when you use names such as A0, A1, A2.
Write your code as if the chairman of the IOCCC judges will read it and as if they know where you live (to come and give you the prize).
It's a reference to a quote — "Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live". This is John F. Woods's phrase, however, it's sometimes credited to Steve McConnell who quoted it in his "Code Complete" book.
The tip tells that it's better to write as unusual, weird, and incomprehensible as possible — like you're going to send your code to the IOCCC.
IOCCC (International Obfuscated C Code Contest) is a computer programming contest. Participants need to write the most creatively obfuscated C code within the size of the source code.
It seems obvious why poorly written code is bad. But still — why? Programmers spend most of their time not writing code but reading it. I can't remember the source and the exact numbers, but it seems to say that they spend more than 80% of their time reading.
Accordingly, if the code is hard to read and understand, that greatly slows down the development. That's one of the reasons why every team member needs to follow one coding style so that other developers can read the code.
If line breaks and indents are insignificant in C++, why not write code in the form of a bunny or a squirrel?
That's an odd play that makes code unreadable for those who will maintain it. I would refer to the reasoning from the previous advice, as it fits this case as well.
But I'm not going to be a snob. I sometimes wrote creative and humorous comments, so I don't see any harm in it. We are all human, and we all have emotions. So, it's alright if we express our feelings in code comments. And we all know how strong these emotions can be when it comes to coding :).
The key principles are: don't break the code, don't overcomment the code, and don't offend anyone.
If I meet a dragon in a code comment, I won't mind. And I'll be even glad that the author brought something to my attention in such an unexpected way.
// .==. .==.
// //`^\\ //^`\\
// // ^ ^\(\__/)/^ ^^\\
// //^ ^^ ^/6 6\ ^^ ^ \\
// //^ ^^ ^/( .. )\^ ^ ^ \\
// // ^^ ^/\| v""v |/\^ ^ ^\\
// // ^^/\/ / `~~` \ \/\^ ^\\
// -----------------------------By the way, I recommend taking a look at various unusual things that may appear in code comments. My colleague wrote an article about this: "Code comments as a work of art".
Alignment and code style do not allow to express your individuality and creativity. This is a violation of individual freedoms and self-expression. Everyone should write code the way they like.
Okay, the last two tips were a little bit bizarre. What about expressing oneself appropriately in entity naming and code design?
This should not be done for the following reasons:
I hope I was persuasive enough. A unified coding standard in a team is a very useful practice. You can take the Google C++ Style Guide or any other style guide as a basis. Then adapt it for yourself. Another source of inspiration may be found here:
The topic of code formatting is related to the coding style and coding standard. Developers can check entity naming during code reviews. As for code formatting, they can use various helpful tools. The most important thing is to agree on how a team formats code, and then it's just a matter of technique:
For as many types as possible, overload as many operators as possible, including non-arithmetic ones. By giving operators a different meaning, you are getting closer to creating your own language dialect. Creating your own language is fun. And what if you also add macros...
Operator overloading means a more elegant function call. For example, it allows you to use the operator+ and operator= for strings. It helps write elegant string concatenation code:
result = str1 + str2;You must admit that this code is far neater than the following:
result.assign(str1.strcat(str2));Operator overloading is useful only when it makes code writing easier, as in the example above. Irrelevant operator overloading will make the code harder to read. If the operation of overloaded operators is intuitive, that's good. If not, it's harmful.
Let's say, A, B, C are instances of the matrix class. In this case, the following code is clear:
A = B * C;That is another case:
A = B && C;This code is not intuitive. Sure, you can examine what the operator&& does with matrices. If the operation is performed frequently, operator overloading can help you write code more neatly. However, I believe you know that the more unexpected actions overloaded operators perform, the more difficult it is to understand the code. In this case, operator overloading complicates the code.
P.S. By the way, once Bjarne Stroustrup jokingly wrote about enabling whitespace overloading: Generalizing Overloading for C++2000.
A universal std::string is inefficient. realloc, strlen, strncat work more quickly and effectively.
The fact that the program performance can be significantly increased by giving up the std::string class is a myth. However, there must be a reason for this myth to appear.
The thing is that previously common implementations of std::string were far from satisfactory. So, maybe, we are dealing not with a myth but with outdated information.
Let me share my own experience. Since 2006, we've been developing the PVS-Studio static analyzer. In 2006, its name was Viva64, but it doesn't matter. Initially, we widely used the std::string class in the analyzer.
Time passed. The analyzer developed, more and more diagnostics appeared, and it worked slower and slower with each release :). It was time to think about code optimization. The profiler pointed out at one of the bottlenecks — the work with strings. And then the quote came to my mind: "in any project, sooner or later, custom string class appears". Unfortunately, I don't remember where this quote came from, or when exactly it happened. I think it was 2008 or 2009.
The analyzer creates many empty or very short strings during its work. We created our own string class — vstring that effectively allocated memory for such strings. From the point of view of the public interface, our class repeated std::string. The custom string class increased the analyzer's speed by about 10%. Cool!
This string class served us for many years, until I listened Anton Polukhin's report at the C++ Russia 2017 conference — "Things not to do: how C++ professionals reinvent the wheel [RU]". In his talk, he said that the std::string class has been well optimized for many years. And those who use their own string class are unprogressive dinosaurs :).
Anton told the audience what optimizations are currently used in the std::string class. For example, from the simplest – about the move constructor. I was particularly interested in Small String Optimization.
So, we didn't want to be dinosaurs anymore. Our team conducted an experiment — we started to switch from a custom vstring class back to std::string. First, we just commented out the vstring class and wrote using vstring = std::string;. Fortunately, after that, minor code edits were required in other places since the class interfaces still almost completely matched.
And how has the running time changed? It hasn't changed at all! This means that for our project, the universal std::string has become just as effective as our own custom class that we made about a dozen years ago. Amazing! Minus one pointless invention.
However, let's get back to classes. The terrible tip recommends that we go down to the level of the C language functions. I doubt that these functions will help write faster and more reliable code than in the case of using a string class.
Firstly, the processing of C strings (null-terminated strings) provokes frequent calculation of their length. If you don't store the length of the strings separately, it's difficult to write high-performance code. And if you store the length, then we again proceed to the string class analog.
Secondly, it is difficult to write reliable code with functions such as realloc, strncat, and so on. Errors that PVS-Studio found in various projects underscore that the code using these functions directly "attracts" errors. Here are error patterns found when strlen, strncat, realloc were used.
Make sure your code supports the outdated C++ standard for compatibility purposes.
There are projects that need to be compiled for a variety of platforms. In this case, you should stick to the version of the language that is supported by all of the compilers.
However, this is a rare case. That's why it makes no sense to delay the support of a new language standard. With each new version of the C++ language, you can write tighter, safer, and more efficient code.
Some programmers would say that they stick to the old standard just in case. After all, their project may be in demand on platforms with outdated compilers. Developers tend to do a lot of things just in case. This strategy often does more harm (a waste of time) than good.
This "hypothetical case" may never happen. Even if it happens, the main problem is unlikely to be a compilation failure of certain C++ constructs. Other challenges will arise, such as libraries, the necessity to adjust the graphical interface, performance optimization, and so on. In other words, there will be a lot more difficulties, making it pointless to worry about the language standard's version.
Reuse variables as much as possible. Allocate memory once and then reuse it. For example, if we need three integers in a function, create one, call it something generic, like x, and then use that x name for all three integers.
That's a truly terrible tip; this approach makes the program harder to understand and, as a result, leads to errors in code.
Firstly, the variable's name is confusing in any way:
It turns out that this terrible tip violates the principles of self-documenting code. Variable names are meaningless and do not help to understand how the program works.
Note. We can get around this by making different references to the same variable. However, in the end, it gets even more confusing. We may unintentionally start using the same variable to write completely different values, overriding other values that are still necessary.
Secondly, using the same variable for different purposes leads to errors. Fortunately, it's not that common, and I was not collecting statistics to prove this claim. Years of identifying bugs in numerous open-source projects have shaped my viewpoint. Intuition tells me that if we write this way, the number of errors in code will skyrocket.
Thirdly, the tip violates the generally recognized principle of reducing the scope of a variable:
This reduces the number of errors caused by using the wrong variable (due to a typo). For example, now we can declare variables in the condition for this purpose. As a result, the variable's scope is limited to the body of the if statement:
if (auto p = dynamic_cast<Derived*>(bp))
p->df();What about memory saving, though?
Actually, this is a dubious way of memory saving. There will be no significant memory saving, if these are int-type variables generated on the stack. Moreover, if the lifetime of a variable has ended, the compiler can place a new variable in the same memory location on the stack. Or the compiler may decide to use one of the processor registers to store the variable instead of storing it on the stack. In general, the compiler can independently perform the optimization to save memory.
What about arrays created on the heap? These are, of course, heavier operations, and compiler optimizations most likely won't help in this case. For optimization purposes, I admit that it may make more sense to reuse an existing array rather than allocate a new one.
Yet, this is a rare case. I couldn't recall a single instance in my development practice where I was tempted to reuse an array for other purposes. For some reason, I just didn't find it necessary.
Anyway, this approach may be harmful! It has an extremely negative impact on code's readability and maintainability. As a result, it does more harm than (possible) good.
Write comments to explain what exactly a line of code does. Yet every true coder understands why this is done.
What a line of code does is almost always clear. Let's take a look at this hyperbolized example:
i++; // add 1 to iHoly cow, even someone with a basic understanding of C++ can see that the variable has been increased by one. A comment written to this code does not carry any useful information and even clutters the code up.
Code comments should answer the question "why/what for do we need it?" rather than "what?"
The concept of the Golden Circle by Simon Sinek is quite relevant here. It's not about code comments, but it effectively conveys the entire idea. All comments can be divided into three groups according to the question they answer:
A TEDTalks video on the Golden Circle concept may be found here:
Let's look at a real-world example of useful code comments.
I picked this code while working on the article "Date processing attracts bugs or 77 defects in Qt 6".
The PVS-Studio analyzer issued a warning: V575 [CWE-628] The 'memcpy' function doesn't copy the whole string. Use 'strcpy / strcpy_s' function to preserve terminal null. qplaintestlogger.cpp 253. Here is the code fragment:
const char *msgFiller = msg[0] ? " " : "";
QTestCharBuffer testIdentifier;
QTestPrivate::generateTestIdentifier(&testIdentifier);
QTest::qt_asprintf(&messagePrefix, "%s: %s%s%s%s\n",
type, testIdentifier.data(), msgFiller, msg,
failureLocation.data());
// In colored mode, printf above stripped our nonprintable control characters.
// Put them back.
memcpy(messagePrefix.data(), type, strlen(type));
outputMessage(messagePrefix.data());Pay attention to the memcpy function call. The code raises two questions:
Fortunately, the comment immediately makes it all clear. Some non-printing characters must be restored.
Here's an important and valuable comment. It provides an explanation for why something is being done. This comment explains a non-obvious thing in the code. It may be used as an example in how-to articles.
For comparison, take a look at another code snippet from the same file:
char buf[1024];
if (result.setByMacro) {
qsnprintf(buf, sizeof(buf), "%s%s%s%s%s%s\n", buf1, bufTag, fill,
buf2, buf2_, buf3);
} else {
qsnprintf(buf, sizeof(buf), "%s%s%s%s\n", buf1, bufTag, fill, buf2);
}
memcpy(buf, bmtag, strlen(bmtag));
outputMessage(buf);A programmer forgot to leave a similar code comment here. As a result, everything has changed. A new team member responsible for maintaining and modifying this code will be perplexed. It's not clear at all why the memcpy function is used here. Moreover, it's also unclear why the contents of some buffer buf1 are written at the beginning of the line, and why the contents of the bmtag buffer are added at the beginning of the string. So many questions and so few answers.
Multithreading is always more efficient than single-threading.
However, it is critical to define what is meant by efficiency. If we define it as program performance, then parallelized code will obviously process data quicker than single-threaded code.
If we talk about efficiency as the computing resources spent on solving a problem, then non-parallelized code is definitely more efficient. Non-parallelized code lacks the additional functionality needed to synchronize threads. No time is lost when one thread is waiting for something from another thread. And so on. Basically, the code is simpler and faster.
At that moment, it may seem that the statement "multithreading is better" is true. Users aren't interested in the entire operating duration of the application's threads. They are concerned with the amount of time it takes to solve the problem.
However, it's not that simple. The point is that there is still such a thing as parallelization levels. The greater the size of the parallelization units, the more efficiently the application can operate.
We can also look at the following broad example. Let's say we have a multi-core processor. The task is to convert 1,000,000 photos from jpeg to png. In this case, several single-threaded programs running in parallel will cope with the task faster than a program that can parallelize the conversion of images internally. There's a reason for this: single-threaded applications are simpler, and they don't waste time on synchronization.
But wait, there's more. It is easier to implement high-level parallelism. You will agree that multiple instances of a running program taking images from a shared pool and processing them are not complex. It's not that difficult to write a manager for this.
Writing code that divides the image into parts, processes them in parallel, and then assembles the processed parts together would be far more challenging. And when we write complex code, we are more likely to make a mistake!
Figure. Parallel programming: Expectation vs reality.
Here is another example of a reasonable approach. PVS-Studio is parallelized at the level of the C++ file analysis. That means that each C++ file is analyzed in a separate process that uses a single thread to process data. It's effective and easy. As many processor cores there are, as many instances of the analyzer are run. In general, this is how parallel code compilation works.
But what if we only need to check a single file? Wouldn't a parallelized analyzer process this faster than a single-threaded one?
Yes, but it has no practical sense. We can already check a single file rapidly enough. From a practical standpoint, there will be no difference for the user. We can even roughly estimate the numbers.
PVS-Studio uses an external preprocessor. The analyzer can in no way affect the preprocessor's performance. The preprocessor works sequentially. Suppose preprocessing is performed in 2 seconds.
PVS-Studio analyzes code and finds errors in 2 seconds too.
Let's add 1 second for several extra operations. We need to request the file's data from Visual Studio. Run the preprocessor, run the analyzer. Open an IDE window and display warnings in it.
In total, let's say that the file analysis is performed in 5 seconds.
Imagine we did a tremendous job parallelizing the C++ analyzer core. After that, the file will be analyzed in 1 second instead of 2. We are unlikely to get more benefits, regardless of how many threads we run. Parsing into tokens, building a syntax tree, traversing it, and other operations are all poorly parallelized. After all, it is impossible to parse, for example, the second part of the file without knowing what types are declared in the first part.
As a result, the analysis will take 4 seconds instead of 5. There isn't much of a difference from the user's perspective.
Actually, this is the only scenario where we notice the advantage we get from parallelization. In scenarios where a large number of files are processed, everything will work as fast as possible.
However, if we wish to slightly speed up the analysis of a single file, you have to greatly complicate the code analysis algorithms. Is it worth it? No.
As you can see, parallel programming can have different results, and they are not always equally beneficial.
There is no limit to the amount of code that may fit into a single file; in fact, this way code compiles faster.
Some might think that I stand for creating a few small files. Not at all. I get annoyed when every class or other entity, no matter how minor, is implemented in a separate file. It gets even more harder to find anything — you frequently need to use the global search to look for files. I believe that grouping related and similar entities in a single file is much better.
However, let's go back to giant files. They are problematic for the following reasons:
By the way, speaking of compilation speed. I discussed this section with coworkers while writing it, and we all agreed that the quantity and size of files matter nothing. The pace of partial or complete recompilation is determined by a variety of factors, including how the development process is organized.
Anyway, the file size is irrelevant when discussing compilation speed. You can find another useful ways and tools for making compilation faster in "Speeding up the Build of C and C++ Projects".
Everything that can be represented by a class must be represented by it.
I think this kind of maximalism comes at a time of unhealthy obsession with OOP. As someone once said, "To a man with a hammer, everything looks like a nail".
I recommend you to watch Jack Diederich's talk "Stop Writing Classes". It's actually about Python, but it doesn't matter.
Reading fundamental books on C++ is a waste of time. Educational videos are enough, Google will help with everything else.
I'm a big proponent of reading programming books. At the same time, I do not deny the benefits of educational videos and other ways of learning. I personally enjoy watching some talks from a C++ conference.
However, educational videos have two drawbacks:
In my opinion, the video can complement the knowledge gained. This knowledge is useful when placed on top of the foundation of knowledge obtained from books. Otherwise, they form a shallow broken picture of knowledge. A person seems to know a lot about programming, but such 'patchwork' knowledge will quickly backfire on them and their employer.
By the way, I have met such "programmers". The first superficial impression is that they are outstanding. They can quickly create something at a hackathon using some fashionable AI library, or surprise with some incredible beauty by using a game engine somewhere. It seems like some kind of magic, especially if you haven't worked with these libraries yourself. Except that sooner or later all this is crushed by a lack of knowledge of some basic algorithms or programming language peculiarities.
And what's the problem if a person does not know something, but nevertheless does something? The answer is inefficiency and limited opportunities. Due to the lack of knowledge, a person can use strange, extremely suboptimal approaches. Or they can program by searching for ready-made solutions in Google or on Stack Overflow. But not everything can be "googled", and sooner or later a person simply will not be able to solve the tasks facing them.
So, here we're getting closer to the relatively recent problem of "Google programmers". The Internet is full of 'how to make X' training videos and ready-made projects/solutions. This generates programmers who do not know how to solve problems on their own. But sooner or later they face such tasks. This problem is described in the article "Google programmers. How one idiot hired a couple more idiots".
Note that this is a provocative article that has gathered a lot of criticism. However, I think many readers are just triggered by unpolished narrative style. This article is grotesque! The article purposely presents the problem in a harsh manner. Otherwise, the article might not have received as much attention and would have gone unnoticed. So, I recommend reading it, it raises a very interesting and important problem of the modern programming world.
Additionally, you can get acquainted with the comments to the article:
Just a friendly reminder: this is a guest article. It wasn't written by someone from the PVS-Studio team. We found this article intriguing and requested author's permission to translate it and post it on our blog.
By the way, during job interviews, I ask what books on C++ programming an applicant has read. This does not mean that we will not hire a candidate if they answer that they have not read books, but this is a reason to be wary.
We also ask candidates to write a couple of small functions on paper, for example, "count the number of zero bits in an unsigned int type variable". This immediately says a lot about the person. However, we are more interested in comprehensive theoretical knowledge of the C++ language due to the specifics of our work on creating the code analyzer.
PS: It may seem that I am against searching for something on the Internet. That's not true. Googling is one of the most important skills for every developer. However, search skills cannot replace your own knowledge and ability to write complex code.
Need to print a string? What's there to think about! Just print it using printf!
When you need to print or, for example, write a string to a file, many programmers, without hesitation, write the following code:
printf(str);
fprintf(file, str);These are dangerous constructions. The thing is that if a formatting specifier somehow gets inside the string, it will lead to unpredictable consequences.
Let's say we want to use the following code to print the file name:
printf(name().c_str());If the file has the "file%s%i%s.txt" name, the program may crash or print nonsense.
But that's only half the trouble. In fact, such a function call is a real potential vulnerability and could be used to try to attack the software. By preparing the strings in a special way, you can print the private data stored in memory.
You can read more about such vulnerabilities in this article. Take the time to check it out, I think it would be interesting. It not only discusses the theory, but also provides practical examples.
Here's the correct code:
printf("%s", name().c_str());In general, functions such as printf, sprintf, fprintf are dangerous. It is better not to use them, but to use something more modern. For example, you may find boost::format, std::stringstream or std::format useful.
I also recommend watching this video.
The C++ standard clearly defines how a virtual function call works in a constructor and destructor. So, you can safely make such calls.
In the abstract, this is indeed true. But in practice, the incorrect use of virtual functions is a classic mistake when developing in C++. There are two reasons:
Therefore, I have reviewed these two reasons and errors in detail in the article "Virtual function calls in constructors and destructors (C++)".
I recommend reading this article to anyone who is currently studying C++. However, even experienced programmers may find it useful to refresh their knowledge in this area. Especially for those who write code in several languages at once.
Copying code and then editing it is the fastest way to write code. Long live the copy-paste programming!
Indeed, you can quickly write a lot of code this way. This is especially convenient if your work is evaluated by the number of code lines :).
However, if we are talking about developing a high-quality application, and not about how to create more "sh*t code", this approach has three big drawbacks:
The situation can be rectified by not copying the code, but by passing it into functions and then using it from different parts of the program. This fixes all three problems:
Let's look at how this might look in practice. Here's an error we found in the Blend2D project:
static BLResult BL_CDECL bl_convert_argb32_from_prgb_any(
const BLPixelConverterCore* self,
uint8_t* dstData, intptr_t dstStride,
const uint8_t* srcData, intptr_t srcStride,
uint32_t w, uint32_t h, const BLPixelConverterOptions* options) noexcept {
if (!options)
options = &blPixelConverterDefaultOptions;
const size_t gap = options->gap;
dstStride -= uintptr_t(w) * 4 + gap;
srcStride -= uintptr_t(w) * PixelAccess::kSize;
const BLPixelConverterData::NativeFromForeign& d =
blPixelConverterGetData(self)->nativeFromForeign;
uint32_t rMask = d.masks[0];
uint32_t gMask = d.masks[1];
uint32_t bMask = d.masks[2];
uint32_t aMask = d.masks[3];
uint32_t rShift = d.shifts[0];
uint32_t gShift = d.shifts[1];
uint32_t bShift = d.shifts[2];
uint32_t aShift = d.shifts[3];
uint32_t rScale = d.scale[0];
uint32_t gScale = d.scale[1];
uint32_t bScale = d.scale[2];
uint32_t aScale = d.scale[3];
for (uint32_t y = h; y != 0; y--) {
if (!AlwaysUnaligned && blIsAligned(srcData, PixelAccess::kSize)) {
for (uint32_t i = w; i != 0; i--) {
uint32_t pix = PixelAccess::fetchA(srcData);
uint32_t r = (((pix >> rShift) & rMask) * rScale) >> 16;
uint32_t g = (((pix >> gShift) & gMask) * gScale) >> 8;
uint32_t b = (((pix >> bShift) & bMask) * bScale) >> 8;
uint32_t a = (((pix >> aShift) & aMask) * aScale) >> 24;
BLPixelOps::unpremultiply_rgb_8bit(r, g, b, a);
blMemWriteU32a(dstData, (a << 24) | (r << 16) | (g << 8) | b);
dstData += 4;
srcData += PixelAccess::kSize;
}
}
else {
for (uint32_t i = w; i != 0; i--) {
uint32_t pix = PixelAccess::fetchA(srcData);
uint32_t r = (((pix >> rShift) & rMask) * rScale) >> 16;
uint32_t g = (((pix >> gShift) & gMask) * gScale) >> 8;
uint32_t b = (((pix >> bShift) & bMask) * bScale) >> 8;
uint32_t a = (((pix >> aShift) & aMask) * aScale) >> 24;
BLPixelOps::unpremultiply_rgb_8bit(r, g, b, a);
blMemWriteU32a(dstData, (a << 24) | (r << 16) | (g << 8) | b);
dstData += 4;
srcData += PixelAccess::kSize;
}
}
dstData = blPixelConverterFillGap(dstData, gap);
dstData += dstStride;
srcData += srcStride;
}
return BL_SUCCESS;
}In this code fragment, then and else branches are completely the same. This code was clearly written using the copy-paste method. A programmer copied the inner loop, and then got distracted and forgot to replace the PixelAccess::fetchA function call with PixelAccess::fetchU in the second loop.
Fortunately, the PVS-Studio static analyzer noticed the anomaly and issued a warning: V523 The 'then' statement is equivalent to the 'else' statement. pixelconverter.cpp 1215
This classic copy-paste error appeared, because the programmer was a little lazy when writing the code. There are at least 3 ways to avoid code duplication and at the same time reduce the likelihood of the error mentioned above.
The first option is to move the inner loop into a separate function and pass it an additional flag that will indicate whether to call PixelAccess::fetchA or PixelAccess::fetchU.
I don't like this option, since you will need to pass a lot of arguments to this new function. So, we are not going to look at it in detail. I would only point out that even this option reduces the chances of error. It's hard to forget to use the function argument (flag). Moreover, even the compiler will warn that the argument is not used.
The second option is to move the common code into a lambda function. So, the code might look something like this:
static BLResult BL_CDECL bl_convert_argb32_from_prgb_any(
const BLPixelConverterCore* self,
uint8_t* dstData, intptr_t dstStride,
const uint8_t* srcData, intptr_t srcStride,
uint32_t w, uint32_t h, const BLPixelConverterOptions* options) noexcept {
if (!options)
options = &blPixelConverterDefaultOptions;
const size_t gap = options->gap;
dstStride -= uintptr_t(w) * 4 + gap;
srcStride -= uintptr_t(w) * PixelAccess::kSize;
const BLPixelConverterData::NativeFromForeign& d =
blPixelConverterGetData(self)->nativeFromForeign;
uint32_t rMask = d.masks[0];
uint32_t gMask = d.masks[1];
uint32_t bMask = d.masks[2];
uint32_t aMask = d.masks[3];
uint32_t rShift = d.shifts[0];
uint32_t gShift = d.shifts[1];
uint32_t bShift = d.shifts[2];
uint32_t aShift = d.shifts[3];
uint32_t rScale = d.scale[0];
uint32_t gScale = d.scale[1];
uint32_t bScale = d.scale[2];
uint32_t aScale = d.scale[3];
auto LoopImpl = [&](const bool a)
{
for (uint32_t i = w; i != 0; i--) {
uint32_t pix = a ? PixelAccess::fetchA(srcData) :
PixelAccess::fetchU(srcData);
uint32_t r = (((pix >> rShift) & rMask) * rScale) >> 16;
uint32_t g = (((pix >> gShift) & gMask) * gScale) >> 8;
uint32_t b = (((pix >> bShift) & bMask) * bScale) >> 8;
uint32_t a = (((pix >> aShift) & aMask) * aScale) >> 24;
BLPixelOps::unpremultiply_rgb_8bit(r, g, b, a);
blMemWriteU32a(dstData, (a << 24) | (r << 16) | (g << 8) | b);
dstData += 4;
srcData += PixelAccess::kSize;
}
}
for (uint32_t y = h; y != 0; y--) {
LoopImpl(!AlwaysUnaligned && blIsAligned(srcData, PixelAccess::kSize));
dstData = blPixelConverterFillGap(dstData, gap);
dstData += dstStride;
srcData += srcStride;
}
return BL_SUCCESS;
}In fact, for this example, there is no need to move anything into the function at all. But I wanted to show how an approach with a function can shorten the code and reduce the likelihood of an error.
The third option is the simplest and most natural — to do the check inside the loop.
static BLResult BL_CDECL bl_convert_argb32_from_prgb_any(
const BLPixelConverterCore* self,
uint8_t* dstData, intptr_t dstStride,
const uint8_t* srcData, intptr_t srcStride,
uint32_t w, uint32_t h, const BLPixelConverterOptions* options) noexcept {
if (!options)
options = &blPixelConverterDefaultOptions;
const size_t gap = options->gap;
dstStride -= uintptr_t(w) * 4 + gap;
srcStride -= uintptr_t(w) * PixelAccess::kSize;
const BLPixelConverterData::NativeFromForeign& d =
blPixelConverterGetData(self)->nativeFromForeign;
uint32_t rMask = d.masks[0];
uint32_t gMask = d.masks[1];
uint32_t bMask = d.masks[2];
uint32_t aMask = d.masks[3];
uint32_t rShift = d.shifts[0];
uint32_t gShift = d.shifts[1];
uint32_t bShift = d.shifts[2];
uint32_t aShift = d.shifts[3];
uint32_t rScale = d.scale[0];
uint32_t gScale = d.scale[1];
uint32_t bScale = d.scale[2];
uint32_t aScale = d.scale[3];
for (uint32_t y = h; y != 0; y--) {
const bool a = !AlwaysUnaligned && blIsAligned(srcData, PixelAccess::kSize);
for (uint32_t i = w; i != 0; i--) {
uint32_t pix = a ? PixelAccess::fetchA(srcData) :
PixelAccess::fetchU(srcData);
uint32_t r = (((pix >> rShift) & rMask) * rScale) >> 16;
uint32_t g = (((pix >> gShift) & gMask) * gScale) >> 8;
uint32_t b = (((pix >> bShift) & bMask) * bScale) >> 8;
uint32_t a = (((pix >> aShift) & aMask) * aScale) >> 24;
BLPixelOps::unpremultiply_rgb_8bit(r, g, b, a);
blMemWriteU32a(dstData, (a << 24) | (r << 16) | (g << 8) | b);
dstData += 4;
srcData += PixelAccess::kSize;
}
dstData = blPixelConverterFillGap(dstData, gap);
dstData += dstStride;
srcData += srcStride;
}
return BL_SUCCESS;
}That's a great example of code where it's possible to get rid of code duplication. However, this is not always possible. Sometimes the copy-paste and the error caused by it are clearly visible, but it is not clear how this could have been avoided. Let's look at the example of a bug we found in LLVM 15.0:
static std::unordered_multimap<char32_t, std::string>
loadDataFiles(const std::string &NamesFile, const std::string &AliasesFile) {
....
auto FirstSemiPos = Line.find(';');
if (FirstSemiPos == std::string::npos) // <=
continue;
auto SecondSemiPos = Line.find(';', FirstSemiPos + 1);
if (FirstSemiPos == std::string::npos) // <=
continue;
....
}The code was written using copy-paste. Here's the fragment that was copied:
auto FirstSemiPos = Line.find(';');
if (FirstSemiPos == std::string::npos)
continue;Then the call to the find function was changed. First was replaced by Second but not in every place. As a result, the following line
if (FirstSemiPos == std::string::npos)remained unchanged. Since this condition has already been checked above, the PVS-Studio analyzer reports that the condition is always false: V547 Expression 'FirstSemiPos == std::string::npos' is always false. UnicodeNameMappingGenerator.cpp 46
In this case, there is nothing to generalize and move into the function. And it is not clear how to write this code in another way to avoid an error.
Some might say: don't copy the code, write it again. Then there would be no error. And if you want to copy something, that's a reason to stop, think and make a function or write code in a different way.
It sounds reasonable, but I don't believe in this approach. No matter what they say, but sometimes it is fast, convenient and effective to copy a piece of code. So, I won't be so adamant to suggest never using copy-paste.
Moreover, I doubt the sincerity of people who encourage you to never use code copying. Probably, they left a smart comment to seem more perfect than others, and went on to do copy-paste in their project :).
Well, everyone copied the code and will continue to do so. Yes, the number of such cases can and should be reduced. However, we must admit that some fragments will be copied anyway, and this will lead to errors. So, what to do?
The advice is still the same:
If you can refer to the next element outside the array, it means that it's possible to access this element as well.
Opps, this is the 61st tip, but I promised 60. Sorry, but what a collection of terrible tips without array index out of bounds!
Array index out of bounds leads to undefined behavior. However, there is one point that may confuse a junior programmer.
C++ allows to refer to the element past the end of an array. For example, the following code:
int array[5] = { 0, 1, 2, 3, 4 };
int *P = array + 5;However, the P pointer's value can only be compared with other values but not dereferenced.
Such permission allows to build an elegant concept of iterators. In classes for working with arrays, the end function returns an iterator that points to an element located behind the last container element. The end iterator can be compared with other iterators, but it cannot be dereferenced.
In addition, programmers simply inadvertently make a mistake by going 1 element outside the array. Such an error even has a name — off-by-one error. The reason is that the elements in the array are numbered from 0. This may be confusing sometimes, especially when writing code in a hurry.
Most often, the error occurs due to incorrect index validation. Developers check that the index is not greater than the number of elements in the array. But this is incorrect: if the index is equal to the number of elements, it already refers to an element outside the array. Let's explain this with an example.
The following error was found by the PVS-Studio static analyzer in Clang 11. So, as you can see, not only juniors make such mistakes.
std::vector<Decl *> DeclsLoaded;
SourceLocation ASTReader::getSourceLocationForDeclID(GlobalDeclID ID) {
....
unsigned Index = ID - NUM_PREDEF_DECL_IDS;
if (Index > DeclsLoaded.size()) {
Error("declaration ID out-of-range for AST file");
return SourceLocation();
}
if (Decl *D = DeclsLoaded[Index])
return D->getLocation();
....
}The correct check should be as follows:
if (Index >= DeclsLoaded.size()) {Don't miss out our new articles, subscribe to our monthly newsletter.
I know it was a huge article. Thank you for your attention and your time. I would be grateful, if you share the link to this article with your colleagues. And please write down what you disagree with or, on the contrary, where I definitely touched a sore spot :).
{kind=link}
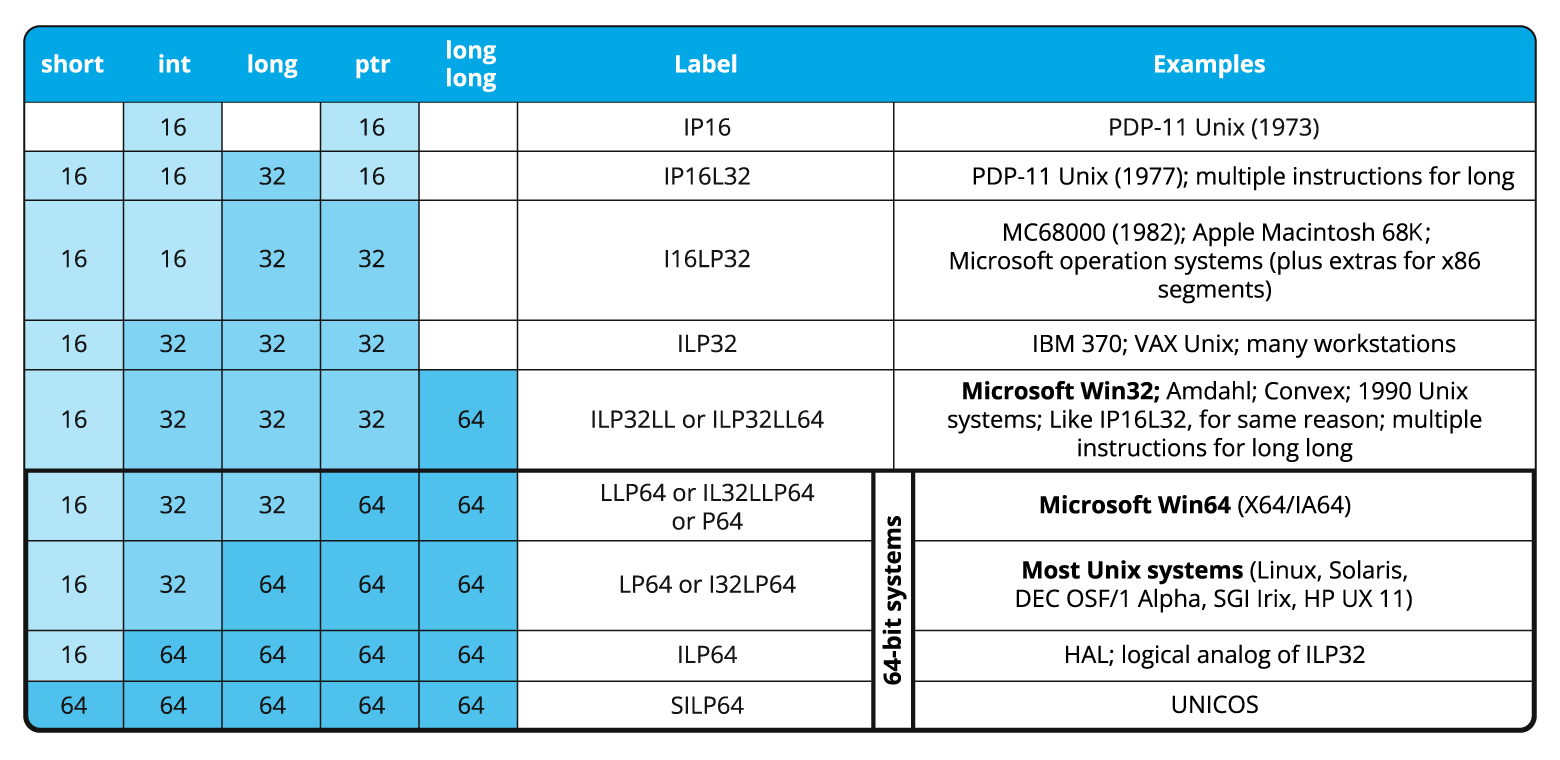{kind=link}