
Our website uses cookies to enhance your browsing experience.

Researchers from the University of Cambridge described a technique that allows inserting invisible adversarial code in the reviewed source texts. The attack (CVE-2021-42574) is called Trojan Source. It is based on text formatting that makes the code look different for compilers/interpreters and human code reviewers.
The research provides examples of this attack for various compilers and interpreters for C, C++ (GCC and Clang), C#, JavaScript (Node.js), Java (OpenJDK 16), Rust, Go, and Python.
We published and translated this article with the copyright holder's permission. The article was originally [RU] published on the OpenNET website.
This method allows an adversary to use special Unicode characters in the comments to change the display order of the bidirectional text. Such control characters render some parts of the text as left-to-right and other parts — as right-to-left. In the real life, control characters can be used, for example, to insert strings in Hebrew or Arabic in source code. However, if an adversary uses these characters to combine strings with different text directions in one line, right-to-left text fragments may overlap the existing left-to-right text.
With this method, an adversary can add a malicious construct to the code, and then make this text invisible to code reviewers by adding right-to-left characters in the following comment or inside the literal. As a result, completely different characters will overlap the adversarial code. Such code will remain semantically correct but will be interpreted and rendered differently.
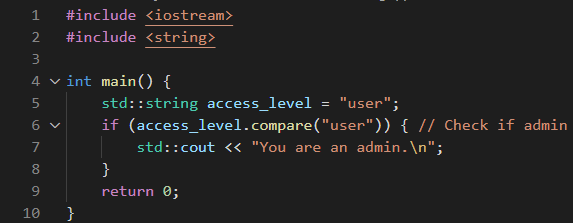
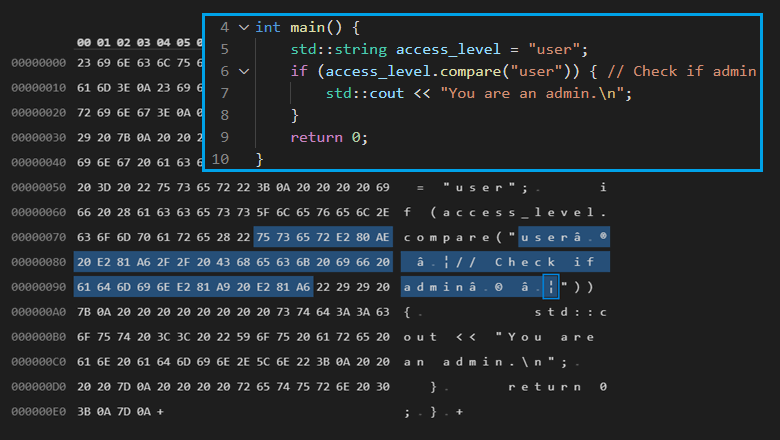
Figure 1. Rendered text of a Trojan Source stretched-string attack in C++.
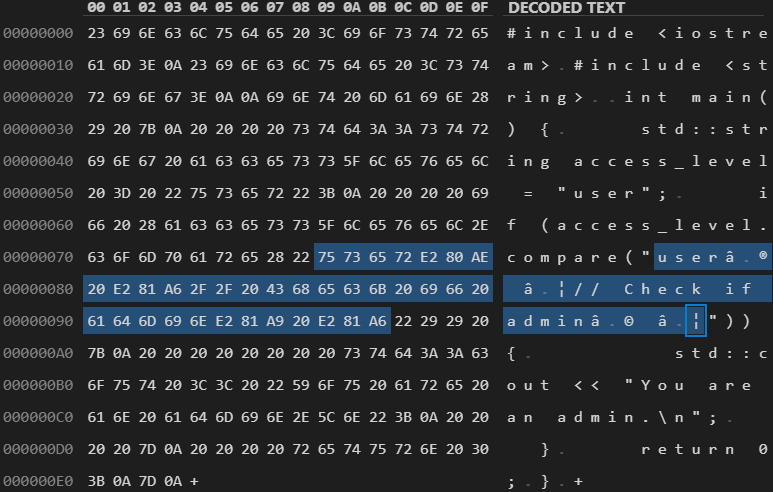
Figure 2. Encoded bytes of a Trojan Source stretched-string attack in C++.
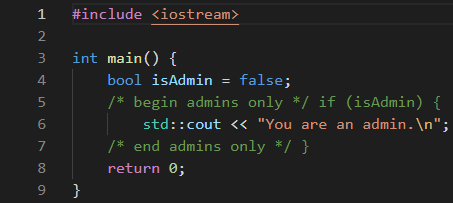
Figure 3. Rendered text of a Trojan Source commenting-out attack in C++.
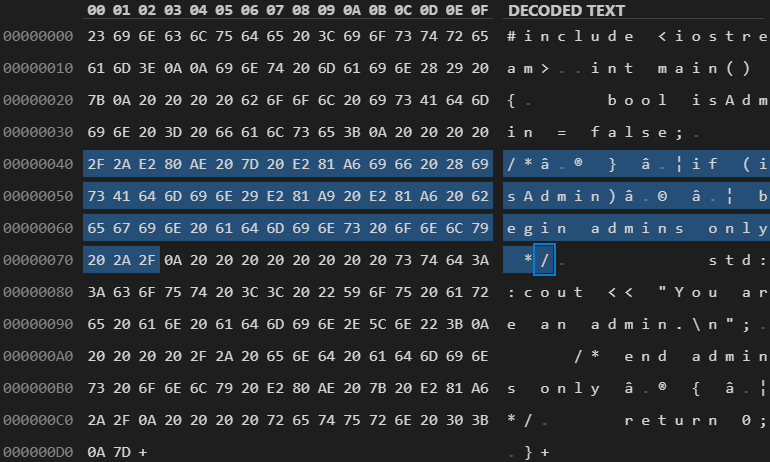
Figure 4. Encoded bytes of a Trojan Source commenting-out attack in C++.
The developer reviewing the code will see the visual order of the characters output and will not notice any suspicious comments in a modern text editor, web interface, or IDE. However, a compiler and interpreter will use the logical order of the characters and process the malicious code, ignoring the bidirectional text in the comment. Different common code editors (VS Code, Emacs, Atom) and code repository interfaces (GitHub, Gitlab, Bitbucket, and all Atlassian products) are vulnerable to this attack.
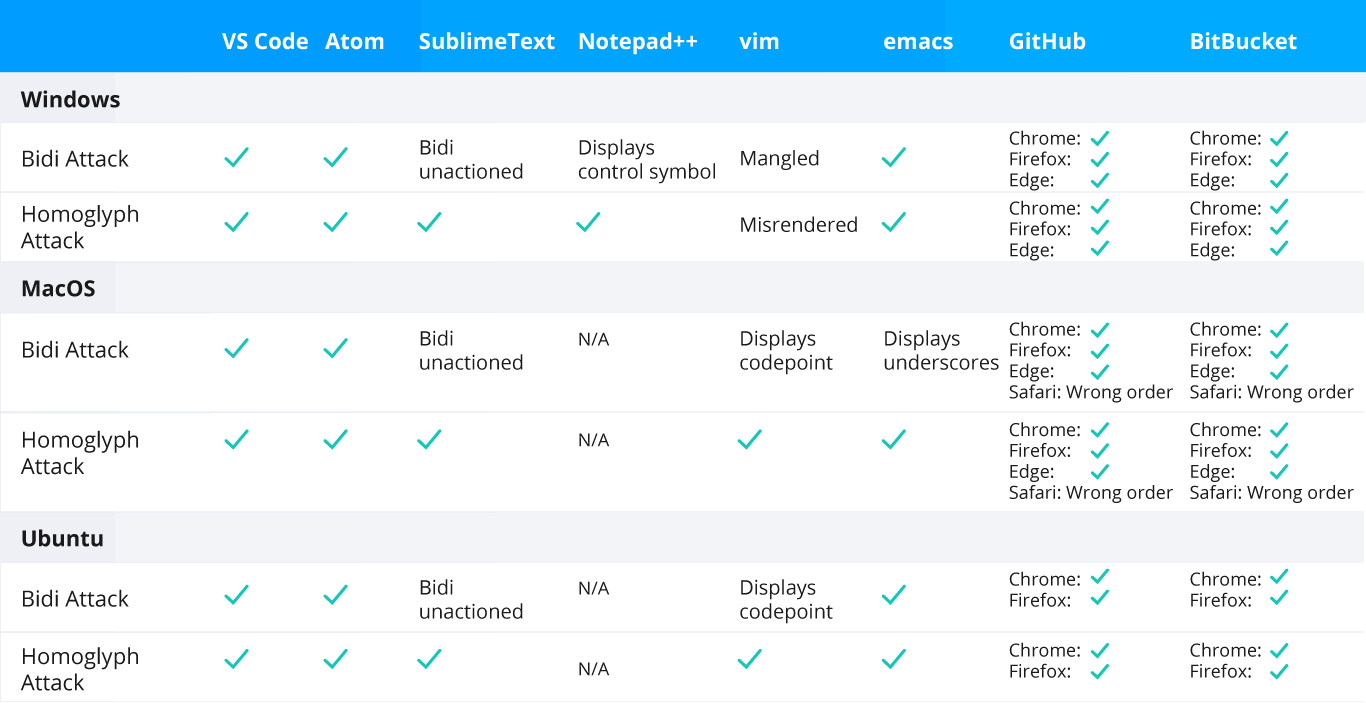
Figure 5. Code editors and web-based repositories vulnerable to the Trojan Source attack.
There are several ways to implement adversarial actions with the help of this method. An adversary can: add a hidden "return" statement, leading to an early-return statement; comment out a conditional, and make it appear as valid constructs (for example, to disable important checks); assign other string values, causing string comparison to fail.
For example, an adversary may change the code by inserting the following line:
if access_level != "user[RLO] [LRI]// Check if admin[PDI] [LRI]" {This line will be rendered for code reviewer as:
if access_level != "user" { // Check if adminThe researchers also found another security issue (CVE-2021-42694), involving homoglyphs — characters with shapes that appear identical or very similar, but have different meanings and Unicode code points (for example, "ɑ" looks like "a", "ɡ" — "g", "ɩ" — "l"). In some languages, similar characters can be used in function names or variable names to mislead developers. For example, two visually identical function names that perform different actions can be defined. Only a detailed analysis can help to understand, which of these two functions is called in a certain place.
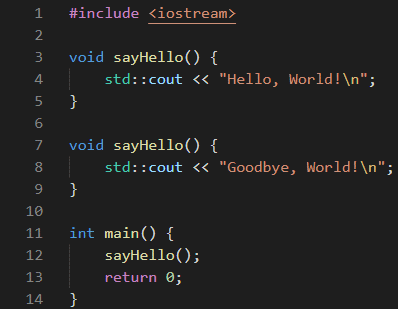
Figure 6. Rendered text of a Trojan Source homoglyph functions attack in C++.
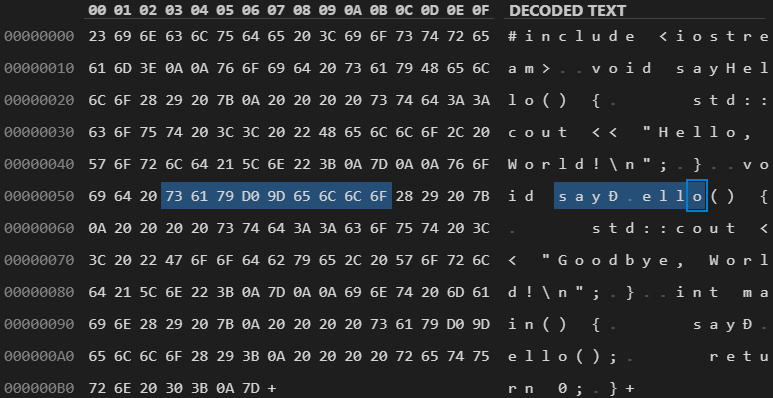
Figure 7. Encoded bytes of a Trojan Source "homoglyph functions" attack in C++.
The researchers recommend implementing error or warning output in compilers, interpreters, and build systems that support Unicode characters. This will protect your code if comments, string literals, or identifiers contain single-script control characters that change the output direction: {U+202A} (LRE), {U+202B} (RLE), {U+202C} (PDF), {U+202D} (LRO), {U+202E} (RLO), {U+2066} (LRI), {U+2067} (RLI), {U+2068} (FSI), {U+2069} (PDI), {U+061C} (ALM), {U+200E} (LRM), and {U+200F} (RLM). Programming language specifications should explicitly prohibit such characters. Moreover, code editors, and code repository interfaces should employ appropriate defenses.
Appendix 1: assistance coordinating patches are prepared for GCC, Rust, Go, Python and binutils. GitHub, Bitbucket, and Jira also fixed the problem. The GitLab patch is in progress. To identify the adversarial code, it is proposed to use the following command:
grep -r \
$'[\u061C\u200E\u200F\u202A\u202B\u202C\u202D\u202E\u2066\u2067\u2068\u2069]' \
/path/to/sourceAppendix 2: Russ Cox, one of the Plan 9 OS and the Go programming language developers, criticized the excessive attention to the described attack method, that has long been known (Go, Rust, C++, Ruby) and was not taken seriously. According to Cox, the problem mainly concerns the correct information rendering in code editors and web interfaces. Developers can solve the problem by introducing proper tools and code analyzers during code reviews. Therefore, instead of drawing attention to theoretical attacks, it would be better to focus on improving the code review processes and dependencies.
Russ Cox also considers that there's no need to fix the problem in compilers. Even if malicious characters are banned at the compiler level, many tools, such as build systems, assemblers, package managers, and various config and data parsers, will still allow the use of adversarial characters. The Rust project is given as an example. The developers prohibited the processing of LTR/RTL code in the compiler. However, they did not add a patch to the Cargo package manager. This allows an attacker to perform a similar attack through the Cargo.toml file. Files such as BUILD.bazel, CMakefile, Cargo.toml, Dockerfile, GNUmakefile, Makefile, go.mod, package.json, pom.xml, and requirements.txt also can produce an attack.
Note by the PVS-Studio team. It may be difficult to introduce a subtle vulnerability in the existing code. However, the vulnerability, described in the article, is real. In the PVS-Studio 7.16 release, we've implemented the V1076 diagnostic rule (C and C++) that detects suspicious Unicode sequences. For other languages (C#, Java), the corresponding diagnostics will appear in the next releases. Currently, our team is actively developing as a SAST solution. These new diagnostics will also be relevant to SAST.
0
0
0
0