
Our website uses cookies to enhance your browsing experience.

In my previous article I wrote that I don't like the approach of evaluating the efficiency of static analyzers with the help of synthetic tests. In that article, I give the example of a code fragment that the analyzer treats as a special case, and deliberately doesn't issue a warning for. To be honest, I didn't expect such an overflow of comments regarding the fact that an analyzer may not issue warnings because of the mechanisms of false positive elimination. In general the topic of battling against false positives is such a huge part of any static analyzer that it's really not clear what we can discuss here; but still, let's talk about it. Such mechanisms exist not only in our analyzer but also in another analyzers/compilers. Nevertheless, if this topic brought about so much discussion, I think it's worth talking about, and so I wrote this explanatory article.

It all started with the post "Why I dislike synthetic tests". I mostly meant it to be "just in case article". Sometimes in discussions, I need to describe why I dislike certain synthetic tests. It's quite hard to write long and detailed answers every time, so I've been long planning to write an article that I would use for these cases. So when I was examining itc-benchmarks, I realized that this was a good chance to write an article, as there are a couple of tests I can cite in the article.
But I didn't expect such a huge amount of negative feedback from programmers on various forums, and by email. Perhaps, the reason is that I've been working on static analyzers for 10 years already, and some issues seem so obvious to me that I judge too categorically without much explanation. To avoid misunderstanding, I will tell how and why we fight against false positives.
The text of the article may refer to any tool, and it has little to do with PVS-Studio itself. The same article could be written by any other developer from GCC, Coverity, or Cppcheck.
Before proceeding to the main topic I would like to clarify a couple of points concerning false positives markup. I got an impression that some people started writing negative comments without proper investigation into what it is all about. I saw comments of this kind:
You went the wrong way. Instead of providing mechanism of false positive suppression, you try to eliminate them yourself as much as you can and most probably make mistakes.
Here is my explanation, so that we cover this topic and don't go back to it again. PVS-Studio provides several mechanisms to eliminate false positives, which are inevitable anyway:
You may find more details about these abilities in the documentation section "Suppression of false positives". You can also disable warnings or suppress warnings in macros using configuration files (see pvsconfig)
We should also note the system of mass false positives suppression, with the help of a special markup base. It allows quick integration of the analyzer to the development process of large projects. The ideology of this process is described in the article Best Practices of PVS-Studio (Now with C# support).
All of this refers to the idea of what not to consider as errors. However, the task of minimizing warnings with the help of special exceptions, is still there. The value of an analyzer is not that it issues warnings for any erroneous code, but that it knows when not to issue the warnings.
Now a little bit of theory. Each analyzer warning has two characteristics:
These two criteria can be combined in any proportion. And so, we can describe the types of diagnostics using a two-dimensional graph:
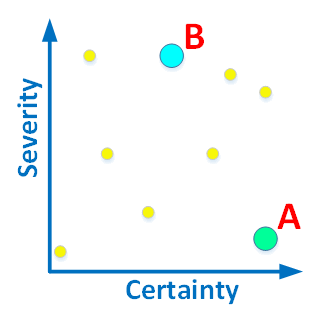
Figure 1. The diagnostics can be assessed by the severity and certainty (reliability).
I will provide a couple of explanatory examples: The diagnostic A, detecting that a *.cpp file has no headers from the comments, will be located in the right lower corner. A forgotten comment will not lead to a program crash, although it is an error from the point of view of the coding standard of the team. We can say for definite whether there is a comment or not. Therefore, the certainty rate is very high.
The diagnostic B, detecting that some of the class members are not initialized in the constructor will be located in the middle of the upper part. The certainty rate of this error is not very high because the analyzer may simply not understand how and where this member is initialized (it is complicated). A programmer may do the initialization after the constructor was executed. Thus, an uninitialized member in the constructor is not necessarily an error. But this diagnostic is in the upper part of the graph, because if it really points to an error, it will be critical for the program. Using an uninitialized variable is a serious defect.
Hopefully the idea is clear. However, I think the reader would agree that such distribution of errors on the graph is difficult for perception. That's why some analyzers simplify this graph to a table of 9 or 4 cells.
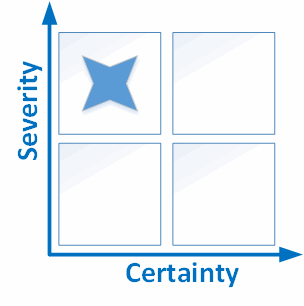
Figure 2. A simplified version of the classification. Using 4 cells.
That's what the authors of Goanna analyzer did before they were bought by Coverity, which was later bought by Synopsis. They classified the warnings issued by the analyzer referring them to one of 9 cells.

Figure 3. A fragment from Goanna reference guide (Version 3.3). Uses 9 cells.
However, this technique is not very common, and uncomfortable to use. Programmers want the warnings to be located on a one-dimensional graph: not important-> important. It's more familiar as the compiler warnings use the same principles.
It's not an easy task, to simplify a two dimensional classification to one-dimensional. Here's how we did it in the PVS-Studio analyzer. We simply don't have the bottom part of two-dimensional graph:
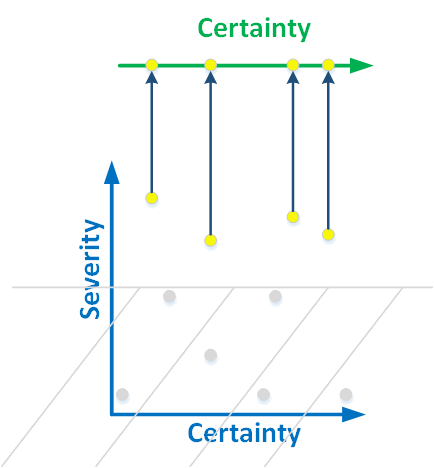
Figure 4. We project the warnings of high severity to a line. The errors start being classified by the level of certainty.
We detect only those errors that can lead to incorrect program operation. Forgetting a comment at the beginning of the file may not lead to a program crash, and is not interesting to us. But we do search for uninitialized members of the class, because it is a critical error.
Thus, we need to classify errors according to their level of certainty. This level of certainty distributes the analyzer warnings into three groups (High, Medium, Low).

Figure 5. A fragment of PVS-Studio interface window. We see general analysis diagnostics of High and Medium level.
At the same time, one warning can get to different levels depending on the level of confidence of the analyzer that it found a real error, and has not issued a false positive.
I should emphasize once more that all warnings search for bugs that could be critical for a program. But sometimes the analyzer is more confident, sometimes less.
Note. Of course, there is certain relativity here. For example in PVS-Studio there is a warning V553, that the analyzer issues when it sees a function that is longer than 2000 lines. This function may not necessarily have an error. But in practice the probability that this function is the source of errors is very high. It's impossible to test this function with unit tests. So we can consider such a function as a defect in the code. However, there are just a few such diagnostics, because the main task of the analyzer is to look for errors like 'array index out of bounds', 'undefined behavior', and other fatal errors (see the table).
PVS-Studio warnings detect those code fragments, which are more or less likely lead to serious problems in the workings of a program. This is why the levels of warnings in PVS-Studio are not the level of severity, but their certainty. However, severity may also be taken into account when distributing the warnings across the levels; but we're not going to go into such details, as we're more interested in the overall picture.
Briefly: Levels indicate the certainty of the reported issue.
The criticism expressed in the previous article, was mainly against the idea of losing useful warnings, when fighting false positives. In fact, the warnings don't get lost - they just fall into different levels of severity. And those rare variants of errors that our readers were so anxious about, usually just get to the Low level, that we usually do not recommend for viewing. Only pointless warnings disappear completely.

Figure 6. It's good to have something just in case. But you should stop at some point.
Our readers may have been worried by my words that some useful warning may disappear. I don't see any point in denying it. Such a possibility exists, but it is so small that it's not worth worrying about. I can show using real examples, that there is no point in considering such cases. But let's continue the topic of distributing warnings across different levels.
In some cases it's clear which level of certainty this error is. As an example let's have a look at a simple diagnostic V518 that detects the following error pattern:
char *p = (char *)malloc(strlen(src + 1));Mostly likely a programmer misplaced a parenthesis. He wanted to add one byte to have space to place a terminal null. But he made a mistake, and as a result the memory allocates two bytes less than it should.
We could assume that the programmer wanted to write this code, but the probability is very small. That's why the certainty level of this warning is very high, and we place it to the group of high-level warnings.
By the way, this diagnostic has no false positives. If this pattern was found, then there's an error.
In other cases it may be clear right away that the certainty level is Low. We have very few of such diagnostics, as it usually means that it was a badly written diagnostic. One such unfortunate diagnostic is V608, that detects repeating sequences that consist of explicit type casting operators. It looks for statements of this kind:
y = (A)(B)(A)(B)x;I don't even remember why we made this diagnostic. Until now I haven't seen this diagnostic detect a real bug. It usually finds redundant code (especially in complex macros), but not bugs.
The majority of diagnostics shift the levels depending on the analyzer's confidence that it found a real bug.
We interpret the levels in the following way:
High (first level). Most likely this is a bug. This code requires reviewing.
Even if this is not an error, the code is poorly written, and it should be fixed anyway, so that it doesn't confuse analyzers or other team members. Let me explain using an example:
if (A == B)
A = 1; B = 2;Perhaps, there is no mistake here, the curly brackets are not necessary either. There is a tiny possibility that the programmer wanted to assign the variable B with value 2. But I think everybody will agree that it's better to rewrite such code, even if there is no error.
if (A == B)
A = 1;
B = 2;Medium (second level). This code seems to contain an error, but the analyzer is not sure. If you have fixed all the High level warnings, it would be useful to work on the Medium level errors.
Low (third level). These are warnings with Low level or low certainty and we do not recommend viewing them at all. Take note that when we write articles on the checks of projects, we consider only High and Medium levels, and do not write about low Level warnings at all.
When we worked with the Unreal Engine project, we did the same. Our aim was to eliminate all first and second level warnings. We didn't consider the Low level warnings.
As I have already said, most diagnostics can get various levels depending on the set of characteristics. Some characteristics may increase and others may decrease the level of certainty. They are chosen empirically based on testing the diagnostic on more than 100 open source projects.
See how a diagnostic can move across different levels. Let's take diagnostic V572 as an example. This diagnostic warns about suspicious explicit type casting. The programmer creates an object of a class with the help of a new operator, then a pointer to this object is cast to a different type:
T *p = (T *)(new A);It is a strange construction. If the class A is inherited from T, then this casting is redundant, and it can be removed. If it is not inherited then it is most likely a bug. However, the analyzer is not completely sure that this is it an error, and places this diagnostic to the Medium level. Such a construction may really seem very strange, but sometimes this really is correctly working code. It's hard to bring any example, though.
It is much more dangerous if a programmer creates an array of elements and then casts it to a pointer to base class:
Base *p = (Base *)(new Derived[10]);In this case the analyzer issues a high level warning. The size of the base class can be less than the size of the inherited class, and then when accessing the element p[1] , we will be working with incorrect data. Even if now the size of the base class and of the inherited classes is the same, this code needs fixing. For some time it may all work fine, but it's very easy to break everything by adding a new class member to the inheritance class.
There's an opposite situation when a programmer casts to the same type.
T *p = (T *)(new T);This code may appear if somebody has worked with C for too long, and has forgotten that unlike the call of malloc function, a compulsory type casting is not necessary. Or, in the result of refactoring of the old code, when a C program turns into C++.
There is no error here, and therefore no need to issue a warning at all. The analyzer leaves this warning just in case, but moves it to the Low level. A programmer doesn't have to review this warning and fix this code; though if he wants everything to look nice and neat, he may do so.
In the comments to the previous article some readers worried that warnings that are likely to point to a real bug, may disappear from the analysis. As a rule, such warnings don't disappear, they move to a low level. We have just reviewed one such example. "T *p = (T *)(new T);". There is no error here, but what if there is something wrong here... Those who are willing, may examine this code.
Let's have a look at a different example. Diagnostic V531: It is odd that a sizeof() operator is multiplied by sizeof().
size_t s = sizeof(float) * sizeof(float);It is a meaningless statement, and most likely there was an error here; probably a typo. The analyzer will issue a warning of the High level.
But there is a situation when the level is changed to Low. This happens when one of the multipliers is sizeof(char).
Of all the "sizeof (T) * sizeof (char)" expressions we have seen, in more than a hundred projects they were not mistakes. Almost always, these were some macros where such multiplication was caused by substitution of one macro with another.
In general, you may not even need to look at these warnings, so they are hidden on the Low level. However if you wish, you may have a look at them.

Figure 7. Now the reader knows that he may bravely start the journey across the vast seas of the Low level warnings.
There are exceptions to existing diagnostics, and for groups of diagnostics. Let's start with the "exceptions of mass destruction". Sometimes in programs there is code that never gets executed. Thus there really is no need to search for errors in it. As the code isn't executed, then the errors will not appear. This is why most diagnostics do not apply to un-executable code. I'll explain using an example.
int *p = NULL;
if (p)
{
*p = 1;
}When dereferencing a pointer, its only possible value is NULL. There is no other value that could be stored in the variable 'p'. But an exception is triggered that the dereference is in the code that never gets executed. And if it doesn't get executed then there is no error there. The dereference will occur only in the case that the p value has a value different from NULL.
Some may say that the warning could be useful, as it shows that the condition is always false. But this is a concern for other diagnostics, for example, V547.
Will it be useful to anyone if the analyzer starts issuing warnings that in the code cited above, a null pointer gets dereferenced? No.
Now let's turn to some particular exceptions in diagnostics. Let's go back to our V572 diagnostic that we discussed earlier:
T *p = (T *)(new A);There are exceptions, when this message will not be issued. One such case, is casting to (void). Example:
(void) new A();A programmer creates the object, and deliberately leaves it in the code till the end of the program execution. This construction couldn't appear just because of a typo. This is a deliberate action to suppress warnings from compilers and analyzers for the statements:
new A();Many tools will complain about this construction. A compiler/analyzer suspects that a person forgot to write a pointer that will be returned by the new operator. So a person deliberately suppressed warnings, by adding casting to the void type.
Yes, this code is strange. But if a person asks to leave his code alone, that should do this. The task of the analyzer is to look for the bugs, not to make a person write more sophisticated constructions to confuse the compiler/analyzer, and get rid of the warnings.
Will it be useful to anyone if the message is issued anyway? No. A person who wrote this code, won't be very thankful.
Now let's go back to diagnostic V531:
sizeof(A) * sizeof(B)Are there cases when the analyzer should not issue any warnings, even of the Low level? Yes, there are.
A typical task: it is necessary to evaluate the size of the buffer, whose size is a multiple of the size of another buffer. Let's say there is an array of 125 items of int type, and we have to create an array of 125 items of double type. To do this, the number of array elements must be multiplied by the size of the object. But it's very easy to make a mistake evaluating the number of elements. Therefore, programmers use special macros to safely calculate the number of elements. Learn more on why and how to do this from the articles (see here on the arraysize macro).
After expanding the macro, we get the following construction:
template <typename T, size_t N>
char (*RtlpNumberOf( __unaligned T (&)[N] ))[N];
....
size_t s = sizeof(*RtlpNumberOf(liA->Text)) * sizeof(wchar_t);The first sizeof is used to evaluate the number of elements. The second sizeof evaluates the size of the object. As a result, everything works fine, and we evaluate the array size, in bytes, correctly. Perhaps it is not quite clear what I'm talking about here, so I should apologize for not giving additional explanation of this behavior.
In general there is some magic when two sizeof operators are multiplied - it is a normal and expected result. The analyzer is able to detect the pattern of this size buffer evaluation, and does not issue a warning.
Again, will it be useful to anybody if the analyzer issues warnings anyway? No. This code is totally correct and reliable. It should be written like this.
Let's move on. The analyzer will issue a warning V559 for the construction
if (a = 5)To suppress a warning for such code we should enclose the expression in additional parenthesis:
if ((a = 5))This is a hint to analyzers and compilers that there is no error here and the person wants to assign a value inside the condition. I have no idea who came up with such a method, or when; but I know that it is quite common, and supported by many compilers and analyzers.
PVS-Studio analyzer also won't complain about this code.
Perhaps we should have moved this warning to the Low level, rather than completely suppressing it? No. Is there a chance that a person will accidentally put extra parentheses around an incorrect statement? Yes, but a very small chance.
Do you often put extra parentheses? I don't think so. I think it happens once per 1000 if operators, or even less frequently. So, the probability said error will be made because of extra parentheses, is less than 1 in 1000.
Would it still be a good idea to issue a warning? No. This is a case where a false positive can be avoided, and at the same time the probability of finding a real bug is extremely small.
I have already provided these arguments in the comments of the previous article, but they were not convincing enough. So, I decided to approach this topic from another angle.
I have a question for those who want to see all the possible warnings from the analyzer. Have you covered 100% of your code with unit tests? No? How come, you may have errors there!
I should also mention this point here; It's very hard and expensive to cover 100% of your code with unit tests. The cost of this unit test coverage won't be worth the effort or time.
The same idea can be applied to a static analyzer. There comes a point when time spent examining warnings may exceed all reasonable limits. This is why there is no practical sense in issuing as many warnings as possible.
Let's consider one more case, where the warning V559 does not get issued:
if (ptr = (int *)malloc(sizeof(int) * 100))It is a classical pattern of memory allocation, and verification that the memory was allocated. It's clear that there is no mistake here. A person really did not mean to write:
if (ptr == (int *)malloc(sizeof(int) * 100))Such a statement does not have any practical sense, and will lead to a memory leak. So, the assignment within a condition is exactly what the programmer wanted to do.
Will it have any practical use if the analyzer starts issuing warnings for such constructions? No.
Let conclude the chapter with another example of an exception. It is a little harder to explain it but I will try to convey our philosophy regarding this case.
Diagnostic V501 is one of the leaders by the number of exceptions. However, these exceptions do not hinder the correct workings of the diagnostic (proof).
The diagnostic issues warnings for statements of this kind:
if (A == A)
int X = Q - Q;If the left and right operands are the same, it is suspicious.
One of the exceptions states that it is not necessary to issue a warning if the operation '/' or '-' applies to numeric constants. Examples:
double w = 1./1.;
R[3] = 100 - 100;The thing is, that programmers often write such statements without simplifying them. It helps them understand the main point of the program better. Such situations are most common for applications that perform large numbers of evaluations.
Here is an example of real code, containing such statements:
h261e_Clip(mRCqa, 1./31. , 1./1.);Can we miss an error because of such a statement? Yes, we can. However, the benefits of reducing the number of false positives greatly exceeds the potential loss of useful warnings.
Such division or subtraction is a standard common practice in programming. The risk of losing the warning is justified.
Is there a chance that a programmer intended to write a different statement? Yes, there is. But such discussions will lead us nowhere. The phrase "perhaps he programmer wanted to write something else", can be applied to 1./31, so here we may come to the idea of the perfect analyzer, that issues warnings for all the lines in the program, even for empty ones. Just in case, thinking that it can be wrong or perhaps the foo() function should be called for.

Figure 8. It is important to stop at some point. Otherwise the useful task of examining the warnings will become a waste of time.
It is much better to lose one useful warning, than to show 1000 useless warnings. There is nothing dreadful in it. The ability to detect useful errors is not the only criterion of analyzer efficiency. The balance between useful and useless warnings is also very important. Attention can be lost very quickly. Viewing a log with large numbers of false positives, a person begins inattentively scanning the warnings, and skips a lot of errors, not marking them as bugs.
I suppose I gave quite a detailed explanation, but I assume that I may get a comment of this kind:
I don't understand, why should you complain about the lack of understanding, instead of just creating a function and a button to "turn on/off". If you want, you may use it - if not, don't use it. Yes, this requires some work. And yes, this is your job.

Figure 9. Reaction of the unicorn to making a setting that disables all the filters of the warnings.
The suggestion is to make a button that would show all the warnings without any limits with disabled exceptions.
There is already such a button in the analyzer! It is there! It's called "Low" and shows warnings with a minimal level of confidence.
Apparently, a lot of people just incorrectly understand the term "exception". A great number of completely necessary conditions for correct operation of a diagnostic are formulated as exceptions.
I'll explain this using the V519 diagnostic as an example. It warns that the same object is assigned values twice in a row. Example:
x = 1;
x = 2;But the diagnostic cannot work in this way. So, we have to make certain clarifications, such as:
Exception N1. An object is used in the second statement as a part of a right operand of the = operation.
If this exception is removed, the analyzer will start complaining at completely normal code:
x = A();
x = x + B();Does anybody want to spend time and effort to viewing this kind of code? No.
So, it would be hard to convince us of the opposite.
I have no intention of proving something, or justifying my actions. My aim is to give a different perspective. I try to explain that an attempt to get as many warnings from the analyzer as possible, is counterproductive. This won't help make the project more reliable, but will take time that could be spent on looking for alternative methods of improving code quality.
A static code analyzer is not able to detect all errors; there is no tool that is capable of that task. There is no silver bullet. The quality and certainty of software can be achieved by use of a reasonable combination of varying tools, rather than attempting to get all possible and impossible functions from a single tool.
Let me give you an analogy. Safety during construction is usually provided through various methods: safety training, wearing of helmets, a ban on working while drunk, and so on. It would be inefficient to choose just one component, and hope that it will solve all problems. You can make a wonderful armoured helmet, or even a helmet with a built-in Geiger counter, and water supply for the day; but that won't save you from a fall when working at height. You need another device here - a safety rope. You may start thinking about a parachute built into a helmet. It's certainly an interesting engineering task, but such an approach is impractical. Most likely the weight and the size of the helmet will exceed all reasonable limits. The helmet will slow down work, and be uncomfortable to wear. There is a chance that builders will secretly take off the helmet, and work without it.
If a user has managed to work on all the analyzer warnings, there is no sense in trying to see as many low level warnings as possible. It would be more useful to work on unit tests to cover the code for at least 80%. I don't even suggest having 100% unit-test coverage, because the time required for its creation and support will outweigh the benefits. Further on, you may add one of the dynamic analyzers to the process of code testing. Some types of defects, which dynamic analyzers are able to find, cannot be detected by static analyzers. And vice versa. This is why dynamic and static analysis complement each other so perfectly. You can also develop UI tests.
This integrated approach will have a much greater impact on the quality and certainty of your software. Using multiple technologies, you can achieve better quality than having 100% test coverage of the code. 100% test coverage will require much more time.
Actually, I think that everyone who writes that he wants more unfiltered messages from the static analyzers, never actually used these analyzers properly. Or they have tried the analyzer on some small projects where you have a low density of errors. In any real project, there is the problem of how to deal with false positives. This is a large and complicated task that requires the work of analyzer developers, and their users. Do you want even more warnings?!
We regularly receive e-mails from our customers, where they ask to deal with a false positive. We have never really heard "give us more messages".
What we found out from this article:
Thanks to everyone who took the time to read this article. I didn't expect it to be so lengthy. This goes to show that this topic is more complex than it seems at first glance.

Unicorn will continue to safeguard the quality of your code. I wish you all the best, and suggest having a look at the presentation "PVS-Studio 2017" (YouTube).
0
0
0
0