
Our website uses cookies to enhance your browsing experience.

Here we'll discuss how SAST solutions find security flaws. I'll tell you about different and complementary approaches to detecting potential vulnerabilities, explain why each of them is necessary, and how to turn theory into practice.

SAST (Static Application Security Testing) is used to find security defects without executing an application. While the "traditional" static analysis is the way to detect errors, SAST focuses on detecting potential vulnerabilities.
What does SAST look like for us? We take sources, give them to the analyzer and get a report with a list of possible security defects.

So, the main purpose of this article is to answer the question of how exactly SAST tools look for potential vulnerabilities.
SAST solutions do not analyze the source code in a simple text representation: it's inconvenient, inefficient, and often insufficient. Therefore, analyzers work with intermediate code representations and several types of information. If combined, they provide the most complete representation of an application.
The analyzers work with an intermediate code representation. The most common are syntax trees (abstract syntax tree or parse tree).
Let's take a look at the error pattern:
operand#1 <operator> operand#1The point is that the same operand is used to the left and right of the operator. The code of this kind may contain an error, when a comparison operation is used, for example.
a == aHowever, the above case is a special one, and there are many variations:
In this case it's just unhandy to analyze the code as a text. This is where syntax trees can help.
Let's take a look at the expression: a == (a). Its syntax tree may look like this:
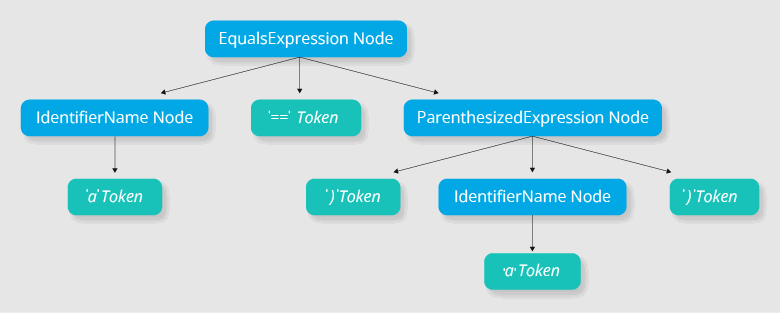
Such trees are easier to work with: there is information about the structure, and it is easy to extract operands and operators from expressions. Do you need to omit the brackets? No problem. Simply go down the tree.
In this way trees are used as a convenient and structured representation of the code. However, syntax trees alone are not enough.
Here's an example:
if (lhsVar == rhsVar)
{ .... }If lhsVar and rhsVar are the variables of the double type, the code may have some problems. For example, if both lhsVar and rhsVar are precisely equal to 0.5, this comparison is true. However, if one value is 0.5 and the other is 0.4999999999999, then the check results in false. Then the question arises: what kind of behavior does the developer expect? If he expects that the difference lies within the margin of error, the comparison should be rewritten.
Suppose we'd like to catch such cases. But here's the problem: the same comparison will be absolutely correct if the types of lhsVar and rhsVar are integer.
Let's imagine: the analyzer encounters the following expression while checking code:
if (lhsVar == rhsVar)
{ .... }The question is: should we issue a warning in this case or not? You can look at the tree and see that the operands are identifiers, and the infix operation is a comparison. However, we cannot decide whether this case is dangerous or not, because we do not know the types of the lhsVar and rhsVar variables.
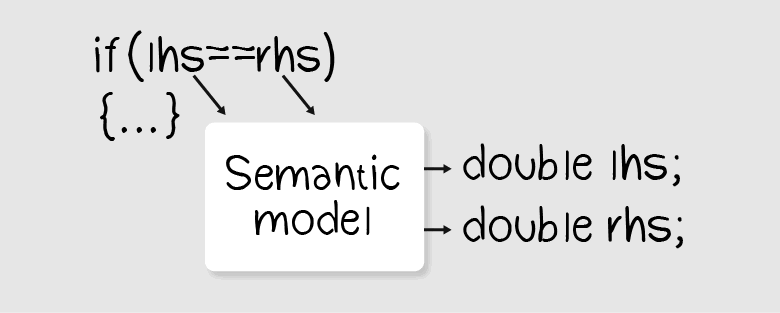
Semantic information comes to the rescue in this case. Using the semantics, you can get the tree node's data:
In the example above, we need information about the types of the lhsVar and rhsVar variables. All you have to do is get this information using a semantic model. If the variable type is real — then issue a warning.
Syntax and semantics are sometimes not enough. Look at the example:
IEnumerable<int> seq = null;
var list = Enumerable.ToList(seq);
....The ToList method is declared in an external library, the analyzer does not have access to the source code. There is the seq variable with a null value, which is passed to the ToList method. Is this a safe operation or not?
Let's use syntax information. You can figure out where is the literal, where is the identifier, and where is the method call. But is calling the method safe? That's unclear.
Let's try semantics. You can understand that seq is a local variable, and even find its value. What can we learn about Enumerable.ToList? For example, the type of the return value and the type of the parameter. Is it safe to pass null to it? That's unclear.
Annotations are a possible solution. Annotations are a way to guide the analyzer on what the method does, what constraints it imposes on input and return values, etc.
An annotation for the ToList method in the analyzer's code may be the following:
Annotation("System.Collections.Generic",
nameof(Enumerable),
nameof(Enumerable.ToList),
AddReturn(ReturnFlags.NotNull),
AddArg(ArgFlags.NotNull));The main information that this annotation contains:
Let's go back to the initial example:
IEnumerable<int> seq = null;
var list = Enumerable.ToList(seq);
....With the help of the annotation mechanism, the analyzer recognizes the limitations of the ToList method. If the analyzer tracks the value of the seq variable, it will be able to issue a warning on an exception of the NullReferenceException type.
We now have an overview of an information used for the analysis. So, let's discuss types of the analysis.
Sometimes these "regular" errors are actually security flaws. Look at this example of a vulnerability.
iOS: CVE-2014-1266
Vulnerability Information:
Code:
....
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
....At first sight, it may seem that everything is ok. In fact, the second goto is unconditional. That's why the check with the SSLHashSHA1.final method call has never been performed.
The code should be formatted this way:
....
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
....How can a static analyzer catch this kind of defect?
The first way is to see that goto is unconditional, and is followed by expressions without any labels.
Let's take the simplified code with the same meaning:
{
if (condition)
goto fail;
goto fail;
....
}Its syntax tree may look like this:
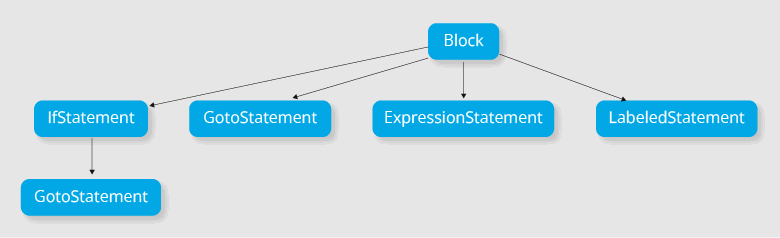
Block is a set of statements. It's also clear from the syntax tree that:
Of course, this is a special case of heuristic. In practice, this kind of problem is better solved by more general mechanisms of calculating the reachability of the code.
Another way to catch the defect is to check if the formatting of the code corresponds to the execution logic.
A simplified algorithm would be as follows:

The algorithms are simplified for clarity and do not include corner cases. Diagnostic rules are usually more complicated and contain more exceptions for cases where no warning is necessary.
Here's an example:
if (ptr || ptr->foo())
{ .... }Developers messed up the logic of code by mixing up the operators '&&' and '||'. So, if ptr is a null pointer, it's dereferenced.
In this case the context is local, and it's possible to find an error by pattern-based analysis. The problems arise when the context gets spread. For example:
if (ptr)
{ .... }
// 50 lines of code
....
auto test = ptr->foo();Here the ptr pointer is checked for NULL and then dereferenced without checking, it looks suspicious.
Note. I use NULL in the text to denote the value of the null pointer, not as a C macro.
It would be difficult to catch a similar case in patterns. It is necessary to issue a warning for the code example above, but not for the code fragment below, since ptr is not a null pointer at the time of dereferencing:
if (ptr)
{ .... }
// 50 lines of code
....
if (ptr)
{
auto test = ptr->foo();
....
}As a result, we concluded that it would be a good idea to trace variable values. This would be useful for the above examples, since tracking estimates the value that the ptr pointer has at a particular location in the application. If a pointer is dereferenced to NULL — then a warning is issued, otherwise — it is not.
Data flow analysis helps to trace the values that expressions have across various locations in the source code. The analyzer issues warnings based on this data.
Data flow analysis is useful for different types of data. Take a look at these examples:
Let's discuss the pointers example again. A null pointer dereference is a security defect — CWE-476: NULL Pointer Dereference.
if (ptr)
{ .... }
// 50 lines of code
....
auto test = ptr->foo();First of all, the analyzer finds that ptr is checked for NULL. The check imposes restrictions on the value of ptr: the ptr is not a null pointer in then branch of the if statement. Since the analyzer knows this, it will not issue a warning to the following code:
if (ptr)
{
ptr->foo();
}But what is the value of ptr outside of the if statement?
if (ptr)
{ .... }
// ptr - ???
// 50 lines of code
....
auto test = ptr->foo();Generally, it's unknown. However, the analyzer may incorporate the fact that ptr has already been checked for NULL. This way the developer declares a contract that ptr can take the NULL value. This fact may be kept.
As a result, when the analyzer meets the auto test = ptr->foo() expression, it may check the condition:
Compliance with both conditions looks suspicious, and in this case a warning should be issued.
Now let's see how data flow analysis handles integer types. Look at the code containing the CWE-570: Expression is Always False security defect as an example.
void DataFlowTest(int x)
{
if (x > 10)
{
var y = x - 10;
if (y < 0)
....
if (y <= 1)
....
}
}Let's start from the beginning. Take a look at the method's declaration:
void DataFlowTest(int x)
{ .... }In the local context (analysis within a single method), the analyzer has no information about what value x can have. However, the type of the parameter is defined — int. It helps to limit the range of possible values: [-2 147 483 648; 2 147 483 647] (assuming we count int of size 4 bytes).
Then there is a condition in the code:
if (x > 10)
{ .... }If the analyzer checks then branch of the if statement, it imposes some additional restrictions to the range. The value of x is within the range of [11; 2 147 483 647] in then branch.
Then the y variable is declared and initialized:
var y = x - 10;Since the analyzer knows limits of the values of x, it can calculate the possible value of y. To do this, 10 is deducted from the boundary values. So, the value of y lies within the range of [1; 2 147 483 637].
Next — the if statement:
if (y < 0)
....The analyzer knows that at this execution point the value of the y variable is within the range of [1; 2 147 483 637]. It turns out that the value of y is always larger than zero, and the y < 0 expression is always false.
Let's look at a security flaw that can be found with data flow analysis.
ytnef: CVE-2017-6298
Vulnerability information:
Let's look at the code fragment:
....
TNEF->subject.data = calloc(size, sizeof(BYTE));
TNEF->subject.size = vl->size;
memcpy(TNEF->subject.data, vl->data, vl->size);
....We'll explore from where the vulnerability comes:
Both annotations and data flow analysis will be helpful in identifying this problem.
Annotations:
Data flow analysis tracks:

The picture above shows how the analyzer tracks expression values to find the dereferencing of a potentially null pointer.
Sometimes the analyzer may not know the exact values of the variables, or the possible values are too general to draw any conclusions. However, the analyzer may know that the data comes from an external source and may be compromised. So, the analyzer is ready to look for new security defects.
Let's look at the example of code that is vulnerable to SQL injections:
using (SqlConnection connection = new SqlConnection(_connectionString))
{
String userName = Request.Form["userName"];
using (var command = new SqlCommand()
{
Connection = connection,
CommandText = "SELECT * FROM Users WHERE UserName = '" + userName + "'",
CommandType = System.Data.CommandType.Text
})
{
using (var reader = command.ExecuteReader())
{ /* Data processing */ }
}
}In this case we're interested in the following:
Suppose the string _SergVasiliev_ comes as userName from a user. Then the generated query would look like this:
SELECT * FROM Users WHERE UserName = '_SergVasiliev_'The initial logic is the same — the data are extracted from the database for the user named _SergVasiliev_.
Now let's say that a user sends the following string: ' OR '1'='1. After substituting it into the query template, the query will look like this:
SELECT * FROM Users WHERE UserName = '' OR '1'='1'An attacker managed to change the query's logic. Since a part of the expression is always true, the query returns data about all users.
By the way, this is where the meme about cars with strange license plates came from.

Let's look again at the example of vulnerable code:
using (SqlConnection connection = new SqlConnection(_connectionString))
{
String userName = Request.Form["userName"];
using (var command = new SqlCommand()
{
Connection = connection,
CommandText = "SELECT * FROM Users WHERE UserName = '" + userName + "'",
CommandType = System.Data.CommandType.Text
})
{
using (var reader = command.ExecuteReader())
{ /* Data processing */ }
}
}The analyzer does not know the exact value that will be written to userName. The value can be either the safe _SergVasiliev_ or the dangerous ' OR '1'='1. The code does not impose restrictions on the string either.
So, it turns out that data flow analysis does not help much to look for SQL injection vulnerabilities. Then taint analysis comes to the rescue.
Taint analysis deals with data transmission routes. The analyzer keeps track of where the data comes from, how it is distributed, and where it goes.
Taint analysis is used to detect various types of injections and those security flaws that arise due to insufficient user input checking.
In the SQL injection example, taint analysis can build a data transmission route that helps find the security flaw:
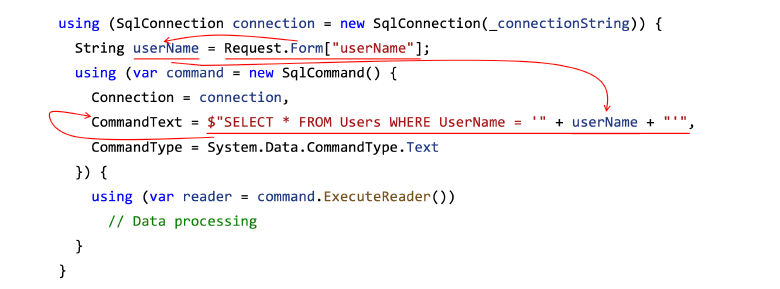
Here's an example of a real vulnerability that can be detected by taint analysis.
BlogEngine.NET: CVE-2018-14485
Vulnerability information:
Let's just briefly review the vulnerability from BlogEngine.NET, a more detailed review would take at least an article. By the way, there is an article on this topic and you can read it here.
BlogEngine.NET is a blogging platform written in C#. It turned out, that some handlers were vulnerable to XXE (XML eXternal Entity) attack. An attacker can steal data from the machine where the blog is deployed. For this purpose, one would need to send a specially configured XML file to a certain URL.
XXE vulnerability consists of two components:
Only a dangerous parser can be tracked and a warning can be issued regardless of what data it processes. This approach has some pros and cons:
Suppose we finally decided to track user data. In this case, taint analysis also comes in handy.
But let me take you back to XXE. CVE-2018-14485 from BlogEngine.NET can be caught this way:
The analyzer starts tracking data transmission with an HTTP request and sees how data is passed between variables and methods. Also, it tracks the movement of a dangerous parser instance (request of the XmlDocument type) through the program.
The data comes together in the request.LoadXml(xml) call — a parser with a dangerous configuration processes user data.
I have compiled a theory of XXE and a detailed description of this vulnerability in the following article: "Vulnerabilities due to XML files processing: XXE in C# applications in theory and in practice".
We've discussed some options for finding vulnerabilities in the application's source code, as well as their strong and weak points. The main purpose of this article is to explain how SAST tools look for vulnerabilities. However, in conclusion I wish to remind why they look for vulnerabilities.
1. The year 2022 (even before it is over) has already surpassed 2021 in the number of safety defects discovered. That's why safety has to be a concern.
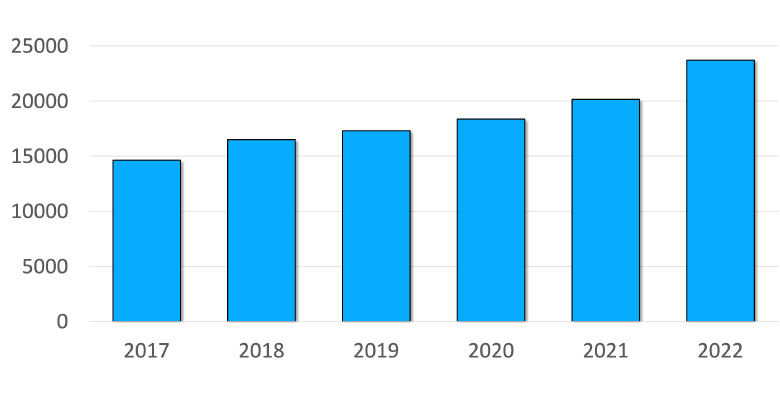
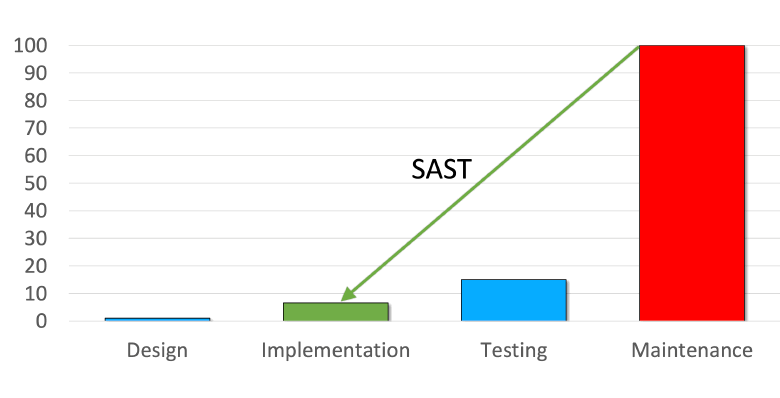
2. The sooner a vulnerability is found, the easier and cheaper it is to fix. SAST tools reduce financial and reputational risks because they help to find and fix bugs as early as possible. I covered this topic in more detail here: "SAST in Secure SDLC: 3 reasons to integrate it in a DevSecOps pipeline".
0
0
0
0