
Our website uses cookies to enhance your browsing experience.

Years pass, and projects overgrow dark spots that nobody wants to venture into—they're too tricky and prone to failure. Today, we're diving into refactoring legacy code with OOP. And we're gonna do it with a style—a modern one, of course.
That's not the first time I write about "OOP in real-life cases" — it's literally the title of one of my past articles (I partially touched on the topic here as well). There, I focused on how to use behavioral patterns. Here, I talk more about the creational patterns, or the builder pattern if to be precise. So, this article is a sequel in some way.
This time, I'm going to move on from static analysis and bring an example that's closer to web dev—with Blazor, though.
Although PVS-Studio is primarily known for static analysis, it also includes some internal web-development activities. Particularly, C# development with the Blazor framework. If you're interested in Blazor, I suggest checking out our articles on the topic:
I've been trying to figure out what's going on there, but I give up.
It's my comment on the task that landed on my plate once. After taking a peek, I grabbed my head and handed off the task to a colleague who knew the module better than I did. In the annotation to the article, I mentioned the dark project spots—this was just one of them.
A classic scenario: developers started the project ages ago, with most of the original team long gone. So, an outsider might have a meltdown, whichever approach they use.
That project was the statistics module. The issue seemed trivial—in one of the tables, a dev had mixed up the two column values, Activated and Answered.
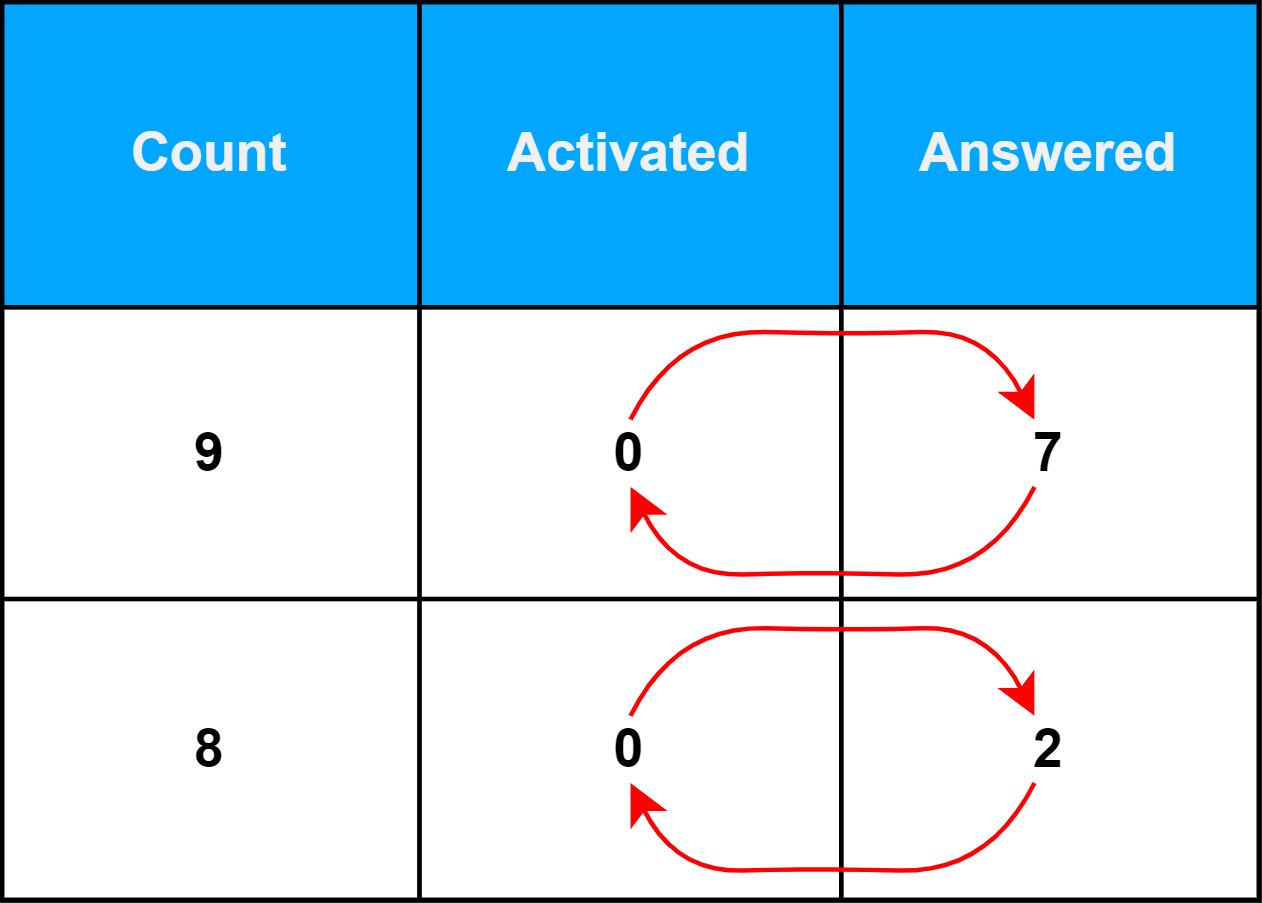
Trivial, uh? Well, let's check it.
What's under the hood? I'm not going to show you the full code because it's way too huge and not very pretty. Code fragments are all we need.
This led me to a 500-line long static method. Look at the method signature:
private static (
Dictionary<string, List<int>> Requests,
// .... skipping another 12 dictionaries
Dictionary<DateTime,
Dictionary<string, (int Count, int Activated, int Answered,
Dictionary<string,
(int Count, int Activated, int Answered)> Medium)>> UTMs)
GetMailDataForStatForPeriod<TMail>(
List<TMail> mails,
DateTime RightDate,
int monthsIterations) where TMail : Mail
{The method returns a tuple that contains fourteen different entities. The leaky encapsulation is already visible to the naked eye, but we're just warming up.
Next, we can see that the returned objects are declared:
var requests = new Dictionary<string, List<int>>
{
{ requestName, new() }
};
var requestsReadAnswered = new Dictionary<string, List<int>>
{
{ requestName, new() },
{ "Read", new() }
};
// and more, and more
var UTMs = new Dictionary<DateTime,
Dictionary<string, (int Count, int Activated, int Answered,
Dictionary<string, (int Count, int Activated, int Answered)> Medium)>>();After that, the counters for each month are declared:
for (int i = 0; i < monthsIterations; i++)
{
int countReqeusts = 0;
int countRead = 0;
int countActivated = 0;
int countAnswered = 0;
// and so on
UTMs.Add(RightDate, new());
// ....
}Finally, the entire data sample is traversed. When an entity matches one of the conditions, the proper counters are incremented:
if (trial != null && trial.Activated)
{
countActivated++;
countRead++;
}
else if (chainGroup.Any(mail => mail.Read || mail.Ticket > 0))
{
countRead++;
}
// and so on and so forth
if (trial != null)
{
// ....
if (lastUTM != default)
source = lastUTM.Source;
if (!UTMs[RightDate].ContainsKey(source))
UTMs[RightDate].Add(source, (0, 0, 0, new()));
var currSource = UTMs[RightDate][source];
(int Count, int Answered, int Activated) currMedium = (0, 0, 0);
if (ans != null)
{
if (lastUTM != default)
currMedium.Answered++;
currSource.Answered++;
}
// ....
}Once delving into the code, I felt about the same as the meme. Not as terminator, though.

At some point, I just gave up. The code was so cluttered and monotonous — all that class for two thousand lines—that I struggled reading it. And I didn't eager to debug this single loop. So, the task ended up with a developer who's more familiar with the code. The dev fixed it quite quickly—the problem was quite trivial. By the way, we can try spotting that error in the above code.
The returned tuple has a part for UTM:
Dictionary<DateTime,
Dictionary<string, (int Count, int Activated, int Answered,
Dictionary<string,
(int Count, int Activated, int Answered)> Medium)>> UTMs)We have a return object for this part:
var UTMs = new Dictionary<DateTime,
Dictionary<string, (int Count, int Activated, int Answered,
Dictionary<string, (int Count, int Activated, int Answered)> Medium)>>();However, in the last code snippet, the fields are disordered in the tuple:
(int Count, int Answered, int Activated) currMedium = (0, 0, 0);You may not immediately notice it, but Answered and Activated are mixed up.
The variable is then written to another variable, which is written into UTMs:
if (lastUTM != default)
currSource.Medium[lastUTM.Medium] = currMedium;
UTMs[RightDate][source] = currSource;No compilation error, but errors in the final data.
Indeed, we could easily blame tuples for everything—after all, we're writing in an OO language! Despite all my love of language innovations, their implementation creeped me out a little bit. So, when a dev had fixed the bug, we flagged the code as a reminder to thoroughly refactor it later.
You might expect a sophisticated discussion about technical specs here, but instead, I'll just admit that we overlooked checking for such issues :)
The analyzer has suitable diagnostic rules. V3038 for method arguments and V3056 for object usage may come to mind, but there are countless ways to make a typo. So, the case inspired us to come up with a new diagnostic rule.
So, we've had some time to refactor. How are we going to spend it?
First, we list particular issues to be fixed:
The first point is pretty straightforward. Even a simple class with public class fields—let alone the properties—is better than a tuple. A class helps us avoid the issue we've just discussed above, and that's basically what we did. There's not much to describe.
We can reduce the second and third points to the following: split up the statistics god method using OOP. Since we're in the Refactoring section, that's what we're going to do.
If you want to solve a problem, start with the simplest. What's the first thing that comes to mind?
It looks solid, but is it a smart move, though? It might be... until the user encounters an infinite loading spinning wheel on the website.

Obviously, in such a case the load time will increase by about ~k times, where k is the number of such methods with an internal loop. But if we had a large dataset with myriads of entities being transformed during analysis, we'd strongly feel this slowdown. Yes, O(n*k) isn't as severe as O(n^k), but still it's not so good.
And here's the solution. So, what we have:
Grab the GoF book about design patterns and look for what we can use. Bingo! We have a builder for complex initialization and an iterator for encapsulating traversal. I covered the iterator in the previous article, so we'll skip it in the theoretical section. We'll focus on the builder for those who haven't encountered it yet. And for those who already know them, it'll be a chance to refresh their memory.
Here's a classic UML builder diagram:
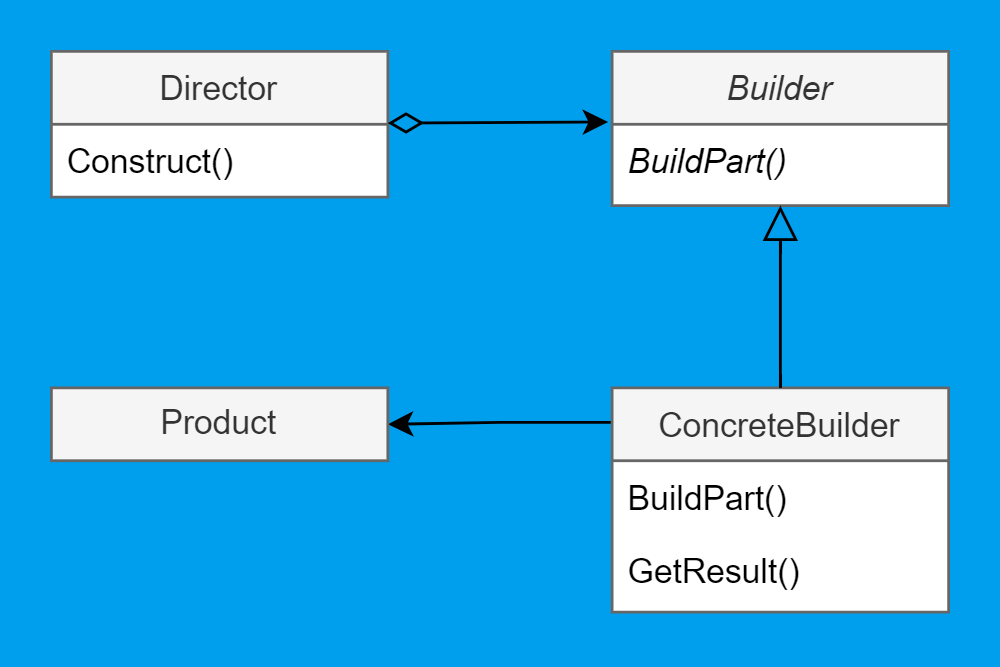
Meet our star cast:
Let's try to quickly decipher the diagram with an example. This is another real case from our project but a little reduced.
The task is to create a builder for charts in images. There can be two chart types—a bar and a pie chart, that we can customize extensively, tweaking legends, entries, and much more. To keep things simple, let's define just the image and series size for the general chart and define specific settings for each individual chart. The series is a set of numbers that we use to create a chart, as you can see in the very first code snippet.
Let's define the entities we'll work with:
The UML diagram will look like this:
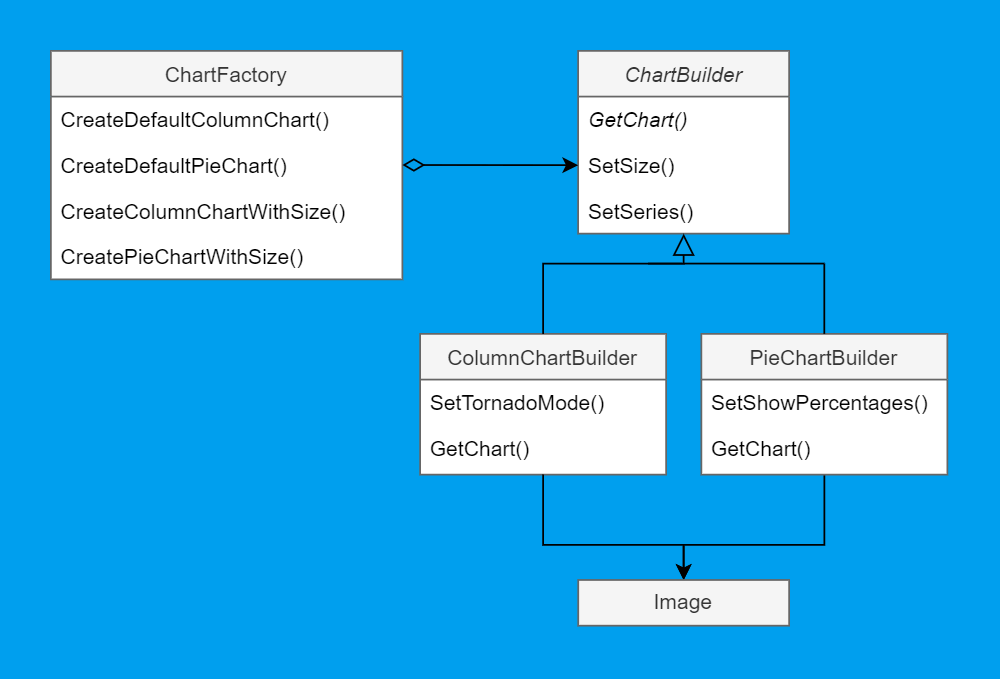
In this case, we can still notice one difference from the above diagram: GetChart is defined in the parent interface, although there it was left to the specific implementations. Those who create patterns argue that builders can make fundamentally different objects, and it's unnecessary to output a general interface for them. However, since we already have such an interface, deviating slightly from it won't do great harm.
Well, now it's just a matter of writing the code. ChartBuilder will look like this:
public abstract class ChartBuilder
{
private int width = Consts.DefaultChartWidth;
private int Height = Consts.DefaultChartHeight;
private Series series;
public void SetSeries(Series series)
{
this.series = new(series);
}
public void SetSize(int width, int height)
{
this.width = width;
this.height = height;
}
public abstract Image GetChart();
}Its specific implementations are as follows:
public class ColumnChartBuilder : ChartBuilder
{
private bool tornadoBar = false;
public void SetTornadoMode()
{
tornadoBar = true;
}
Public override Image GetImage()
=> ChartUtils.CreateColumnChart(series,
width,
height,
tornadoBar);
}
public class PieChartBuilder : ChartBuilder
{
private bool showPercentages = false;
public void SetShowPercentages()
{
showPercentages = true;
}
public override Image GetImage()
=> ChartUtils.CreatePieChart(series,
width,
height,
showPercentages);
}A generation is handled in a different method—well, it makes things easier for us. If you wonder why there is a builder, just keep in mind that the number of parameters can be up to dozens according to the task requirements :)
Well, the last thing we have left to do is the ChartFactory:
public class ChartFactory()
{
private ColumnChartBuilder CreateBaseColumnBuilder(
Series series,
bool tornado = false)
{
var builder = new ColumnChartBuilder();
builder.SetSeries(series);
if (tornado)
builder.SetTornadoMode();
return builder;
}
public Image CreateDefaultColumnChart(Series series,
bool tornado = false)
=> CreateBaseColumnBuilder(series, tornado).GetChart();
public Image CreateColumnChartWithSize(Series series,
int width,
int height,
bool tornado = false)
{
var builder = CreateBaseColumnBuilder(series, tornado);
builder.SetSize(width, height);
return builder.GetChart();
}
private PieChartBuilder CreateBasePieBuilder(
Series series,
bool showPercentages = false)
{
var builder = new PieChartBuilder();
builder.SetSeries(series);
if (showPercentages)
builder.SetShowPercentages();
return builder;
}
public Image CreateDefaultPieChart(Series series,
bool showPercentages = false)
=> CreateBasePieBuilder(series, showPercentages).GetChart();
public Image CreatePieChartWithSize(Series series,
int width,
int height,
bool showPercentages = false)
{
var builder = CreateBasePieBuilder(series, showPercentages);
builder.SetSize(width, height);
return builder.GetChart();
}
}That's all folks! Now the client code needs to call the factory method:
var pie = chartFactory.CreateDefaultPieChart(series);We'll get a complete chart image. Although you may ask a fair question, why do we even need the director—in our case, a simple factory—if the client can directly build the object? There are two reasons for this:
The one-minute theory is over. Let's get back to the topic.
You might be wondering why I used a chart example to show a builder implementation from the book if we planned to refactor the stat gathering. The answer is simple: I wanted to showcase a classic implementation, but now we get away from it in during refactoring. Why not? We can add a touch of gloss to it:)
Although the initial tasks might seem different, we follow the same approach as in the theoretical part.
As we've already outlined, our task is to decompose a static class into a set of instance classes. This will help us streamline the initialization, enhance code readability, and follow all the SOLID principles.
Again, meet our star cast, not much has changed in the sequel:
And that's it! The cast may seem incomplete, but that's not an issue. Firstly, it lacks a director, but it doesn't need one for the following reasons:
Secondly, StatisticsBuilder adds series counting to itself and handles the iterator. So, the builder essentially builds itself. This may seem strange, but this pattern is quite common. Everyone knows about StringBuilder, right? :)
To cut to the chase, we'll map out the entities. This time, we'll use the scope notation:
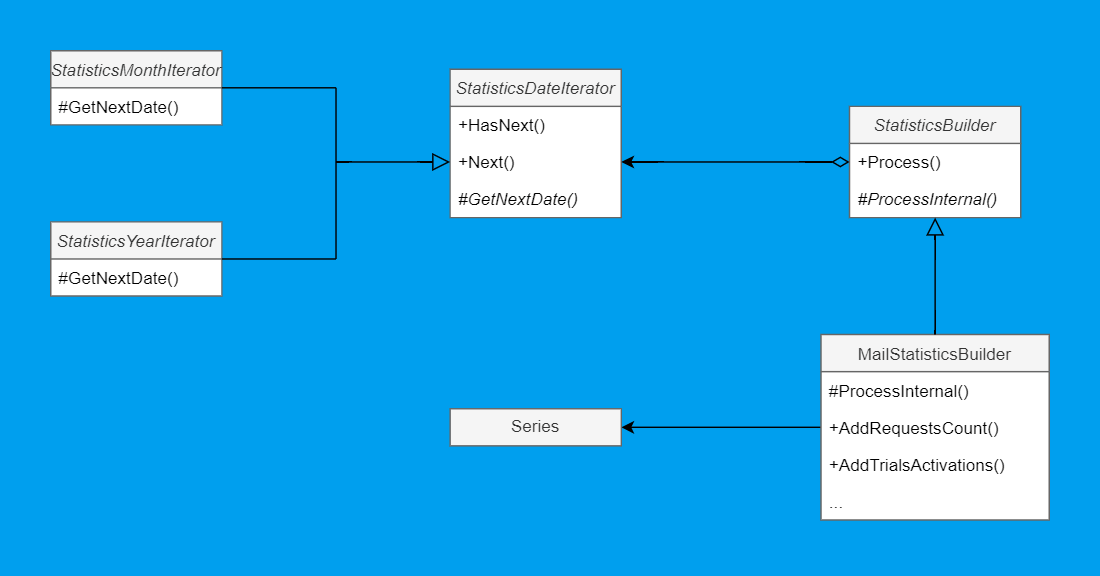
Having the basic understanding of it, this would be straightforward to implement. First, we introduce iterators:
public abstract class StatisticsDateIterator
{
public record struct DateEntry(int Year, int Month);
public StatisticsDateIterator(DateTime firstIteration,
DateTime lastIteration,
int iterationCount)
{
LastIteration = FromDate(lastIteration);
FirstIteration = FromDate(firstIteration);
IterationsCount = iterationCount;
CurrentDate = FirstIteration;
}
public int IterationsCount { get; }
public int Iteration { get; private set; } = 0;
public DateEntry CurrentDate { get; protected set; }
protected DateEntry FirstIteration { get; }
protected DateEntry LastIteration { get; }
public bool HasNext() => (Iteration <= IterationsCount);
public DateEntry Next()
{
CurrentDate = GetNextDate(CurrentDate);
Iteration++;
return CurrentDate;
}
public abstract DateEntry GetNextDate(DateEntry date);
public abstract DateEntry FromDate(DateTime date);
}
public class StatisticsYearIterator : StatisticsDateIterator
{
// ....
public override DateEntry GetNextDate(DateEntry date)
=> date with { Year = date.Year + 1 };
public override DateEntry FromDate(DateTime date)
=> new(date.Year, 0);
}
public class StatisticsMonthIterator : StatisticsDateIterator
{
// ....
public override DateEntry GetNextDate(DateEntry date)
{
var month = date.Month + 1;
var year = date.Year;
if (month > 12)
{
month = 1;
year++;
}
return new(year, month);
}
public override DateEntry FromDate(DateTime date)
=> new(date.Year, date.Month);
}The iterators for month and year are crystal clear, their parent is a bit murkier. Let me anticipate the questions:
Got it cleared up here. Move on to the abstract StatisticsBuilder:
public abstract class StatisticsIterator
{
protected StatisticsDateIterator Iterator;
protected StatisticsIterator(StatisticsIteratorType iteratorType,
int rightYear,
int rightMonth)
{
if (iteratorType == StatisticsIteratorType.Month)
Iterator = new StatisticsMonthIterator(rightYear, rightMonth);
else if (iteratorType == StatisticsIteratorType.Year)
Iterator = new StatisticsYearIterator(rightYear, rightMonth);
else
throw new NotImplementedException();
}
public void Process()
{
for (var cur = Iterator.CurrentDate;
Iterator.HasNext();
cur = Iterator.Next())
{
ProcessInternal(cur);
}
}
protected abstract void ProcessInternal(DateEntry date);
protected Series GetSeriesWithZeroData(string name)
=> new(name, Enumerable.Repeat(0, Iterator.IterationsCount));
}It looks simple: just create an iterator relevant to a type and define an interface for data processing. We use the public method to run the interface, and the private one for the specific implementation. Let's save GetSeriesWithZeroData for later, and we can ignore the name parameter since it's only for display purposes.
It all started with email processing, and we can finally get back to it. Here's what the implementation of the abstract class looks like in MailStatisticsBuilder:
public class MailStatisticsBuilder : StatisticsBuilder
{
private readonly Dictionary<DateEntry, List<Mail>> groupedMails;
private readonly List<Action<List<Mail>, int>> _actions = new();
public MailStatisticsBuilder(List<Mail> mails,
StatisticsIteratorType iteratorType,
int rightYear,
int rightMonth = 1)
: base(iteratorType, rightYear, rightMonth)
{
groupedMails = mails.Select(x => (Iterator.FromDate(x.CreationTime), x))
.GroupBy(x => x.Item1, x => x.Item2)
.ToDictionary(x => x.Key, x => x.ToList());
}
protected override void ProcessInternal(DateEntry date)
{
if (groupedMails.TryGetValue(date, out var mails))
{
foreach (var action in _actions)
{
action.Invoke(mails, Iterator.Iteration);
}
}
}
// ....
}You might feel a bit lost here, with all these vague _actions. Don't worry, we'll get to that in a moment—the answers are hiding just behind the ellipsis.
But before we dive in, let's look at the data traversal. In the builder, we group emails by date. That way, when we move to the next iteration in ProcessInternal, we'll have instant access to the emails in that specific period. You may also wonder why we don't shove all the logic involving _actions into the parent class. However, the implementation is so because the dataset can be very heterogeneous, so it won't be a big gain.
Now let's move on to _actions. Up until now, I've been tactfully dodging the return value, which was one of the stumbling blocks in the original implementation. Moreover, the code fragments above didn't even hint at it—the Process builder returns void. So, how do we maintain the flexibility of optional data counting while ensuring the safety of the compile-time checks? In other words, how do we avoid using things like dictionaries? We can take advantage of two C# features: anonymous functions and out parameters. Can't we use them together, they say? Whatever :)
After you look at the code, everything should become clear:
public MailStatisticsBuilder AddRequestsCount(string type,
out Series count,
out Series read,
out Series answered)
{
var _count = GetSeriesWithZeroData(type);
var _read = GetSeriesWithZeroData("Read");
var _answered = GetSeriesWithZeroData("Answered");
_actions.Add((List<Mail> mails, int iteration) =>
{
foreach (var mail in mails)
{
_count.Data[iteration]++;
if (mail.Read)
_read.Data[iteration]++;
if (mail.HasAnswer)
_answered.Data[iteration]++;
}
});
count = count;
read = _read;
answered = _answered;
return this;
}What we see:
Is there any logic in combining these series into a single method rather than using three separate ones? Not really. On the one hand, that's how flexibility degrades. On the other hand, if you complicate the checking process and make it multistep, you'll end up duplicating more checks. It's best to handle it on a case-by-case basis.
Btw, the complex checks are one of the reasons why you can't declare counting parameters using reflection.
That's all! Just add the remaining parameters to count them, and then we can use the builder. We've already mentioned trial activations, let's add them in a separate method as well:
public MailStatisticsBuilder AddTrialsActivations(out Series activations)
{
var _activations = GetSeriesWithZeroData("Activated");
_actions.Add((List<Mail> mails, int iteration) =>
{
foreach (Mail mail in mails)
{
if (mail is Trial trial && trial.Activated)
_activations.Data[iteration]++;
}
});
activations = _activations;
return this;
}This is how the workflow of such a builder would look:
var builder = new MailStatisticsBuilder(
allTrials,
StatisticsIteratorType.Month,
Year,
month);
builder.AddRequestsCount("Trials", out var count,
out var read,
out var answered)
.AddTrialsActivations(out var trialsActivations)
.Process();These series are ready and now we can integrate them into the chart.
This solution gives us both flexibility (we use only what we need), performance (efficient data processing), compile-time issue detection, and maximum modularity. Such a system is super flexible. We can scale a concrete builder (like in our project, where the builder call chains extend across many methods) and other builder types (for example, we collect both the request data we've gathered and information from our Task Tracker). This is the result of our refactoring.
It's the second time I've been trying how to tackle common tasks using an OOP approach, and I hope I've made it. This piece is a bit different from the previous one, where I didn't delve that as deeply in the tricks of the trade and specific language techniques. Anyway, I'd love to hear your thoughts in the comments.
Unfortunately, static analysis won't teach you the architectural insights on how to tackle the issue, but it'll detect possible errors in the code that's already been written. If you write in C, C#, C++, or Java, you may try PVS-Studio for free at this link.
To stay tuned for new articles on code quality, we invite you to subscribe:
0
0
0


0