
Our website uses cookies to enhance your browsing experience.

Nullable reference types appeared in C# 3 years ago. By this time, they found their audience. But even those who work with this "beast" may not know all its capabilities. Let's figure out how to work with these types more efficiently.

Nullable reference types are designed to help create a better and safer application architecture. At the code writing stage, it is necessary to understand whether this or that reference variable can be null or not, whether the method can return null, and so on.
It is safe to say that every developer has encountered NRE (NullReferenceException). And the fact that this exception can be generated at the development stage is a good scenario, because you can fix the problem immediately. It is much worse when the user finds the problem when working with the product. Nullable reference types help protect against NRE.
In this article I will talk about a number of non-obvious features related to nullable reference types. But it's worth starting with a brief description of these types.
In terms of program execution logic, a nullable reference type is no different from a reference type. The difference between them is only in the specific annotation that the first one has. The annotation allows the compiler to conclude whether a particular variable or expression can be null. To use nullable reference types, you need to make sure that the nullable context is enabled for the project or file (I will describe later how to do this).
To declare a nullable reference variable, add '?' at the end of the type name.
Example:
string? str = null;Now the variable str can be null, and the compiler will not issue a warning for this code. If you don't add '?' when declaring a variable and assigning it with null, a warning will be issued.
It is possible to suppress compiler warnings about possible writing null to a reference variable that is not marked as nullable.
Example:
object? GetPotentialNull(bool flag)
{
return flag ? null : new object();
}
void Foo()
{
object obj = GetPotentialNull(false);
}The obj variable will never be assigned with null, but the compiler does not always understand this. You can suppress the warning as follows:
object obj = GetPotentialNull(false)!;Using the '!' operator, we "tell" the compiler that the method will definitely not return null. Therefore, there will be no warnings for this code fragment.
The functionality available when working with nullable reference types is not limited to declaring variables of that type (using '?') and suppressing warnings with '!'. Below I'll look at the most interesting features when working with nullable reference types.
There are a number of mechanisms for more flexible work with nullable reference types. Let's look at some of them.
Attributes can be used to tell the compiler the null-state of various elements. Let's look at the most interesting ones. Check out the documentation to find the full list of attributes.
To make it easier, let's introduce the term — null-state. The null-state is information about whether a variable or expression can be null at a given time.
Let's look how the attribute work. Here is an example:
public string Name
{
get => _name;
set => _name = value ?? "defaultName";
}
private string _name;If you write the null value to the Name property, the compiler will issue a warning: Cannot convert null literal to non-nullable reference type. But you can see from the implementation of the property that it can be null. In this case, the "defaultName" string is assigned to the _name field.
If you add '?' to the property type, the compiler will assume that:
For correct implementation, it is worth adding the AllowNull attribute to the property:
[AllowNull]
public string NameAfter that, the compiler will assume that Name may be assigned with null, although the property's type is not marked as nullable. If you assign the value of this property to a variable that should never be null, then there will be no warnings.
Suppose we have a method that checks a variable for null. Depending on the result of this check, the method returns a value of the bool type. This method informs us about the null-state of the variable.
Here's a synthetic code example:
bool CheckNotNull(object? obj)
{
return obj != null;
}This method checks the obj parameter for null and returns a value of the bool type depending on the check result.
Let's use the result of this method in the condition:
public void Foo(object? obj1)
{
object obj2 = new object();
if (CheckNotNull(obj1))
obj2 = obj1;
}The compiler will issue a warning to code above: Converting null literal or possibly null value to non-nullable type. But such a scenario is impossible, since the condition guarantees that obj1 is not null in the then branch. The problem is that the compiler doesn't understand this, so we have to help it.
Let's change the signature of the CheckNotNull method by adding the NotNullWhen attribute:
bool CheckNotNull([NotNullWhen(true)]object? obj)This attribute takes a value of the bool type as the first argument. With NotNullWhen, we link the null-state of the argument with the return value of the method. In this case, we "tell" the compiler that if the method returns true, the argument has a value other than null.
There is a peculiarity associated with this attribute.
Here are some examples:
Using the out modifier
bool GetValidOrDefaultName([NotNullWhen(true)] out string? validOrDefaultName,
string name)
{
if (name == null)
{
validOrDefaultName = name;
return true;
}
else
{
validOrDefaultName = "defaultName";
return false;
}
}Here, the compiler will issue a warning: Parameter 'validOrDefaultName' must have a non-null value when exiting with 'true'. It is quite reasonable, since '==' is used in the condition instead of the '!=' operator. In this implementation, the method returns true when validOrDefaultName is null.
Using the ref modifier
bool SetDefaultIfNotValid([NotNullWhen(true)] ref string? name)
{
if (name == null)
return true;
name = "defaultName";
return false;
}We will also get a warning for this code fragment: Parameter 'name' must have a non-null value when exiting with 'true'. Similarly to the previous example, the warning is reasonable. '==' is used instead of the '!=' operator.
Without using a modifier
bool CheckingForNull([NotNullWhen(true)] string? name)
{
if (name == null)
return true;
Console.WriteLine("name is null");
return false;
}The situation here is similar to previous cases. If name equals null, the method returns true. Following the logic of previous examples, a warning should also be issued here: Parameter 'name' must have a non-null value when exiting with 'true'. However, there is no warning. It's hard to say what's caused this, but it looks strange.
This attribute allows you to establish a relationship between the argument and the return value of the method. If the argument is not null, the return value is also not null, and vice versa.
Example:
public string? GetString(object? obj)
{
return obj == null ? null : string.Empty;
}The GetString method returns null or an empty string, depending on the null-state of the argument.
Usage of this method:
public void Foo(object? obj)
{
string str = string.Empty;
if(obj != null)
str = GetString(obj);
}Compiler's warning for this code: Converting null literal or possibly null value to non-nullable type. In this case, the compiler is lying. Assignment is performed in the body of if, the condition of which guarantees that GetString will not return null. To help the compiler, let's add the NotNullIfNotNull attribute for the return value of the method:
[return: NotNullIfNotNull("obj")]
public string? GetString(object? obj)Note. Starting with C#11, you can get the parameter name using the nameof expression. In this case, it would be nameof(obj).
The NotNullIfNotNull attribute takes the value of the string type as the first argument — the name of the parameter, based on which the null-state of the return value is set. Now the compiler has information about the relationship between obj and the return value of the method: if obj is not null, the return value of the method will not be null, and vice versa.
Let's start with an example:
class Person
{
private string _name;
public Person()
{
SetDefaultName();
}
private void SetDefaultName()
{
_name = "Bob";
}
}The compiler will issue a warning to this code fragment: Non-nullable field '_name' must contain a non-null value when exiting constructor. Consider declaring the field as nullable. However, the SetDefaultName method is called in the constructor's body, which initializes the only field of the class. This means that the compiler's message is false. The MemberNotNull attribute allows you to solve the problem:
[MemberNotNull(nameof(_name))]
private void SetDefaultName()This attribute takes an argument of the string[] type with the params keyword. The strings need to match the names of the members that are initialized in the method.
Thus, we are indicating that the value of the _name field will not be null after this method is called. Now the compiler can understand that the field is initialized in the constructor.
Let's look at the example:
class Person
{
static readonly Regex _nameReg = new Regex(@"^I'm \w*");
private string _name;
public Person(string name)
{
if (!TryInitialize(name))
_name = "invalid name";
}
private bool TryInitialize(string name)
{
if (_nameReg.IsMatch(name))
{
_name = name;
return true;
}
else
return false;
}
}TryInitialize will initialize _name if the argument's value matches some pattern. The method returns true when the field has been initialized, otherwise it returns false. Depending on the result of executing TryInitialize, a value is assigned to the _name field in the constructor. In this implementation, _name cannot be not initialized in the constructor. However, the compiler will issue a warning: Non-nullable field '_name' must contain a non-null value when exiting constructor. Consider declaring the field as nullable.
To fix the situation, you need to add the MemberNotNullWhen attribute:
[MemberNotNullWhen(true, nameof(_name))]
private bool TryInitialize(string name)The type of the first argument is bool, the second argument's type is string[] (with the params keyword). The attribute is used for methods with a return value of the bool type. The logic is simple: if the method returns a value that corresponds to the first argument of the attribute, the class members passed to params will be considered initialized.
It is not uncommon to have to create methods that throw out exceptions if something has not gone according to plan. Unfortunately, the compiler cannot always understand that program execution will be terminated after such a method is called.
Example:
private void ThrowException()
{
throw new Exception();
}
void Foo(string? str)
{
if (str == null)
ThrowException();
string notNullStr = str;
}For code above, the compiler will issue a warning: Converting null literal or possibly null value to non-nullable type. However, if str is null, the execution of the method will not reach the code fragment with the assignment, as an exception will be thrown. Thus, at the time of assignment, the str variable cannot be null.
The DoesNotReturn attribute allows you to tell the compiler that after executing the method marked with the attribute, the execution of the calling method stops.
Let's add the attribute for the throwException:
[DoesNotReturn]
private void ThrowException()Now the compiler knows that after this method is called, control will not be returned to the calling method. Therefore, null will never be written to notNullStr.
The DoesNotReturnIf attribute works similarly to DoesNotReturn, except for checking an additional condition.
Example:
private void ThrowException([DoesNotReturnIf(true)] bool flag)
{
if(flag)
throw new Exception();
}The compiler will assume that throwException will not return control to the calling method if the flag parameter is set to true.
To change the nullable context at the project level, you need to open the project properties and select the context in the "Build" section.
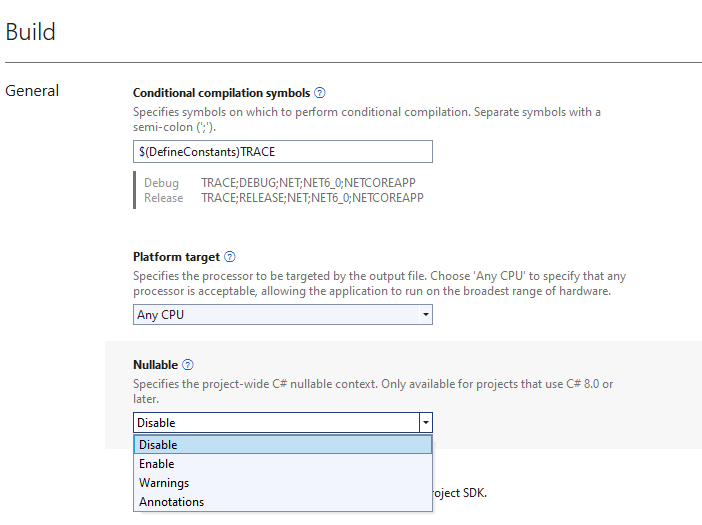
You can set the nullable context in the project file (.csproj). You need to open this file and write the value to the Nullable property:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net6.0</TargetFramework>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>disable</Nullable> // <=
</PropertyGroup>
</Project>It is likely that many people know that you can turn on or turn off the nullable context. However, there are two more context options.
Behavior in the nullable warning context:
This mode helps protect against exceptions of NullReferenceException type. The mode informs about the dereference of null reference.
Behavior in the nullable annotation context:
This mode helps make a smooth entry into the use of nullable reference types in the project. It allows you to markup variables that can and cannot be null.
Preprocessor directives are used at the file level with the .cs extension and allow you to change the states of the nullable context for fragments of code in this file. The way it works is similar to that described in the previous section. Each directive starts with '#'.
Let's look at all possible directives:
In fact, the enable value represents the enabled context of annotations and the context of warnings, and disable – on the contrary, these same contexts are in the disabled state. So the '#nullable enable' directive would be equivalent to writing '#nullable enable annotations' and '#nullable enable warnings' together.
You can use multiple directives in one file at once. This allows you to set a different nullable context for different code fragments.
Let's look at an example of such usage (at the project level, nullable-context is disabled):
.... // nullable-context is disabled in this code fragment
#nullable enable warnings
.... // the warning context is enabled in this code fragment
#nullable enable annotations
.... // the context of warnings and annotations is enabled
// in this code fragment
#nullable disable annotations
.... // only the warning context is enabled in this code fragment
#nullable restore
.... // nullable-context is disabled in this code fragment
// (since the Nullable property – disable)In conclusion, being able to use nullable reference types should be of great benefit to developers. These types allow you to make the application more secure and correct from the point of view of architecture.
This mechanism is not without its drawbacks either. About drawbacks, and in general about nullable reference types, my colleagues told in articles: one, two. The ability to add attributes makes sense largely because of the imperfection of the static analyzer. Therefore, it is necessary to add annotations to methods, fields, etc. manually, because the analyzer cannot understand some relationships. For example, the relationship between the return value of a method and the null state of a variable.
A number of drawbacks are the result of insufficient in-depth analysis. Such analysis cannot be done on the fly. On the other hand, it is not required. nullable-context is a good help in the code-writing process. When part of the functionality is ready and it needs to be tested, we recommend using tools for deeper analysis – for example, PVS-Studio.
0
0
0
0