
Our website uses cookies to enhance your browsing experience.

In most cases, you can solve a task in an intuitive, procedural way. However, the simplest option isn't always the best. I invite you to take a look at a real-world example of transforming a solution into an object-oriented one and explore the benefits it can bring.

At PVS-Studio, we develop a static code analyzer. Our daily work involves the creation of new diagnostic rules that detect potential errors in code. You can learn how static analysis works here, and here you can learn more about the Java analyzer. However, explaining the basics of how our two tools — the syntax tree and the semantic model — work is enough to understand the task.
So, we have a syntax tree that consists of code elements. I won't be a smarty-pants but will show you the diagram from the above article:
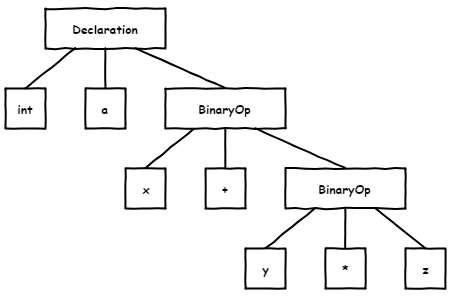
As you may have guessed, this is the parse tree for the following code:
int a = x + y * z;We also have various semantic information about each node: type, variable declaration location, etc. Okay, now we're done with the basics! We'll discuss the rest as we go along. To make the information more digestible, I'll cut to the chase and intentionally simplify the API.
We need to implement a diagnostic rule that detects a real-type variable as the for loop counter. The rule implementation is trivial: we just need to check the type of counter variables (and handle special cases like the for (;;) loops). Next comes the question of the certainty level. This is where all the fun begins.
One of the main risks of using real-type counters is excessive (or missing) iterations. Since for is often defined as a loop with a given number of iterations, this behavior is particularly harmful in its case. In the real world, however, people don't always use tools as intended (you can use the for loop similarly to while). So, how do we distinguish one programmer's intention from another? Heuristics!
We have the following rule: if we can get all variable values in the loop declaration from the method context, then a programmer definitely expected a certain number of iterations. In such a case, we issue a second-level warning. Otherwise, we can't be sure of the programmer's intentions and will issue a third-level warning.
Warnings in our analyzer have three levels. They show how certain we are about a warning issued by the analyzer. The first level is the most certain, the third is the most questionable.
In this case, I'd prefer the second level to the first, because not every counter of a real type results in an excessive iteration. For example, the two following loops will run the same number of times (20 each):
for (double i = 0.0; i < 1.0; i += 0.05) { }
for (double i = 0.0; i <= 1.0; i += 0.05) { }In the first case, the behavior is expected, while in the second case, the iteration is missing. Don't expect correct results when checking a real number for equality.
The third-level warning is issued if the number of iterations was expected to be given and the loop is in a method, or for a rare but possible infinite loop (CVE-2006-6499).
For a second-level warning, the reference case is when all values are in the loop declaration:
for (double i = 0.0; i < 1.0; i += 0.1) { }We also need to find cases like this, though:
double lowerBoundary = 0.5;
for (double i = lowerBoundary; i < 1.0; i += 0.1) { }And like this:
double shift = 0.5;
double lowerBoundary = 0.0 + shift;
double upperBoundary = 1.0;
for (double i = lowerBoundary; i < shift + upperBoundary; i += 0.1) { }If values in the loop come from outside (from object fields or method parameter) we issue the third-level warning.
So, we have a syntax tree node with the for loop declaration. We need to return true or false depending on whether we can get all values from the local context.
In each loop section — counter initialization, counter update, and stop condition — we'll check the source of values in expressions.
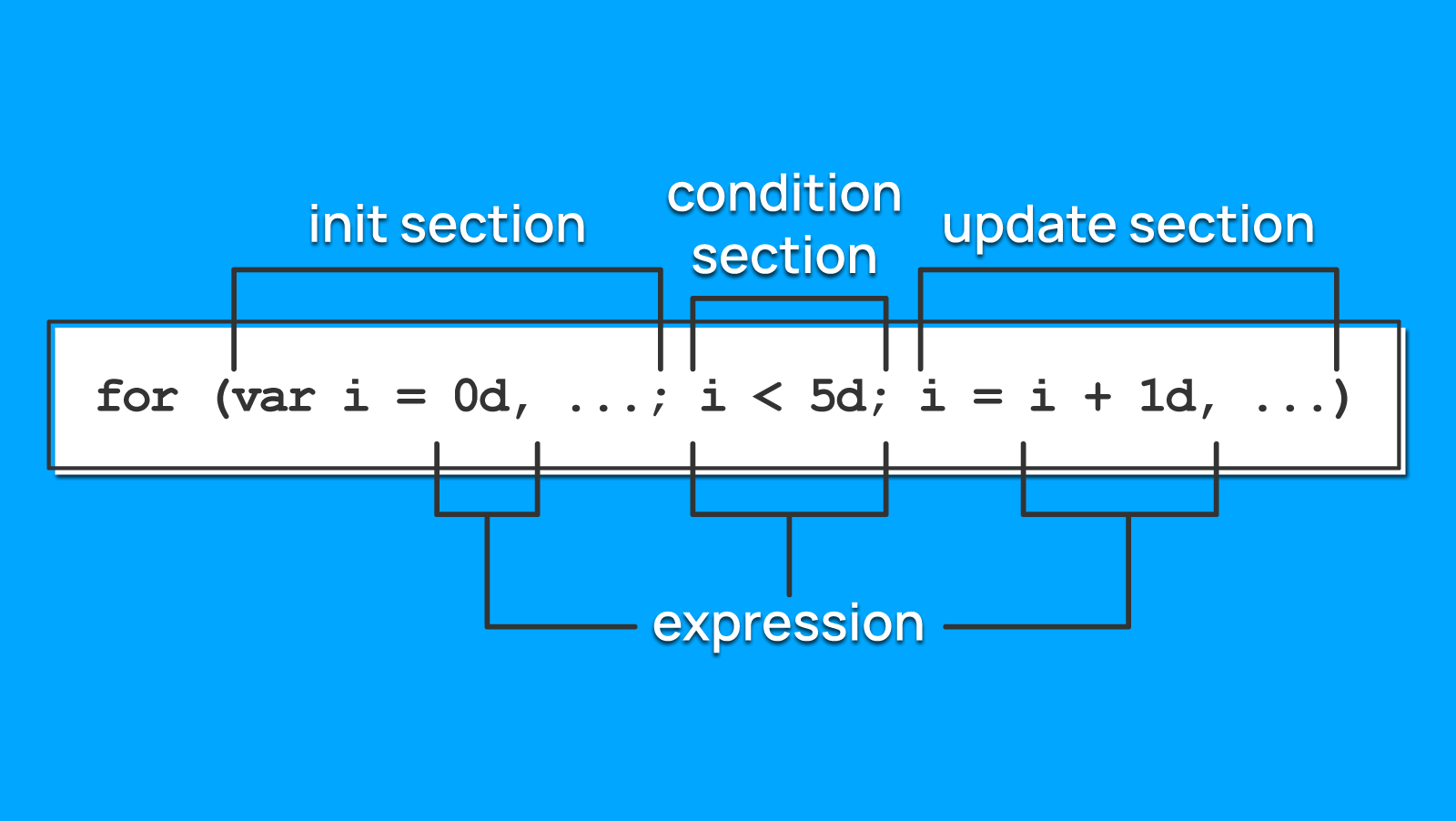
Expressions can consist of the following elements:
Of course, just investigating the neighboring nodes in the syntax tree is not enough, because expressions can consist of other subexpressions, and some variables can depend on others. So, we need a way to traverse the whole tree, not just the neighboring nodes (and those obtained from semantic analysis).
The stop condition is the traversal of all terminal nodes (those that have no child nodes). If all terminal nodes in the traversal are literals, then the value is predictable. Otherwise, it's unpredictable.
So, we need to traverse a tree of unknown depth. The classic solution is recursion. Let's write the isAccessible method, which takes an expression as input, then expands it and determines the accessibility of the value source.
private static boolean isAccessible(CtCodeElement el) {
return isAccessible(el, Collections.emptyList());
}
private static boolean isAccessible(
CtCodeElement el,
List<CtVariable> exclude
) {
if (isCodeElementEqualsToAny(el, exclude)) {
return true;
}
var expressionElements = new LinkedList<CtCodeElement>();
parseExpression(el, expressionElements);
return expressionElements.stream().allMatch(x -> x instanceof CtLiteral);
}
private static void parseExpression(
CtCodeElement el,
List<CtCodeElement> terminalNodes
) {
if (el instanceof CtBinaryOperator) {
var op = (CtBinaryOperator) el;
parseExpression(op.getLeftHandOperand(), terminalNodes);
parseExpression(op.getRightHandOperand(), terminalNodes);
} else if (el instanceof CtUnaryOperator) {
parseExpression(((CtUnaryOperator)el).getOperand(), terminalNodes);
} else if (el instanceof CtVariable) {
parseExpression(Optional.ofNullable(((CtVariable)el).getDeclaration())
.map(CtDeclaration::getDefaultExpression)
.orElse(null), terminalNodes);
} else {
terminalNodes.add(el);
}
}There's no point in expanding the counter in the sections of the counter condition and update, because we'll check it first. Here's the code of the method:
private static boolean isCodeElementEqualsToAny(
CtCodeElement el,
List<CtVariable> toCompare
) {
return el instanceof CtVariable
&& toCompare.stream()
.anyMatch(x -> ((CtVariable)el).equals(x));
}The hardest work is done. The only thing left to do is to get the expressions from each section of the loop. It's simple in the init section: you can either declare the counter directly in the section or use an existing variable. Anyway, we care only about the expression, which result is assigned to the counter. There can be more than one counter, so we keep that in mind as well.
public boolean areInitsPredictable() {
return init.stream().allMatch(x -> {
if (x instanceof CtLocalVariable) {
return isAccessible(((CtLocalVariable)x).getDefaultExpression());
} else if (x instanceof CtAssignment) {
return isAccessible(((CtAssignment)x).getAssignment());
} else {
return false;
}
});
}It's very simple when it comes to the condition: just check whether it's a binary operator (if not, our job here is done), then expand and check the operands.
public boolean isConditionPredictable(
List<CtVariableReference> initReferences
) {
var operator = safeCast(condition, CtBinaryOperator.class);
if (operator == null)
return false;
return Stream.of(
operator.getLeftHandOperand(),
operator.getRightHandOperand()
).allMatch(x -> isAccessible(x, initReferences));
}@Nullable
public static <T> T safeCast(Object obj, @Nullable Class<T> cl) {
return cl != null && cl.isInstance(obj) ? cl.cast(obj) : null;
}And finally, the update section. Everything is almost the same here: we expand the binary operator and stop at unary ones — increments, for example.
public boolean areUpdatesPredictable(
List<CtVariableReference> initReferences
) {
return update.stream().allMatch(x -> {
if (x instanceof CtAssignment) {
return isAccessible(
((CtAssignment)x).getAssignment(),
initReferences
);
} else {
return x instanceof CtUnaryOperator;
}
});
}Then we put it all together:
public boolean areAllValuesPredictable() {
var initReferences = getInitReferences();
return areInitsPredictable()
&& isConditionPredictable(initReferences)
&& areUpdatesPredictable(initReferences);
}The algorithm is pretty much the same as the one for getting expressions from the init section. We just need the left initialization/declaration part.
public List<CtVariable> getInitReferences() {
var res = new LinkedList<CtVariable>();
init.forEach(x -> {
if (x instanceof CtLocalVariable) {
res.add(((CtLocalVariable) x).getVariable());
} else if (x instanceof CtAssignment) {
var variableWrite = safeCast(
((CtAssignment) x).getAssigned(),
CtVariableWrite.class
);
if (variableWrite != null) {
res.add(variableWrite.getVariable());
}
}
});
return res;
}That's it! The code works, it passes tests, and potential bugs are found.
The procedural code is quite readable, and the solution gets the job done. Is there anything we can enhance here?
Of course, the question is open to debate because of KISS, YAGNI, and so on. However, it's worth recalling sometimes that work isn't limited to just one task. Thinking broadly makes sense. Syntactic and semantic analysis aren't the only tools the analyzer has, but they are among the most basic ones. And we use them a lot, of course.
So, if we accept the hypothesis that the frequent traversal of the syntax tree is necessary, it's better to reuse the code. Obviously, it's not always possible to use the same parseExpressions method "as is". We may want to change the depth-first search to a breadth-first search, or choose an even more elegant tree-traversal algorithm. Maybe we need different rules for expanding expressions or getting semantic information (expanding array elements, for example).
Of course, we can move methods into a utility class and refactor them, but after a few iterations, the code will predictably turn into spaghetti. Can you feel that? That's the premise of using patterns!
It's decided: let's build an OOP-based solution. How exactly do we achieve the result? We can use classic design patterns to encapsulate the desired behavior. I don't want to take away the credit from GoF and thousands of others who have already described them, but a quick reminder is necessary.
Since almost the whole task is based on traversing the syntax tree, the iterator is self-explanatory. Its standard class diagram looks like this.
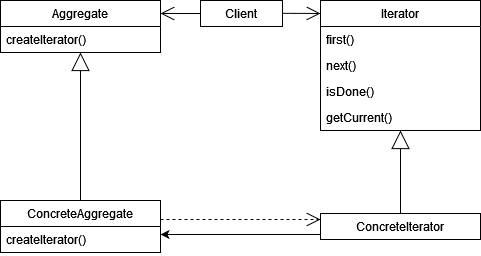
As for the iterator, everything is clear: we can move, get the current element, and determine when we're done traversing.
An aggregate usually refers to the collection being iterated over. But wait! A careful reader may have noticed that we were given an element of the tree as an input, but not a collection.
Now it's time for some abstract thinking. After all, we not only traverse the tree (operator expansion), but also look for the variable initialization (we go to completely different nodes of this tree). That is, the "collection" is rather abstract and exists only in our minds. It doesn't quite follow the pattern... Fortunately, patterns aren't a set of strict rules, so we can safely move away from them and forget about the entire left side of the diagram.
Okay, we've agreed that an iterator should encapsulate the traversal behavior of some (abstract) set of elements. Although, didn't we want to be able to implement different traversal strategies if we needed to? Oh, well, I just said that :).
Of course, we could implement them in different concrete iterators, but here's the problem: there can be many types of these strategies. As I've said, we may want to change the collection traversal algorithm from width-first to depth-first, or we may want to change the principle of expanding nodes (in our case, to add nodes from semantic information). So, if we combined these algorithms in a concrete iterator, we would get combinatorial growth of iterator types.
Working with composition instead of inheritance resolves the issue, so I suggest leaving the type of traversal algorithm in the iterator and encapsulating the node expansion in the strategy. Its default diagram looks like this.
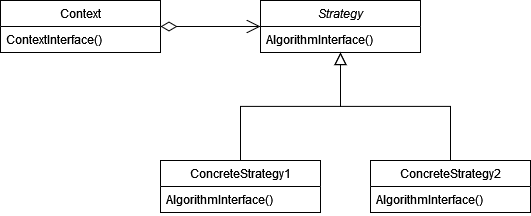
In our case, the context is the iterator itself, and everything else should be clear. The only thing left to understand is how to distribute the traversal behavior among the different strategies.
Another hypothesis is that operator expansion is such a common operation that we consider it the default one. In such a case, we can put an alternative method for expanding a node into a hook, which is a special case of the template method. Take a look at its diagram below.
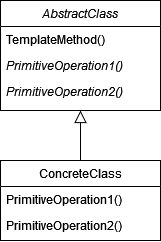
Now we can finish revising the necessary theory and finally move on to practice.
Let's move on to the implementation. We'll begin, as we did last time, by expanding the nodes. In this case, with the strategy implementation.
As such, we introduce the TreeNode class, which encapsulates the expansion behavior of the nodes and has a hook for implementing alternative strategies. The expansion of the expression is done in the getChildrenInternal method, which can use getChildrenHook overridden in the children.
public class TreeNode {
private CtCodeElement element;
private List<CtCodeElement> children = null;
public TreeNode(CtCodeElement element) {
this.element = element;
}
public final CtCodeElement getElement() {
return element;
}
public final void setElement(CtCodeElement element) {
this.element = element;
children = null;
}
// A method that implements node expansion behavior
private List<CtCodeElement> getChildrenInternal() {
var current = getElement();
if (current instanceof CtLiteral) {
return Collections.emptyList();
}
var children = getChildrenHook();
if (children != null) {
return children;
} else if (current instanceof CtBinaryOperator) {
CtBinaryOperator op = (CtBinaryOperator) current;
return Arrays.asList(op.getLeftHandOperand(),
op.getRightHandOperand());
} else if (current instanceof CtUnaryOperator) {
return Collections.singletonList(
((CtUnaryOperator) current).getOperand()
);
} else {
return Collections.emptyList();
}
}
protected List<CtCodeElement> getChildrenHook() {
return null;
}
// Wrapper methods for using the node cache
public List<CtCodeElement> getChildren() {
if (children == null) {
children = getChildrenInternal();
}
return children;
}
public boolean hasChildren() {
if (children == null) {
children = getChildrenInternal();
}
return !children.isEmpty();
}
}The algorithm won't find where the variable is initialized. We'll leave that to the children. Let's go back to the diagnostic class and add a method that returns an anonymous class.
private TreeNode createDeclarationFinderNode(CtCodeElement el) {
return new TreeNode(el) {
@Override
public List<CtCodeElement> getChildrenHook() {
var el = this.getElement();
CtExpression expr = null;
if (el instanceof CtLocalVariable) {
expr = ((CtLocalVariable) el).getDefaultExpression();
} else if (el instanceof CtAssignment) {
expr = ((CtAssignment) el).getAssignment();
} else if (el instanceof CtVariable) {
expr = Optional.of(((CtVariable) el))
.map(CtVariable::getDeclaration)
.map(CtDeclaration::getDefaultExpression)
.orElse(null);
}
return expr != null ? Collections.singletonList(expr)
: null;
}
};
}Now, if we encounter a variable, the semantic analysis is added to the syntactic one, and we can add new nodes for traversal.
Only the iterator is left. In addition to the lack of an aggregate, I'll take a few more liberties and make the interface a little bit smaller than the one shown in the diagram. We don't need first(), and instead of isDone() let's use getCurrent(), which returns null. The behavior of node expansion is determined by the TreeNode type passed to the constructor, so the default traversal algorithm (breadth-first) is the logic that remains here.
public class TreeIterator {
private final TreeNode currentNode;
private final LinkedList<CtCodeElement> unfoldedNodes = new LinkedList<>();
public TreeIterator(CtCodeElement node) {
currentNode = new TreeNode(node);
}
// A constructor for creating an iterator with the TreeNode child
public TreeIterator(
CtCodeElement node,
Function<CtCodeElement, TreeNode> constructor
) {
currentNode = constructor.apply(node);
}
public CtCodeElement getCurrentNode() {
return currentNode.getElement();
}
public boolean isTerminalNode() {
return !currentNode.hasChildren();
}
public CtCodeElement next() {
var children = currentNode.getChildren();
if (children != null)
unfoldedNodes.addAll(children);
if (unfoldedNodes.isEmpty())
return null;
currentNode.setElement(unfoldedNodes.pop());
return currentNode.getElement();
}
}Finally, we adapt the methods already written in the procedural section (method calls that haven't been encountered before are explained in the same section of this article).
Let's start with making analogs of isAccessible that will be designed to detect whether the following condition is met: there should be nothing in the terminal node except for the literal (the only exception is the counter).
private static boolean isPassable(TreeIterator iterator, CtCodeElement el) {
return !iterator.isTerminalNode() || el instanceof CtLiteral;
}
private static boolean isPassableOrExcludes(
TreeIterator iterator,
CtCodeElement el,
List<CtVariableReference> exclude
) {
return isPassable(iterator, el)
|| el instanceof CtVariable && isCodeElementEqualsToAny(el, exclude);
}Now we can safely redo the initialization.
private boolean areInitsPredictable() {
for (var el : init) {
var iterator = new TreeIterator(el, this::createDeclarationFinderNode);
for (var node = iterator.getCurrentNode();
node != null;
node = iterator.next()
) {
if (!isPassable(iterator, node)) {
return false;
}
}
}
return true;
}Handle the condition in the same way.
private boolean isConditionPredictable(
List<CtVariableReference> initReferences
) {
var iterator = new TreeIterator(condition, this::createDeclarationFinderNode);
for (
var node = iterator.getCurrentNode();
node != null;
node = iterator.next()
) {
if (!isPassableOrExcludes(iterator, node, initReferences)) {
return false;
}
}
return true;
}And update section. The additional logic is similar to that in the procedural part.
private boolean areUpdatesPredictable(
List<CtVariableReference> initReferences
) {
return update.stream()
.allMatch(
x -> {
if (x instanceof CtAssignment) {
var iterator = new TreeIterator(x, this::createDeclarationFinderNode);
for (
var node = iterator.getCurrentNode();
node != null;
node = iterator.next()
) {
if (!isPassableOrExcludes(iterator, node, initReferences)
) {
return false;
}
}
return true;
}
else {
return x instanceof CtUnaryOperator;
}
});
}The general method without any changes.
public boolean areAllValuesPredictable() {
var initReferences = getInitReferences();
return areInitsPredictable()
&& isConditionPredictable(initReferences)
&& areUpdatesPredictable(initReferences);
}That's it! Feature-wise, the code is identical to what was written before, but now it's in an object-oriented style, so we can reuse and expand it. Although, it has gotten a little harder to figure out, hasn't it? :).
I hope I have shown you how a common task with an obvious procedural solution can be transformed into an object-oriented one. Of course, one can question the hypotheses presented in the text and accuse me of over-engineering. However, the topic of choosing approaches is beyond this article scope.
Feel free to share your thoughts in the comments. Is it worth continuing to talk about the use of patterns in real cases? Is the topic well-covered from a static analysis perspective?
By the way, the diagnostic rule from this article is included in PVS-Studio 7.29. If you would like to try out the new version, follow the link.
To stay tuned for new articles on code quality, we invite you to subscribe:
0
0
0

0