
Our website uses cookies to enhance your browsing experience.

A brief description of technologies used in the PVS-Studio tool, which let us effectively detect a large number of error patterns and potential vulnerabilities. The article describes the implementation of the analyzer for C and C++ code, but this information is applicable for modules responsible for the analysis of C# and Java code.

There are misconceptions that static code analyzers are simple programs based on code patterns search using regular expressions. This is far from the truth. Moreover, it is simply impossible to detect the vast majority of errors using regular expressions.
This wrong belief arose based on developers' experience when working with some tools, which existed 10-20 years ago. Back then, functionality of those tools often came down to searching for dangerous code patterns and such functions as strcpy, strcat and so on. RATS can be called a representative of such kind of tools.
Although such tools could provide benefit, they were generally irrelevant and ineffective. Since that time, many developers have had these memories that static analyzers are quite useless tools that interfere with the work rather than help it.
Time has passed and static analyzers started to represent complicated solutions performing deep code analysis and finding bugs, which remain in code even after a careful code review. Unfortunately, due to past negative experiences, many programmers still consider static analysis methodology as useless and are reluctant to introduce it into the development process.
In this article, I will try to somehow fix the situation. I'd like to ask readers to give me 15 minutes and get acquainted with technologies the PVS-Studio static code analyzer uses to find bugs. Perhaps after that you will look in a new way at static analysis tools and might like to apply them in your work.
Data flow analysis enables you to find various errors. Here are some of them: array index out of bounds, memory leaks, always true/false conditions, null pointer dereference, and so on.
Data analysis can be also used to search for situations when unchecked data coming from the outside is used. An attacker can prepare a set of input data to make the program operate in a way he needs. In other words, he can exploit insufficient control of input data as a vulnerability. A specialized V1010 diagnostic that detects unchecked data usage in PVS-Studio is implemented and constantly improved.
Data-Flow Analysis represents the calculation of possible values of variables at various points in a computer program. For example, if a pointer is dereferenced, and it is known that at this moment it can be null, then this is a bug, and a static analyzer will warn about it.
Let's take a practical example of data flow analysis usage for finding bugs. Here we have a function from the Protocol Buffers (protobuf) project meant for data validation.
static const int kDaysInMonth[13] = {
0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31
};
bool ValidateDateTime(const DateTime& time) {
if (time.year < 1 || time.year > 9999 ||
time.month < 1 || time.month > 12 ||
time.day < 1 || time.day > 31 ||
time.hour < 0 || time.hour > 23 ||
time.minute < 0 || time.minute > 59 ||
time.second < 0 || time.second > 59) {
return false;
}
if (time.month == 2 && IsLeapYear(time.year)) {
return time.month <= kDaysInMonth[time.month] + 1;
} else {
return time.month <= kDaysInMonth[time.month];
}
}In the function, the PVS-Studio analyzer found two logical errors and issued the following messages:
Let's pay attention to the subexpression "time.month < 1 || time.month > 12". If the month value is outside the range [1..12], the function finishes its work. The analyzer takes this into account and knows that if the second if statement started to execute, the month value certainly fell into the range [1..12]. Similarly, it knows about the range of other variables (year, day, etc.), but they are not of interest for us now.
Now let's take a look at two similar access statements to the array elements: kDaysInMonth[time.month].
The array set statically, and the analyzer knows the values of all of its elements:
static const int kDaysInMonth[13] = {
0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31
};As the months are numbered starting with 1, the analyzer ignores 0 at the beginning of the array. It turns out that a value in the range [28..31] can be taken from the array.
Whether a year is a leap one or not, 1 is added to the number of days. However, it's also not interesting for us now. Comparisons themselves are important:
time.month <= kDaysInMonth[time.month] + 1;
time.month <= kDaysInMonth[time.month];The range [1..12] (number of a month) is compared with the number of days in the month.
Considering the fact that February always takes place in the first case (time.month == 2), we get that the following ranges are compared:
As you can see, the result of comparison is always true, this is what the PVS-Studio analyzer is warning us about. Indeed, the code contains two identical typos. A day class member should have been used in the left part of the expression instead of month.
The correct code should be as follows:
if (time.month == 2 && IsLeapYear(time.year)) {
return time.day <= kDaysInMonth[time.month] + 1;
} else {
return time.day <= kDaysInMonth[time.month];
}The error considered here has already been described in the article February 31.
In the previous section, there is a description of a method where the analyzer evaluates possible variables' values. However, to find some errors, it is not necessary to know variables' values. Symbolic Execution involves solution of equations in symbolic form.
I have not found a suitable demo example in our error database, so let's consider a synthetic code example.
int Foo(int A, int B)
{
if (A == B)
return 10 / (A - B);
return 1;
}The PVS-Studio analyzer issues a warning V609 / CWE-369 Divide by zero. Denominator 'A - B' == 0. test.cpp 12
The values of A and B variables are not known to the analyzer. However, the analyzer knows that, when the 10 / (A - B) expression is evaluated, the variables A and B are equal. Therefore, division by 0 will occur.
I said that the values A and B are unknown. For the general case it is really so. However, if the analyzer sees a function call with specific values of the actual arguments, it will take them into account. Let's consider the example:
int Div(int X)
{
return 10 / X;
}
void Foo()
{
for (int i = 0; i < 5; ++i)
Div(i);
}The PVS-Studio analyzer warns about dividing by zero: V609 CWE-628 Divide by zero. Denominator 'X' == 0. The 'Div' function processes value '[0..4]'. Inspect the first argument. Check lines: 106, 110. consoleapplication2017.cpp 106
Here a mixture of technologies is working: data flow analysis, symbolic execution, and automatic method annotation (we will cover this technology in the next section). The analyzer sees that X variable is used in the Div function as a divisor. On this basis, a special annotation is built for the Div function. Further it is taken into account that in the function a range of values [0..4] is passed as the X argument. The analyzer comes to a conclusion that a division by 0 has to occur.
Our team has annotated thousands of functions and classes, given in:
All functions are manually annotated, which allows us to specify many characteristics that are important in terms of finding errors. For example, it is set that the size of the buffer passed to the function fread, must not be less than the number of bytes to be read from the file. The relationship between the 2nd and 3rd arguments, and the function's return value is also specified. It all looks as follows (you can click on the picture to enlarge it):
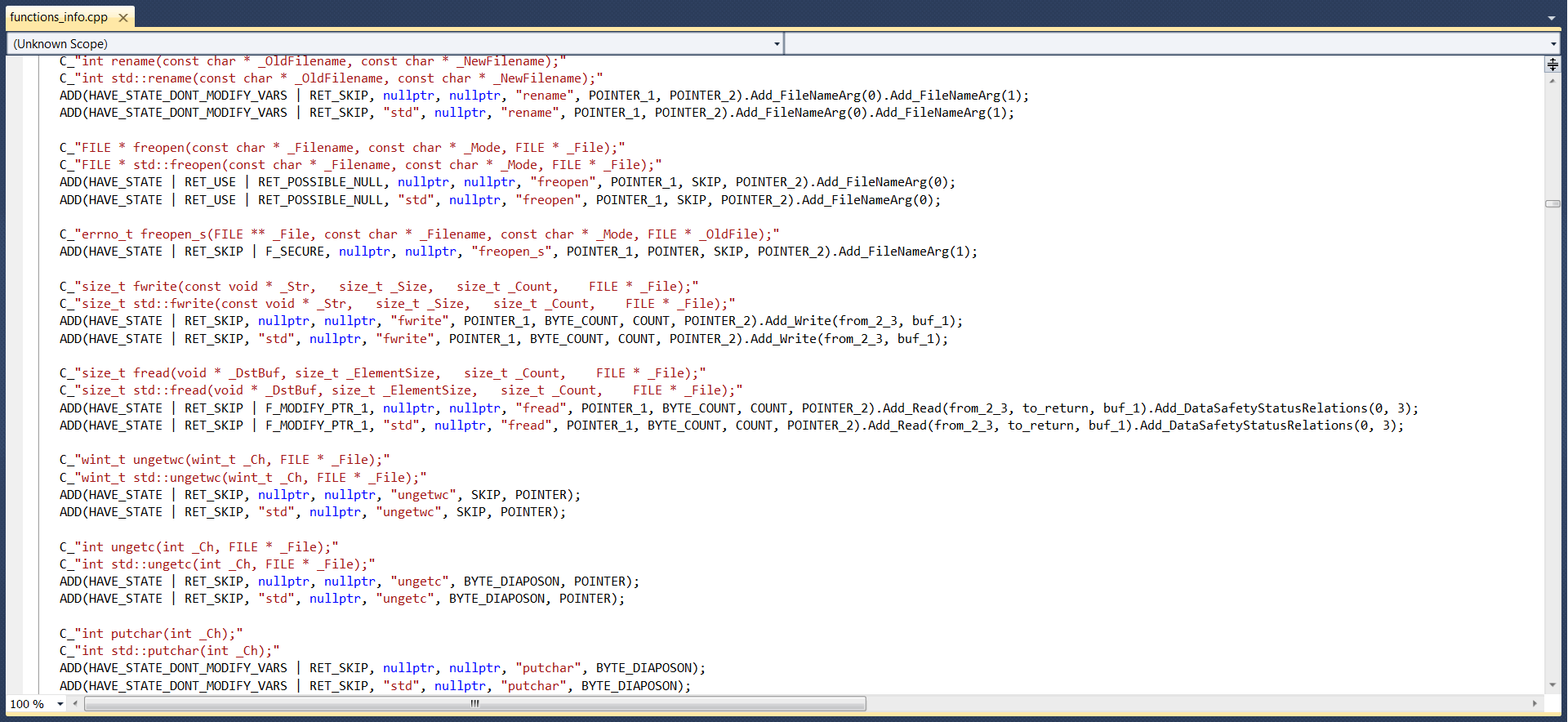
Thanks to this annotation in the following code, which uses fread function, two errors will be revealed.
void Foo(FILE *f)
{
char buf[100];
size_t i = fread(buf, sizeof(char), 1000, f);
buf[i] = 1;
....
}PVS-Studio warnings:
Firstly, the analyzer multiplied the 2nd and the 3rd actual argument and figured out that this function can read up to 1000 bytes of data. In this case, the buffer size is only 100 bytes, and an overflow can occur.
Secondly, since the function can read up to 1000 bytes, the range of possible values of the variable i is equal to [0..1000]. Accordingly, accessing an array by the incorrect index can occur.
Let's take a look at another simple error example, identifying of which became possible thanks to the markup of the memset function. Here we have a code fragment from the CryEngine V project.
void EnableFloatExceptions(....)
{
....
CONTEXT ctx;
memset(&ctx, sizeof(ctx), 0);
....
}The PVS-Studio analyzer has found a typo: V575 The 'memset' function processes '0' elements. Inspect the third argument. crythreadutil_win32.h 294
The 2nd and the 3rd arguments of function are mixed up. As a result, the function processes 0 bytes and does nothing. The analyzer notices this anomaly and warns developers about it. We have previously described this error in the article "Long-Awaited Check of CryEngine V".
The PVS-Studio analyzer is not limited to annotations specified by us manually. In addition, it tries to create annotations by studying bodies of functions itself. This enables to find errors of incorrect function usage. For example, the analyzer remembers that a function can return nullptr. If the pointer returned by this function is used without prior verification, the analyzer will warn you about it. Example:
int GlobalInt;
int *Get()
{
return (rand() % 2) ? nullptr : &GlobalInt;
}
void Use()
{
*Get() = 1;
}Warning: V522 CWE-690 There might be dereferencing of a potential null pointer 'Get()'. test.cpp 129
Note. You can approach searching for the error that we have just considered from the opposite direction. You can remember nothing about the return value but analyze the Get function based on knowledge of its actual arguments when you encounter a call to it. Such algorithm theoretically lets you find more errors, but it has exponential complexity. Time of the program analysis increases in hundreds to thousands of times, and we believe this approach is pointless from practical point of view. In PVS-Studio, we develop the direction of automatic function annotation.
At first glance, pattern-matching technology might seem the same as search using regular expressions. Actually, this is not the case, and everything is much more complicated.
Firstly, as I have already told, regular expressions in general are no good. Secondly, analyzers work not with text strings, but with syntax trees, allows recognizing more complex and higher-level patterns of errors.
Let's look at two examples, one is simpler and other is more complicated. I found the first error when checking the Android source code.
void TagMonitor::parseTagsToMonitor(String8 tagNames) {
std::lock_guard<std::mutex> lock(mMonitorMutex);
if (ssize_t idx = tagNames.find("3a") != -1) {
ssize_t end = tagNames.find(",", idx);
char* start = tagNames.lockBuffer(tagNames.size());
start[idx] = '\0';
....
}
....
}The PVS-Studio analyzer detects a classic error pattern related to wrong understanding by a programmer of operation priority in C++: V593 / CWE-783 Consider reviewing the expression of the 'A = B != C' kind. The expression is calculated as following: 'A = (B != C)'. TagMonitor.cpp 50
Look closely at this line:
if (ssize_t idx = tagNames.find("3a") != -1) {The programmer assumes that first the assignment is executed and then the comparison with -1. Comparison is actually happening in the first place. Classic. This error is covered in detail in the article on the Android check (see the section "Other errors").
Now let's take a closer look at a high-level pattern matching variant.
static inline void sha1ProcessChunk(....)
{
....
quint8 chunkBuffer[64];
....
#ifdef SHA1_WIPE_VARIABLES
....
memset(chunkBuffer, 0, 64);
#endif
}PVS-Studio warning: V597 CWE-14 The compiler could delete the 'memset' function call, which is used to flush 'chunkBuffer' buffer. The RtlSecureZeroMemory() function should be used to erase the private data. sha1.cpp 189
The crux of the problem lies in the fact that after null-filling the buffer using memset, this buffer is not used anywhere else. When building the code with optimization flags, a compiler will decide that this function call is redundant and will remove it. It has the right to do so, because in terms of C++ language, a function call doesn't cause any observable effect at program flow. Immediately after filling the buffer chunkBuffer the function sha1ProcessChunk finishes its work. As the buffer is created on the stack, it will become unavailable after the function exits. Therefore, from the viewpoint of the compiler, it makes no sense to fill it with zeros.
As a result, somewhere in the stack private data will remain that can lead to trouble. This topic is regarded in detail in the article "Safe Clearing of Private Data".
This is an example of a high-level pattern matching. Firstly, the analyzer must be aware of the existence of this security defect, classified according to the Common Weakness Enumeration as CWE-14: Compiler Removal of Code to Clear Buffers.
Secondly, it must find all the places in code where the buffer is created on stack, cleared using memset, and is not used anywhere else further on.
As you can see, static analysis is a very interesting and useful methodology. It allows you to fix a large number of bugs and potential vulnerabilities at the earliest stages (see SAST). If you still don't fully appreciate static analysis I invite you to read our blog where we regularly investigate errors found by PVS-Studio in various projects. You will not be able to remain indifferent.
We will be glad to see your company among our clients and will help to make your applications qualitative, reliable and safe.
0
0
0
0