
Our website uses cookies to enhance your browsing experience.

The article compares a specialized static analyzer Viva64 with universal static analyzers Parasoft C++Test and Gimpel Software PC-Lint. The comparison is carried within the framework of the task of porting 32-bit C/C++ code on 64-bit systems or developing new code with taking into account peculiarities of 64-bit architecture.
The purpose of this article is to show advantages of Viva64 analyzer in comparison with other products possessing similar functional abilities. Viva64 is a specialized static analyzer for verifying 64-bit C/C++ code [1]. Its scope of use is developing new 64-bit code or porting old code on 64-bit systems. By now the analyzer is implemented for Windows operation system being a module pluggable in Visual'Studio 2005/2008 development environment.
This article is topical because there is no systematized information about abilities of modern static analyzers which are announced as tools of diagnosing 64-bit errors. Within the framework of this article we will compare three most popular analyzers which implement checking of 64-bit code: Viva64, Parasoft C++Test, Gimpel Software PC-Lint.
Comparison made will be presented in the table and then we'll briefly touch upon each of the evaluation criteria. But at first let's explain some notions which will be used in this article.
Under a data model correlations of types' dimensions accepted within the framework of the development environment are understood. There can be several development environments holding different data models for one operation system, but usually there is only one model most corresponding the hardware and software environment. An example is a 64-bit Windows operation system for which LLP64 data model is native. But for the purpose of compatibility a 64-bit Windows supports 32-bit programs which work in ILP32LL data model.
Table 1 shows the most popular data models. We are interested first of all in LP64 and LLP64 data models.
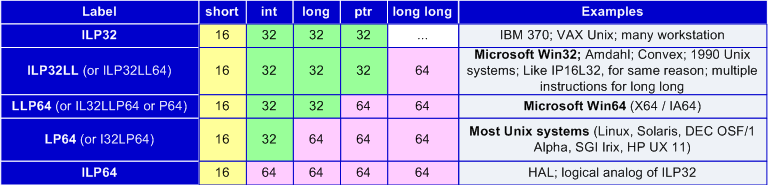
Table 1. Most popular data models.
LP64 and LLP64 data models differ only in the size of "long" type. But this small difference contains a great difference in recommended methodologies of developing programs for 64-bit operation systems of Unix and Windows families. For example, in Unix programs it is recommended to use long type or unsigned long type for storing pointers and creating loops to process a large number of elements. But these types are unsuitable for Windows programs and you should use ptrdiff_t and size_t instead of them. To learn more about peculiarities of using different data models you may read the article "Forgotten problems of developing 64-bit programs" [2].
In this article we speak about data models because different static analyzers are not always adapted for LP64 data model and LLP64 as well. Looking forward, we may say that Parasoft C++Test and Gimpel Software PC-Lint analyzers are better adapted for Unix systems than for Windows ones.
To make it easier to understand the matter of the article we'll use the term "memsize-type". This term appeared as a try to briefly name all the types capable of storing the size of pointers and indexes of the largest arrays. Memsize type can store the maximum array's size which can be theoretically allocated within the framework of the given architecture.
Under memsize-types we understand all the simple data types of C/C++ language which have 32-bit size on the 32-bit architecture and 64-bit size on the 64-bit one. Mind that long type is not a memsize-type in Windows while in Unix it is. To make it clearer the main memsize-types are shown in table 2.
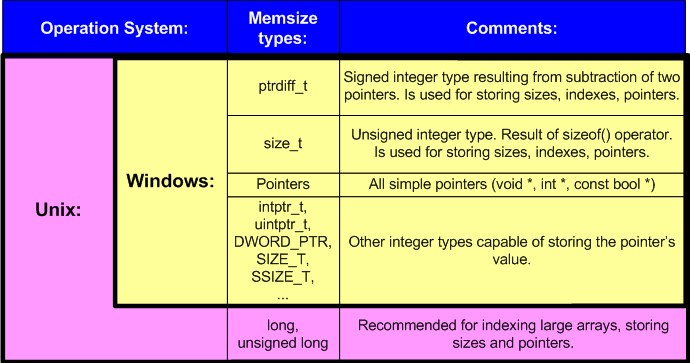
Table 2. Examples of memsize-types.
Let's set to the comparison of static analyzers itself. Comparative information is given in table 3. The list of evaluation criteria was composed on the basis of the static analyzers' documentation, articles and other additional sources. You may get acquainted with the original sources by the following links:

Table 3. Comparison of static analyzers from the viewpoint of searching 64-bit code's specific errors.
The names of the evaluation criteria listed in the table don't reveal much information by themselves. That's why let's briefly speak about each of them. Paragraph 3.1. corresponds to the first criterion, paragraph 3.2. to the second one etc.
To learn more about typical errors occurring while porting applications on 64-bit systems see the following articles: 20 issues of porting C++ code on the 64-bit platform [3], Problems of testing 64-bit applications [4], Development of resource-intensive applications in Visual C++ environment [5].
A typical example is the incorrect use of printf, scanf functions and their varieties:
1) const char *invalidFormat = "%u";
size_t value = SIZE_MAX;
printf(invalidFormat, value);
2) char buf[9];
sprintf(buf, "%p", pointer);In the first case it is not taken into consideration that size_t type is not equivalent to unsigned type on a 64-bit platform. This will cause printing of incorrect result if value > UINT_MAX.
In the second case it is not taken into consideration that the pointer's size can be more than 32 bit in future. As a result this code will cause an overflow on a 64-bit architecture.
In a low-quality code you may often see magical constants which are dangerous by themselves. During migration of the code on the 64-bit platform these constants may make it invalid if they participate in operations of calculating addresses, objects' size or in bit operations. The main magical constants are: 4, 32, 0x7fffffff, 0x80000000, 0xffffffff. For example:
size_t ArraySize = N * 4;
intptr_t *Array = (intptr_t *)malloc(ArraySize);Double type as a rule has 64-bit size and is compatible with IEEE-754 standard on 32-bit and 64-bit systems. Sometimes double type is used in the code to store and work with integer types:
size_t a = size_t(-1);
double b = a;
--a;
--b;
size_t c = b; // x86: a == c
// x64: a != cSuch code can be justified on a 32-bit system where double type can store a 32-bit integer value without loss as it has 52 significant bits. But when trying to save a 64-bit integer number into double the exact value can be lost.
Shift operations can cause a lot of troubles when used inattentively while porting code from a 32-bit to a 64-bit system. Let's consider the function defining the value of the specified bit as "1" in a variable of memsize type:
ptrdiff_t SetBitN(ptrdiff_t value, unsigned bitNum) {
ptrdiff_t mask = 1 << bitNum;
return value | mask;
}This code is valid on a 32-bit architecture and allows you to define bits with numbers from 0 to 31. After porting the program on a 64-bit platform you should define bits from 0 to 63. But the call of SetBitN(0, 32) function will return 0. You should take into consideration that "1" has int type and an overflow will occur at the shift of 32 positions and the result will be incorrect.
A lot of errors concerning the migration on 64-bit systems are related to the change of a pointer's size with respect to the size of simple integers. Many programmers stored pointers in such types as int and unsigned in their 32-bit programs. This is of course incorrect from the viewpoint of 64-bit data models. For example:
char *p;
p = (char *) ((unsigned int)p & PAGEOFFSET);You should keep in mind that one should use only memsize types for storing pointers in integer form. Fortunately, such errors are detected easily not only by static analyzers but by compilers as well when switching on corresponding options.
A peculiarity of union in C/C++ is that one and the same memory area is allocated for storing all items - members of a union. Although access to this memory area is possible using any of the items, still the item for access should be selected so that the result would be sensible.
You should be attentive to unions which contain pointers and other members of memsize type. Developers often mistakenly think that size of memsize type will always equal the group of other objects on all the architectures. Here is an example of an incorrect function implementing table algorithm for calculating the number of zero bits in variable "value":
union SizetToBytesUnion {
size_t value;
struct {
unsigned char b0, b1, b2, b3;
} bytes;
} u;
SizetToBytesUnion u;
u.value = value;
size_t zeroBitsN = TranslateTable[u.bytes.b0] +
TranslateTable[u.bytes.b1] +
TranslateTable[u.bytes.b2] +
TranslateTable[u.bytes.b3];Sometimes it is necessary (or simply convenient) to convert an array's items into items of a different type. Unsafe and safe type conversion is shown in the following code:
int array[4] = { 1, 2, 3, 4 };
enum ENumbers { ZERO, ONE, TWO, THREE, FOUR };
//safe cast (for MSVC2005/2008)
ENumbers *enumPtr = (ENumbers *)(array);
cout << enumPtr[1] << " ";
//unsafe cast
size_t *sizetPtr = (size_t *)(array);
cout << sizetPtr[1] << endl;
//Output on 32-bit system: 2 2
//Output on 64 bit system: 2 17179869187If your program has large hierarchies of inheritance of classes with virtual functions you may inattentively use arguments of different types which nearly coincide on a 32-bit system. For example, you use size_t type as an argument of a virtual function in a base class while in the descendant it is unsigned type. Consequently, this code will be incorrect on a 64-bit system.
Such errors don't always relate to complex inheritance hierarchies, for example:
class CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};Such errors may occur not only because of the programmer's inattention. The error shown in the example occurs if you have developed your code for earlier versions of MFC library where WinHelp function's prototype in CWinApp class was like this:
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);Surely, you have used DWORD type in your code. In Microsoft Visual C++ 2005/2008 the function's prototype was changed. On a 32-bit system the program will continue to work correctly as DWORD and DWORD_PTR types coincide here. But there will be troubles in the 64-bit program. You'll have two functions with same names but different parameters and as a result your code won't be executed.
Let's consider the following example:
unsigned short a16, b16, c16;
char *pointer;
...
pointer += a16 * b16 * c16;This code works correctly with pointers if "a16 * b16 * c16" expression's value doesn't exceed UINT_MAX (4Gb). Such code could always work correctly on a 32-bit platform as a program could never allocate an array of bigger size. On a 64-bit architecture the array's size will exceed UINT_MAX of items. Assume that we want to shift the pointer's value in 6.000.000.000 bytes and that's why variables a16, b16 and c16 have values 3000, 2000 and 1000 correspondingly. While calculating "a16 * b16 * c16" expression all the variables will be converted into int type according to C++ language's rules and only then they will be multiplied. During multiplication an overflow will occur. The incorrect result of the expression will be extended to ptrdiff_t type and the pointer will be calculated incorrectly.
Here is another example of the code valid in a 32-bit version and invalid in a 64-bit one:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); //Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); //Access violation on 64-bit platformLet's trace the way of calculating "ptr + (A + B)" expression:
Then "ptr + 0xFFFFFFFFu" expression is calculated but the result of this depends on the pointer's size on the given architecture. If addition will be carried in a 32-bit program the given expression will be equivalent to "ptr - 1" and we'll have number 3 printed.
In a 64-bit program 0xFFFFFFFFu value will be added to the pointer and as a result the pointer will be far beyond the array's limits.
In C and later C++ programming the practice was developed of using variables of int and unsigned types as indexes for working with arrays. But time passes and everything changes. And now it's high time to say: "Stop doing it! Use only memsize types for indexing large arrays." An example of incorrect code using unsigned type:
unsigned Index = 0;
while (MyBigNumberField[Index] != id)
Index++;This code cannot process an array containing more than UINT_MAX items in a 64-bit program. After the access to the item with UINT_MAX index an overflow of Index variable will occur and we'll get an eternal loop.
We would like Windows developers once more to pay attention that long type remains 32-bit in a 64-bit Windows. That's why Unix developers' advice to use long type for long loops is irrelevant.
Mixed use of memsize types and non-memsize types in expressions can cause incorrect results on 64-bit systems and relate to the change of the range of input values. Let's consider some examples:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; ++Index)
{ ... }This is an example of an eternal loop if Count > UINT_MAX. Assume that on 32-bit systems this code worked at the range of less than UINT_MAX iterations. But a 64-bit version of the program can process more data and it may need more iterations. Since Index variable's values lie in the range [0..UINT_MAX] condition "Index != Count" will never be fulfilled and cause an eternal loop.
Here is a small code showing that inaccurate expressions with mixed types can be dangerous (the results are received by using Microsoft Visual C++ 2005 in 64-bit compilation mode):
int x = 100000;
int y = 100000;
int z = 100000;
intptr_t size = 1; // Result:
intptr_t v1 = x * y * z; // -1530494976
intptr_t v2 = intptr_t(x) * y * z; // 1000000000000000
intptr_t v3 = x * y * intptr_t(z); // 141006540800000
intptr_t v4 = size * x * y * z; // 1000000000000000
intptr_t v5 = x * y * z * size; // -1530494976
intptr_t v6 = size * (x * y * z); // -1530494976
intptr_t v7 = size * (x * y) * z; // 141006540800000
intptr_t v8 = ((size * x) * y) * z; // 1000000000000000
intptr_t v9 = size * (x * (y * z)); // -1530494976It is necessary that all the operands in such expressions be converted to a type of larger dimension beforehand. Remember that an expression like
intptr_t v2 = intptr_t(x) * y * z;doesn't guarantee a correct result at all. It guarantees only that "intptr_t(x) * y * z" expression will have intptr_t type. The correct result shown by this expression in the example is nothing more than a good luck.
Danger of mixed use of memsize and non-memsize types can concern not only expressions. An example:
void foo(ptrdiff_t delta);
int i = -2;
unsigned k = 1;
foo(i + k);Above (see Incorrect pointer arithmetic) we discussed such a situation. An incorrect result here occurs because of the implicit extension of a factual 32-bit argument to 64 bits in the moment of function call.
Unsafe implicit type conversion may occur also when using return operation. An example:
extern int Width, Height, Depth;
size_t GetIndex(int x, int y, int z) {
return x + y * Width + z * Width * Height;
}
...
MyArray[GetIndex(x, y, z)] = 0.0f;Although we return the value of size_t type, "x + y * Width + z * Width * Height" expression is calculated with the use of int type. When working with large arrays (more than INT_MAX items) this code will behave incorrectly and we'll address other items of MyArray array than we wanted.
Generation and processing of exceptions with the use of integer types is not a good programming practice in C++ language. You should use more informative types for such aims, for example classes derived from std::exception classes. But sometimes you have to work with less quality code as in the example:
char *ptr1;
char *ptr2;
try {
try {
throw ptr2 - ptr1;
}
catch (int) {
std::cout << "catch 1: on x86" << std::endl;
}
}
catch (ptrdiff_t) {
std::cout << "catch 2: on x64" << std::endl;
}You should be very careful and avoid generation and processing of exceptions with the use of memsize types as it can change the program's working logic.
Be careful with explicit type conversions. They may change the program's executing logic when types' dimensions are changed or cause loss of significant bits. It is difficult to show type errors related to explicit type conversion by examples as they vary very much and are specific for different programs. You got acquainted with some of such errors earlier. But on a whole it is useful to look through all the explicit type conversions in which memsize types are used.
While porting 32-bit programs on a 64-bit platform the working logic may be changed and this is related to the use of overloaded functions. If a function is overlaid for 32-bit and 64-bit values, the access to it with the use of an argument of memsize type will be translated into different calls on different systems.
Such a change in the working logic may be dangerous. An example of this is saving into and reading from the data file by means of a set of functions like:
class CMyFile {
...
void Write(__int32 &value);
void Write(__int64 &value);
};
CMyFile object;
SSIZE_T value;
object.Write(value);Depending on the compilation mode (32- or 64-bit) this code will write into the file a different number of bytes what may cause failure of files' formats compatibility.
If you use bit fields you should take into consideration that using memsize types will cause change of sizes of structures and alignment. But that's not all. Let's consider a peculiar example:
struct BitFieldStruct {
unsigned short a:15;
unsigned short b:13;
};
BitFieldStruct obj;
obj.a = 0x4000;
size_t addr = obj.a << 17; //Sign Extension
printf("addr 0x%Ix\n", addr);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0xffffffff80000000Pay attention that if you compile this code for a 64-bit system you will have signed extension in "addr = obj.a << 17;" expression despite that both variables addr and obj.a are unsigned. This signed extension is determined by rules of type conversions which work in the following way:
1) obj.a member of the structure is converted from the bit field of unsigned short type into int type. We get int type but not unsigned int because the 15-bit field is placed into a 32-bit signed integer.
2) "obj.a << 17" expression has int type but it is converted into ptrdiff_t and then into size_t before it is assigned to addr variable. Signed extension occurs in the moment of conversion from int into ptrdiff_t.
It can be very dangerous when you are trying to calculate fields' addresses inside structures manually.
Such actions often cause generation of incorrect code. Diagnosis of such type errors is presented in C++test analyzer but unfortunately it is poorly described.
The use of long types in cross-platform code is theoretically always dangerous when porting code from a 32-bit to a 64-bit system. This is because long type has different sizes in two most popular data models - LP64 and LLP64. This kind of check implements search of all long's in applications' code.
This check is implemented in C++ Test unlike Viva64 and PC-Lint, but all the macros open and the full check is carried anyway. That's why let's consider that this type of check is implemented in Viva64 and PC-Lint too.
Sometimes you may find an overflow of an array which will occur while porting on a 64-bit architecture. For example:
struct A { long n, m; };
void foo(const struct A *p) {
static char buf[ 8 ]; // should have used sizeof
memcpy(buf, p, sizeof( struct A )); //Owerflow
...It is difficult to speak about efficiency of static analyzers. For sure, static analysis methodology is very useful and allows you to detect more errors already at the stage of writing the code what significantly reduces the period of debugging and testing.
But you should remember that static code analysis will never help you to detect all the errors even in the concrete sphere of 64-bit code analysis. Let's list the main reasons:
1. Some C++ language's elements are difficult for analysis. First of all this refers to generic classes' code as they work with different data types using same constructions.
2. Errors occurring while porting a 32-bit program on a 64-bit system may be not only in the code itself but also appear indirectly. A good example is a stack's size which by default doesn't change and equals 1 MB in Visual Studio 2005/2008 while building a 64-bit version of a project. While working 64-bit code may fill the stack much more than 32-bit code. This is related to the growth of sizes of pointers and other objects, to a different alignment. As a result a 64-bit program's version may suddenly lack the stack while working.
3. There are algorithmical errors caused by some suppositions concerning types' dimensions which change in a 64-bit system.
4. Exterior libraries may also contain errors.
This list is not complete but it allows us to state that some errors can be detected only when launching a program. In other words we need load testing of applications, dynamic analysis systems (for example, Compuware BoundsChecker), unit-testing, manual testing etc.
Thus, only a complex approach using different strategies and tools can guarantee a good quality of a 64-bit program.
You should also understand that criticism we referred to above by no means reduces the efficiency of static analysis. Static analysis is the most efficient method of detecting errors while porting 32-bit code on 64-bit systems. It allows you to detect most errors in rather a short time. The advantages of static analysis are as follows:
1. Possibility to check all the code branches irrespectively of the frequency of their execution in real conditions.
2. Possibility to carry the check already at the stage of migration or development of the code. It allows you to correct a lot of errors before testing and debugging. It saves a lot of resources and time. It is commonly known that the earlier an error is detected the cheaper it is to correct it.
3. A static analyzer can detect unsafe constructions a programmer considers correct as far as they are valid on 32-bit systems.
4. Static analysis allows you to evaluate code's quality from the point of view of its correctness for 64-bit systems and thus make the best plan of work.
5. A specialized analyzer Viva64 is the leader in the sphere of diagnosis of 64-bit code for Windows OS. First of all it is because of its orientation on LLP64 data model, and also because new specific diagnosis rules are implemented in it [1].
In the sphere of diagnosis of 64-bit code for operation system of Unix family preference should be given to a universal analyzer PC-Lint. You cannot judge about its leadership by table 3 but it implements more important rules in comparison with C++ Test.
0
0
0
0