
Our website uses cookies to enhance your browsing experience.


The article will familiarize application developers with tasks given them by the mass introduction of 64-bit multi-core processors symbolizing revolutionary increase of computing power available for an average user. It will also touch upon the problems of effective use of hardware resources for solving everyday applied tasks within the limits of Windows x64 operating system.
By default in this article we mean Windows as the operating system. By 64-bit systems we mean the x86-64 (AMD64) architecture. By the development environment - Visual Studio 2005/2008. You may download a demo sample which will be touched upon in the article using this link.
Parallel computing and large RAM size are now available not only for large firmware complexes meant for large-scale scientific computing, but are also used for solving everyday tasks related to work, study, entertainment and computer games.
The possibility of paralleling and large RAM size, on the one hand, make the development of resource-intensive applications easier, but on the other hand, requires more qualification and knowledge in the area of parallel programming from a programmer. Unfortunately, a lot of developers are far from possessing such qualification and knowledge. And this is not because they are bad developers but because they simply haven't come across such tasks. This is not surprising since creation of parallel systems of information processing has been performed mostly in scientific institutions while solving tasks of modeling and forecasting until recently. Parallel computer complexes with large memory size were used also for solving applied tasks by enterprises, banks etc, but they have been rather expensive and very few developers were able to get acquainted with the peculiarities of developing software for such systems.
The authors of the article managed to take part in the development of resource-intensive software products related to visualization and modeling of physical processes and to learn the peculiarities of development, testing and debugging of such systems by themselves. By resource-intensive software we mean program code which efficiently uses abilities of multiprocessor systems and large amount of memory (2GB and more). That's why we'd like to bring some knowledge to developers who may find it useful while creating modern parallel 64-bit systems in the nearest future.
Problems related to parallel programming have been studied in detail long ago and described in many books, articles and study courses. That's why this article will pay more attention to the sphere of organizational and practical issues of developing high-performance applications and to the use of 64-bit technologies.
While talking about 64-bit systems we'll consider that they use LLP64 data model (see table 1). This data model is used in 64-bit versions of the Windows operating system. But information given here may be also useful for those who work with systems using a data model different from LLP64.
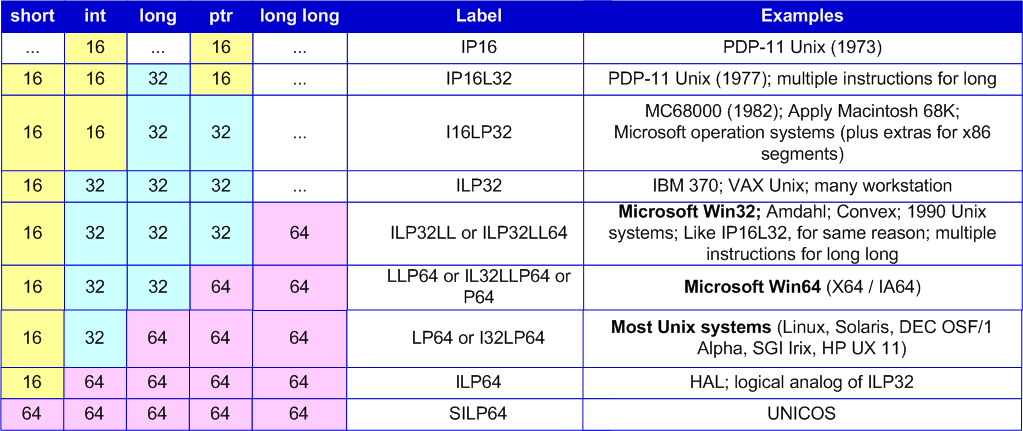
Table 1. Data models and their use in different operating systems.
Considering the conservatism in the sphere of developing large program systems, we would like, though, to advise you to use the abilities provided by multicore 64-bit processors. It may become a large competitive advantage over similar systems and also become a good reason for news in advertising campaigns.
It is senseless to delay 64-bit technology and parallelism usage since it is inevitable. You may ignore all-round passion for a new programming language or optimizing a program for MMX technology. But you cannot avoid increase of the amount of processed data and slowing down of clock frequency rise. Let's touch upon this statement in detail.
Parallelism is becoming the basis of productivity rise and this is related to the slowing down of the tempo of modern microprocessors' clock frequency rise. While the number of transistors on a dice is increasing, a sharp fall of clock frequency rise speed was outlined after 2005 (see figure 1). There is an article on this topic which is rather interesting: "The Free Lunch Is Over. A Fundamental Turn Toward Concurrency in Software" [1].
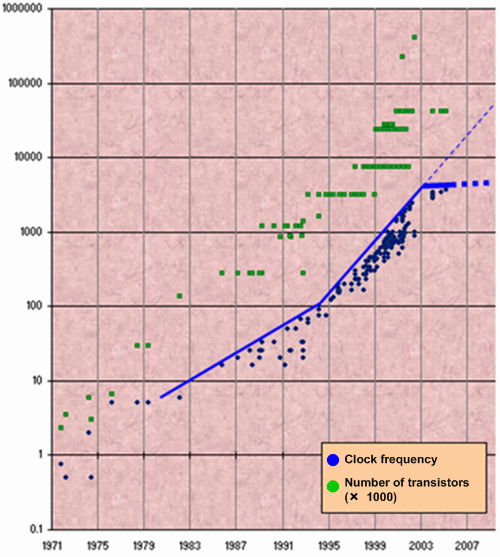
Figure 1. Rise of clock frequency and the number of transistors on a dice.
During last 30 years productivity has been determined by clock frequency, optimization of command execution and cache enlarging. In the next years it will be determined by the number of cores. Development of parallel programming will become the main direction of programming technologies' development.
Parallel programming will allow not only to solve the problem of slowing down of clock frequency rise but also to come to creation of scalable software which will fully use the increase of number of computational nodes in the processor. That is, software will gain productivity not only through the increase of the microprocessor's clock frequency, but through the rise of number of cores as well. Such systems are the future of software. And one who will master the new technologies quicker will be able to shift the software market for one's own benefit.
Although the use of 64-bit technologies doesn't look so impressive in comparison to parallelism, however, it provides a lot of new abilities too. Firstly, it is free 5-15% productivity rise. Secondly, large address space solves the problem of RAM fragmentation while working with large data sizes. The search for solution of this task has caused a lot of troubles for many developers whose programs crash because of memory shortage after several hours of work. Thirdly, this is an opportunity to easily work with data arrays of several GB. Sometimes it results in amazing rise of productivity, because HDD is not accessed.
If all said above doesn't convince you of advantages of 64-bit systems look closer what your colleagues or yourself are working at. Does somebody optimize code, raising the function's productivity in 10%, although this 10% can be got by simple recompilation of a program for the 64-bit architecture? Does somebody create his own class for working with arrays, loaded from files because there is no enough space for these arrays in memory? Do you develop your own manager of memory allocation in order not to fragment memory? If you say "Yes" to at least one of the question, you should stop and think for a while. Perhaps, you fight in vain. And perhaps, it would be more profitable to spend your time on porting your application on a 64-bit system where all these questions will disappear at once. Still, sooner or later you will have to spend your time on this.
Let's sum up all said above. It can be a waste of time trying to gain last profits from the 32-bit architecture. Save your time. Think about using parallelism and 64-bit address space to increase productivity. Give a new informational occasion and take the lead over your rivals while developing the market of high-performance applications.
So, you decided to use parallelism and 64-bit technologies in your program development. Perfect. So, let's touch upon some organizational questions first.
Inspite of you have to face the development of complex programs processing large amounts of data, still the company management often doesn't understand the necessity of providing the developers with the most high-performance computers. Although your applications may be intended for high-performance workstations, you are likely to test and debug them on your own machine. Of course all programmers need high-performance computers even if their programs don't process many GB of data. All have to compile them, launch heavy auxiliary tools and so on. But only a developer of resource-intensive software reveals all the troubles caused by the lack of RAM or slow speed of the disk subsystem.
Show this part of the article to your manager. Now we'll try to explain why it is profitable to invest money into your tools - computers.
This may sound trivial but a fast processor and a fast disk subsystem may speed up the process of applications' compilation greatly! It seems to you that there is no difference between two minutes and one minute of compilation of some part of the code, doesn't it? The difference is enormous! Minutes turn out into hours, days, months. Ask your programmers to count how much time they spend awaiting the code compilation. Divide this time at least by 1.5 and then you can calculate how quickly the investment into the new machinery will be repaid. I assure you that you will be amused.
Keep in mind one more effect which will help you to save work time. If some action takes 5 minutes one will wait. If it is 10 minutes one will go to make coffee, read forums or play ping-pong, what will take more than 10 minutes! And not because he is an idler or wants coffee very much - he will be just bored. Don't let the action be interrupted: push the button - get the result. Make those processes consume 5 minutes instead of 10.
Once again I want you to note that the aim is not to occupy a programmer with a useful task in his leisure-time but to speed up all the processes in general. Setting up a second computer (dual-processor system) so that the the programmer will switch to other tasks while waiting is wrong at all. A programmer's labor is not that of a street cleaner, who can clear a bench from snow during a break between breaking ice. A programmer's labor needs concentration on the task and keeping in mind a lot of its elements. Don't try to make a programmer switch to another task (this try will be useless), try to make it so that he could continue to solve the task he's working at as soon as possible. According to the "Stresses of multitask work: how to fight them" article a person needs 25 minutes to go deeply into some other task or return to an interrupted one. If you don't provide continuity of the process, half of the time will be wasted on this very switching over. It doesn't matter what it is - playing ping-pong or searching for an error in another program.
Don't spare money to buy some more gigabytes of memory. This purchase will be repaid after several steps of debugging a program allocating large memory size. Be aware that lack of RAM causes swapping and can slow down the process of debugging from minutes to hours.
Don't spare money to provide the machine with RAID subsystem. Not to be a theorist, here is an example from our own experience (table 2).
|
Configuration (pay attention to RAID) |
Time of building of an average project using large number of exterior libraries. |
|---|---|
|
AMD Athlon(tm) 64 X2 Dual Core Processor 3800+, 2 GB of RAM,2 x 250Gb HDD SATA - RAID 0 |
95 minutes |
|
AMD Athlon(tm) 64 X2 Dual Core Processor 4000+, 4 GB of RAM,500 Gb HDD SATA (No RAID) |
140 minutes |
Table 2. An example of how RAID affects the speed of an application's building.
Dear managers! Trust me that saving on hardware is compensated by delays of programmers' work. Such companies as Microsoft provide the developers with latest models of hardware not because of generosity and wastefulness. They do count their money and their example shouldn't be ignored.
At this point the part of the article concerning managers is over, and we would like to address creators of program solutions again. Do demand for the equipment you consider to be necessary for you. Don't be shy, since your manager is likely is not understanding that it is profitable for everybody. You should enlighten him. Moreover, in case the plan isn't fulfilled it is you who will seem to be guilty. It is easier to get new machinery than try to explain what are you wasting your time for. Imagine how can your excuse concerning why you have been correcting only one error all the day long sound: "It's a very large project. I launched the debugger, had to wait very long. And I have only one GB of memory. I can't work at anything else simultaneously. Windows began to swap. Found an error, corrected it, but I have to launch and check it again...". Perhaps, your manager won't say anything but will consider you just an idler. Don't allow this.
Your major task while developing a resource-intensive application is not designing a new system and even not the study of theory, this task is to demand to buy all the necessary hardware and software in time. Only after that you may begin to develop resource-intensive program solutions efficiently. It is impossible to write and check parallel programs without multicore processors. And it is impossible to write a system for processing large data sizes without necessary RAM size.
Before we switch to the next topic, we would like to share some ideas, which will help you to make your work process more comfortable.
You may try to solve the problem of slow building of a project by using special tools of parallel building of a system similar, for example, to Incredibuild by Xoreax Software (http://www.xoreax.com). Of course, there are other similar systems which may be found in the Web.
The problem of testing applications with large data arrays (launch of a tests set) for which usual machines are not productive enough, may be solved by using several special high-performance machines via remote access. An example of remote access tool is Remote Desktop or X-Win. Usually simultaneous test launches are performed only by a few developers. And for a group of 5-7 developers 2 dedicated high-performance machines are quite enough. It won't be the most convenient solution but it will be rather saving in comparison to providing every developer with such workstations.
The next obstacle on your way while developing systems for processing large data sizes is that you are likely to reconsider your methodology of work with the debugger or even refuse to use it at all.
Some specialists offer to refuse the debugging methodology because of some ideological reasons. The main argument is that the use of the debugger is the use of the 'cut and try' method. A person noticing the incorrect behavior of the algorithm at some step of its execution brings corrections into it without examining why this error occurred and without thinking about the way he corrects it. If he didn't guess the right way of correction he will notice it during the next execution of the code and bring new corrections. It will result in lower quality of the code. And the author of this code is not always sure that he understands how it works. Opponents of debugging method offer to replace it with more strict discipline of algorithm development, with the use of functions as small as possible so that their working principles are clear. Besides, they offer to pay more attention to unit testing and to use logging systems for analysis of the program's correct work.
There are some rational arguments in the described criticism of debugging systems but, as in many cases, one should weigh everything and not run to extremes. The use of the debugger is often convenient and may save much efforts and time.
Bad applicability of the debugger for systems processing large data sizes is unfortunately related not to ideological but practical difficulties. We'd like to familiarize the readers with these difficulties to save their time on fighting with the debugging tool when it is of little use, and prompt them to search for alternative solutions.
Let's study some reasons why alternative means should be used instead of a traditional debugger (for example, the one integrated into Visual C++ environment).
1) Slow program execution.
Execution of a program under a debugger processing millions and billions of elements may become practically impossible because of great time costs. Firstly, it is necessary to use debugging code variant with optimization turned off and that already slows down the speed of algorithm's work. Secondly, in the debug version of the program more memory is allocated in order to check bounds of memory blocks, memory fill during allocation/deallocation etc. This slows down the work even more.
One can truly notice that a program may be debugged not necessarily at large working data sizes and testing tasks are anough. Unfortunately, this is not so. An unpleasant surprise is that while developing 64-bit systems you cannot be sure that the algorithms work correctly when testing them at small amounts of data instead of working amounts of many GB.
Here is another simple example demonstrating the problem of necessary testing at large amounts of data.
#include <vector>
#include <boost/filesystem/operations.hpp>
#include <fstream>
#include <iostream>
int main(int argc, char* argv[])
{
std::ifstream file;
file.open(argv[1], std::ifstream::binary);
if (!file)
return 1;
boost::filesystem::path
fullPath(argv[1], boost::filesystem::native);
boost::uintmax_t fileSize =
boost::filesystem::file_size(fullPath);
std::vector<unsigned char> buffer;
for (int i = 0; i != fileSize; ++i)
{
unsigned char c;
file >> c;
if (c >= 'A' && c <= 'Z')
buffer.push_back(c);
}
std::cout << "Array size=" << buffer.size()
<< std::endl;
return 0;
}This program reads the file and saves all the capital English letters in the array. If all the symbols in the output file are capital English letters we won't be able to put more than 2*1024*1024*1024 symbols into the array on a 32-bit system, and consequently to process the file of more than 2 GB. Let's imagine that this program has been used correctly on a 32-bit system, taking this limitation into consideration, and no errors occurred.
On a 64-bit system we'd like to process files of larger size as there is no limitation of the array's size. Unfortunately, the program is written incorrectly from the point of view of LLP64 data model (see table 1) used in the 64-bit version of Windows. The loop contains int type variable whose size is still 32 bits. If the file's size is 6 GB, condition "i != fileSize" will never be fulfilled and an infinite loop will occur.
This code is intended to show how difficult it is to use the debugger while searching for errors which occur only at a large memory size. When you get an infinite loop while processing the file on the 64-bit system you may take a file containing 50 bytes and watch how the functions work under the debugger. But an error won't occur at such data size and it is impossible to watch the processing of 6 billion elements under the debugger.
Of course, you should understand that this is only an example and that it can be debugged easily and the cause of the infinite loop may be found. Unfortunately, this often becomes practically impossible in complex systems because of the slow speed of the processing of large amount of data.
To learn more about such unpleasant examples see articles "Forgotten problems of 64-bit program development" [2] and "20 issues of porting C++ code on the 64-bit platform" [3].
2) Multi-threading.
The method of several instruction flows executed simultaneously for speeding up the processing of large amount of data has been used for a long time and rather successfully in cluster systems and high-performance servers. But only with the appearance of multicore processors on market, the possibility of parallel data processing is widely used in applications. And the urgency of the parallel system development will only increase in future.
Unfortunately, it is not easy to explain what is difficult in debugging of parallel programs. Only on facing the task of searching and correcting errors in parallel systems one may feel and understand the uselessness of such a tool as a debugger. But in general, all the problems may be reduced to the impossibility to reproduce many errors and to the way the debugging process affects the workflow of parallel algorithms.
To learn more about the problems of debugging parallel systems you may read the following articles: "Program debugging technology for machines with mass parallelism" [4], "Multi-threaded Debugging Techniques" [5], "Detecting Potential Deadlocks" [6].
Using specialized methods and tools solves the difficulties described. You may handle 64-bit code by using static analyzers, which work with the input program code and do not require its launch. An example is the Viva64 static code analyzer [7].
To debug parallel systems you should pay attention to such tools as TotalView Debugger (TVD). TotalView is the debugger for the C, C++ and Fortran languages, which works on Unix-compatible operating system and macOS X. It allows controlling execution threads, shows data of one or all the threads, can synchronize the threads through breakpoints. It also supports parallel programs using MPI and OpenMP.
Another interesting application for multithreaded analysis is Intel® Threading Analysis Tools [8].
All the tools both mentioned and remaining undiscussed are surely useful and may be of great help while developing high-performance applications. But one shouldn't forget about such time-proved methodology as logging systems. Debugging via logging method hasn't become less urgent for several decades and still remains a good tool which we'll speak about in detail. The only change concerning logging systems is growing requirements applied to them. Let's try to list the properties a modern logging system should have for high-performance systems:
A logging system which meets these requirements allows solving the task of debugging parallel algorithms and also to debug algorithms processing large data arrays.
We won't give a particular example of a logging system's code in this article. It is hard to make such a system universal as it depends on the development environment very much, as well as the project's specificity, the developer's wishes and so on. Instead, we'll touch upon some technical solutions which will help you to create a convenient and effective logging system if you need it.
The simplest way to perform logging is to use the function similar to printf as shown in the example:
int x = 5, y = 10;
...
printf("Coordinate = (%d, %d)\n", x, y);Its natural disadvantage is that the information will be shown both in the debugging mode and in the output product. That's why we have to change the code as follows:
#ifdef DEBUG_MODE
#define WriteLog printf
#else
#define WriteLog(a)
#endif
WriteLog("Coordinate = (%d, %d)\n", x, y);This is better. And pay attention that we use our own macro DEBUG_MODE instead of a standard macro _DEBUG to choose how the function WriteLog will be implemented. This allows including debug information into release versions that is important when debugging at large amount of data.
Unfortunately, when compiling the non-debugging version in Visual C++ environment we get a warning message: "warning C4002: too many actual parameters for macro 'WriteLog'". We may turn this message off, but it is a bad style. We can rewrite the code as follows:
#ifdef DEBUG_MODE
#define WriteLog(a) printf a
#else
#define WriteLog(a)
#endif
WriteLog(("Coordinate = (%d, %d)\n", x, y));This code is not smart because we have to use double parentheses and this is often forgotten. That's why let's bring some improvements:
#ifdef DEBUG_MODE
#define WriteLog printf
#else
inline int StubElepsisFunctionForLog(...) { return 0; }
static class StubClassForLog {
public:
inline void operator =(size_t) {}
private:
inline StubClassForLog &operator =(const StubClassForLog &)
{ return *this; }
} StubForLogObject;
#define WriteLog \
StubForLogObject = sizeof StubElepsisFunctionForLog
#endif
WriteLog("Coordinate = (%d, %d)\n", x, y);This code looks complicated but it allows to write single brackets. When the DEBUG_MODE flag is turned off this code doesn't matter at all and you can safely use it in critical code fragments.
The next modification is to add parameters to the logging function. Let us add the specification level and information type. The specification level may be defined as a parameter, for example:
enum E_LogVerbose {
Main,
Full
};
#ifdef DEBUG_MODE
void WriteLog(E_LogVerbose,
const char *strFormat, ...)
{
...
}
#else
...
#endif
WriteLog (Full, "Coordinate = (%d, %d)\n", x, y);This is convenient because you can decide whether to filter unimportant messages or not after the program's shutdown using a special utility. The disadvantage of this method is that all the information is shown - both important and unimportant, and this may affect the productivity badly. That's why you may create several functions of the WriteLogMain, WriteLogFull type and so on, whose implementation will depend on the mode of the program's building.
We mentioned that the writing of the debugging information must not affect the speed of the algorithm's execution too much. We can reach this by creating a system for gathering messages, which are written in the thread executed simultaneously. The outline of this mechanism is shown on figure 2.
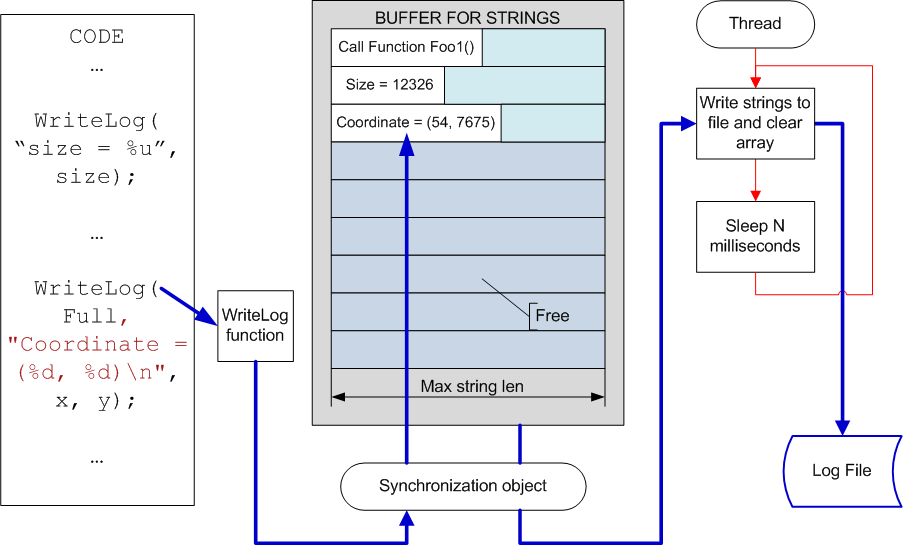
Figure 2. Logging system with the lazy write algorithm.
As you can see from the figure the next data portion is written into an intermediate array with strings of fixed length. The fixed size of the array and its strings allows excluding expensive memory allocation operations. This doesn't reduce the possibilities of this system at all. You can just select the strings' length and the array's size with spare. For example, 5000 strings of 4000 symbols will be enough for debugging nearly any system. And memory size of 20 MB which is necessary for that is not critical for modern systems, I think you'll agree with me. But if the array's overflow occurs anyway, it's easy to provide a mechanism for anticipatory writing of the information into a file.
The described mechanism provides practically instant execution of the WriteLog function. If there are offloaded processor's cores in the system the writing into the file will be practically transparent for the main program code.
The advantage of the described system is that it can function without changes while debugging the parallel program, when several threads are being written into the log simultaneously. You need just to add a process identifier so that you can know later from what threads the messages were received (see figure 3).
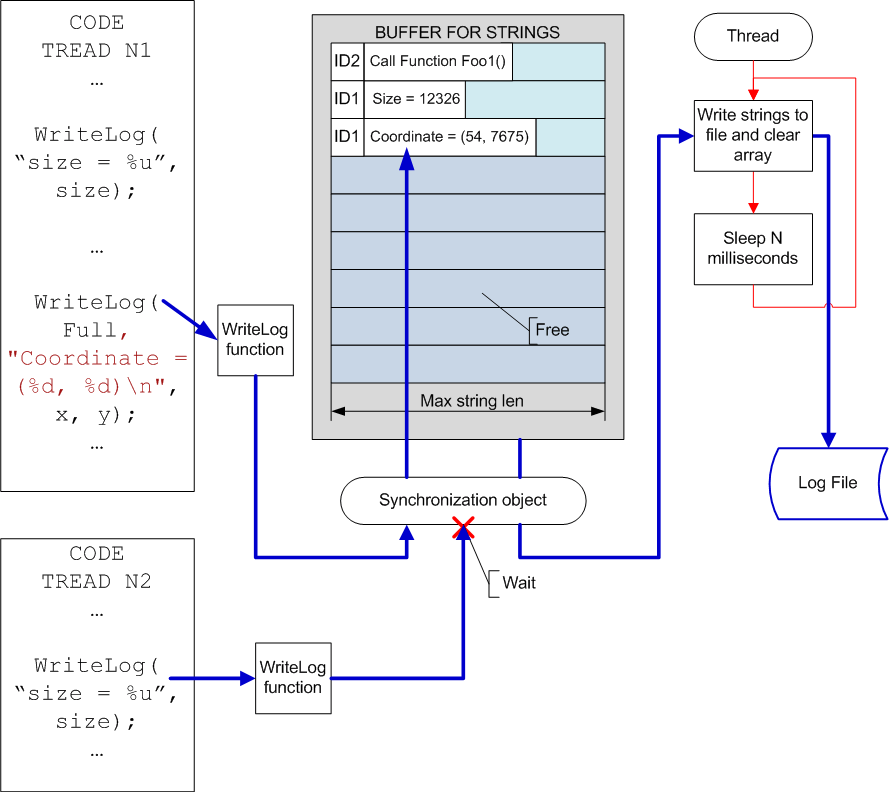
Figure 3. Logging system for multithread applications debugging.
The last improvement we'd like to suggest is showing the level of nesting of messages at the moment of functions' call or the beginning of a logical block. This can be easily organized by using a special class that writes an identifier of a block's beginning into the log in the constructor, and an identifier of the block's end in the destructor. Let's try showing this on an example.
Program code:
class NewLevel {
public:
NewLevel() { WriteLog("__BEGIN_LEVEL__\n"); }
~NewLevel() { WriteLog("__END_LEVEL__\n"); }
};
#define NEW_LEVEL NewLevel tempLevelObject;
void MyFoo() {
WriteLog("Begin MyFoo()\n");
NEW_LEVEL;
int x = 5, y = 10;
printf("Coordinate = (%d, %d)\n", x, y);
WriteLog("Begin Loop:\n");
for (unsigned i = 0; i != 3; ++i)
{
NEW_LEVEL;
WriteLog("i=%u\n", i);
}
}Log's content:
Begin MyFoo()
__BEGIN_LEVEL__
Coordinate = (5, 10)
Begin Loop:
__BEGIN_LEVEL__
i=0
__END_LEVEL__
__BEGIN_LEVEL__
i=1
__END_LEVEL__
__BEGIN_LEVEL__
i=2
__END_LEVEL__
Coordinate = (5, 10)
__END_LEVEL__Log after transformation:
Begin MyFoo()
Coordinate = (5, 10)
Begin Loop:
i=0
i=1
i=2
Coordinate = (5, 10)I think that's all for this topic. We'd like to mention at last that the article "Logging In C++" [9] may be of use for you too. We wish you successful debugging.
Using base data types corresponding to the hardware platform in C/C++ languages is an important point of creating quality and high-performance program solutions. With the appearance of 64-bit systems new data models have been used - LLP64, LP64, ILP64 (see table 1) and this changes the rules and recommendations concerning the use of base data types. Such types are int, unsigned, long, unsigned long, ptrdiff_t, size_t and pointers. Unfortunately, there are practically no popular literature and articles which touch upon the problems of choosing types. And those sources which do, for example "Software Optimization Guide for AMD64 Processors" [10], are seldom read by application developers.
The urgency of correct choice of base types for processing data is determined by two important causes: the correctness of the code execution and its efficiency.
Due to the historical development the base and the most often used integer type in C and C++ languages is int or unsigned int. It is accepted to consider the int type the most optimal as its size coincides with the length of the processor's computer word.
The computer word is a group of RAM bits taken by the processor at one call (or processed by it as a single group) and usually contains 16, 32 or 64 bits.
The tradition to make the int type size equal to the computer word has been seldom broken until recently. On 16-bit processors int consisted of 16 bits. On 32-bit processors it is 32 bits. Of course, there existed other correlations between int-size and the computer word's size but they were used seldom and are not of interest for us now.
We are interested in that fact that with the appearance of 64-bit processors the size of int type remained 32-bits in most systems. Int type has 32-bit size in the LLP64 and LP64 data models, which are used in 64-bit Windows operating system and most Unix systems (Linux, Solaris, SGI Irix, HP UX 11).
It is a bad decision to leave the int type size equal to 32 bits due to many reasons, but it is really a reasonable way to choose the lesser of two evils. First of all, it is related to the problems of providing backward compatibility. To learn more about the reasons of this choice you may read the "Why did the Win64 team choose the LLP64 model?" blog [11] and the "64-Bit Programming Models: Why LP64?" article [12].
For developers of 64-bit applications all said above is the reason to follow two new recommendations in the process of software development.
Recommendation 1. Use the ptrdiff_t and size_t types for loop counters and pointers arithmetic instead of the int and unsigned types.
Recommendation 2. Use the ptrdiff_t and size_t types for indexing in arrays instead of the int and unsigned types.
In other words you should use 64-bit data types in a 64-bit system whenever possible. Therefore you shouldn't use constructions like:
for (int i = 0; i != n; i++)
array[i] = 0.0;Yes, this is a canonical code example. Yes, it is included in many programs. Yes, with this learning the C and C++ languages begins. But it is recommended not to use it anymore. Use either an iterator or the ptdriff_t and size_t data types as it is shown in the improved example:
for (size_t i = 0; i != n; i++)
array[i] = 0.0;Developers of Unix applications may notice that the practice of using long type for counters and indexing arrays has appeared long ago. Long type is 64-bit in 64-bit Unix systems and it looks smarter than ptdriff_t or size_t. Yes, it's true but we should keep in mind two important points.
1) long type's size remained 32-bit in 64-bit Windows operating system (see table 1). Therefore it cannot be used instead of the ptrdiff_t and size_t types.
2) Using the long and unsigned long types causes a lot of troubles for developers of cross-platform applications for Windows and Linux systems. Long type has different sizes in these systems and only complicates the situation. It's better to stick to types, which have the same size in 32-bit and 64-bit Windows and Linux systems.
Now let's explain why we are so insistent asking you to use the ptrdiff_t/size_t type instead of the usual int/unsigned type on an example.
We'll begin with an example illustrating the typical error of using unsigned type for loop counter in 64-bit code. We have already described a similar example before but let's see it once again as this error is widespread:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; ++Index)
{ ... }This code is typical and its variants can be met in many programs. It is executed correctly in 32-bit systems where the value of Count variable cannot exceed SIZE_MAX (which is equal to UINT_MAX in a 32-bit system). In a 64-bit system the range of possible values for Count may be extended and in this case when Count > UINT_MAX, an eternal loop occurs. The proper correction of this code is to use the size_t type instead of unsigned.
The next example shows incorrect using of the int type for indexing large arrays:
double *BigArray;
int Index = 0;
while (...)
BigArray[Index++] = 3.14f;This code doesn't seem suspicious to an application developer accustomed to the practice of using variables of the int or unsigned types as arrays' indexes. Unfortunately, this code won't work in a 64-bit system if the size of the processed BigArray array becomes more than four billion items. In this case an overflow of Index variable will occur and the result of the program's work will be incorrect (not the entire array will be filled). Again, the correction of the code is to use the ptrdiff_t or size_t types for indexes.
As the last example we'd like to demonstrate the potential danger of mixed usage of 32-bit and 64-bit types, which you should avoid whenever possible. Unfortunately, few developers think about the consequences of inaccurate mixed arithmetic and the next example is absolutely unexpected for many (the results are received using Microsoft Visual C++ 2005 at 64-bit compilation mode):
int x = 100000;
int y = 100000;
int z = 100000;
intptr_t size = 1; // Result:
intptr_t v1 = x * y * z; // -1530494976
intptr_t v2 = intptr_t(x) * y * z; // 1000000000000000
intptr_t v3 = x * y * intptr_t(z); // 141006540800000
intptr_t v4 = size * x * y * z; // 1000000000000000
intptr_t v5 = x * y * z * size; // -1530494976
intptr_t v6 = size * (x * y * z); // -1530494976
intptr_t v7 = size * (x * y) * z; // 141006540800000
intptr_t v8 = ((size * x) * y) * z; // 1000000000000000
intptr_t v9 = size * (x * (y * z)); // -1530494976We want you to pay attention that expression of "intptr_t v2 = intptr_t(x) * y * z;" type doesn't guarantee the correct result at all. It guarantees only that expression "intptr_t(x) * y * z" will have intptr_t type. The article "20 issues of porting C++ code on the 64-bit platform" [4] will help you to learn more about this problem.
Now let's look at the example demonstrating the advantages of using the ptrdiff_t and size_t types from the viewpoint of productivity. For demonstration we'll take a simple algorithm of the minimal length of a path in the labyrinth calculation. You may see the whole code of the program here: http://www.Viva64.com/articles/testspeedexp.zip.
In this article we place only the text of the FindMinPath32 and FindMinPath64 functions. Both these functions calculate the length of the minimal path between two points in a labyrinth. The rest of the code is not of interest for us now.
typedef char FieldCell;
#define FREE_CELL 1
#define BARRIER_CELL 2
#define TRAVERSED_PATH_CELL 3
unsigned FindMinPath32(FieldCell (*field)[ArrayHeight_32],
unsigned x, unsigned y, unsigned bestPathLen,
unsigned currentPathLen) {
++currentPathLen;
if (currentPathLen >= bestPathLen)
return UINT_MAX;
if (x == FinishX_32 && y == FinishY_32)
return currentPathLen;
FieldCell oldState = field[x][y];
field[x][y] = TRAVERSED_PATH_CELL;
unsigned len = UINT_MAX;
if (x > 0 && field[x - 1][y] == FREE_CELL) {
unsigned reslen =
FindMinPath32(field, x - 1, y, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (x < ArrayWidth_32 - 1 && field[x + 1][y] == FREE_CELL) {
unsigned reslen =
FindMinPath32(field, x + 1, y, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (y > 0 && field[x][y - 1] == FREE_CELL) {
unsigned reslen =
FindMinPath32(field, x, y - 1, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (y < ArrayHeight_32 - 1 && field[x][y + 1] == FREE_CELL) {
unsigned reslen =
FindMinPath32(field, x, y + 1, bestPathLen, currentPathLen);
len = min(reslen, len);
}
field[x][y] = oldState;
if (len >= bestPathLen)
return UINT_MAX;
return len;
}
size_t FindMinPath64(FieldCell (*field)[ArrayHeight_64],
size_t x, size_t y, size_t bestPathLen, size_t
currentPathLen) {
++currentPathLen;
if (currentPathLen >= bestPathLen)
return SIZE_MAX;
if (x == FinishX_64 && y == FinishY_64)
return currentPathLen;
FieldCell oldState = field[x][y];
field[x][y] = TRAVERSED_PATH_CELL;
size_t len = SIZE_MAX;
if (x > 0 && field[x - 1][y] == FREE_CELL) {
size_t reslen =
FindMinPath64(field, x - 1, y, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (x < ArrayWidth_64 - 1 && field[x + 1][y] == FREE_CELL) {
size_t reslen =
FindMinPath64(field, x + 1, y, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (y > 0 && field[x][y - 1] == FREE_CELL) {
size_t reslen =
FindMinPath64(field, x, y - 1, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (y < ArrayHeight_64 - 1 && field[x][y + 1] == FREE_CELL) {
size_t reslen =
FindMinPath64(field, x, y + 1, bestPathLen, currentPathLen);
len = min(reslen, len);
}
field[x][y] = oldState;
if (len >= bestPathLen)
return SIZE_MAX;
return len;
}The FindMinPath32 function is written in classic 32-bit style using unsigned types. FindMinPath64 function differs from it only in that all the unsigned types in it are replaced by the size_t type. There are no other differences! I think you'll agree that this is an easy modification of the program. And now let's compare the execution speeds of these two functions (see table 2).
|
Mode and function. |
Function's execution time |
|
|---|---|---|
|
1 |
32-bit compilation mode. Function FindMinPath32 |
1 |
|
2 |
32-bit compilation mode. Function FindMinPath64 |
1.002 |
|
3 |
64-bit compilation mode. Function FindMinPath32 |
0.93 |
|
4 |
64-bit compilation mode. Function FindMinPath64 |
0.85 |
Table 2. Execution time of the FindMinPath32 and FindMinPath64 functions.
Table 2 shows the time relative to the FindMinPath32 function's execution speed in a 32-bit system. This is made for more clearness.
In the first line the work time of FindMinPath32 function in a 32-bit system is 1. It is because we take its work time for a unit of measure.
In the second line we see that FindMinPath64 function's work time in a 32-bit system is 1 too. This is not surprising because unsigned type coincides with size_t type in a 32-bit system and there is no difference between FindMinPath32 and FindMinPath64 functions. Some deviation (1.002) means only a little time calculation error.
In the third line we see 7% productivity increase. This is an expected result of the code recompilation for a 64-bit system.
The fourth line is the most interesting. Productivity increase is 15% here. This means that the simple use of the size_t type instead of unsigned allows the compiler to construct more efficient code working 8% faster!
It is a simple and clear example of how the use of data not equal to the computer word's size decreases the algorithms productivity. Simple replacement of the int and unsigned types with ptrdiff_t and size_t may give a great productivity increase. First of all this concerns usage of these data types for indexing arrays, pointer arithmetic and organization of loops.
We hope that having read all said above you will think if you should continue to write:
for (int i = 0; i !=n; i++)
array[i] = 0.0;Developers of Windows applications may take into consideration the Viva64 static code analyzer [8] to automate the errors search in 64-bit code. Firstly, its usage will help to find most errors. Secondly, while developing programs under its control you will use 32-bit variables more seldom, avoid mixed arithmetic with 32-bit and 64-bit data types that will at once increase productivity of your code. Developers of Unix application should take a look at the Gimpel Software PC-Lint [13] and Parasoft C++test [14] static analyzers. They can diagnose some 64-bit errors in the code with LP64 data model, which is used in most Unix-systems.
To learn more about the problems of developing quality and efficient 64-bit code you may read the following articles: "Problems of testing 64-bit applications" [15], "24 Considerations for Moving Your Application to a 64-bit Platform", "Porting and Optimizing Multimedia Codecs for AMD64 architecture on Microsoft Windows" [16], "Porting and Optimizing Applications on 64-bit Windows for AMD64 Architecture" [17].
In the last part of this article we'd like to touch upon some more technologies, which may be useful for you while developing resource-intensive program solutions.
Intrinsic functions are special system-dependent functions, which execute actions impossible to be executed on the level of C/C++ code or which execute these actions much more efficiently. As the matter of fact they allow you to avoid using inline assembler because it is often impossible or undesirable.
Programs may use intrinsic functions for creating faster code due to the absence of overhead costs on the call of a usual function. In this case, of course, the code's size will be a bit larger. The list of functions which may be replaced with their intrinsic versions is given in the MSDN Library. For example, these functions are memcpy, strcmp, etc.
There is a special option, "/Oi" in Microsoft Visual C++ compiler. This option allows you to replace calls of some functions with intrinsic analogs automatically.
Besides automatic replacement of functions with their intrinsic analogs we can explicitly use intrinsic functions in code. This feature may be used due to the following reasons:
Nowadays data alignment doesn't affect the code productivity so greatly as it did 10 years ago. But sometimes you can get a little profit in this sphere too, saving some memory and productivity.
Let's take a look at an example:
struct foo_original {int a; void *b; int c; };This structure occupies 12 bytes in 32-bit mode but in 64-bit mode it takes 24 bytes. In order to make this structure take prescribed 16 bytes in 64-bit mode you should change the order of fields:
struct foo_new { void *b; int a; int c; };In some cases it is useful to help the compiler explicitly by defining the alignment manually in order to increase productivity. For example, SSE data should be aligned at the border of 16 bytes. You can do this in the following way:
// 16-byte aligned data
__declspec(align(16)) double init_val [3.14, 3.14];
// SSE2 movapd instruction
_m128d vector_var = __mm_load_pd(init_val);The "Porting and Optimizing Multimedia Codecs for AMD64 architecture on Microsoft Windows" [16] and "Porting and Optimizing Applications on 64-bit Windows for AMD64 Architecture" [17] sources contain detailed review of these problems.
With the appearance of 64-bit systems the technology of mapping files into memory became more attractive because the data access window increased its size. It may be a very good addition for some applications. Don't forget about it.
Memory mapping of files is becoming less useful with 32-bit architectures, especially with the introduction of relatively cheap recordable DVD technology. A 4 Gb file is no longer uncommon, and such large files cannot be memory mapped easily on 32-bit architectures. Only a region of the file can be mapped into memory and such regions will have to be mapped into and out of memory in order to access such a file via memory mapping. On 64-bit versions of Windows you have much larger address space, so you may map the entire file at once.
One of the most serious problems for a compiler is aliasing. When a program source code contains memory read/write operations it is often impossible to find out whether more than one identifier refers to a certain memory space, i.e. whether more than one identifier can be a "synonym" for one and the same memory space. That's why the compiler should be very careful inside a loop in which memory is both read and written while storing data in registers and not in memory. This insufficient usage of registers may influence the performance greatly.
The __restrict keyword is used to make it easier for the compiler to make a decision. It "tells" the compiler to use registers widely.
The __restrict keyword makes the compiler not to consider the marked pointers to be aliased, i.e. referring to the same memory area. In this case the compiler can provide more efficient optimization. Let's take a look at the following example:
int * __restrict a;
int *b, *c;
for (int i = 0; i < 100; i++)
{
*a += *b++ - *c++ ; // no aliases exist
}In this code the compiler can safely keep the sum in the register related to variable "a" avoiding writing into memory. MSDN Library is a good source of information about the __restrict keyword.
Applications executed on 64-bit processors (regardless of the mode) will work more efficiently if the SSE instructions are used in them instead of MMX/3DNow. This behavior is related to the capacity of processed data. SSE/SSE2 instructions operate with 128-bit data, while MMX/3DNow work only with 64-bit data. That's why it is better to rewrite the code which uses MMX/3DNow so that it will use SSE instructions.
We won't dwell upon SSE-constructions in this article. The readers who may be interested in this topic can read the documentation written by processor architecture developers.
64-bit architecture gives new opportunities for optimizing a programming language on the level of separate operators. These are the methods (which have become traditional already) of "rewriting" pieces of a program to make the compiler optimize them better. Of course, we cannot recommend these methods for mass usage but it may be useful to learn about them.
On the first place of the entire list of these optimizations is manual unrolling of loops. The idea of this method is shown in the example:
double a[100], sum, sum1, sum2, sum3, sum4;
sum = sum1 = sum2 = sum3 = sum4 = 0.0;
for (int i = 0; i < 100; I += 4)
{
sum1 += a[i];
sum2 += a[i+1];
sum3 += a[i+2];
sum4 += a[i+3];
}
sum = sum1 + sum2 + sum3 + sum4;In many cases the compiler can unroll the loop to this form (see the description of the /fp:fast key for Visual C++) but not always.
Another syntax optimization is the use of array notation instead of pointer one.
A lot of such methods are described in the "Software Optimization Guide for AMD64 Processors" article [10].
Though you'll have to face many difficulties while creating program systems using hardware abilities of modern computers efficiently, it is worthwhile. Parallel 64-bit systems provide new possibilities for developing real, scalable solutions. They allow to expand the abilities of modern data processing software tools, such as games, CAD-systems or pattern recognition. We wish you good luck in creating new technologies!
0
0
0
0