
Our website uses cookies to enhance your browsing experience.

Somehow, it so happens that we write about our diagnostics, but barely touch upon the subject of how we enhance the analyzer's internal mechanics. So, for a change, today we'll talk about a new useful upgrade for our data flow analysis.

A few days ago I saw a post from JetBrains about new features offered by CLion's built-in static analyzer.
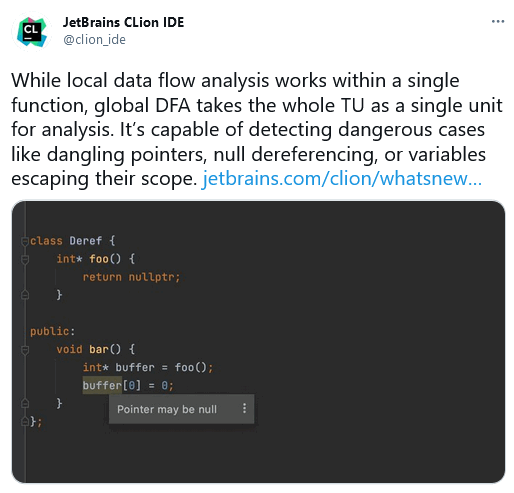
Since we are soon planning to release the PVS-Studio plugin for CLion, I could not just ignore their announcement! I had to point out that PVS-Studio is also powerful. And that the PVS-Studio plugin for CLion can find even more mistakes.
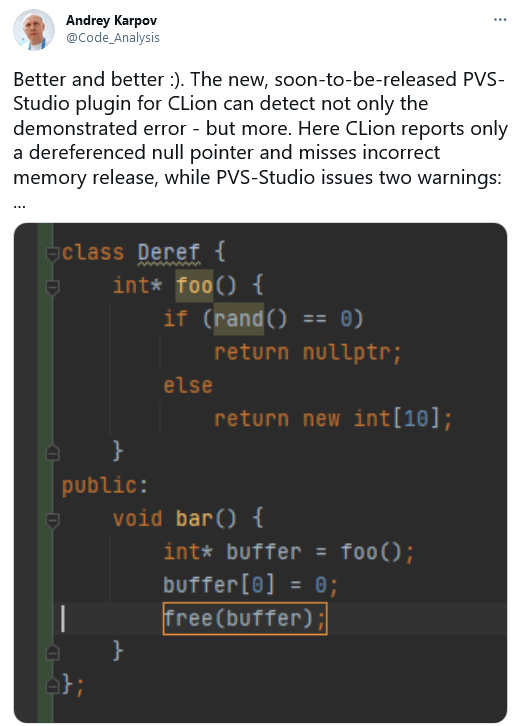
So I had a nice little chat with JetBrains:
I pondered this all for a little bit. Very nice! They enhanced their data flow analysis and told the world about it. We are no worse! We're always enhancing the analyzer's engine - including that very data flow analysis mechanics. So here I am, writing this note.
One of our clients described an error that PVS-Studio unfortunately failed to find. A couple of days ago we upgraded the analyzer so that it can find this error. Sometimes, in case of an overflow, the analyzer got confused with unsigned variable values. The code that caused the problem looked something like this:
bool foo()
{
unsigned N = 2;
for (unsigned i = 0; i < N; ++i)
{
bool stop = (i - 1 == N);
if (stop)
return true;
}
return false;
}The analyzer could not understand that the stop variable was always assigned the false value.
Why false? Let's do a quick calculation:
Note. There is no undefined behavior here, because numbers are overflown (wrapped) when you work with an unsigned type.
Now we have taught PVS-Studio to process these expressions correctly and to issue an appropriate warning. Interestingly, this change led to other improvements.
For example, the initial change caused false positives related to string length processing. While fighting them, we introduced more enhancements and taught the analyzer about functions like strlen - how and why they are used. Now I'll go ahead and show you the analyzer's new abilities.
There is an open-source project test base that we use for our core's regression testing. The project test base contains the FCEUX emulator. The upgraded analyzer found an interesting error in the Assemble function.
int Assemble(unsigned char *output, int addr, char *str) {
output[0] = output[1] = output[2] = 0;
char astr[128],ins[4];
if ((!strlen(str)) || (strlen(str) > 0x127)) return 1;
strcpy(astr,str);
....
}Can you see it? To be honest, we did not notice it immediately and our first thought was, "Oh no, we broke something!" Then we saw what was up and took a minute to appreciate the advantages of static analysis.
PVS-Studio warned: V512 A call of the 'strcpy' function will lead to overflow of the buffer 'astr'. asm.cpp 21
Still don't see the error? Let's go through the code step by step. To start with, we'll remove everything irrelevant:
int Assemble(char *str) {
char astr[128];
if ((!strlen(str)) || (strlen(str) > 0x127)) return 1;
strcpy(astr,str);
....
}The code above declares a 128-byte array. The plan is to verify a string and then pass it to the strcpy function that copies the string to the array. The string should not be copied if it is empty or contains over 127 characters (not counting the terminal zero).
So far, all is well and good, right? Wait, wait, wait. What do we see here? What kind of a constant is 0x127?!
It's not 127 at all. Far from it!
This constant is set in hexadecimal notation. If you convert it to decimal, you get 295.
So, the code above is equivalent to the following:
int Assemble(char *str) {
char astr[128];
if ((!strlen(str)) || (strlen(str) > 295)) return 1;
strcpy(astr,str);
....
}As you can see, the str string check does not prevent possible buffer overflows. The analyzer correctly warns you about the problem.
Previously, the analyzer could not find the error. The analyzer could not understand that both strlen function calls work with the same string. And the string does not change between them. Although things like this one are obvious to developers, this is not the case for the analyzer. It needs to be taught expressly.
Now PVS-Studio warns that the str string length is in the [1..295] range, and thus may exceed the array bounds if copied to the astr buffer.

The error above also exists in the FCEUX project's current code base. But we will not find it, because now the string's length is written to a variable. This breaks the connection between the string and its length. For now, the analyzer is oblivious to this error in the code's new version:
int Assemble(unsigned char *output, int addr, char *str) {
output[0] = output[1] = output[2] = 0;
char astr[128],ins[4];
int len = strlen(str);
if ((!len) || (len > 0x127)) return 1;
strcpy(astr,str);
....
}This code is easy for a human to understand. The static analyzer, however, has a difficult time tracking values here. It needs to know that the len variable represents the str string's length. Additionally, it needs to carefully track when this connection breaks. This happens when the len variable or the string contents are modified.
So far, PVS-Studio does not know how to track these values. On the bright side, now here's one more direction to grow and develop! Over time, the analyzer will learn to find the error in this new code as well.
By the way, the reader may wonder why we analyze projects' old code and do not upgrade the test projects regularly. It's simple, really. If we update the test projects, we won't be able to perform regression testing. It will be unclear what caused the analyzer to behave differently - the analyzer's or the test projects' code changes. This is why we do not update open-source projects we use for testing.
Of course, we need to test the analyzer on modern code written in C++14, C++17 etc. To do this, we add new projects to the database. For example, one of our recent additions was a header-only C++ library collection (awesome-hpp).
It's always interesting and useful to enhance data flow analysis mechanisms. Do you think so too? Do you want to know more about how static code analysis tools work? Then we recommend you read the following articles:
On a final note, I invite you to download the PVS-Studio analyzer and check your projects.
0
0
0
0