
Our website uses cookies to enhance your browsing experience.

Combining many actions in a single C++ expression is a bad practice, as such code is hard to understand, maintain, and it is easy to make mistakes in it. For example, one can instill a bug by reconciling different actions when evaluating function arguments. We agree with the classic recommendation that code should be simple and clear. Now let's look at an interesting case where the PVS-Studio analyzer is technically wrong, but from a practical point of view, the code should still be changed.
What I'm going to tell you about is a continuation of the old story about the order of argument evaluation, which we wrote about in the article "How deep the rabbit hole goes, or C++ Job interviews at PVS-Studio".
The brief gist is as follows. The order in which function arguments are evaluated is unspecified behavior. The standard does not specify the order in which developers of compilers are required to calculate arguments. For example, from left to right (Clang) or from right to left (GCC, MSVC). Before the C++17 standard, if side effects occurred when evaluating arguments, this could lead to undefined behavior.
With the advent of the C++17 standard, the situation has changed for the better. Now the evaluation of an argument and its side effects will only be performed after all the evaluations and side effects of the previous argument are performed. However, this does not mean that there is no room for errors now.
Let's look at a simple test program:
#include <cstdio>
int main()
{
int i = 1;
printf("%d, %d\n", i, i++);
return 0;
}What will this code print? The answer still depends on the compiler, its version, and its mood. Depending on the compiler, either "1, 1" or "2, 1"can be printed. Indeed, using the Compiler Explorer I will get the following results:
There is no undefined behavior in this program, but there is unspecified behavior (the order in which arguments are evaluated).
Let's go back to the code fragment from the CSV Parser project that I mentioned in the article "Checking a header-only C++ library collection (awesome-hpp)".
The analyzer and I, we know that arguments can be evaluated in different order. Therefore, the analyzer, and so did I considered this code to be erroneous:
std::unique_ptr<char[]> buffer(new char[BUFFER_UPPER_LIMIT]);
....
this->feed_state->feed_buffer.push_back(
std::make_pair<>(std::move(buffer), line_buffer - buffer.get()));PVS-Studio warning: V769 The 'buffer.get()' pointer in the 'line_buffer - buffer.get()' expression equals nullptr. The resulting value is senseless and it should not be used. csv.hpp 4957
In fact, we are both wrong, and there is no error. I'll tell about nuances further, let's start with a simple question.
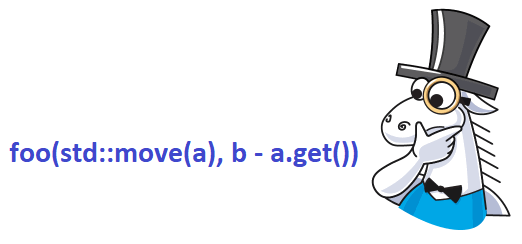
Let's find out why it's dangerous to write code like this:
Foo(std::move(buffer), line_buffer - buffer.get());I think you can guess the answer. The result depends on the order in which the arguments are evaluated. Let's look at this in the following synthetic code:
#include <iostream>
#include <memory>
void Print(std::unique_ptr<char[]> p, ptrdiff_t diff)
{
std::cout << diff << std::endl;
}
void Print2(ptrdiff_t diff, std::unique_ptr<char[]> p)
{
std::cout << diff << std::endl;
}
int main()
{
{
std::unique_ptr<char[]> buffer(new char[100]);
char *ptr = buffer.get() + 22;
Print(std::move(buffer), ptr - buffer.get());
}
{
std::unique_ptr<char[]> buffer(new char[100]);
char *ptr = buffer.get() + 22;
Print2(ptr - buffer.get(), std::move(buffer));
}
return 0;
}Let's use the Compiler Explorer again and see the result of this program compiled by different compilers.
Clang 11.0.0 Compiler. Result:
23387846
22GCC 10.2 compiler. Result:
22
26640070The result is as expected. But one just can't write like this. This is what the PVS-Studio analyzer warns us about.
I wish I could put an end to this, but everything is a little more complicated. The fact is that we are talking about passing arguments by value, whereas when instantiating the template of the std::make_pair function, everything will be different. So, we will continue to dive into the subtleties and find out why PVS-Studio is wrong in this case.
Let's refer to the cppreference site and see how the template for the std::make_pair function was changing.
Until C++11:
template< class T1, class T2 >
std::pair<T1,T2> make_pair( T1 t, T2 u );
Since C++11, until C++14:
template< class T1, class T2 >
std::pair<V1,V2> make_pair( T1&& t, T2&& u );
Since C++14:
template< class T1, class T2 >
constexpr std::pair<V1,V2> make_pair( T1&& t, T2&& u );
As you can see, once upon a time std::make_pair was taking arguments by value. If std::unique_ptr had existed at that time, then the code above would have been indeed incorrect. Whether this code would work or not would be a matter of luck. In practice, of course, this situation would never have occurred, since std::unique_ptr appeared in C++11 as a replacement for std::auto_ptr.
Let's go back to our time. Starting with C++11, the constructor started to use move semantics.
There is a subtle point here that std::move does not actually move anything, but only converts the object to an rvalue reference. This allows std::make_pair to pass a pointer to the new std::unique_ptr, leaving nullptr in the original smart pointer. But passing of this pointer won't happen until we get inside std::make_pair. By then, we will have evaluated line_buffer - buffer.get(), and everything will be fine. In other words, a call to the buffer.get() function can't return nullptr at the moment it is evaluated, regardless of when exactly this happens.
I apologize for the complicated description. The bottom line is that this code is quite correct. And in fact, the PVS-Studio static analyzer gave a false positive in this case. However, our team is not sure if we should rush to make changes to the analyzer's logic for such situations.
We found out that the warning described in the article was false. Thanks to one of our readers who drew our attention to the implementation of std::make_pair.
However, this is the case when we are not sure that we should improve the behavior of the analyzer. The fact is that this code is too confusing. You have to admit that the code above does not deserve such a detailed investigation resulting in the entire article. If this code requires so much attention, it is janky code.
It is fitting here to recall the article "False positives are our enemies, but may still be your friends". The post is not ours, but we agree with it.
This is probably the case. The warning may be false, but it points to a better place to refactor. The author can just write something like this:
auto delta = line_buffer - buffer.get();
this->feed_state->feed_buffer.push_back(
std::make_pair(std::move(buffer), delta));In this case, one can make the code even better by using the emplace_back method:
auto delta = line_buffer - buffer.get();
this->feed_state->feed_buffer.emplace_back(std::move(buffer), delta);Such code creates the final std::pair object in the container "in place", bypassing creating a temporary object and moving it to the container. By the way, the PVS-Studio analyzer offers to make such a replacement by issuing the V823 warning from the set of rules for code micro-optimizations.
The code will definitely become easier and clearer for any reader and analyzer. There is no merit in putting as many actions as possible in one line of code.
Well, in this case there is no error due to pure chance. Still it is unlikely that the author kept in mind all that we discussed when writing this code. Most likely, it was luck that played its part. And other times one might not be that lucky.
So, we figured out that there is no real error. The analyzer issues a false positive. We may or may not remove the warning for such cases. We'll think over it. After all, this is a fairly rare case. The code where arguments are evaluated with side effects is generally dangerous, and it is better not to allow it. It is worth refactoring at least for preventive purposes.
The code as the following:
Foo(std::move(buffer), line_buffer - buffer.get());can be easily crashed by changing something else in the program. This code is hard to maintain. It is also nasty because it may give you the false impression that everything is working correctly. In fact, this is just a set of circumstances, and everything can crash when changing a compiler or optimization settings.
Write simple code!
0
0
0
0