
Our website uses cookies to enhance your browsing experience.

One of the main problems with C++ is having a huge number of constructions whose behavior is undefined, or is just unexpected for a programmer. We often come across them when using our static analyzer on various projects. But, as we all know, the best thing is to detect errors at the compilation stage. Let's see which techniques in modern C++ help writing not only simple and clear code, but make it safer and more reliable.


The term Modern C++ became very popular after the release of C++11. What does it mean? First of all, Modern C++ is a set of patterns and idioms that are designed to eliminate the downsides of good old "C with classes", that so many C++ programmers are used to, especially if they started programming in C. C++11 looks way more concise and understandable, which is very important.
What do people usually think of when they speak about Modern C++? Parallelism, compile-time calculation, RAII, lambdas, ranges, concepts, modules, and other equally important components of the standard library (for example, an API to work with the file system). These are all very cool modernizations, and we are looking forward to seeing them in the next set of standards. However, I would like to draw attention to the way the new standards allow writing more secure code. When developing a static analyzer, we see a great number of varying errors, and sometimes we cannot help thinking: "But in modern C++ this could have been avoided". Therefore, I suggest we examine several errors that were found by PVS-Studio in various Open Source projects. Also, we'll see how they can be fixed.

In C++, the keywords auto and decltype were added. Of course, you already know how they work.
std::map<int, int> m;
auto it = m.find(42);
//C++98: std::map<int, int>::iterator it = m.find(42);It's very convenient to shorten long types, without losing the readability of the code. However, these keywords become quite expansive, together with templates: there is no need to specify the type of the returning value with auto and decltype.
But let's go back to our topic. Here is an example of a 64-bit error:
string str = .....;
unsigned n = str.find("ABC");
if (n != string::npos)In a 64-bit application, the value of string::npos is greater than the maximum value of UINT_MAX, which can be represented by a variable of unsigned type. It could seem that this is a case where auto can save us from this kind of problem: the type of the n variable isn't important to us, the main thing is that it can accommodate all possible values of string::find. And indeed, if we rewrite this example with auto, the error is gone:
string str = .....;
auto n = str.find("ABC");
if (n != string::npos)But not everything is as simple. Using auto is not a panacea, and there are many pitfalls related to its use. For example, you can write the code like this:
auto n = 1024 * 1024 * 1024 * 5;
char* buf = new char[n];Auto won't save us from the integer overflow and there will be less memory allocated for the buffer than 5GiB.
Auto also isn't of any great help when it comes to a very common error: an incorrectly written loop. Let's look at an example:
std::vector<int> bigVector;
for (unsigned i = 0; i < bigVector.size(); ++i)
{ ... }For large size arrays, this loop becomes an infinity loop. It's no surprise that there are such errors in the code: they reveal themselves in very rare cases, for which there were no tests.
Can we rewrite this fragment with auto?
std::vector<int> bigVector;
for (auto i = 0; i < bigVector.size(); ++i)
{ ... }No. Not only is the error is still here. It has become even worse.
With simple types auto behaves very badly. Yes, in the simplest cases (auto x = y) it works, but as soon as there are additional constructions, the behavior can become more unpredictable. What's worse, the error will be more difficult to notice, because the types of variables aren't that obvious at first glance. Fortunately it is not a problem for static analyzers: they don't get tired, and don't lose attention. But for us, as simple mortals it's better to specify the types explicitly. We can also get rid of the narrowing casting using other methods, but we'll speak about that later.
One of the "dangerous" types in C++ is an array. Often when passing it to the function, programmers forget that it is passed as a pointer, and try to calculate the number of elements with sizeof.
#define RTL_NUMBER_OF_V1(A) (sizeof(A)/sizeof((A)[0]))
#define _ARRAYSIZE(A) RTL_NUMBER_OF_V1(A)
int GetAllNeighbors( const CCoreDispInfo *pDisp,
int iNeighbors[512] ) {
....
if ( nNeighbors < _ARRAYSIZE( iNeighbors ) )
iNeighbors[nNeighbors++] = pCorner->m_Neighbors[i];
....
}Note: This code is taken from the Source Engine SDK.
PVS-Studio warning: V511 The sizeof() operator returns size of the pointer, and not of the array, in 'sizeof (iNeighbors)' expression. Vrad_dll disp_vrad.cpp 60
Such confusion can arise because of specifying the size of an array in the argument: this number means nothing to the compiler, and is just a hint to the programmer.
The trouble is that this code gets compiled, and the programmer is unaware that something is not right. The obvious solution would be to use metaprogramming:
template < class T, size_t N >
constexpr size_t countof( const T (&array)[N] ) {
return N;
}
countof(iNeighbors); //compile-time errorIf we pass to this function, not an array, we get a compilation error. In C ++17 you can use std::size.
In C++11, the function std::extent was added, but it isn't suitable as countof, because it returns 0 for inappropriate types.

std::extent<decltype(iNeighbors)>(); //=> 0You can make an error not only with countof, but with sizeof as well.
VisitedLinkMaster::TableBuilder::TableBuilder(
VisitedLinkMaster* master,
const uint8 salt[LINK_SALT_LENGTH])
: master_(master),
success_(true) {
fingerprints_.reserve(4096);
memcpy(salt_, salt, sizeof(salt));
}Note: This code is taken from Chromium.
PVS-Studio warnings:
As you can see, the standard C++ arrays have a lot of problems. This is why you should use std::array: in the modern C++ its API is similar to std::vector and other containers, and it's harder to make an error when using it.
void Foo(std::array<uint8, 16> array)
{
array.size(); //=> 16
}One more source of errors is a simple for loop. You may think, "Where can you make a mistake there? Is it something connected with the complex exit condition or saving on the lines of code?" No, programmers make error in the simplest loops. Let's take a look at the fragments from the projects:
const int SerialWindow::kBaudrates[] = { 50, 75, 110, .... };
SerialWindow::SerialWindow() : ....
{
....
for(int i = sizeof(kBaudrates) / sizeof(char*); --i >= 0;)
{
message->AddInt32("baudrate", kBaudrateConstants[i]);
....
}
}Note: This code is taken from Haiku Operation System.
PVS-Studio warning: V706 Suspicious division: sizeof (kBaudrates) / sizeof (char *). Size of every element in 'kBaudrates' array does not equal to divisor. SerialWindow.cpp 162
We have examined such errors in detail in the previous chapter: the array size wasn't evaluated correctly again. We can easily fix it by using std::size:
const int SerialWindow::kBaudrates[] = { 50, 75, 110, .... };
SerialWindow::SerialWindow() : ....
{
....
for(int i = std::size(kBaudrates); --i >= 0;) {
message->AddInt32("baudrate", kBaudrateConstants[i]);
....
}
}But there is a better way. Let's take a look at one more fragment.
inline void CXmlReader::CXmlInputStream::UnsafePutCharsBack(
const TCHAR* pChars, size_t nNumChars)
{
if (nNumChars > 0)
{
for (size_t nCharPos = nNumChars - 1;
nCharPos >= 0;
--nCharPos)
UnsafePutCharBack(pChars[nCharPos]);
}
}Note: This code is taken from Shareaza.
PVS-Studio warning: V547 Expression 'nCharPos >= 0' is always true. Unsigned type value is always >= 0. BugTrap xmlreader.h 946
It's a typical error when writing a reverse loop: the programmer forgot that the iterator of an unsigned type and the check always return true. You might think, "How come? Only novices and students make such mistakes. We, professionals, don't." Unfortunately, this is not completely true. Of course, everyone understands that (unsigned >= 0) - true. Where do such errors come from? They often occur as a result of refactoring. Imagine this situation: the project migrates from the 32-bit platform to 64-bit. Previously, int/unsigned was used for indexing and a decision was made to replace them with size_t/ptrdiff_t. But in one fragment they accidentally used an unsigned type instead of a signed one.
What shall we do to avoid this situation in your code? Some people advise the use of signed types, as in C# or Qt. Perhaps, it could be a way out, but if we want to work with large amounts of data, then there is no way to avoid size_t. Is there any more secure way to iterate through array in C++? Of course there is. Let's start with the simplest one: non-member functions. There are standard functions to work with collections, arrays and initializer_list; their principle should be familiar to you.
char buf[4] = { 'a', 'b', 'c', 'd' };
for (auto it = rbegin(buf);
it != rend(buf);
++it) {
std::cout << *it;
}Great, now we do not need to remember the difference between a direct and reverse cycle. There is also no need to think about whether we use a simple array or an array - the loop will work in any case. Using iterators is a great way to avoid headaches, but even that is not always good enough. It is best to use the range-based for loop:
char buf[4] = { 'a', 'b', 'c', 'd' };
for (auto it : buf) {
std::cout << it;
}Of course, there are some flaws in the range-based for: it doesn't allow flexible management of the loop, and if there is more complex work with indexes required, then for won't be of much help to us. But such situations should be examined separately. We have quite a simple situation: we have to move along the items in the reverse order. However, at this stage, there are already difficulties. There are no additional classes in the standard library for range-based for. Let's see how it could be implemented:
template <typename T>
struct reversed_wrapper {
const T& _v;
reversed_wrapper (const T& v) : _v(v) {}
auto begin() -> decltype(rbegin(_v))
{
return rbegin(_v);
}
auto end() -> decltype(rend(_v))
{
return rend(_v);
}
};
template <typename T>
reversed_wrapper<T> reversed(const T& v)
{
return reversed_wrapper<T>(v);
}In C++14 you can simplify the code by removing the decltype. You can see how auto helps you write template functions - reversed_wrapper will work both with an array, and std::vector.
Now we can rewrite the fragment as follows:
char buf[4] = { 'a', 'b', 'c', 'd' };
for (auto it : reversed(buf)) {
std::cout << it;
}What's great about this code? Firstly, it is very easy to read. We immediately see that the array of the elements is in the reverse order. Secondly, it's harder to make an error. And thirdly, it works with any type. This is much better than what it was.
You can use boost::adaptors::reverse(arr) in boost.
But let's go back to the original example. There, the array is passed by a pair pointer-size. It is obvious that our idea with reversed will not work for it. What shall we do? Use classes like span/array_view. In C++17 we have string_view, and I suggest using that:
void Foo(std::string_view s);
std::string str = "abc";
Foo(std::string_view("abc", 3));
Foo("abc");
Foo(str);string_view does not own the string, in fact it's a wrapper around the const char* and the length. That's why in the code example, the string is passed by value, not by the reference. A key feature of the string_view is compatibility with strings in various string presentations: const char*, std::string and non-null terminated const char*.
As a result, the function takes the following form:
inline void CXmlReader::CXmlInputStream::UnsafePutCharsBack(
std::wstring_view chars)
{
for (wchar_t ch : reversed(chars))
UnsafePutCharBack(ch);
}Passing to the function, it's important to remember that the constructor string_view(const char*) is implicit, that's why we can write like this:
Foo(pChars);Not this way:
Foo(wstring_view(pChars, nNumChars));A string that the string_view points to, does not need to be null- terminated, the very name string_view::data gives us a hint about this, and it is necessary to keep that in mind when using it. When passing its value to a function from cstdlib, which is waiting for a C string, you can get undefined behavior. You can easily miss it, if in most cases that you are testing, there is std::string or null-terminated strings used.
Let's leave C++ for a second and think about good old C. How is security there? After all, there are no problems with implicit constructor calls and operators, or type conversion, and there are no problems with various types of the strings. In practice, errors often occur in the simplest constructions: the most complicated ones are thoroughly reviewed and debugged, because they cause some doubts. At the same time programmers forget to check simple constructions. Here is an example of a dangerous structure, which came to us from C:
enum iscsi_param {
....
ISCSI_PARAM_CONN_PORT,
ISCSI_PARAM_CONN_ADDRESS,
....
};
enum iscsi_host_param {
....
ISCSI_HOST_PARAM_IPADDRESS,
....
};
int iscsi_conn_get_addr_param(....,
enum iscsi_param param, ....)
{
....
switch (param) {
case ISCSI_PARAM_CONN_ADDRESS:
case ISCSI_HOST_PARAM_IPADDRESS:
....
}
return len;
}An example of the Linux kernel. PVS-Studio warning: V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B: ... }. libiscsi.c 3501
Pay attention to the values in the switch-case: one of the named constants is taken from a different enumeration. In the original, of course, there is much more code and more possible values and the error isn't so obvious. The reason for that is lax typing of enum - they may be implicitly casting to int, and this leaves a lot of room for errors.
In C++11 you can, and should, use enum class: such a trick won't work there, and the error will show up at the compilation stage. As a result, the following code does not compile, which is exactly what we need:
enum class ISCSI_PARAM {
....
CONN_PORT,
CONN_ADDRESS,
....
};
enum class ISCSI_HOST {
....
PARAM_IPADDRESS,
....
};
int iscsi_conn_get_addr_param(....,
ISCSI_PARAM param, ....)
{
....
switch (param) {
case ISCSI_PARAM::CONN_ADDRESS:
case ISCSI_HOST::PARAM_IPADDRESS:
....
}
return len;
}The following fragment is not quite connected with the enum, but has similar symptoms:
void adns__querysend_tcp(....) {
...
if (!(errno == EAGAIN || EWOULDBLOCK ||
errno == EINTR || errno == ENOSPC ||
errno == ENOBUFS || errno == ENOMEM)) {
...
}Note: This code is taken from ReactOS.
Yes, the values of errno are declared as macros, which is bad practice in C++ (in C as well), but even if the programmer used enum, it wouldn't make life easier. The lost comparison will not reveal itself in case of enum (and especially in case of a macro). At the same time enum class would not allow this, as there will were no implicit casting to bool.
But back to the native C++ problems. One of them reveals when there is a need to initialize the object in the same way in several constructors. A simple situation: there is a class, two constructors, one of them calls another. It all looks pretty logical: the common code is put into a separate method - nobody likes to duplicate the code. What's the pitfall?
Guess::Guess() {
language_str = DEFAULT_LANGUAGE;
country_str = DEFAULT_COUNTRY;
encoding_str = DEFAULT_ENCODING;
}
Guess::Guess(const char * guess_str) {
Guess();
....
}Note: This code is taken from LibreOffice.
PVS-Studio warning: V603 The object was created but it is not being used. If you wish to call constructor, 'this->Guess::Guess(....)' should be used. guess.cxx 56
The pitfall is in the syntax of the constructor call. Quite often it gets forgotten, and the programmer creates one more class instance, which then gets immediately destroyed. That is, the initialization of the original instance isn't happening. Of course, there are 1001 ways to fix this. For example, we can explicitly call the constructor via this, or put everything into a separate function:
Guess::Guess(const char * guess_str)
{
this->Guess();
....
}
Guess::Guess(const char * guess_str)
{
Init();
....
}By the way, an explicit repeated call of the constructor, for example, via this is a dangerous game, and we need to understand what's going on. The variant with the Init() is much better and clearer. For those who want to understand the details of these "pitfalls" better, I suggest looking at chapter 19, "How to properly call one constructor from another", from this book.
But it is best to use the delegation of the constructors here. So we can explicitly call one constructor from another in the following way:
Guess::Guess(const char * guess_str) : Guess()
{
....
}Such constructors have several limitations. First: delegated constructors take full responsibility for the initialization of an object. That is, it won't be possible to initialize another class field with it in the initialization list:
Guess::Guess(const char * guess_str)
: Guess(),
m_member(42)
{
....
}And of course, we have to make sure that the delegation doesn't create a loop, as it will be impossible to exit it. Unfortunately, this code gets compiled:

Guess::Guess(const char * guess_str)
: Guess(std::string(guess_str))
{
....
}
Guess::Guess(std::string guess_str)
: Guess(guess_str.c_str())
{
....
}Virtual functions hinder a potential problem: the thing is that it's very simple to make an error in signature of the derived class and as result not to override a function, but to declare a new one. Let's take a look at this situation in the following example:
class Base {
virtual void Foo(int x);
}
class Derived : public class Base {
void Foo(int x, int a = 1);
}The method Derived::Foo isn't possible to call by the pointer/reference to Base. But this is a simple example, and you may say that nobody makes such mistakes. Usually people make mistakes in the following way:
Note: This code is taken from MongoDB.
class DBClientBase : .... {
public:
virtual auto_ptr<DBClientCursor> query(
const string &ns,
Query query,
int nToReturn = 0
int nToSkip = 0,
const BSONObj *fieldsToReturn = 0,
int queryOptions = 0,
int batchSize = 0 );
};
class DBDirectClient : public DBClientBase {
public:
virtual auto_ptr<DBClientCursor> query(
const string &ns,
Query query,
int nToReturn = 0,
int nToSkip = 0,
const BSONObj *fieldsToReturn = 0,
int queryOptions = 0);
};PVS-Studio warning: V762 Consider inspecting virtual function arguments. See seventh argument of function 'query' in derived class 'DBDirectClient', and base class 'DBClientBase'. dbdirectclient.cpp 61
There are a lot of arguments and there is no last argument in the function of heir-class. These are different, unconnected functions. Quite often such an error occurs with arguments that have a default value.
In the next fragment the situation is a bit more tricky. This code will work if it's compiled as 32-bit code, but will not work in the 64-bit version. Originally, in the base class, the parameter was of DWORD type, but then it was corrected to DWORD_PTR. At the same time it wasn't changed in the inherited classes. Long live the sleepless night, debugging, and coffee!
class CWnd : public CCmdTarget {
....
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd = HELP_CONTEXT);
....
};
class CFrameWnd : public CWnd { .... };
class CFrameWndEx : public CFrameWnd {
....
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);
....
};You can make a mistake in the signature in more extravagant ways. You can forget const of the function, or an argument. You can forget that the function in a base class is not virtual. You can confuse a signed/unsigned type.
In C++ several keywords were added that can regulate overriding of virtual functions. Override will be of great help. This code simply won't compile.
class DBDirectClient : public DBClientBase {
public:
virtual auto_ptr<DBClientCursor> query(
const string &ns,
Query query,
int nToReturn = 0,
int nToSkip = 0,
const BSONObj *fieldsToReturn = 0,
int queryOptions = 0) override;
};Using NULL to indicate a null pointer leads to a number of unexpected situations. The thing is that NULL is a normal macro that expands in 0 which has int type: That's why it's not hard to understand why the second function is chosen in this example:
void Foo(int x, int y, const char *name);
void Foo(int x, int y, int ResourceID);
Foo(1, 2, NULL);Although the reason is clear, it's very illogical. This is why there is a need in nullptr that has its own type nullptr_t. This is why we cannot use NULL (and more so 0) in modern C++.
Another example: NULL can be used to compare with other integer types. Let's suppose that there is some WinAPI function that returns HRESULT. This type is not related to a pointer in any way, so its comparison with NULL is meaningless. And nullptr underlines this by issuing a compilation error, at the same time NULL works:
if (WinApiFoo(a, b) != NULL) // That's bad
if (WinApiFoo(a, b) != nullptr) // Hooray,
// a compilation errorThere are cases where it's necessary to pass an undefined amount of arguments. A typical example - the function of a formatted input/ouput. Yes, it can be written in such a way that a variable number of arguments will not be needed, but I see no reason to abandon this syntax because it is much more convenient and easier to read. What do old C++ standards offer? They suggest using va_list. What problems have we got with that? It's not that easy to pass an argument of the wrong type to such an argument. Or not to pass the argument whatsoever. Let's have a closer look at the fragments.
typedef std::wstring string16;
const base::string16& relaunch_flags() const;
int RelaunchChrome(const DelegateExecuteOperation& operation)
{
AtlTrace("Relaunching [%ls] with flags [%s]\n",
operation.mutex().c_str(),
operation.relaunch_flags());
....
}Note: This code is taken from Chromium.
PVS-Studio warning: V510 The 'AtlTrace' function is not expected to receive class-type variable as third actual argument. delegate_execute.cc 96
The programmer wanted to print the std::wstring string, but forgot to call the method c_str(). So the type wstring will be interpreted in the function as const wchar_t*. Of course, this won't do any good.
cairo_status_t
_cairo_win32_print_gdi_error (const char *context)
{
....
fwprintf (stderr, L"%s: %S", context,
(wchar_t *)lpMsgBuf);
....
}Note: This code is taken from Cairo.
PVS-Studio warning: V576 Incorrect format. Consider checking the third actual argument of the 'fwprintf' function. The pointer to string of wchar_t type symbols is expected. cairo-win32-surface.c 130
In this fragment, the programmer confused the specifiers of the string format. The thing is that in Visual C++ wchar_t*, and %S - char*, are waiting for wprintf %s. It's interesting, that these errors are in strings that are meant for the error output or debug information - surely these are rare cases, that's why they were skipped.
static void GetNameForFile(
const char* baseFileName,
const uint32 fileIdx,
char outputName[512] )
{
assert(baseFileName != NULL);
sprintf( outputName, "%s_%d", baseFileName, fileIdx );
}Note: This code is taken from the CryEngine 3 SDK.
PVS-Studio warning: V576 Incorrect format. Consider checking the fourth actual argument of the 'sprintf' function. The SIGNED integer type argument is expected. igame.h 66
The integer types are also very easy to confuse. Especially when their size is platform-dependent. However, here it's much simpler: the signed and unsigned types were confused. Large numbers will be printed as negative ones.
ReadAndDumpLargeSttb(cb,err)
int cb;
int err;
{
....
printf("\n - %d strings were read, "
"%d were expected (decimal numbers) -\n");
....
}Note: This code is taken from Word for Windows 1.1a.
PVS-Studio warning: V576 Incorrect format. A different number of actual arguments is expected while calling 'printf' function. Expected: 3. Present: 1. dini.c 498
Example found under one of the archaeological researches. This string presupposes three arguments, but they aren't written. Perhaps the programmer intended to print data on the stack, but we can't make assumptions of what is laying there. Certainly, we need to pass these arguments explicitly.
BOOL CALLBACK EnumPickIconResourceProc(
HMODULE hModule, LPCWSTR lpszType,
LPWSTR lpszName, LONG_PTR lParam)
{
....
swprintf(szName, L"%u", lpszName);
....
}Note: This code is taken from ReactOS.
PVS-Studio warning: V576 Incorrect format. Consider checking the third actual argument of the 'swprintf' function. To print the value of pointer the '%p' should be used. dialogs.cpp 66
An example of a 64-bit error. The size of the pointer depends on the architecture, and using %u for it is a bad idea. What shall we use instead? The analyzer gives us a hint that the correct answer is %p. It's great if the pointer is printed for debugging. It would be much more interesting if later there is an attempt to read it from the buffer and use it.
What can be wrong with functions with a variable number of arguments? Almost everything! You cannot check the type of the argument, or the number of arguments. Step left, step right up-undefined behavior.

It is great that there are more reliable alternatives. Firstly, there are variadic templates. With their help, we get all the information about passed types during compilation, and can use it as we want. As an example let's use that very printf, but, a more secure one:
void printf(const char* s) {
std::cout << s;
}
template<typename T, typename... Args>
void printf(const char* s, T value, Args... args) {
while (s && *s) {
if (*s=='%' && *++s!='%') {
std::cout << value;
return printf(++s, args...);
}
std::cout << *s++;
}
}Of course this is just an example: in practice its use is pointless. But in the case of variadic templates, you are limited only by your imagination, not by the language features.
One more construction that can be used as an option to pass a variable number of arguments - std::initializer_list. It does not allow you to pass arguments of different types. But if this is enough, you can use it:
void Foo(std::initializer_list<int> a);
Foo({1, 2, 3, 4, 5});It's also very convenient to traverse it, as we can use begin, end and the range for.
Narrowing casts caused a lot of headache in the programmers' life. Especially when migration to the 64-bit architecture became even more necessary. It's very good if there are only correct types in your code. But it's not all that positive: quite often programmers use various dirty hacks, and some extravagant ways of storing pointers. It took a lot of coffee to find all such fragments:
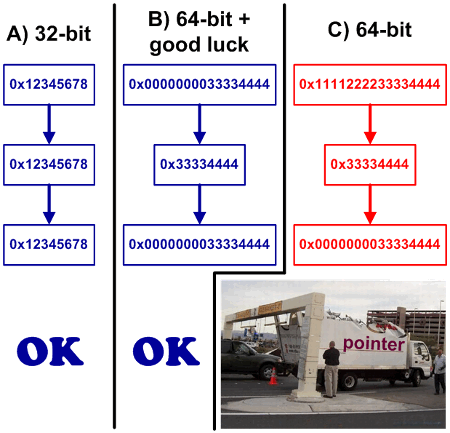
char* ptr = ...;
int n = (int)ptr;
....
ptr = (char*) n;But let's leave the topic of 64-bit errors for a while. Here's a simpler example: there are two integer values and the programmer wants to find their ratio. It is done this way:
virtual int GetMappingWidth( ) = 0;
virtual int GetMappingHeight( ) = 0;
void CDetailObjectSystem::LevelInitPreEntity()
{
....
float flRatio = pMat->GetMappingWidth() /
pMat->GetMappingHeight();
....
}Note: This code is taken from the Source Engine SDK.
PVS-Studio warning: V636 The expression was implicitly cast from 'int' type to 'float' type. Consider utilizing an explicit type cast to avoid the loss of a fractional part. An example: double A = (double)(X) / Y;. Client (HL2) detailobjectsystem.cpp 1480
Unfortunately, it's not possible to protect yourself from such errors - there will always be one more way to cast one type to another implicitly. But the good news is that the new method of initialization in C++11 has one nice feature: it prohibits narrowing casts. In this code, the error will occur at the compilation stage and it can be easily corrected.
float flRatio { pMat->GetMappingWidth() /
pMat->GetMappingHeight() };There are a great number of ways to make an error in the management of resources and memory. Convenience when working, is an important requirement for the modern language. Modern C++ is not far behind, and offers a number of tools for automatic control of resources. Although such errors are at the heartland of dynamic analysis, some issues can be revealed with the help of static analysis. Here are some of them:

void AccessibleContainsAccessible(....)
{
auto_ptr<VARIANT> child_array(
new VARIANT[child_count]);
...
}Note: This code is taken from Chromium.
PVS-Studio warning: V554 Incorrect use of auto_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. interactive_ui_tests accessibility_win_browsertest.cc 171
Of course, the idea of smart pointers is not new: for example, there was a class std::auto_ptr. I am talking about it using the past tense, because it was declared as deprecated in C++11 and removed in C++17. In this fragment the error was caused by the incorrectly used auto_ptr, the class doesn't have specialization for the arrays, and a result, the standard delete will be called instead of a delete[]. unique_ptr replaced auto_ptr, and it has specialization for the arrays and the ability to pass a deleter functor that will be called instead of delete, and a complete support of move semantics. It may seem that nothing can go wrong here.
void text_editor::_m_draw_string(....) const
{
....
std::unique_ptr<unsigned> pxbuf_ptr(
new unsigned[len]);
....
}Note: This code is taken from nana.
PVS-Studio warning: V554 Incorrect use of unique_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. text_editor.cpp 3137
It turns out that you can make exactly the same error. Yes, it would be enough to write unique_ptr<unsigned[]> and it will disappear, but nevertheless, the code gets compiled in this form too. Thus, it is also possible to make an error in this way, and as practice shows, if it's possible, then people do it. This code fragment is proof of that. That's why, using unique_ptr with arrays, be extremely careful: it's much easier to shoot yourself in the foot than it seems. Perhaps it would be better to use std::vector as the Modern C++ prescribes?
Let's take a look at another type of accident.
template<class TOpenGLStage>
static FString GetShaderStageSource(TOpenGLStage* Shader)
{
....
ANSICHAR* Code = new ANSICHAR[Len + 1];
glGetShaderSource(Shaders[i], Len + 1, &Len, Code);
Source += Code;
delete Code;
....
}Note: This code is taken from Unreal Engine 4.
PVS-Studio warning: V611 The memory was allocated using 'new T[]' operator but was released using the 'delete' operator. Consider inspecting this code. It's probably better to use 'delete [] Code;'. openglshaders.cpp 1790
The same mistake can be easily made without smart pointers: the memory allocated with new[] is freed via free.
bool CxImage::LayerCreate(int32_t position)
{
....
CxImage** ptmp = new CxImage*[info.nNumLayers + 1];
....
free(ptmp);
....
}Note: This code is taken from CxImage.
PVS-Studio warning: V611 The memory was allocated using 'new' operator but was released using the 'free' function. Consider inspecting operation logics behind the 'ptmp' variable. ximalyr.cpp 50
In this fragment malloc/free and new/delete got mixed up. This can happen during refactoring: there were functions from C that needed to be replaced, and as a result, we have UB.

int settings_proc_language_packs(....)
{
....
if(mem_files) {
mem_files = 0;
sys_mem_free(mem_files);
}
....
}Note: This code is taken from the Fennec Media.
PVS-Studio warning: V575 The null pointer is passed into 'free' function. Inspect the first argument. settings interface.c 3096
This is a more amusing example. There is a practice when a pointer is zeroed after it is freed. Sometimes, programmers even write special macros for that. On the one hand, it's a great technique: you can protect yourself from another memory release. But here, the expression order was confused, and thus, free gets a null pointer (which didn't escape the analyzer's attention).
ETOOLS_API int __stdcall ogg_enc(....) {
format = open_audio_file(in, &enc_opts);
if (!format) {
fclose(in);
return 0;
};
out = fopen(out_fn, "wb");
if (out == NULL) {
fclose(out);
return 0;
}
}But this problem does not only relate to memory management, but also to resource management. For example, you forget to close the file, as in the fragment above. And in both cases, the keyword-RAII. This same concept is behind smart pointers. In combination with move-semantics, RAII helps to avoid a lot of bugs related to memory leaks. And code written in this style allows the identification of resource ownership more visually.
As a small example, I'll provide the wrapper over FILE, which is using the abilities of unique_ptr:
auto deleter = [](FILE* f) {fclose(f);};
std::unique_ptr<FILE, decltype(deleter)> p(fopen("1.txt", "w"),
deleter);Although, you may probably want a more functional wrapper to work with the files (with a more readable syntax). It's time to remember that in C++17, an API will be added to work with file systems — std::filesystem. But if you are not satisfied with this decision, and you want to use fread/fwrite instead of i/o-streams, you can get some inspiration from unique_ptr, and write your own File, which will be optimized for your personal needs, convenient, readable, and safe.
Modern C++ provides a lot of tools that help you write code more securely. A lot of constructions for compile-time evaluations and checks have appeared. You can switch to a more convenient memory and resources management model.
But there is no technique or programming paradigm that can fully protect you from errors. Together with the functionalities, C++ also obtains new bugs, which will be peculiar only to it. This is why we cannot solely rely on one method: we should always use the combination of code-review, quality code, and decent tools; which can help save your time and energy drinks, both of which can be used in a better way.
Speaking about tools, I suggest trying PVS-Studio: we have recently started working on a Linux version of it, you can see it in action: it supports any build system and allows you to check your project just by building it. For the Windows developers we have a handy plugin for Visual Studio which you can try as a trial version.
0
0
0
0