
Our website uses cookies to enhance your browsing experience.

This post is about love. About the love of the static code analyzer PVS-Studio, for the great open source Linux operating system. This love is young, touching and fragile. It needs help and care. You will help greatly if you volunteer to help testing the beta-version of PVS-Studio for Linux.

My colleagues and I have long refused to discuss the topic of development of PVS-Studio for the Linux OS and UNIX world in general. It's not about personal preferences or technical issues. It's much simpler - this is a cold, pragmatic approach to product development.
We are a small company that is living solely on selling the PVS-Studio software product. We do not receive any grants or other support from the government or large companies. It all puts great responsibility on us, in choosing what direction to take in the development .
By now, we have become strong enough, and are ready to start in a new direction - Linux. Oh yes, it really happened. We have finally made up our mind to start working in this direction. We hope it will be a more successful venture than CppCat.
Firstly, I would like to remind you what PVS-Studio is, and what it is capable of at this moment. If you've already read our articles, you can skip this section.
PVS-Studio is a tool for bug detection in the source code of programs, written in C, C++, and C#. Until the present moment, the analyzer was mostly aimed at developers using the Visual Studio environment. Supported languages and dialects:
Main features of PVS-Studio:
On the PVS-Studio page, you can learn more about the product and download it. Here is a table of the main diagnostic features of PVS-Studio. Not all the diagnostics are included in the table, as some of them are really hard to classify. However, it shouldn't detract from the overall impression; the full list of diagnostics and the descriptions can be found here.
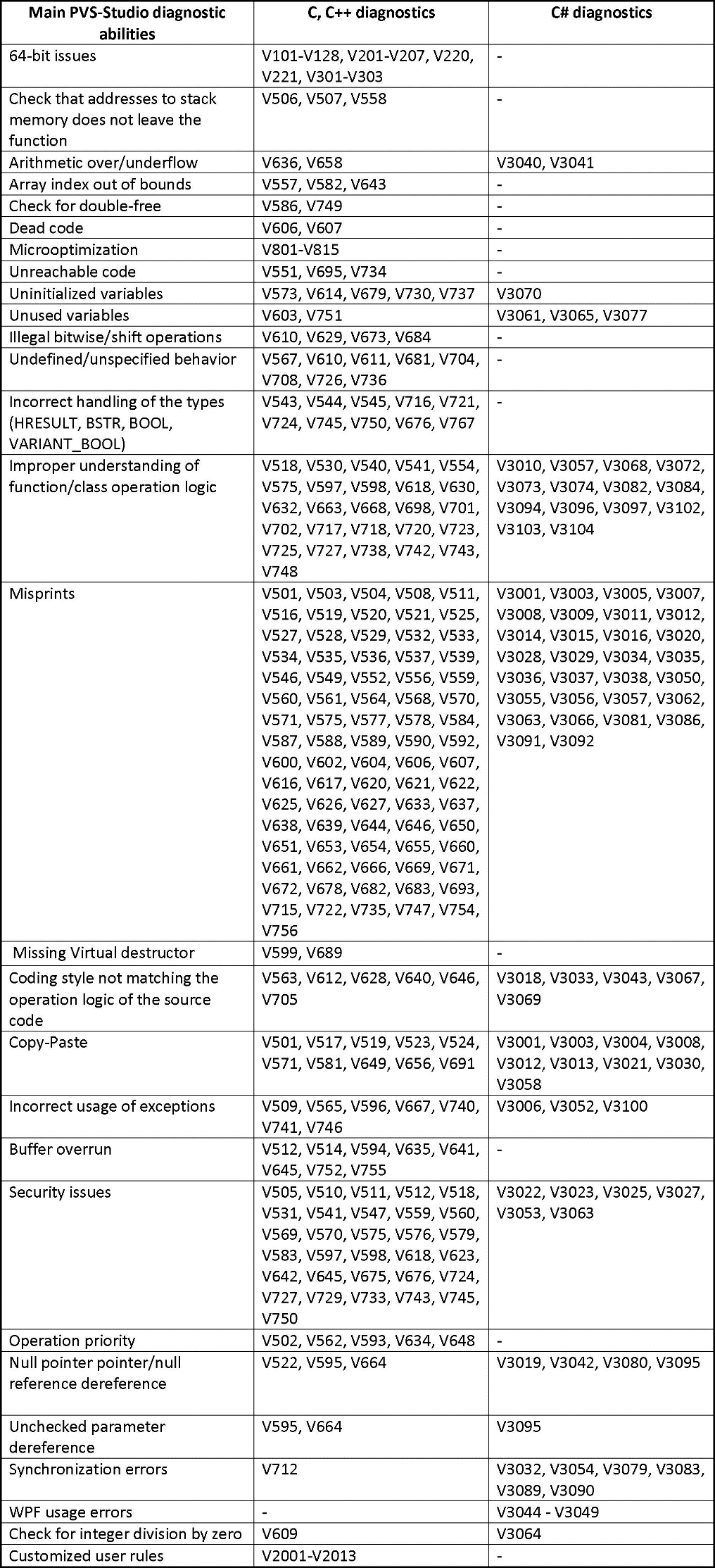
Table 1 - Features of PVS-Studio. Click on the picture to enlarge.
Now let's speak about the reason you have started reading this article: Linux support.
This task is not as easy as it may seem at first glance. To compile an executable module for Linux, and check something with it, wasn't that troublesome. We did that long ago. Over a year ago we wrote an article about checking the Vim project. But this is only a small part of the total load of work. Programmers sometimes forget that to compile an executable module and create a software product is not the same thing.
We plan to support GCC and Clang. We have started with GCC and will go back to Clang later. Here are our tasks at this point.
Sometimes I get the impression that the developers of compilers get so bored that they start making their life more complicated, and also the life of the developers that are implementing the code, highlighting, performing static analysis, and so on. In other words I cannot explain why it was needed to introduce Conditionals with Omitted Operands. Of course, it's really cool that we can cut the ternary operator to: z = x ? : y;. But to my mind we could happily live without it.
A lot of people wonder why we should bother with various documented and undocumented compiler extensions. It seems that it's enough to analyze C++ compliant to the standard, and not worry about the extensions, as they are used very rarely. Unfortunately, it is not so and these extensions require a lot of work time.
It doesn't matter if there are non-standard entities in the program. Any serious program will have header files that contain some extension. As a result it confuses the parser in the analyzer, and it cannot normally process many *.cpp files, in which this "unfortunate" *.h file is included. Of course, there are mechanisms in PVS-Studio analyzer which attempt to compensate for the errors in code parsing, and continue the analysis. Unfortunately, this mechanism does not always help. This can cause strange false positives or vice versa, a code fragment (up till the end of the function or a class, or even a whole file) can be excluded from the analysis.
Moreover, programmers like to use some "tricky" features in the system header files. That's why it's very easy to encounter some extension.
If you are interested, what this really means, I suggest looking for example, at:
These are documented extensions. Judging by our experience of working with Visual C++, we can expect some more pitfalls in the form of undocumented extensions.
As we are using our own parser (the development of a forgotten and abandoned OpenC++ library), we should support various extensions.
However, if we used some other parser, it wouldn't help us much. For example, if we rewrite the analyzer and take Clang as the basis for it, we will still have to deal wit the extensions of GCC and Visual C++.
We use seven main methods of testing in the PVS-Studio development.
From the point of view of Linux support, we should first work on the points N5 and N6. The point N5 intersects with the previous section "More complete support of GCC and Clang". It's not really hard to write tests to check system header files, but it's quite labour-intensive to enhance the parser. Yet, we have already spoken about it, so N6 is way more interesting for us.
In fact, it is the largest and most elaborate of the testing systems we have. Here is the workflow of the program:
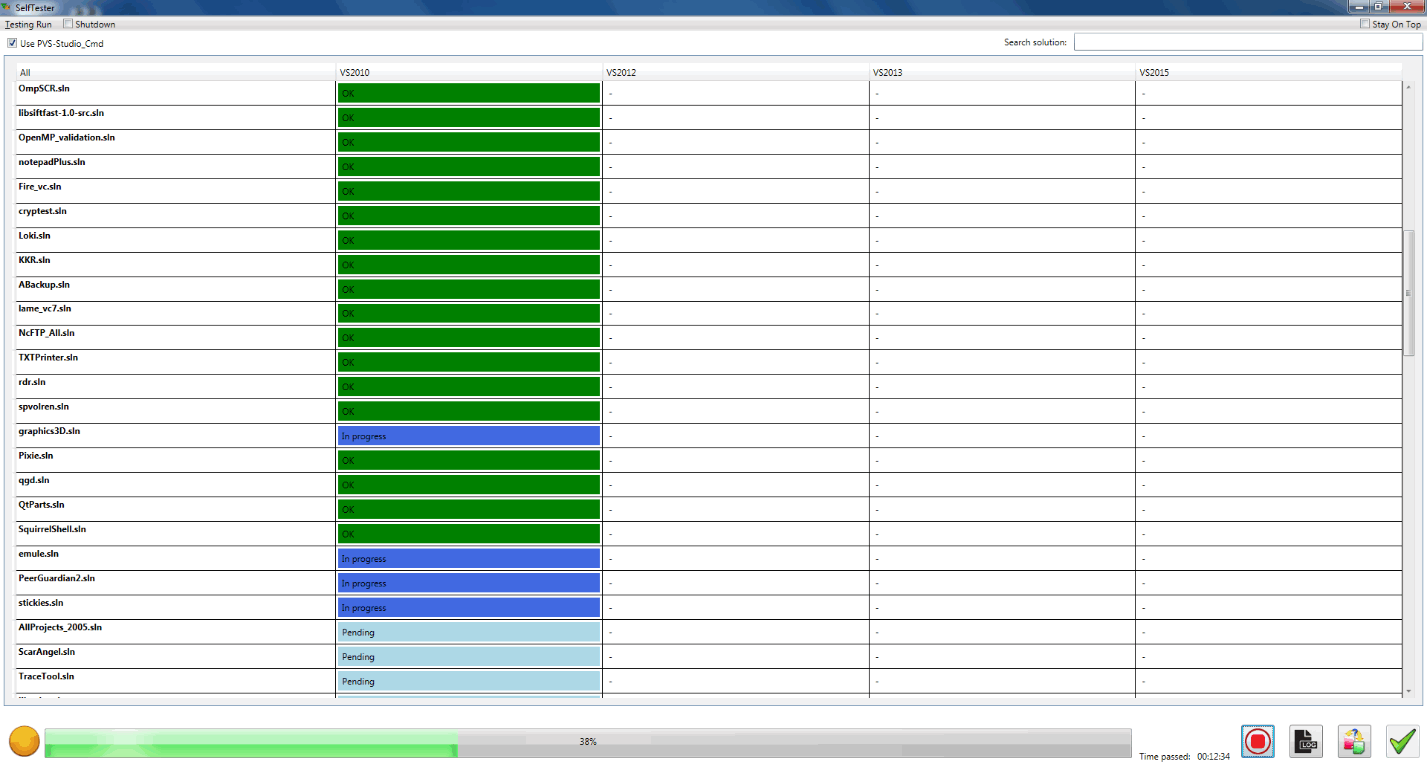
There is no point in describing the tool in detail, as it is intended only for inner usage. I should only say that it allows the developers to do a very comfortable track of the editing results in the core of the analyzer, and addition of new diagnostics.
So now we have to create the same system for Linux. Understanding that it is a very important part of the analyzer development, we should treat this task very seriously. On top of that we'll have to do a considerable amount of work selecting open-source projects that we'll use to check the efficiency of the analyzer. On the one hand, these projects must not be too large, so as not to make the check time too long. On the other, they need to be "rich": we have to see various approaches to programming. It is desirable that there are goto operators, patterns (templates), somewhere there is active usage of Unicode, and so on. This makes the analyzer testing more in-depth. To get such a collection of source code requires a lot of time to study a large amount of open source projects.
In PVS-Studio for Windows there is a GUI utility Standalone.exe. It makes working with the reports (.*plog-files) possible, if the Visual Studio environment isn't installed very convenient.
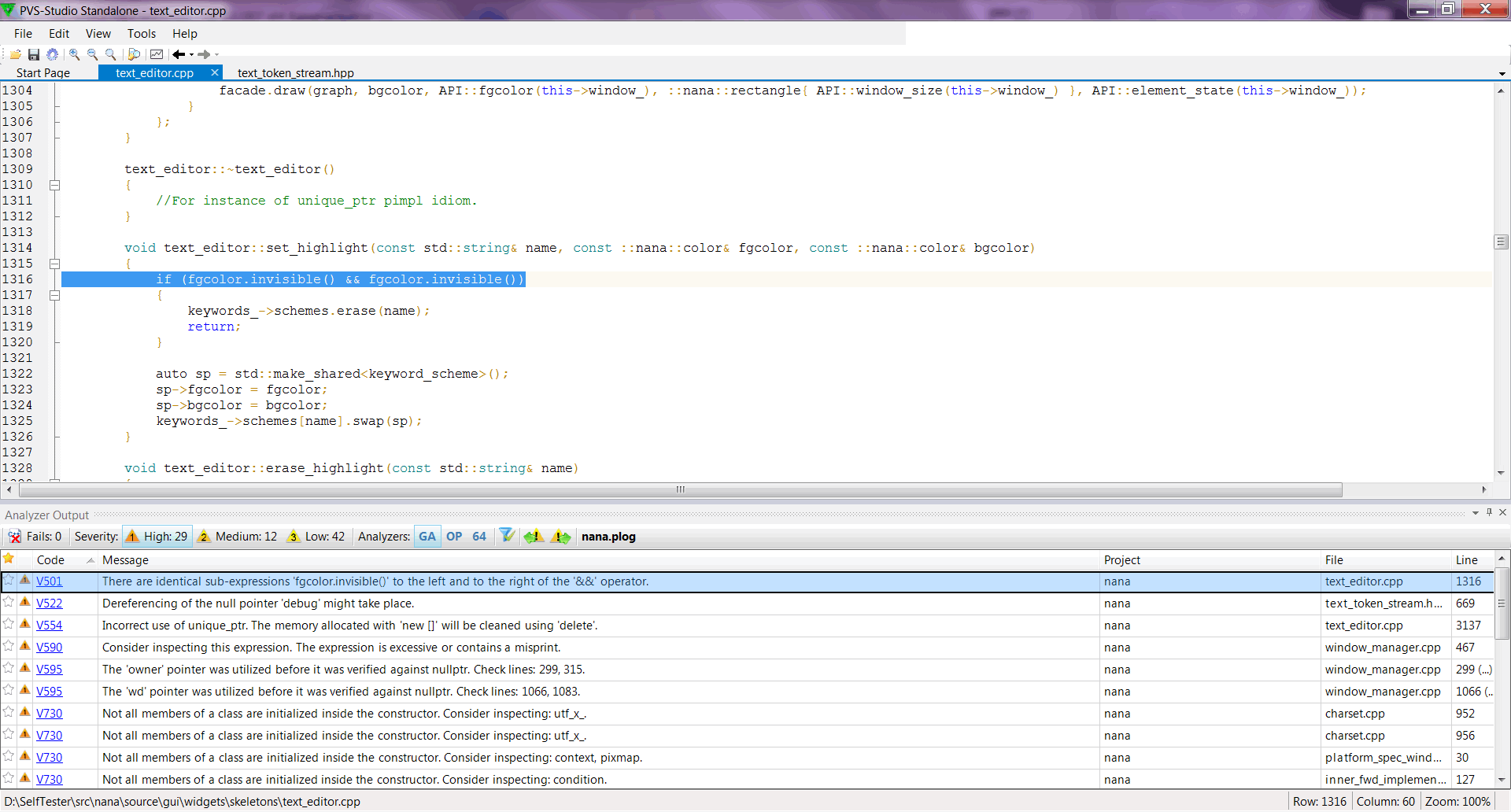
But that's not the most important. More important is the fact that with the help of this utility you can check a project that is compiled by any exotic and hand-made system. However, it is not intended just for exotic situations. Even if you have a classic makefile, it's easier to do the analysis with the Standalone, rather than digging into PVS-Studio documentation to write the analyzer call in the makefile.
Standalone enables you to track the runs of Visual C++, GCC (MinGW), and Clang, and collect all the necessary information for the check. It works like this: you tell the program "start tracking", after that you do your usual project build. Then you should set the program "ready". Then the program starts analyzing those files, whose compilation has just been done.
By the way, it's not necessary to do this manually. You can use a console utility CLMonitor.exe to check the project on the server. It also collects information on the running compilers, and scans the project.
Having started the Linux version implementation, we have decided that we should support tracking of the compiler runs. This helps programmers to quickly and easily get a good command of PVS-Studio. The thing is that any team member can check the project with this utility, without bothering people who are supporting the makefiles and the build system in general. In big projects, not everyone knows how their application may be compiled. Moreover, not everyone will be able to find the time, and wish to investigate how and where to write a PVS-Studio call. All of this can be made even more complicated if there is an auto-generated makefile. It's clear that it's not that hard to sort all these things out, but is a significant barrier when checking the first project and satisfying research curiosity.
So you have got acquainted with another subtask of a Linux version creation. We are working on the development of the compiler runs monitoring system, and collecting all the necessary information for the check.
When writing the documentation, we always have two opposing wishes. On the one hand, we have always tried to make the product as simple as possible, so that a user doesn't have to read a large manual. On the other hand, static analysis is a fairly complicated tool, and the documentation should reflect all the nuances of working with it. This especially concerns the descriptions of diagnostic messages: there are quite a lot of them, and it's necessary for each of them to contain code examples.
As a result we'll have to do a lot of work correcting and replenishing the documentation with the files about Linux development. Besides that, we have to come up with an idea of how to implement a way in which to quickly get information about one or another diagnostic rule. There are no problems concerning this question in Visual Studio - you need just press the error number in the warning list, and the corresponding page will open up.
We still have to think what to make in the Linux environment. Of course, there is always a PDF file (350 pages), or online documentation available on the web site, but this isn't really the most convenient way to access the diagnostics.
Of course, the site requires a lot of work to be done. This is not a programming task but it needs to be done. That's why I decided to mention the site just for your information. A lot of programmers think only about the code, and forget that the release of the product involves a large number of our colleagues, solving a large number of tasks that seem "invisible".
Of course, we should not forget about testing. Although multi-level tests detect the majority of problems, there are always some unexpected errors or flaws. For now it's impossible to predict what they can be, but we have no illusions about the ideal world. Working under the Windows platform, we had a great many situations when we were doing everything right, but still something didn't work correctly. I gave an interview about 2 years ago about such unpleasant surprises (look for the phrase ("Unfortunately, however smart and safe our internal code may be, it sometimes gets discredited by the factors of the hostile external environment"). I'm sure, similar surprises will appear in Linux.
The results of our work will be wrapped in a distribution kit which you can easily download and use. But it's easier said than done. I think we'll need several iterations to make the program convenient, and take various nuances into account.
And lastly, we have to organize support for the new direction. Our customers appreciate qualitative and quick support. As soon as the new Linux version is released, we'll get a higher number of customer requests, especially in the beginning, when not everything will work perfectly. We'll have to be ready for this.
This list of further steps that we will have to take to adapt PVS-Studio for Linux is far from being complete. There are always plenty of small insignificant tasks that I cannot think of right away, and which wouldn't be very interesting to write about. For example, we will also have to write articles that will tell people about the fact that we now have PVS-Studio for Linux.
There are even bigger tasks that we will get to in the future. For example, as I have already said, we have focused on GCC, and only after this, are we planning to start work with Clang. For now I don't actually know if there will be Clang support in the first release version of PVS-Studio for Linux.
Here are a couple more tasks waiting for us:
We are looking forward to the moment that we'll have something to present to this world. I hope this article brought some intrigue, and that Linux developers will want to try scanning their projects with PVS-Studio. If you have time and wish to, I invite you to become a part of the beta-tester team.
So, if you feel like helping us to check PVS-Studio for Linux, please contact us. Also, please specify in the subject of the letter "PVS-Studio for Linux, Beta". Send the mail to support@viva64.com. We also ask to use corporate e-mail boxes, and a brief introduction of who you are and what you do. We will be really grateful to everyone who responds to this call for help, but we will of course pay special attention to those who may potentially become our customers.
Also, we would like to ask you to give answers to the following questions:
Once we have a version that can be tried, we'll write to all the volunteers who contacted us.
Thank you all in advance. From time to time we'll mention in articles the development progress of PVS-Studio. I wish you to run the debugger as seldom as possible!
0
0
0
0