
Our website uses cookies to enhance your browsing experience.
Webinar: Let's make a programming language. Lexer - 29.04

Interviewers and LeetCode problems often focus on rotating binary trees. But what about transforming a general tree into a different one? How do we solve this problem, and what approaches can we take? Let's explore this by examining how we translate one syntax tree into another.

It's not hard to imagine reasons for transforming one tree into another. They are listed below.
From now on, I'll use a more precise term "translation" instead of "transformation."
At PVS-Studio, we develop static code analyzers, so our work overlaps with compilers in terms of tooling. Among other things, we also work with the Abstract Syntax Tree (AST). But all examples here will be simplified, so no deep expertise is required.
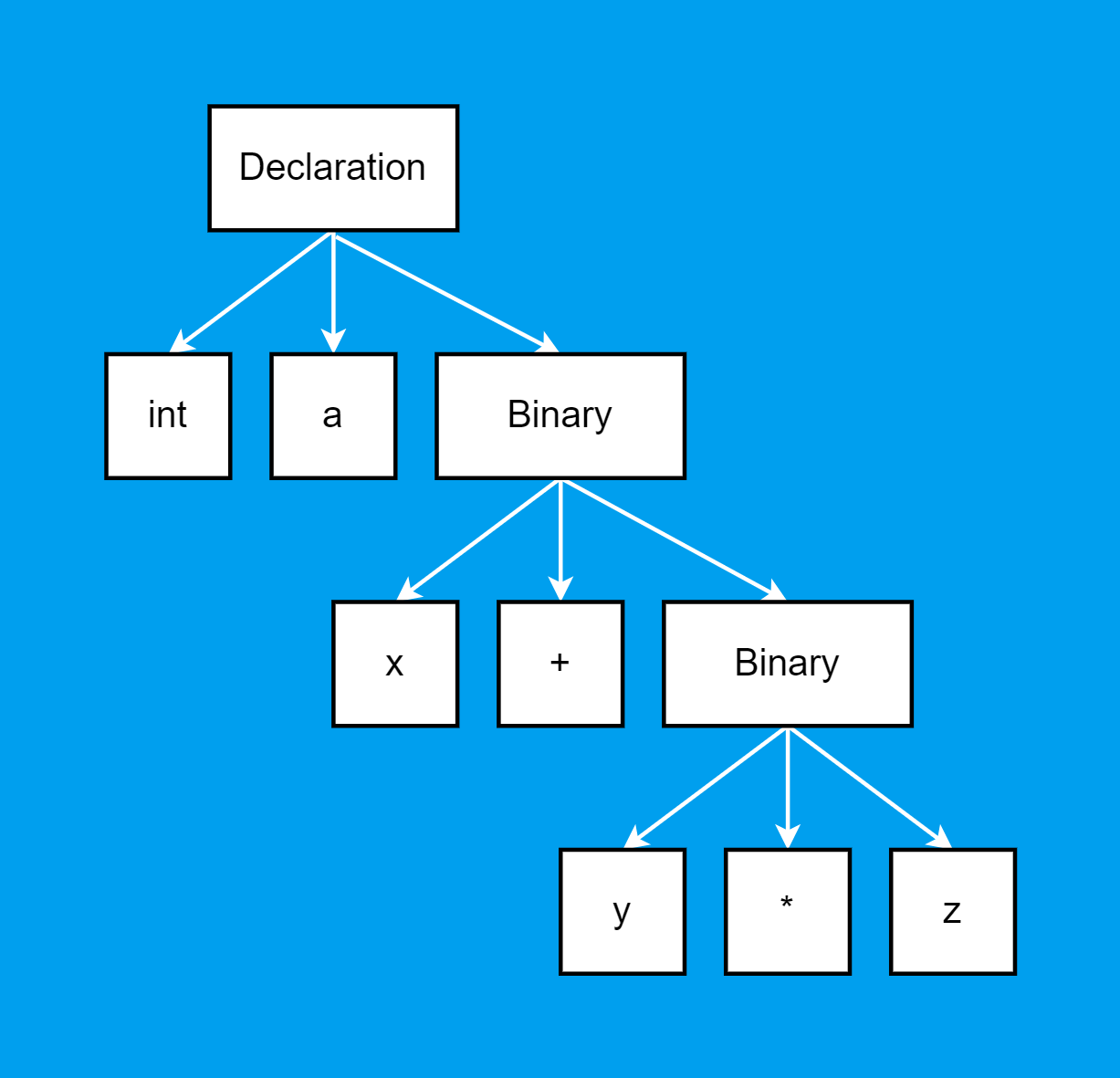
The task emerged in a rather intricate way:
So how did we end up with translation?
Thus, our task was born: Translate the TypeScript compiler tree, chewed up by protobuf, into our own representation.
What exactly are we doing? Let's set aside (for now) the issues with protobuf, we need to convert one tree into another. Both are syntax trees for the same language, so the differences are minor. Most nodes will map isomorphically one-to-one, with only cosmetic variations. Let's say, one model might use do...while naming, while the other uses repeat...until.
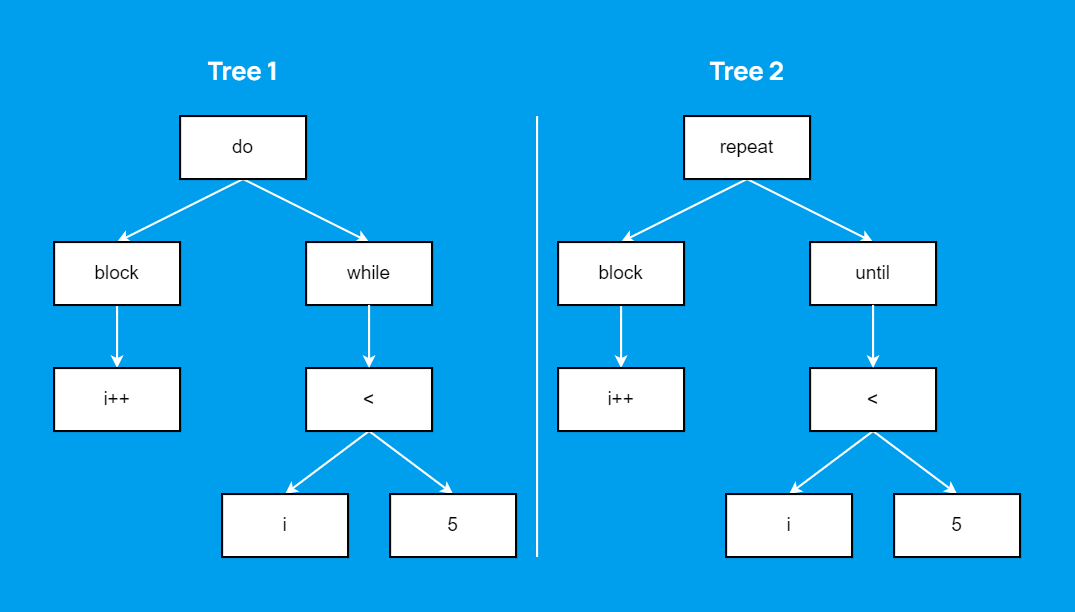
In this case, the transformation preserves the structure "as is"—we're just duplicating it. But there can be more complex scenarios. In JavaScript, for example, there's string interpolation, known as template strings.
For some reason, the TypeScript tree combines expressions inside interpolation and text into a single node, whereas in other languages, interpolation consists of a flat list.
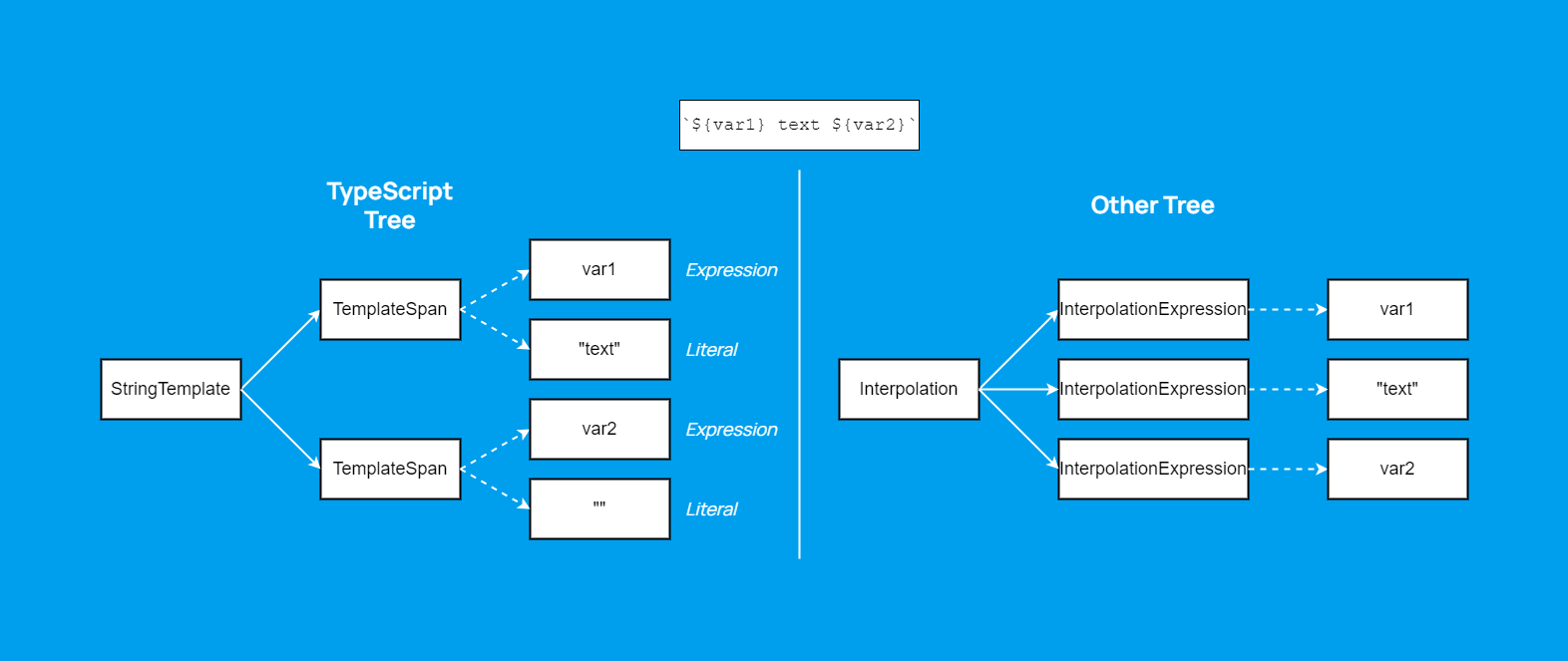
To get the tree on the right, we need to split the properties of the TemplateSpan node into two (or fewer) nodes. So, in addition to direct node-to-node transformation, we also transform a property into a separate node.
By the way, the reverse operation would be called aggregation—merging multiple nodes into one—but our task didn't require it.
So far, everything seems straightforward. But what if the source structure doesn't match the target one at all? In the AST context, we might want to normalize the structure to make it easier to work with later. For example, always add a body to arrow functions:
let a = () -> 1; // source
let a = () -> { return 1 }; // normalized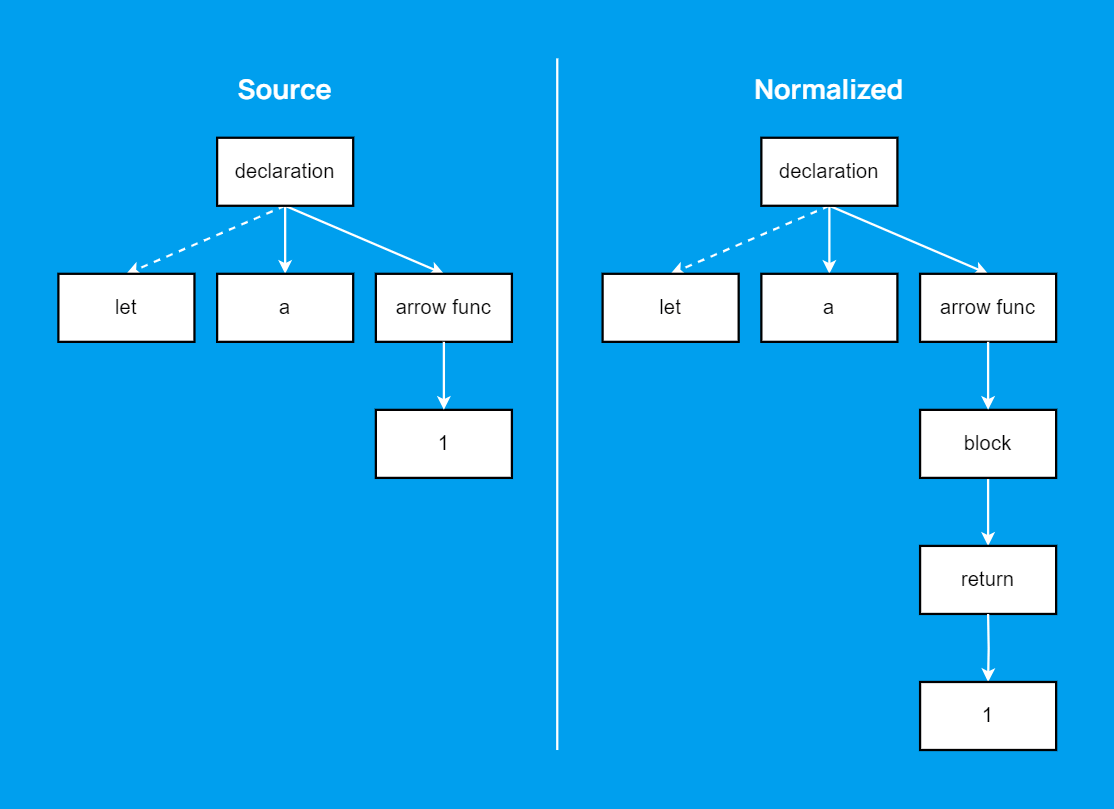
Here, this is just an arbitrary rule forcing us to add nodes to the tree that weren't there originally.
As a result, we have:

We looked at these cases one-by-one, but a syntax tree is built for the entire source file. In practice, everything will be mixed together—and on a huge scale. A single declaration and initialization like let a = 2 + 5 has at least four nodes. Just imagine how many nodes a file with thousands of code lines will contain.
By now, I hope you have a sense of what we're trying to do. It's time to move on to practice.
Before deciding how to perform such transformations, we need to figure out how to traverse the source tree.
The first idea might be to implement a tree iterator. I've even written an article about how it can help when traversing an AST. If your goal is to translate a tree with a small number of node types, this is likely the right choice—but not in our case.
I quickly counted the different node types in the diagrams above: there are about ten—and that's just three examples. In our AST for JavaScript, there are currently under 100 types, and the source model has even more. Each type means an additional if statement when deciding how to handle a node. So, if we want to write code that can be maintained without tears, it's better to turn to the visitor pattern.
I won't dwell on its implementation—you can check it out via the link above or at any other source. Instead, I'll just say that thanks to double dispatch, the number of conditions when working with different node types is almost zero. It's also quite easy to implement a recursive descent. Find the example under the spoiler.
interface Node {
void accept(Visitor v);
}
interface Visitor {
void visitBinary(Binary n);
void visitLiteral(Literal n);
}
class Binary implements Node {
private final Node left;
private final Node right;
public Binary(Node left, Node right) {
this.left = left;
this.right = right;
}
@Override public void accept(Visitor v) {
v.visitBinary(this);
}
}
class Literal implements Node {
private final int value;
public Literal(int value) {
this.value = value;
}
@Override public void accept(Visitor v) {
v.visitLiteral(this);
}
}
class Scanner implements Visitor {
public void scan(Node n) {
n.accept(this);
}
@Override public Binary visitBinary(Binary n) {
scan(n.getLeft());
scan(n.getRight());
}
@Override public void visitLiteral(Literal n) {
}
}An attentive reader will note that protobuf has digested our model for traversal, so what double dispatch are we even talking about? None. Almost none.
Protobuf did hurt us made us think hard. But in the end, we managed to emulate a visitor by generating a traverser based on a .protoset file, which describes all node types. The visit methods of such a visitor are quite ordinary:
@Override
public void visitBinaryExpression(BinaryExpression binaryExpression) {
scan(binaryExpression.getToken());
scan(binaryExpression.getLeft());
scan(binaryExpression.getRight());
}We achieve this via an innocent scan implementation:
public final void scan(Object node) {
switch (node) {
case BinaryExpression binaryExpression ->
visitBinaryExpression(binaryExpression);
case UnaryExpression unaryExpression ->
visitUnaryExpression(unaryExpression);
case LiteralExpression literalExpression ->
visitLiteralExpression(literalExpression);
// 121 LOC more
}
}It's hard to call this solution elegant, but it works. So, let's agree on the following.
visit methods without hand-written if statements.Ok, we figured out the translation scenarios and the traversal. Now we can finally move on to the translation.
Let's start with the simplest case. If we're building a tree, we need to store it somewhere. The easiest way is to return the current node from each visit method and also pass the parent in the arguments. If we inherit from the above scanner, adding a generic return value and a generic second argument for visit methods beforehand, we get something like this:
interface Visitor<R, P> {
R visitBinary(Binary n, P parent);
R visitLiteral(Literal n, P parent);
}
class Builder extends Scanner<JsNode, JsNode> {
@Override
public JsNode visitBinary(Binary n, JsNode parent) {
var left = (JsExpression) scan(n.getLeft());
var right = (JsExpression) scan(n.getRight());
return new JsBinary(left, right);
}
@Override
public JsNode visitLiteral(Literal n, JsNode parent) {
return new JsLiteral(n.getValue());
}
}In this very simple way, we can duplicate the tree structure. To avoid confusion, I mark the nodes of the target tree with the prefix Js at the beginning of the class name.
This case is not much more complicated, but here we'll need the parent we pass. Instead of copying directly, we add a bit of logic. Let's return to the same interpolation example:
@Override
public JsNode visitTemplateSpan(TemplateSpan templateSpan, JsNode parent) {
var interpolation = (Interpolation) parent;
var expr = new InterpolationExpression();
interpolation.add(expr);
interpolation.setExpression(
scan(templateSpan.getExpression())
);
// tail is optional
if (templateSpan.hasTemplateTail()) {
interpolation.add(new InterpolationText(
templateSpan.getTemplateTail().getValue()
));
}
return null;
}Since we skipped TemplateSpan, we return null—we've already attached the children via the parent passed as an argument.
I expressed my emotions with that picture last time for a reason—each case here is unique. Sometimes we get lucky, and normalization goes seamlessly. Other times, it's a hassle. In general, we adopted the following rule of thumb: avoid normalization if it changes the control flow or is too complicated. What counts as "too complicated" remains at the discretion of the developer and their manager :)
The arrow functions that I gave as an example earlier normalize quite simply, though there were still details to consider.
The visit method looks roughly like this:
@Override
public JsNode visitArrowFunction(
ArrowFunction arrowFunction,
JsNode parent
) {
var func = new JsArrowFunction();
// link inside
scan(arrowFunction.getParameterDeclarationList(), func);
// OK
if (arrowFunction.hasBlock()) {
func.setBlock(
scan(arrowFunction.getBlock())
);
} else if (arrowFunction.hasExpression()) {
var normalized = normalizeArrow(
arrowFunction
);
func.setBlock(normalized);
}
return func;
}The transformation is hidden in normalizeArrow:
public JsBlock normalizeArrow(ArrowFunction f) {
var block = new JsCodeBlock();
block.setFlag(Flag.SYNTHETIC);
var ret = new JsReturn();
ret.setFlag(Flag.SYNTHETIC);
block.addStatement(ret);
var expr = scan(f.getExpression());
ret.setExpression(expr);
return block;
}In addition to creating these nodes, we also mark them as synthetic, since they weren't present in the initial tree—effectively treating them as "virtual". It's useful in static analysis—for heuristics in diagnostic rules, we can account for the fact that the developer didn't write things like (var) -> { return console.log(var) }—it's just an artifact of our transformations. Ok, that's all for the transformations.
By this point, we've covered all basic principles related to solving the task.
visit methods.All that remains is to solve the task. Let me remind you: the target tree has about 100 node types, and the source tree has 263 types. This difference is largely due to the specifics of protobuf. This means we would have to hand-write visit and scan methods hundreds or thousands of times. Ready for such race? I'm not.

The solution to the problem has already appeared in the text. Just as the original traverser could be generated based on the .protoset file, so can the typical translation rules be code-generated based on some configuration rule. But we'll cover this—and how to fit in the atypical normalization — some other time.
This is the kind of case I encountered in my work. Although I've only skimmed the surface, I've touched on several interesting points: typical transformations, the choice between an iterator and a visitor, a non-trivial visitor implementation. We also looked at it through the lens of static analysis—synthetic nodes and the approach to normalization.
In any case, I hope you learned something new about working with trees. Don't miss articles on this topic or about new analyzers in general—subscribe to PVS-Studio Twitter and our monthly article digest! You're welcome to try the tool for free here.
If you'd like to follow my posts, subscribe to my personal blog.
0
0
0


0