
Our website uses cookies to enhance your browsing experience.
Webinar: Let's make a programming language. Part 1. Intro - 20.02


Your attention is invited to the tenth part of an e-book on undefined behavior. This is not a textbook, as it's intended for those who are already familiar with C++ programming. It's a kind of C++ programmer's guide to undefined behavior and to its most secret and exotic corners. The book was written by Dmitry Sviridkin and edited by Andrey Karpov.

Let's say we created a neat library to handle 2D vectors and added the Point structure. Here it is:
template <typename T>
struct Point {
~Point() {}
T x;
T y;
};We wrote a function:
Point<float> zero_point();As sedulous developers who cared of compile time and header file sizes, we implemented the function in the compiled .cpp file, providing users only its declaration. Our library was such a hit, quickly gaining popularity, and now many apps depended on it.
Everything was running smoothly. Suddenly, we realized the Point destructor was redundant and delegated the compiler to generate it automatically. We deleted the destructor.
template <typename T>
struct Point {
T x;
T y;
};We rebuilt the library and distributed to users new .dll/.so files—with updated header files, though. The change was so minor that users just added ready-made binaries without recompiling their code. It leads to crash with a catastrophic memory corruption.
Why?
This change broke the ABI.
In C++, all types are classified into trivial and non-trivial. Trivial are also sub-classified by triviality. Triviality allows us to avoid generating additional code for certain operations.
Additional optimizations are feasible with trivial objects. For example, we can pass them via registers. The compiler can replace memcpy used to avoid undefined behavior with reinterpret_cast for optimization purposes. And other things like that.
For example:
struct TCopyable {
int x;
int y;
};
static_assert(std::is_trivially_copyable_v<TCopyable>);
struct TNCopyable {
int x;
int y;
TNCopyable(const TNCopyable& other) :
x{other.x}, y{other.y} {}
// Wrote the constructor because
// aggregate initialization was disabled due to
// the user-provided copy constructor.
TNCopyable(int x, int y) : x{x}, y{y} {}
};
static_assert(!std::is_trivially_copyable_v<TNCopyable>);
// Return via the rax register.
// TCopyable fits perfectly
extern TCopyable test_tcopy(const TCopyable& c) {
return {c.x * 5, c.y * 6};
}
// The pointer returns
// via the rdi register.
extern TNCopyable test_tnocopy(const TNCopyable& c) {
return {c.x * 5, c.y * 6};
}From the the assembly code, we can make sure that two "identical" functions returning "identical" memory structures do this in different ways.
test_tcopy(TCopyable const&): # @test_tcopy(TCopyable const&)
mov eax, dword ptr [rdi]
mov ecx, dword ptr [rdi + 4]
lea eax, [rax + 4*rax]
add ecx, ecx
lea ecx, [rcx + 2*rcx]
shl rcx, 32
or rax, rcx #!
ret
test_tnocopy(TNCopyable const&): # @test_tnocopy(TNCopyable const&)
mov rax, rdi
mov ecx, dword ptr [rsi]
mov edx, dword ptr [rsi + 4]
lea ecx, [rcx + 4*rcx]
add edx, edx
lea edx, [rdx + 2*rdx]
mov dword ptr [rdi], ecx #!
mov dword ptr [rdi + 4], edx #!
retHere's the same case with the 2D point:
struct TPoint {
float x;
float y;
};
static_assert(std::is_trivially_destructible_v<TPoint>);
struct TNPoint {
float x;
float y;
~TNPoint() {} // the user-provided destructor
// turns the type into a non-trivial type, even
// if the destructor isn't executed.
};
static_assert(
!std::is_trivially_destructible_v<TNPoint>);
// Return via a register
extern TPoint zero_point() {
return {0,0};
}
// Return via a pointer
extern TNPoint zero_npoint() {
return {0,0};
}
zero_point(): # @zero_point()
xorps xmm0, xmm0
ret
zero_npoint(): # @zero_npoint()
mov rax, rdi
mov qword ptr [rdi], 0
retIt's getting worse with templates, since the triviality of a structure template may depend on the triviality of template parameters.
For instance, look at the pair structure template implementation in the C++03 standard library. We can notice useless user-provided copy constructors. Since C++11, they were removed. This is another area where old C++ and new C++ libraries are binary incompatible.
If we tried to use the ABI to manage C++ libraries, we might have encountered crashes related to trivial types, not just in C++, but in any language. For example, such a bug cropped up in the bindings generation utility for Rust.
Keep an eye on the trivial types! If we aim to design the robust ABI for our library, we should design it using C structures and functions, not the C++ hodgepodge.
However, don't forget about triviality:
It's common yet well-known hassle, not just in C or C++.
Modern programming languages usually prohibit uninitialized variables. In languages like Go, variables are always initialized with the default value, while in Kotlin and Rust, we get a compilation error while reading the uninitialized variable.
C and C++ are long in the tooth. We can declare a variable and initialize it later—or forget about it at all. In contrast to low-level assembly language, where we can read the uninitialized variable—and get the garbage bytes as well—in C, C++, and Rust (MaybeUninit), it leads to undefined behavior.
Here's an unexpected case of such UB (found here):
struct FStruct {
bool uninitializedBool;
// The constructor doesn't initialize data members.
// To reproduce the issue,
// the constructor should be defined in
// another translation unit.
// We can reproduce it using the noinline attribute
__attribute__ ((noinline)) FStruct() {};
};
char destBuffer[16];
void Serialize(bool boolValue) {
const char* whichString = boolValue ? "true" : "false";
size_t len = strlen(whichString);
memcpy(destBuffer, whichString, len);
}
int main()
{
// Create the object with the uninitialized data member.
FStruct structInstance;
// UB!
Serialize(structInstance.uninitializedBool);
//printf("%s", destBuffer);
return 0;
}The program crashes. Since there aren't any uninitialized variables in a correct program, the compiler identifies that boolValue is always valid and optimizes as follows:
// size_t len = strlen(whichString); // 4 or 5!
size_t len = 5 - boolValue;The "real" value of the uninitialized bool variable isn't necessarily true/false. It could be, for example, 7. In some cases, we get len = 5 - 7. As a result, we catch a buffer overflow on the memcpy call.
If leaving out uninitialized variables helps with optimization, why not just ban them with a hard compilation error on top of that?
First, they allow us to be penny-wise and pound-foolish:
int answer;
if (value == 5) {
answer = 42;
} else {
answer = value * 10;
}If we couldn't declare the uninitialized variable, we'd either be forced to write
int answer = 0;And waste the extra xor instruction for zeroing in debug build!
Or wrap the answer evaluation in a separate function—or the lambda function—and get a call instead of jmp (if the compiler doesn't optimize out this effectively)!
Or use the conditional operator, resulting in unreadable code, especially with multiple conditional branches.
Second, sometimes the penny can be foolish and the pound can be wise. The savings are worth it:
constexpr int data_size = 4096;
char buffer[data_size];
read(fd, buffer, data_size);It's not a good idea to initialize the entire array just immediately to grind it. The compiler is unlikely to skip initialization during optimization. For this purpose, it needs guarantees that the hypothetic read function doesn't read anything from the buffer. These guarantees can be in standard library functions, but not for user-defined functions.
First, let's figure out, what constructs generate uninitialized variables.
We don't consider special functions such as std::make_unique_for_overwrite and the raw memory allocators (*alloc too). I'd like to point out that we can't write (T*)malloc(N) while waiting for initialized memory. There are calloc for that.
If it's true that is_trivially_constructible<T> == true,
Generate uninitialized variables/arrays (or pointers to uninitialized variables/arrays).
If the type is constructed in a non-trivial way, don't celebrate too early. Its default constructor might have forgotten to initialize something. The type became non-trivial because someone provided a destructor to confuse us, or declared a virtual function—and didn't provide member initialization.
#include <iostream>
#include <cstring>
#include <type_traits>
struct S {
int uninit;
~S() {}
};
static_assert(!std::is_trivially_constructible_v<S>);
int main()
{
// Locally construct an instance of our struct here on the stack.
// The bool member uninitializedBool is uninitialized.
S uninit1;
std::cout << uninit1.uninit << "\n";
S uninit2[2];
std::cout << uninit2[1].uninit << "\n";
S* puninit = new S;
std::cout << puninit->uninit << "\n";
S* puninit2 = new S[2];
std::cout << puninit2[1].uninit << "\n";
int* p = new int;
std::cout << *p << "\n";
// Output "true" or "false" to stdout.
return 0;
}The code is compiled, using Clang 18.1 and ignoring the '-Wall -Wextra -O3 -std=c++17 -Wpedantic -Wuninitialized' keys. It outputs the garbage:
272846040
-658903036
-658903036
-658903036
-658903036If we use GCC 14.1 and the same keys, the code outputs zeros, and the compiler issues warnings, but not in all cases.
<source>: In function 'int main()':
<source>:17:36: warning: 'uninit1.S::uninit' is used uninitialized
[-Wuninitialized]
17 | std::cout << uninit1.uninit << "\n";
| ^~~~
<source>:16:7: note: 'uninit1.S::uninit' was declared here
16 | S uninit1;
| ^~~~~~~
<source>:19:39: warning: 'uninit2[1].S::uninit' is used
uninitialized [-Wuninitialized]
19 | std::cout << uninit2[1].uninit << "\n";
| ^~~~
<source>:18:7: note: 'uninit2' declared here
18 | S uninit2[2];But if we delete the -O3, warnings disappear!
When declaring variables, the widespread use of '{}' is a good practice that ensures the zero-initialization only with trivial types. For non-trivial ones, it's all on the constructor.
Sometimes we may "hit it big", and according to the standard, the initialization will go through two steps: first with zeroes, then the default constructor will be called. See more details here. I only managed to reproduce this effect using std::make_unique;.
How to tackle uninitialized variables and their undefined behavior?
1. Don't split declaration and initialization. Instead, use constructions:
auto x = T{...};
auto x = [&] { ... return value }();2. Check constructors for initialization of all data members.
3. Use initializers by default, while declaring structure data members.
4. Use the latest versions of compilers: they're getting better at detecting the access to uninitialized values.
5. Don't use new T if we're not sure what we do. Always use new T{} or new T().
6. Don't forget about dynamic and static analyses using external utilities. Valgrind can identify instances where memory hasn't been initialized. PVS-Studio has a set of diagnostic rules to detect this issue.
If you ever get the bright idea to use uninitialized memory as a source of entropy, chase it away as fast as you can! Someone tried to do it, but failed.
The standard actively enhances how we can handle custom and standard collections in C++.
The standard library algorithms (from C++11 to C++17 standards) operate on pairs of iterators, clearly defining the range of collection elements.
const std::vector<int> v = {1,2,3,4,5};
std::vector<int> odds;
std::copy_if(
v.begin(), v.end(), std::back_inserter(odds),
[](int x){ return x % 2 == 0;});
std::vector<int> squares;
std::transform(
odds.begin(), odds.end(), std::back_iserter(squares),
[](int x) { return x * x;});
// return squares;Wordy and awkward. Moreover, it's not zero cost at all. Usually, most C++ compilers don't optimize redundant allocations. Indeed, we can optimize everything manually. The legacy STL algorithms that handle iterators have flexible options.
std::vector<int> v = {1,2,3,4,5};
v.erase(
std::remove_if(v.begin(), v.end(),
[](int x){ return x % 2 != 0; }),
v.end()
);
std::transform(v.begin(), v.end(), v.begin(),
[](int x){return x * x;});
return v;Great! No redundant allocations! But it's still just as wordy and awkward. The erase-remove construction looks odd too.
Most developers usually start with a simple solution and then optimize it as needed. It's not really practical to use legacy algorithms with pairs of iterators.
Starting with C++11, we can use range-based for. It greatly facilitates the iteration over collection.
for (auto x : v) {
// do something with x
}However, the iteration is available only over the whole collection. If we want to iterate from fifth to tenth vector elements, it's better to write a loop counter or use std::for_each with two iterators.
std::for_each(v.begin() + 5, v.begin() + 10, [&](auto x) {
// do something
});Or trawl through a ton of books, courses, or standards to discover that range-based-for automatically handles any object that provides begin and end functions.
Okay, begin() and end() should return iterators. If these functions return anything else, we'll get a compilation error (sometimes it's clear why). Chances are it'll happen 99.9% of the time. In exotic cases, there might be something unexpected.
This brings up a good point: what if we create a structure with iterators to iterate over a part of the collection? Without any transform, filter, and reverse... Oh! It's the C++20 ranges (initially ranges-v3).
Let's say we developed our own library for convenient work with collections. It's also conveniently working with range-based-for. Everything was fine until we wrote an indolent procedure-generated sequence with a compatible interface.
For example, we could write an "infinite" number generator:
struct Numbers {
struct End {}; // It's a marker to check if the end has been reached.
struct Number { // The iterator–generator. We need three operations.
int x;
// Check if we've reached the end.
bool operator != (End) const {
return true;
}
// Generation of the current element.
int operator*() const {
return x;
}
// Iterator moves to the next element.
Number operator++() {
++x;
return *this;
}
};
explicit Numbers(int start) : begin_{start} {}
Number begin_;
auto begin() { return begin_; }
End end() { return {}; }
};That's where the tricky part starts.
Neither the old STL algorithms nor range-based-for can work here. They don't compile because they need begin and end to have the same type.
Fortunately, we can fix it seamlessly in our simple example:
struct Numbers {
struct Number {
int x;
bool operator != (Number) const {
return true;
}
int operator*() const {
return x;
}
Number operator++() {
++x;
return *this;
}
};
explicit Numbers(int start) : begin_{start} {}
Number begin_;
auto begin() { return begin_; }
auto end() { return begin_; }
};However, the operator != semantics is peculiar. We need something to construct end(), though. If our generator is more complex, like allocating something on the heap, it'll cost extra overhead. This hardly aligns with the zero-cost concept, does it?
In C++17, range-based-for has been fixed. Now it can operate with a different range-based-for iterators.
But, the old STL algorithms still don't function correctly.
auto nums = Numbers(10);
// Compilation error :
auto pos = std::find_if(nums.begin(), nums.end(),
[](int x){ return x % 7 == 0;});
std::cout << *pos;
// Compilation error...In C++20, it has been finally fixed! Unfortunately, the old STL algorithms still don't operate correctly. We just got new STL algorithms, almost the same as the old ones, only in the std::ranges namespace. They roughly order to properly operate with the iterator concepts. That's why the example below bloats.
struct Numbers {
struct End {
};
struct Number {
using difference_type = std::ptrdiff_t;
using value_type = int;
using pointer = void;
using reference = value_type;
using iterator_category = std::input_iterator_tag;
int x;
bool operator == (End) const {
return false;
}
int operator*() const {
return x;
}
Number& operator++() {
++x;
return *this;
}
Number operator++(int) {
auto ret = *this;
++x;
return ret;
}
};
explicit Numbers(int start) : begin_{start} {}
Number begin_;
auto begin() { return begin_; }
End end() { return {}; }
};The following code compiles and handles them.
auto nums = Numbers(10);
auto pos =
std::ranges::find_if(nums.begin(), nums.end(),
[](int x){ return x % 7 == 0;});
std::cout << *pos;Well, it was a brief intro. Now we can finally start shooting ourselves in the foot.
Thanks to C++20, we no longer need to create a new (EndSentinel) type for the end() function for each iterator generating an infinite sequence. The standard library defined the std::unreachable_sentinel_t type, which was designed for this purpose. We can compare it for equality with any object that's similar to ForwardIterator, and the result will always be false.
It facilitated our numeric example.
struct Numbers {
struct Number {
using difference_type = std::ptrdiff_t;
using value_type = int;
using pointer = void;
using reference = value_type;
using iterator_category = std::input_iterator_tag;
int x;
int operator*() const {
return x;
}
Number& operator++() {
++x;
return *this;
}
Number operator++(int) {
auto ret = *this;
++x;
return ret;
}
};
explicit Numbers(int start) : begin_{start} {}
Number begin_;
auto begin() { return begin_; }
auto end() { return std::unreachable_sentinel; } // !
};The comparison with unreachable_sentinel doesn't call any operations, allowing us to generate a range that can be iterated without bounds checking.
For example:
// If we have a vector to shuffle.
std::vector<size_t> perm = { 1, 2, 3, 4, 5, 6, 7, 8, 9};
std::ranges::shuffle(perm, std::mt19937(std::random_device()()));
// And we should find the element location
// known to be in the vector.
// size_t p = 7;
assert(p < perm.size());
return std::ranges::find(perm.begin(),
std::unreachable_sentinel, p) - perm.begin();This is a risky move that's better to use if we've checked everything and this optimization is critically necessary. In the example above, if we try to find the element that isn't contained in the vector, we'll get undefined behavior.
When refactoring large codebases with these features, we may have hard-to-find bugs. Unlike Rust, which enables us to confidently mark potentially dangerous code, C++ has no such guarantees. Any code fragment could be potentially unsafe, so we can only highlight the issue by adding a comment or using some tricks with the function/variable names.
Let's say we developed a class hierarchy and set out to write an interface for a processor that could be started and stopped. In the first iteration, it'd most likely look like this:
class Processor {
public:
virtual ~Processor() = default;
virtual void start() = 0;
// Stops execution, returns 'false' if already stopped.
virtual bool stop() = 0;
};The interface users implemented a lot of their implementations. Everyone was happy—until someone wrote an asynchronous implementation. Suddenly, the app crashed for some reason. After a little investigation, we found that the interface users hadn't called the stop() function before destroying the object. Oh no!
Okay, we might have been tired and angry as well. It might not have been us at all—it might have been an experienced colleague who should have fine-tuned the interface. Anyway, a fix came to the world:
class Processor {
public:
virtual void start() = 0;
// stops execution, returns `false` if already stopped
virtual bool stop() = 0;
virtual ~Processor() {
stop();
}
};Does that make sense? Yes!
Is it correct? No!
If we're lucky, a code analyzer or a tailored compiler will warn us. In C++ constructors and destructors, virtual dispatch doesn't work. In other languages, like C# or Java, it's a different story. These languages have their own set of challenges.
Why? The part of the derived object used in the overridden function might not be created yet during construction. Yet, constructors are called from the base class to the derived class. With destruction, it's the opposite. The part of the derived object has already been destroyed. If we enable dynamic invocation, we can easily encounter use-after-free.
This topic has already been explained in other articles, for example, "Virtual function calls in constructors and destructors (C++)".
Rejoice! This is one of the few C++ topics protected against undefined behavior with lifetimes!
Okay. What if we do this? Let's add an intermediate function call.
// processor.hpp
class Processor {
public:
void start();
// Stops execution, returns 'false' if already stopped.
bool stop();
virtual ~Processor();
protected:
virtual bool stop_impl() = 0;
virtual void start_impl() = 0;
};
// processor.cpp
Processor::~Processor() {
stop();
}
bool Processor::stop() {
return stop_impl();
}
void Processor::start() {
start_impl();
}Compilers don't issue a lovely warning anymore, and it'll be harder to spot an issue. The PVS-Studio analyzer couldn't be tricked so easily—it still issues V1053 Calling the 'stop_impl' virtual function indirectly in the destructor may lead to unexpected results at runtime. Check lines: 18, 22, 11.
We added just one extra indirection level. What happened if our base class code would be more complicated...? If we used implementation inheritance, it could cause many problems. All because of an innocent desire to overuse the code.
It's best to avoid calling virtual functions in class constructors and destructors, as this could lead to problems in the future. If we attended it, it would be better to use an explicit static call with the class name (the name qualified call).
// processor.cpp
Processor::~Processor() {
Processor::stop();
}It's also worth noting that in C++, we can access the implementation of pure virtual functions. Sometimes it's even useful. This way, we can ensure that the user must choose whether to modify the function or use the default behavior.
class Processor {
public:
virtual void start() = 0;
// Stops execution, returns 'false' if already stopped.
virtual bool stop() = 0;
virtual ~Processor() = default;
};
void Processor::start() {
std::cout << "unsupported";
}
class MyProcessor : public Processor {
public:
void start() override {
// call default implementation
Processor::start();
}
};Let's return to the destructor that calls stop(). What shall we do here?
There are two approaches.
First, the implementing interface needs to have its own version of the destructor that will stop things the right way.
We can't force developers to check this at compile time. We could highlight what we want by declaring the interface destructor as purely virtual. However, this won't help because if the destructor isn't specified, it's always generated.
class Processor {
public:
virtual void start() = 0;
// Stops execution, returns 'false' if already stopped.
virtual bool stop() = 0;
virtual ~Processor() = 0;
};
// required!
Processor::~Processor() = default;
class MyProcessor : public Processor {
public:
void start() override {
}
bool stop() override { return false; }
// Missing destructor does not trigger CE.
// ~MyProcessor() override = default;
};
int main() {
MyProcessor p;
}Second, we can add another layer, using it in all public APIs.
class GuardedProcessor {
std::unique_ptr<Processor> proc;
// ....
~GuardedProcessor() {
assert(proc != nullptr);
proc->stop();
}
};The cherry on the cake is that if we play with the object deinitialization, it's easy to duplicate resource release operations.
We needed to create a class hierarchy to manage some resources. We didn't know in advance what class would be created during program execution. We armed ourselves with polymorphism, wrote the virtual destructor, and called functions only via pointers to the base class.
Let's start with the simplest base class.
#include <memory>
#include <iostream>
class Resource
{
public:
void Create() {}
void Destroy() {}
};
class A
{
std::unique_ptr<Resource> m_a;
public:
void InitA()
{
m_a = std::make_unique<Resource>();
m_a->Create();
}
virtual ~A()
{
std::cout << "~A()" << std::endl;
if (m_a != nullptr)
m_a->Destroy();
}
};
int main()
{
std::unique_ptr<A> p = std::make_unique<A>();
}It's all good so far. The running online example outputs:
~A()Then requirements change! Sometimes we need to reset the object status, i.e. release resources, without calling the destructor. Well, the base class interface will get the handy virtual function.
class A
{
std::unique_ptr<Resource> m_a;
public:
void InitA()
{
m_a = std::make_unique<Resource>();
m_a->Create();
}
virtual void Reset()
{
std::cout << "A::Reset()" << std::endl;
if (m_a != nullptr)
{
m_a->Destroy();
m_a.reset();
}
}
virtual ~A()
{
std::cout << "~A()" << std::endl;
Reset();
}
};
int main()
{
std::unique_ptr<A> p = std::make_unique<A>();
}~A()
A::Reset()There's the virtual Reset function that releases resources. To avoid duplicating code, the destructor now stopped releasing resources and just called the function.
As we saw earlier, it's not a good idea to call virtual functions in the destructor. It's okay. The function isn't merely virtual. See no problem yet.
Add a new derived class. It'll have its own resources on top of the existing ones in the base class. We should also remember to release them in the Reset function.
class A
{
std::unique_ptr<Resource> m_a;
public:
void InitA()
{
m_a = std::make_unique<Resource>();
m_a->Create();
}
virtual void Reset()
{
std::cout << "A::Reset()" << std::endl;
if (m_a != nullptr)
{
m_a->Destroy();
m_a.reset();
}
}
virtual ~A()
{
std::cout << "~A()" << std::endl;
Reset();
}
};
class B : public A
{
std::unique_ptr<Resource> m_b;
public:
void InitB()
{
m_b = std::make_unique<Resource>();
m_b->Create();
}
void Reset() override
{
std::cout << "B::Reset()" << std::endl;
if (m_b != nullptr)
{
m_b->Destroy();
m_b.reset();
}
A::Reset();
}
~B() override
{
std::cout << "~B()" << std::endl;
Reset();
}
};
int main()
{
std::unique_ptr<A> p = std::make_unique<B>();
p->Reset();
std::cout << "------------" << std::endl;
p->InitA();
}B::Reset()
A::Reset()
------------
~B()
B::Reset()
A::Reset()
~A()
A::Reset()If we explicitly call the Reset function from the external code, everything operates as intended. B::Reset() is called. Then it calls the same-named function from the base class.
Something unexpected occurs in destructors. Each destructor uses the Reset of its own class, which generates a redundant call.
If we continue to inherit further and override destructors and the Reset function, we'll just make things worse. More and more redundant calls.
Here's the code output with the new class added in:
C::Reset()
B::Reset()
A::Reset()
------------
~C()
C::Reset()
B::Reset()
A::Reset()
~B()
B::Reset()
A::Reset()
~A()
A::Reset()It's clear that there's a design flaw in the class. It's obvious to us now, though. In a real project, these kinds of errors can go pretty much unnoticed. The code and the Reset functions operate as intended. The issue is redundancy and inefficiency.
When a developer recognizes this issue and attempts to address it, they may make two other common mistakes.
The first mistake. Declare the Reset functions as non-virtual and don't call base (x::Reset) variants in them. Then each destructor will call only the Reset function from its class and release only its resources. Indeed, this will remove repeated calls in destructors, but object state reset will be broken when Reset is called externally. The broken code will output:
A::Reset() // Broken external resource release
------------
~C()
C::Reset()
~B()
B::Reset()
~A()
A::Reset()The second mistake. Call the Reset virtual function once only in the base class destructor. According to C++ rules, this will lead to leaks because the Reset function will be called in the base class rather than in the subclasses. This makes sense because by the time the ~A() destructor is called, all derivatives will be destroyed, and their functions can't be called. The broken code will output:
C::Reset()
B::Reset()
A::Reset()
------------
~C()
~B()
~A()
A::Reset() // Leak! Only resources in the base class are releasedThis example is based on a real error case that PVS-Studio found in the qdEngine engine. These are the real pitfalls. Be watchful when designing such classes.
How to correctly implement classes to avoid multiple redundant calls?
We need to separate the cleaning of resources in classes from the interface to clean them externally.
It's better to let data member destructors release resources rather than write ~A(), ~B(), and ~C() destructors. But this isn't always feasible: types for some data members may be provided by the library we can't fix, and we don't have time to create additional wrappers.
We should create non-virtual functions that are only responsible for releasing data in the classes where they're declared. Let's call them ResetImpl and make them private, as they're not intended for the external use.
Then destructors can simply delegate their options to the ResetImpl functions.
The Reset function will remain public and virtual. It'll release the data of all classes using the same ResetImpl auxiliary functions.
Let's consolidate everything and write correct code:
class A
{
std::unique_ptr<Resource> m_a;
void ResetImpl()
{
std::cout << "A::ResetImpl()" << std::endl;
if (m_a != nullptr)
{
m_a->Destroy();
m_a.reset();
}
}
public:
void InitA()
{
m_a = std::make_unique<Resource>();
m_a->Create();
}
virtual void Reset()
{
std::cout << "A::Reset()" << std::endl;
ResetImpl();
}
virtual ~A()
{
std::cout << "~A()" << std::endl;
ResetImpl();
}
};
class B : public A
{
std::unique_ptr<Resource> m_b;
void ResetImpl()
{
std::cout << "B::ResetImpl()" << std::endl;
if (m_b != nullptr)
{
m_b->Destroy();
m_b.reset();
}
}
public:
void InitB()
{
m_b = std::make_unique<Resource>();
m_b->Create();
}
void Reset() override
{
std::cout << "B::Reset()" << std::endl;
ResetImpl();
A::Reset();
}
~B() override
{
std::cout << "~B()" << std::endl;
ResetImpl();
}
};
class C : public B
{
std::unique_ptr<Resource> m_c;
void ResetImpl()
{
std::cout << "C::ResetImpl()" << std::endl;
if (m_c != nullptr)
{
m_c->Destroy();
m_c.reset();
}
}
public:
void InitC()
{
m_c = std::make_unique<Resource>();
m_c->Create();
}
void Reset() override
{
std::cout << "C::Reset()" << std::endl;
ResetImpl();
B::Reset();
}
~C() override
{
std::cout << "~C()" << std::endl;
ResetImpl();
}
};
int main()
{
std::unique_ptr<A> p = std::make_unique<C>();
p->Reset();
std::cout << "------------" << std::endl;
}C::Reset()
C::ResetImpl()
B::Reset()
B::ResetImpl()
A::Reset()
A::ResetImpl()
------------
~C()
C::ResetImpl()
~B()
B::ResetImpl()
~A()
A::ResetImpl()We can't say that's pretty, though. Too many letters A, B, C—too easy to misspell. Let's excuse this for synthetic examples. Verbosity triumphs—redundancy carries a fatality!
As we know, in C and C++, memory for objects can be allocated on the stack or in the heap. It's usually allocated automatically on the stack, and we don't have to worry about it too much.
int32_t foo(int32_t x, int32_t y) {
int32_t z = x + y;
return z;
}When the foo function is called, 4 more bytes will be allocated on the stack for the z variable right after the arguments. It's worth noting that the arguments may not be passed through the stack. To allocate extra bytes, a simple shift of the pointer to the top of the stack is performed. By the way, memory allocation can be even more—who knows what settings the compiler has! Maybe it won't be allocated. For instance, if the compiler optimizes the variable and puts the result immediately into the rax register. The wildlife is amazing, isn't it?
The memory is always automatically deallocated from the stack. Unless we accidentally broke the stack, embedded a monstrous assembly code and now the return address leads to the incorrect place. Or we use attribute ( ( naked ) ). But it seems that we have much more serious problems. In all other cases, memory is automatically released on the stack. As we know, such code generates a dangling pointer:
int32_t* foo(int32_t x, int32_t y) {
int32_t z = x + y;
return &z;
}To allocate something on the stack, the size should be known in advance at compile time. Usually but not always...
Once upon a time, one large and complex HTTP server suddenly crashed. Oddly, it crashed with a lovely segmentation fault (core dumped) message. However, developers were used to it because the HTTP server was written in pure and neat C. So, the crash was something that went without saying.
The core file elements were enigmatic. The line indicated by the dump didn't seem to be doing anything wrong. It wasn't dereferencing a pointer, writing to an array, reading from an array, allocating memory, or deallocating memory—nothing at all. It merely attempted to call a function and passed parameters to it. Something went wrong.
The issue was a stack overflow.
But how?! The core dump only showed a mere 40 stack frames! How could it run out? It had 10 MB for Linux!
As I scrolled through the stack trace, I noticed that the first five frames were relatively small—40 bytes, 180 bytes, kilobyte, etc. But then, the sixth frame was enormous—8 megabytes!
Upon opening the source code, I discovered:
int encoded_len = request->content_len * 4 / 3 + 1;
char encoded_buffer[encoded_len];
encoded_len =
encode_base64(request->content, content_len,
encoded_buffer, encoded_len);
process(encoded_buffer, enconded_len);Meet a variable-length array (VLA)! It's a handy C-based feature. It exists in C++ as a non-standard extension—MSVC doesn't support it, but it compiles in GCC and Clang.
This is a variable-length array on the stack. It was obvious what caused the crash.
Conceptually, the VLA is a functional feature, yet unsafe. Let's say we need a buffer, but we can only get it at runtime. Meet the VLA! Do we need malloc/new? Just declare an array and specify the length! Plus, it's usually faster than malloc, and it won't leak—it's automatically deallocated! What could be better than getting a segfault instead of an out-of-memory?
Only direct use of alloca() can be better than the VLA. Unlike the VLA, it has much more pitfalls, making it much easier to shoot ourselves in the foot.
void fill(char* ptr, int n) {
for (int i =0;i<n;++i) {
ptr[i] = i * i;
}
}
int use_alloca(int n) {
char* ptr = (char*)alloca(n);
fill(ptr, n);
return ptr[n-1];
}
int main() {
int n = 0;
for (int i = 1; i < 10000; ++i) {
n += use_alloca(i);
}
return n ? 0 : 1;
}Here, each call to alloca doesn't cause a stack overflow. If the compiler inlines use_alloca for any reason, it could lead to a SIGSEGV.
Another great thing is that the alloca function call can be hidden somewhere, and we may not even realize we use it. For example, alloca is used within the A2W string conversion macro in the ATL library. It seems like we just convert strings in the loop. Everything even works, as long as the strings are few and short—wow, we encounter a stack overflow. If we don't know this nuance in the macro, it's almost impossible to find it, for example, on a code review. Okay, PVS-Studio will warn us about the alloca usage in the loop. It's really tricky, though.
The alloca and VLA usage isn't so recommended. Some coding standards (e.g., MISRA C) disallowed VLAs.
Well, the man website mentions a case where its usage may be worthwhile: our code relies on setjmp/longjump, and regular management of dynamically allocated memory may be hampered. The stack will still be released even with longjmp. What do we need it for? Whatever.
Indeed, alloca and VLAs can be faster than dynamic memory allocation (new, malloc). If we need to be really quick, using a reallocated array or a fixed-length array is usually will be better option.
Here's the code:
#include <vector>
#include <alloca.h>
int calc(char* arr, int n) {
for (int i = 0; i < n; ++i) {
arr[i] = (i * i) & 0xFF;
}
return arr[n-1];
}
int test_vla(int n) {
char arr[n];
return calc(arr, n);
}
int test_dyn(int n) {
std::vector<char> v(n);
return calc(v.data(), n);
}
int __attribute__ ((noinline)) test_alloca(int n) {
char* arr = (char*)alloca(n);
return calc(arr, n);
}
int test_fixed(int n) {
char arr[10005];
return calc(arr, n);
}
static void VLA(benchmark::State& state) {
// Code inside this loop is measured repeatedly
int size = 10000;
for (auto _ : state) {
if (size < 10005) {
size += 1;
}
benchmark::DoNotOptimize(test_vla(size));
}
}
// Register the function as a benchmark
BENCHMARK(VLA);
static void ALLOCA_TEST(benchmark::State& state) {
// Code inside this loop is measured repeatedly
int size = 10000;
for (auto _ : state) {
if (size < 10005) {
size += 1;
}
benchmark::DoNotOptimize(test_alloca(size));
}
}
// Register the function as a benchmark
BENCHMARK(ALLOCA_TEST);
static void DYN(benchmark::State& state) {
// Code before the loop is not measured
int size = 10000;
for (auto _ : state) {
if (size < 10005) {
size += 1;
}
benchmark::DoNotOptimize(test_dyn(size));
}
}
BENCHMARK(DYN);
static void FIXED(benchmark::State& state) {
// Code inside this loop is measured repeatedly
int size = 1;
char fixed[10005];
for (auto _ : state) {
if (size < 10005) {
size += 1;
}
benchmark::DoNotOptimize(calc(fixed, size));
}
}
// Register the function as a benchmark
BENCHMARK(FIXED);
static void FIXED_LOCAL(benchmark::State& state) {
// Code inside this loop is measured repeatedly
int size = 1;
for (auto _ : state) {
if (size < 10005) {
size += 1;
}
benchmark::DoNotOptimize(test_fixed(size));
}
}
// Register the function as a benchmark
BENCHMARK(FIXED_LOCAL);Now let's look at some charts.
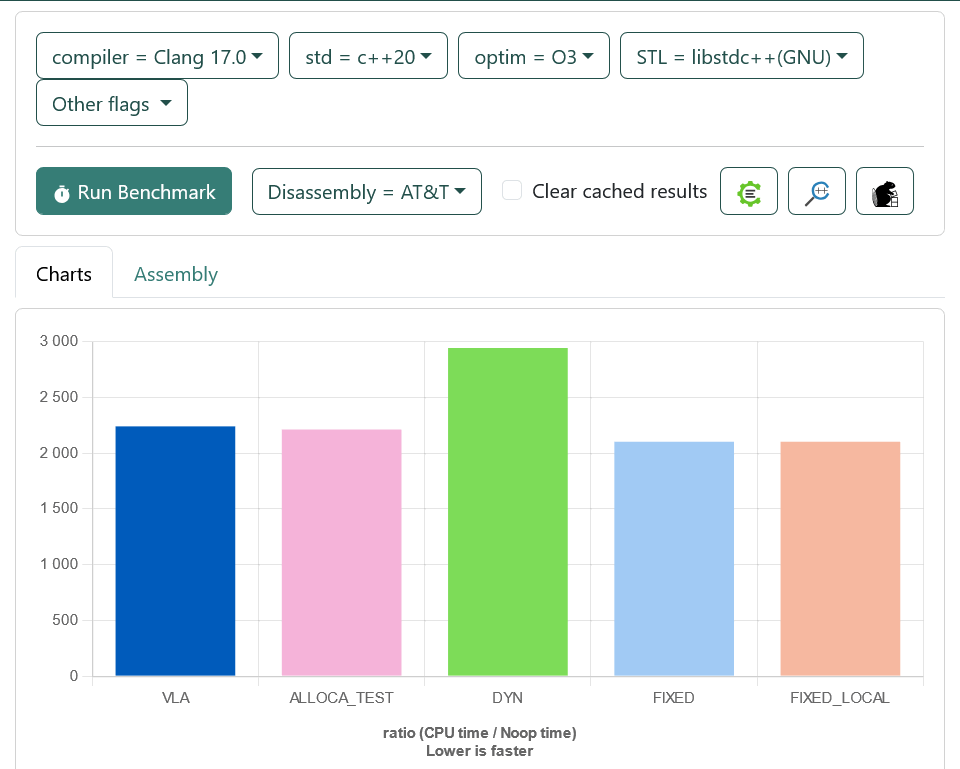
There is no VLAs in C++ (without extensions). There are templates there, and they're not friends with VLAs.
#include <iostream>
template <size_t N>
void test_array(int (&arr)[N]) {
std::cout << sizeof(arr) << "\n";
}
int main(int argc, char* argv[]) {
int fixed[15];
int vla[argc];
test_array(fixed);
test_array(vla); // Compilation error!
}Earlier, I generally covered ODR violations and warned about what can happen if we accidentally choose the wrong variable, structure, or function name in C++. Here, I'd like to show a niftier example that doesn't require any effort to write spaghetti code. All we need is the spaghetti code in our third-party dependencies.
Recently, I dealt with a particularly bizarre bug report:
In the internal repository with packages, the package with GTest library—a well-known, respected library for writing all kinds of tests in C++—was updated. As an update result, some tests suddenly started failing in end-user applications.
They started to fail in different ways: some of them started to fail at checking asserts, while others had everything working, and checks passed, but ctest reported that the testing process exited with a non-zero return code.
If something ridiculous was going on with the first one, the second one could be worked with.
Manually run test: 5/5 passed. Segmentation Fault. Ah!
Running the test via the debugger and outputting the backtrace, I got something as follows:
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff7e123fe in __GI___libc_free (mem=0x55555556a) at
./malloc/malloc.c:3368
3368 ./malloc/malloc.c: No such file or directory.
(gdb) bt
#0 0x00007ffff7e123fe in __GI___libc_free (mem=0x55555556a) at
./malloc/malloc.c:3368
#1 0x00007ffff7fb75ea in
std::vector<std::__cxx11::basic_string<char, std::char_traits<char>,
std::allocator<char> >,
std::allocator<std::__cxx11::basic_string<char,
std::char_traits<char>, std::allocator<char> > > >::
~vector() () from ./libgtest.so
#2 0x00007ffff7db2a56 in __cxa_finalize (d=0x7ffff7fb5090) at
./stdlib/cxa_finalize.c:83
#3 0x00007ffff7fb2367 in __do_global_dtors_aux () from
./libgmock.so
__do_global_dtors_aux () from ./libgmock.soSomething both terrible and beautiful happened at the same time; all that remained was to uncover the root cause.
I examined the tests: they were grouped in separate sources, and each was compiled into its own executable file. All tests were built with the same compilation parameters, which were simply configured in CMake:
file(GLOB files "*_test.cpp")
foreach(file ${files})
add_test(...., ${file})
endforeach()I opened sources for both the crashing and non-crashing tests: the crashing test used gMock, and the non-crashing test didn't. However, both executables were linked with the libgmock.so library.
Let's look at the backtrace snippet again:
std::allocator<char> > > >::~vector() () from ./libgtest.so
#2 0x00007ffff7db2a56 in __cxa_finalize (d=0x7ffff7fb5090) at
./stdlib/cxa_finalize.c:83
#3 0x00007ffff7fb2367 in __do_global_dtors_aux ()
from ./libgmock.soThe finalization of global objects in libgmock has something to do with the global variable destructor in libgtest.
I opened the changelog. What's updated in the internal package with GTest...?
Commit: ...
Produce shared libraries along with staticsExactly two lines that added the dynamic versions of libgmock and libgtest libraries to its CMakeLists.txt.
Hmm... Interesting case. I went online with this question and found a very similar case. First, checking the issue date and the commit dates in the internal version, I was deeply frustrated with the pace of dependency updates—it was late 2023, yet the issue was dated back to 2016. However, that's the C++ issue for another discussion...
What really happened?
The GoogleTest framework consisted of two libraries:
gMock links to GTest. The final user executable with tests is linked to both libraries.
At first glance, this seems harmless.
However, GTest actively relies on global variables to support the beauty of automatic test and fixture registration. As users, we don't have to put test functions anywhere, we just declare them using macros.
As you can see from the backtrace, the problematic object whose destructor caused the crash was a vector of strings in libgtest.so. In GTest sources, I found that this vector is a global variable where InitGoogleTest() stored recognized command line arguments. It's just a global variable declared in the compiled file and not presented in the header file. All seemed fine, except for one detail: it wasn't marked as static and was not wrapped in an anonymous namespace.
So what? It worked, didn't it? Yeah, it worked. The trick was how the gMock library is built. Let's reproduce it step by step.
We used GTest here.
// gtest.h
#pragma once
void initGoogleTest(int argc, char* argv[]);
void runTests();
// gtest.cpp
#include "gtest.h"
#include <vector>
#include <string>
#include <iostream>
// Global variable,
// not static as it was in gtest
std::vector<std::string> g_args;
void runTests() {
// Just for demonstration.
std::cout << "run gtest\n";
for (const auto& arg : g_args) {
std::cout << arg << " ";
}
std::cout << "\n";
}
void initGoogleTest(int argc, char* argv[]) {
for (int i = 0; i < argc; ++i) {
g_args.push_back(argv[i]);
}
}Let's place it into a static library because static libraries were originally used in the package.
g++ -std=c++17 -fPIC -O2 -c gtest.cpp
ar rcs libgtest.a gtest.oAdd our gMock
// gmock.h
#pragma once
void runMocks();
// gmock.cpp
#include "gmock.h"
#include "gtest.h" // gmock is linked to gtest!
#include <iostream>
void runMocks() {
// For clarity
std::cout << "run Mocks:\n";
runTests();
}Let's place it into a static library as well.
g++ -std=c++17 -fPIC -O2 -c gmock.cpp
ar rcs libgmock.a gmock.o gtest.o #Then run it.
// main.cpp
#include "gtest.h"
#include "gmock.h"
int main(int argc, char* argv[]) {
initGoogleTest(argc, argv);
runMocks();
runTests();
return 0;
}g++ -std=c++17 -O2 -o main main.cpp -L . -lgtest -lgmock
./main 1 2 3 4
run Mocks:
run gtest
./main 1 2 3 4
run gtest
./main 1 2 3 4Obviously, if we linked both the GTest and gMock libraries, an ODR violation occurred because gMock includes GTest. So, we had two instances of the global variable. But it still worked: the linker effectively eliminates one of the copies.
Now let's add dynamic versions.
g++ -shared -fPIC -o libgtest.so gtest.o
g++ -shared -fPIC -o libgmock.so gtest.o gmock.oThen rebuild the client code.
g++ -std=c++17 -O2 -o main main.cpp -L . -lgtest -lgmock
LD_LIBRARY_PATH=. ./main
run Mocks:
run gtest
./main
run gtest
./main
Segmentation fault (core dumped)Oh no! Crash! Both libraries had their own version of the global variable, each with the same implicitly exported name. Again, we used only one version. Once we have loaded the library and constructed a global variable, according to the C++ standard, we should register a function to call the destructor, e.g. via __cxa_atexit. Since we had two libraries, two functions were called—on a single object. Oh no again! Double free error! By the way, the constructor was also called twice at the same address:
struct GArgs : std::vector<std::string> {
GArgs() {
std::cout << "Construct it: " <<
uintptr_t(this) << "\n";
}
};
GArgs g_args;
LD_LIBRARY_PATH=. ./main 1 2 3
Construct it: 140368928546992
Construct it: 140368928546992
run Mocks:
run gtest
./main 1 2 3
run gtest
./main 1 2 3
Segmentation fault (core dumped)This was great—we knew what the issue was. Falling assertion tests were also suffered from other global variables. Interestingly, while all tests were built in the same way, some didn't crash. Specifically, those that didn't used gMock, but still linked with it.
Let's comment our gMock.
#include "gtest.h"
#include "gmock.h"
int main(int argc, char* argv[]) {
initGoogleTest(argc, argv);
// runMocks();
runTests();
return 0;
}
g++ -std=c++17 -O2 -o main main.cpp -L . -lgtest -lgmock
LD_LIBRARY_PATH=. ./main 1 2 3
Construct it: 140699707998384
run gtest
./main 1 2 3Oh! The constructor was called once, and the destructor would be called once, too. Everything's great. We linked it, didn't we? Modern linkers were smart enough not to link useless things (which, by the way, is sometimes a problem if the constructors in the library have side effects).
If we forced GCC to link gMock.
g++ -std=c++17 -O2 -o main main.cpp
-Wl,--no-as-needed -L . -lgtest -lgmock
LD_LIBRARY_PATH=. ./main 1 2 3
Construct it: 139687276064944
Construct it: 139687276064944
run gtest
./main 1 2 3
Segmentation fault (core dumped)Everything will be broken, as it should.
This kind of trouble-making pattern is be incredibly common—and not only in C++!
LibA was statically linked into LibB and both LibA and LibB were linked into BinC. Memory management libraries were often used for such a LibA.
For example, when building dynamic libraries in Rust and linking them into other projects, devs frequently encounter this problem: the std is statically linked into both the library and the executable.
I also see similar problems in the AWS SDK: the global UniquePtr also ended up in the final application in two ways, so developers put zeroing in the destructor to avoid calling the delete twice.
Author: Dmitry Sviridkin
Dmitry has over eight years of experience in high-performance software development in C and C++. From 2019 to 2021, Dmitry Sviridkin has been teaching Linux system programming at SPbU and C++ hands-on courses at HSE. Currently works on system and embedded development in Rust and C++ for edge servers as a Software Engineer at AWS (Cloudfront). His main area of interest is software security.
Editor: Andrey Karpov
Andrey has over 15 years of experience with static code analysis and software quality. The author of numerous articles on writing high-quality code in C++. Andrey Karpov has been honored with the Microsoft MVP award in the Developer Technologies category from 2011 to 2021. Andrey is a co-founder of the PVS-Studio project. He has long been the company's CTO and was involved in the development of the C++ analyzer core. Andrey is currently responsible for team management, personnel training, and DevRel activities.
0
0
0

0