
Our website uses cookies to enhance your browsing experience.

In 2022, the PVS-Studio static analyzer for C and C++ turns 16 years old. If the analyzer were a human, it would have already finished high school! This project was started a long time ago, and since then its type system has not almost changed. In this article, we will look at the analyzer over time — what required improvements and how we went about it.

Year 2005 welcomed many significant releases — you've probably heard of games like "God of War", "Resident Evil 4" and "Prince of Persia: The Two Thrones". The Visual C++ 8.0 compiler also came out. Aside from the C++/CLI and OpenMP extensions' support, the compiler got another important feature — the ability to compile code for 64-bit x86-compatible processors.
Migrating an application to the 64-bit architecture was challenging. You couldn't just recompile your program so that it ran on 64-bit systems. Most programs of that time were created for 32-bit systems and could, for example, store pointers in int variables that are not enough for 64-bit pointers. You can learn more about 64-bit error patterns here.
Debugging such errors is quite the challenge. Since unit tests deal only with small amounts of data, they are likely to indicate no problems. Most likely, there is no chance to test how an application processes large amounts of data:
However, tools that can parse C and C++ programming languages find such errors easily. The first version of our analyzer (Viva64) dealt with this exactly — looked for 64-bit errors. Later, we added other useful features — general analysis diagnostics, data flow analysis, Linux support, etc. If you would like to dive deeper into the analyzer's history, click here.
Of course, it is almost impossible to develop a C and C++ analyzer from scratch because of how complex these programming languages are. That's why we decided to use a library as a basis. There were few alternatives available at that time:
PVS-Studio is based on OpenCxx, a library for refactoring C++ code and developing C++ tooling and extensions. The library worked as an intermediary between the preprocessor and compiler, and provided an API based on metaobjects. Let's look at some implementation details.
The syntax tree is represented by the Ptree class. It is a binary parse tree, that contains leaf nodes (external nodes) and non-leaf nodes (internal nodes). Non-leaf nodes are used to link the nodes.
The tree is first built at the parsing stage. Then it is recreated while the translator works (Walker class). The translator processes the semantics of the programming language. Recreating the tree helps to handle the following syntactic ambiguities:
We can parse them in different ways. The first case could mean a multiplication of the A and B variables or a declaration of a pointer to the type A. The second case — a function call or a variable declaration. The third case could be a template or comparison.
The utility functions (First, Second, Third, ..., Nth) are the only way to work with the tree. They take a node of a subtree at a specified position. For example, to take the left-hand operand of the A + B binary expression, you need to call the First function. Calling the Third function will return the right-hand operand. Calling the Second function will return the binary additive arithmetic operator.
The tree nodes lack interfaces. This complicates extending the tree and makes reading and writing code without debugger almost impossible. The two-pass translation system often causes problems, since it is necessary to consider the moment when the tree is recreating.
The library's type system consists of two components — Encoding and TypeInfo. The Encoding class wraps a string that encodes a type. Encoding mainly serves to form this string. TypeInfo, on the contrary, is a class used to work with the string. The class can extract information from the string and resolve aliases, but cannot modify the string.
For example, here's how a pointer to a type is encoded:
int *p; // PiFunctions are encoded in a special way — the character 'F' that denotes the function goes first, followed by parameters. What might seem quite unusual is that they are written as a single word. You can determine the end of each parameter only by going through all the contents: pointers, references, and cv-qualifiers. The return value is separated by the '-' character:
int main(int argc, const char **argv); // FiPPCc-iUser-defined types are the most complicated to work with. First, a special Encoding instance that contains the name of a class is formed:
class MyClass; // \x80MyClassLet's look at the '\x80' character. It is a special character that encodes the length of each subsequent string. However, the Encoding type fails to encode the whole information about the user-defined type. Therefore, Encoding associates with the related object of the Class class. TypeInfo, mentioned above, is used to set the relationship.
All the characters used to encode a type are listed below:
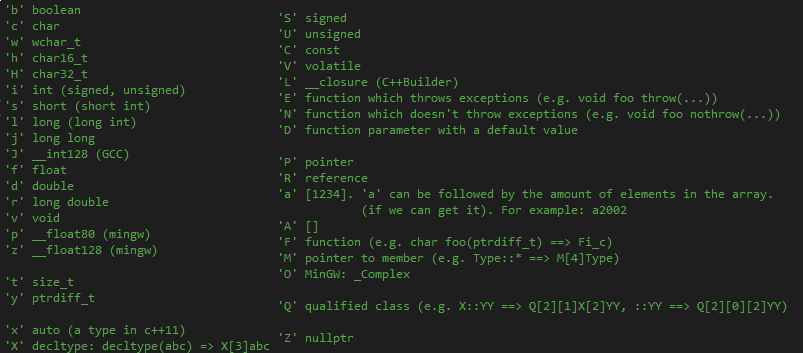
By the way, above you can see a fragment of the updated encoding system. Of course, when the library was created, there were no 'x' (auto), 'L' (__closure), and so on.
Obviously, this data structure complicates working with types. In addition, it has some performance issues. Over time, adding a new type becomes more and more difficult, because the alphabet is gradually running out. But we want to provide high-quality analysis.
As an alternative, we designed a light-weight structure - WiseType. WiseType contains basic information about the type — for example, that a tree node is a pointer to int or some class. However, WiseType cannot provide the information on the type that is deeper than the second pointer, neither it can help identify specific type of a class.
Of course, you can try to rewrite OpenCxx, but is it worth it? After all, there is something specifically made for that purpose...
Clang is a fast-paced and user-friendly front-end that supports modern C++ standards.
It is important to note that Clang had not yet been created in 2005, although we already intended to implement the analyzer. So, we had to use what we had. The first version of our project was released in July 2007, and the first version of the self-hosting compiler was released only in 2010.
It is also difficult to migrate our project from OpenCxx to Clang, because a large amount of code depends on OpenCxx (the data flow mechanism, lots of diagnostic rules, etc.). In addition, Clang is developed independently. It does not support language dialects (such as C++/CLI or C++/CX) and various features of embedded compilers. Any modifications would lead to painful merge conflicts for each release.
It all makes migrating to Clang impossible.
Over time new standards were released. So, we needed to support C++11, C++14, C++17, and recently released C++20. Moreover, we have an upcoming C++23! C++ kept getting new features, and our team kept growing. So, it was the right moment to start solving problems described above and remove kludges from various places.
First, we'll discuss improvements with our tree that we have already completed. And then, we're going to talk about our new type system that we've implemented recently.
Some information that we moved out of Ptree, is mixed in particular children now. This reduces the size of the base Ptree class, e.g. WiseType used to be inside this class and, accordingly, appeared in each node of the tree.
So far, there are only 2 types of additional data:
Now the size of the base Ptree class is as small as possible, and children contain only the necessary information. So, all expressions' nodes are now inherited from the PtreeExpr class, and this class is inherited from PtreeValue. The nodes that contain the declared classes are inherited from PtreeTyped.
We also implemented interfaces for nodes, so that we don't need to check the node type every time we access it via First, Second, etc. The binary expression interface looks as follows:
GetLeftOperand and GetRightOperand return PtreeExpr, not only Ptree.
While we implemented interfaces for tree nodes, we decided to refactor our diagnostic rules that use these nodes. This will help to reimplement the current tree structure in the future (now the tree is tied by the positions of the nodes inside). In addition, the interfaces make the code clearer, and now it's easier to implement diagnostic rules.
Implementing a new type system was quite a challenge, but we did it! PVS-Studio 7.18 got brand new type system. Finally, we have achieved efficient performance and committed changes to the main branch.
In the earlier PVS-Studio versions, all types were implemented in a single data structure — a character string. Now we have a certain hierarchy of classes. We can store anything there, not only characters but also references to AST nodes. Also, each type contains a reference to the canonical type — without typedef, using and some other information. The canonical type is evaluated immediately after a new type has been created. So, we don't have to waste time on resolving of a raw type when we need it (and we need it nearly always).
Another feature of the new type system is the way cv-qualifiers are stored. They are stored in the higher bits of the pointer. These bits are not used on modern systems. However, it's better to reset these bits, if we intend to dereference such a pointer. Despite this difficulty, this way helps reduce memory consumption and improve performance while we use cv-qualifiers. Processor engineers are aware of such tricks, so now Intel/AMD create their own extensions (Intel Linear Address Masking, AMD Upper Address Ignore) to stop using these bits and save a couple of clock cycles for dereferencing. By the way, Clang has qualifiers that are stored in a similar way.
To migrate to the new type system, we needed some kind of compatibility layer to prevent breaking the existing code.
As we said earlier, Encoding is used to form types. It is difficult to rewrite the parser (because it creates the initial information about types) without breaking anything along the way. That's why we created a converter to transform an encoding to a type in our new implementation. This converter is a temporary solution, because we plan to migrate to the new system for all stages of the analyzer.
It's easier to use the TypeInfo class — we only need to implement its interface and everything would work. However, some functions are difficult to implement, or almost impossible. For example, a function that is used to obtain an underlying string with an encoded type. Therefore, in some places we'll have to look at the code and rewrite it a little.
We did a great job — we've implemented the type system and tree interfaces. However, to feel completely satisfied we need to do more.
As I already mentioned, our analyzer's core now performs semantic and syntactic analysis of a file separately. This is a wrong solution for the C++ programming language, or even for C. It makes almost impossible to construct the tree correctly. We need to know what the identifier is — a type, a variable, or something we meet for the first time. The semantic analysis will have needed to perform at the parsing stage not in the walker.
We can't say that our current tree is abstract. Inside, each node contains a string with a token from a file, and the entire structure of the nodes is tied to the grammar. And the tree itself is binary — there are a lot of "garbage" non-leaf nodes. This harms walker performance and also increases memory consumption. We would like to change the structure of the tree to avoid this.
The last challenge that we face is template instantiations. All the templates are instantiated on the same tree. This leads to losing information on the original tree. After instantiating, the tree contains new types and virtual values. It's too expensive to save the information before instantiating, so after instantiating new types and virtual values are just "killed". Moreover, the walker may recreate the tree during the instantiation. As a result, the original tree may change. We want to make sure that the original tree is copied for each instantiation, and don't experience any changes.
I hope you found this story useful and interesting. Of course, Clang's tree and ours differ greatly still, but we have already started reworking and look forward to its completion. You can evaluate our work and test your own project — just request a trial key. If you encounter problems, feel free to contact us and describe your problem to our support team. We would be pleased to consider and resolve it.
0
0
0
0