
Our website uses cookies to enhance your browsing experience.

Starting from PVS-Studio 7.14, the C and C++ analyzer has been supporting intermodular analysis. In this two-part article, we'll describe how similar mechanisms are arranged in compilers and reveal some technical details of how we implemented intermodular analysis in our static analyzer.

Before we inspect intermodular analysis, let's remember how compilation works in the C and C++ world. This article focuses on various technical solutions for object module layout. We'll also see how well-known compilers use intermodular analysis and how it's related to Link Time Optimizations (LTO).
If you're an expert in this field, you'll probably like the second part of the article. There we'll describe our solutions and the problems we have encountered during the implementation. By the way, the author doesn't consider himself an expert of compilers. Constructive criticism is always welcome.
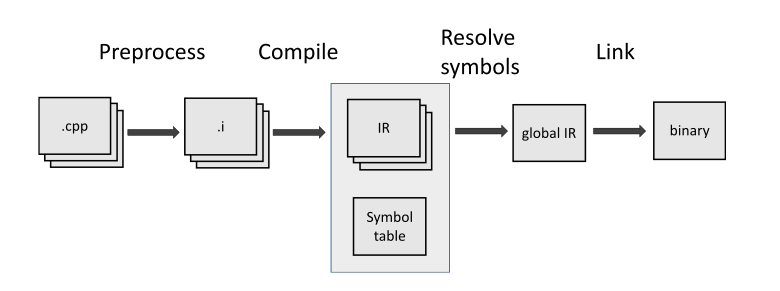
C and C++ projects are compiled in several steps.
Standards C18 (paragraph 5.1.1.2 "Programming languages — C") and C++20 (paragraph .5.2 "Working Draft, Standard for Programming Language C++") defined 8 and 9 phases of translation, respectively.
Let's omit the details and look at the translation process abstractly:
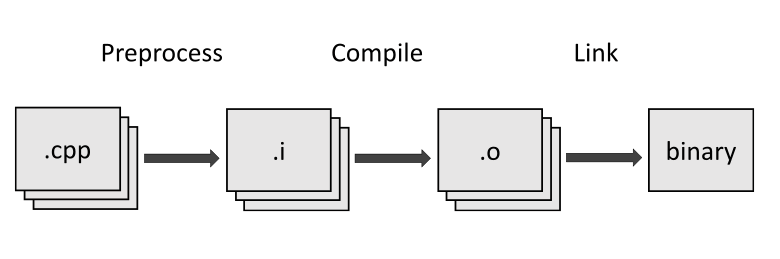
As you can see, the program is made of the translation units. Each of these units is compiled independently of the other. Because of this, each individual translation unit has no information about the others. Thus, all entities (functions, classes, structures, etc.) in C and C++ programs have declaration and definition.
Look at the example:
// TU1.cpp
#include <cstdint>
int64_t abs(int64_t num)
{
return num >= 0 ? num : -num;
}
// TU2.cpp
#include <cstdint>
extern int64_t abs(int64_t num);
int main()
{
return abs(0);
}The TU1.cpp has definition of the abs function, and the TU2.cpp file has its declaration and use. The linker determines which function is called if one definition rule (ODR) is not violated. ODR means limitation: each symbol should have only one definition.
To simplify the coordination of different translation units, a header file mechanism was created. This mechanism consists in declaring a clear interface. Later each translation unit, if necessary, will include a header file via the preprocessor #include directory.
When the compiler meets a declaration that doesn't have a corresponding definition in the translation unit, it has to let the linker do its work. And, unfortunately, the compiler loses some optimizations that it could have performed. This stage is performed by the linker and is called Link Time Optimizations (LTO). The linking goes by entity names, i.e. by identifiers, or symbols. At the same stage intermodular analysis is also performed.
The compiler has to merge different object files into one, while linking all the references in the program. Here we need to inspect the latter in more detail. We are talking about symbols — basically, symbols are identifiers that occur in the program. Look at the example:
struct Cat // <Cat, class, external>
{
static int x; // <Cat::x, object, internal>
};
Cat::x = 0;
int foo(int arg) // <foo(int), function, external>
{
static float symbol = 3.14f; // <foo(int)::symbol, object, internal>
static char x = 2; // <foo(int)::x, object, internal>
static Cat dog { }; // <foo(int)::dog, object, internal>
return 0;
}The compiler divides symbols into categories. Why? Not all symbols are supposed to be used in other translation units. We need to keep this in mind when linking. The same should be taken into account in static analysis. First, we need to determine which information to collect to share between modules.
The first category is linkage. Defines the symbol scope.
If a symbol has an internal linkage then the symbol can be referenced only in the translation unit where it is declared. If there is a symbol with the same name in another object module, this won't be a problem. But the linker will treat them as if they are different.
static int x3; // internal
const int x4 = 0; // internal
void bar()
{
static int x5; // internal
}
namespace // all symbols are internal here
{
void internal(int a, int b)
{
}
}If a symbol has an external linkage, then it is unique, intended for use in all program translation units, and will be placed in a common table. If the linker encounters more than one definition with an external linkage, it reports a violation of the one definition rule.
extern int x2; // external
void bar(); // externalIf a symbol doesn't have a linking type, then it will be visible only in the scope in which it is defined. For example, in a block of instructions that has its own scope (if, for, while, and so on).
int foo(int x1 /* no linkage */)
{
int x4; // no linkage
struct A; // no linkage
}The second category — storage duration. It is the identifier's property that defines the rules according to which an object is created and destroyed.
Automatic storage duration – the object is placed in memory at the time of its definition and is released when the context of the program execution leaves the object's scope.
Static storage duration defines the resources that will be placed in memory at the start of the program and released at its termination.
Objects created with thread storage duration will be placed in the memory of each thread separately from each other. This is useful when we create thread-safe applications.
And finally, dynamic storage duration. Defines the resources placed in dynamic memory. The most difficult case for compilers and static analyzers. Such objects won't be destroyed automatically. Resources with dynamic storage duration are managed via pointers. It is convenient to control such resources with the help of control objects that have their own storage duration, which are obliged to release them on time (the RAII idiom).
All symbols are saved in an object file in a special section in the table. And now it's time for object files.
As mentioned above, the compiler converts translation units into binary object files organized in a special way. Different platforms have different object file formats. Let's look at the structure of the most common ones.
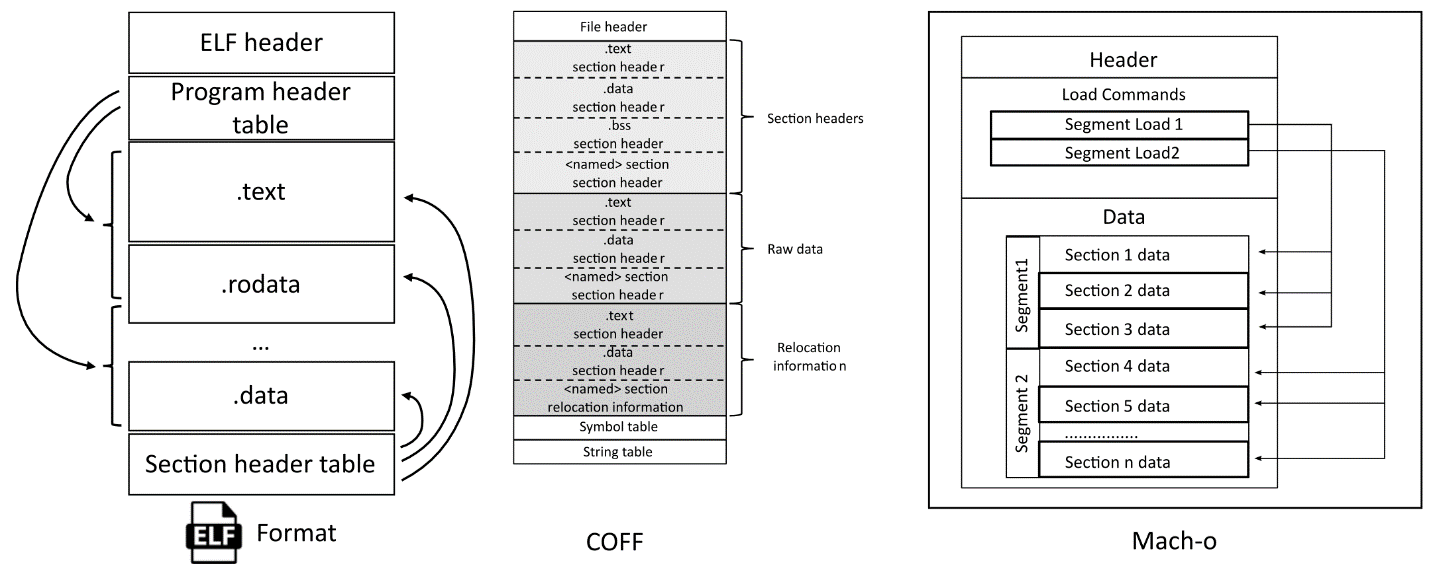
COFF was originally used on UNIX systems (.o, .obj) and didn't support 64-bit architectures (because they didn't exist at that time). Later it was replaced by the ELF format. With the development of COFF, Portable Executable (PE) appeared. This format is still used in Windows (.exe, .dll).
Mach-o is an object file format on macOS. It differs from COFF in structure, but it performs the same functions. This format supports code storage for different architectures. For example, a single executable file can store code for both ARM and x86 processors.
ELF is an object file format on Unix systems. A small spoiler: we were inspired by ELF when creating object semantic modules for PVS-Studio.
All three formats have a similar structure, so we will inspect the general idea of dividing into sections, which is used in them. Let's inspect ELF as an example. Note that it is intended for storing executable program code. Since we inspect it in terms of static analysis, not all its components are interesting to us.
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 688 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 12
Section header string table index: 1
There are 12 section headers, starting at offset 0x2b0:The header section contains information defining the file format: Magic, Class, Data, Version, etc. Besides, it contains information about the platform for which the file was generated.
Next in content is a list of header and program sections.
Section Headers:
[Nr] Name Type Off Size ES Flg Lk Inf Al
[ 0] NULL 000000 000000 00 0 0 0
[ 1] .strtab STRTAB 0001b9 0000a3 00 0 0 1
[ 2] .text PROGBITS 000040 000016 00 AX 0 0 16
[ 3] .rela.text RELA 000188 000018 18 11 2 8
[ 4] .data PROGBITS 000058 000005 00 WA 0 0 4
[ 5] .bss NOBITS 00005d 000001 00 WA 0 0 1
[ 6] .comment PROGBITS 00005d 00002e 01 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 00008b 000000 00 0 0 1
[ 8] .eh_frame X86_64_UNWIND 000090 000038 00 A 0 0 8
[ 9] .rela.eh_frame RELA 0001a0 000018 18 11 8 8
[10] .llvm_addrsig LLVM_ADDRSIG 0001b8 000001 00 E 11 0 1
[11] .symtab SYMTAB 0000c8 0000c0 18 1 6 8There are a lot of sections. For more information, see the ELF documentation. As an example, let's look at some of them:
Now, let's look at contents of the sections. Since we are inspecting the subject area from the side of intermodular analysis, we will focus on the symbol table.
Symbol table '.symtab' contains 8 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS sym.cpp
2: 0000000000000004 1 OBJECT LOCAL DEFAULT 4 foo(int)::x
3: 0000000000000000 1 OBJECT LOCAL DEFAULT 5 foo(int)::dog
4: 0000000000000000 4 OBJECT LOCAL DEFAULT 4 foo(int)::symbol
5: 0000000000000000 0 SECTION LOCAL DEFAULT 2 .text
6: 0000000000000000 22 FUNC GLOBAL DEFAULT 2 foo(int)
7: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND Cat::xIt consists of records that have a certain structure. This is the simplest database, convenient for multiple reads. Moreover, all data is aligned in memory. Thanks to this, we can simply load them into the structure to work with them further.
Some compilers use their own object file formats to store intermediate information there. These include the LLVM bitcode (.bc), which stores an intermediate representation of LLVM IR in binary format, or GCC Gimple (.wpo). All this information is used by compilers to implement Link Time Optimizations, in which intermodular analysis is also involved.
Let's move closer to the topic of the article. Before trying to implement anything, let's look at how similar tasks were solved in other tools. Compilers perform a large number of code optimizations. These include dead code elimination, loop unrolling, tail-recursion elimination, constant evaluation, etc.
For example, here you can read the list of available optimizations for GCC. I'm sure it will take you a few minutes only to scroll through this document. However, all conversions are performed within specific translation units. Because of this, some useful information is lost and, as a result, the effectiveness of optimizations is lost as well. Intermodular analysis is designed to solve this problem. It is successfully used in compilers for Link Time Optimizations. We have already briefly described the basic idea of how it works in the previous article.
The first compiler (my favorite one) — Clang. It belongs to the group of compilers that use LLVM for code generation. Such compilers have a modular architecture. Its scheme is shown in the picture:
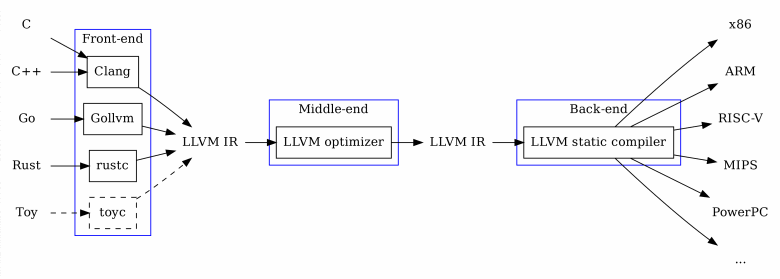
It contains three parts:
Such an architecture has many advantages. If you need to create your own compiler that will work on most architectures, you can just write your frontend for LLVM. Moreover, out of the box, you will have general optimizations, such as dead code elimination, loop unrolling, etc. If you are developing a new architecture, then in order to support a large set of popular compilers for it, you can implement only backend for LLVM.
Link Time Optimizations work at the intermediate representation level. Let's see an example of how it looks in a human-readable form:
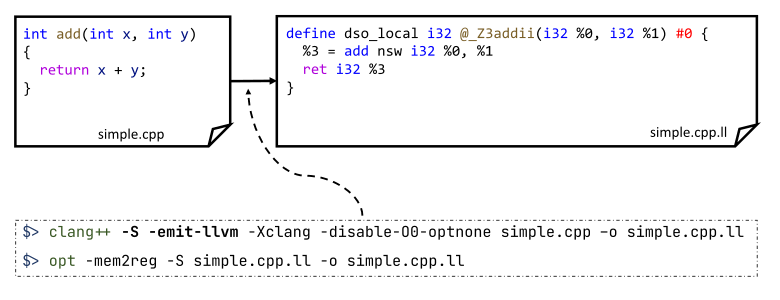
You can convert the simple.cpp source code file to an intermediate form using a special command. For the sake of the result's brevity, in the picture I also applied most of the optimizations that removed all unnecessary code. We are talking about converting the original version of the intermediate representation into an SSA form. If possible, any variable assignments are removed in it and initializations of virtual registers are replaced. Of course, after any transformations, the direct connection with the source code in C or C++ is lost. However, the external symbols significant for the linker will remain. In our example, this is the add function.
However, we're missing the point. Let's go back to Link Time Optimizations. The LLVM documentation describes 4 steps.
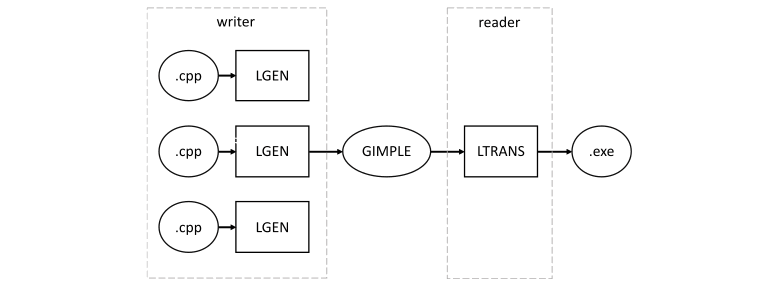
We can't forget about GCC — a set of compilers for C, C++, Objective-C, Fortran, Ada, Go, and D. It also has Link Time Optimizations. However, they are arranged a bit differently.
During translation, GCC also generates its intermediate representation — GIMPLE. However, unlike LLVM, GIMPLE is not stored as separate files, but next to the object code in a special section. Besides, it's more similar to the program's source code even though it's a separate language with its own grammar. Look at the example from the documentation.
To store GIMPLE, GCC uses the ELF format. By default, they contain only the program's bytecode. But if we specify the -ffat-lto-objects flag, then GCC will put the intermediate code in a separate section next to the finished object code.
In the LTO mode, object files generated by GCC contain only GIMPLE bytecode. Such files are called slim and are designed so that utilities such as ar and nm understand LTO sections.
In general, LTO to GCC is performed in two stages.
This approach works well on small programs. However, since all translation units are linked into one together with intermediate information, further optimizations are performed in one thread. Besides, we have to load the entire program into memory (not just the global symbol table), and this can be a problem.
Therefore, GCC supports a mode called WHOPR, in which object files are linked by pieces. The linking is based on a call graph. This allows us to perform the second stage parallelized and not load the entire program into memory.
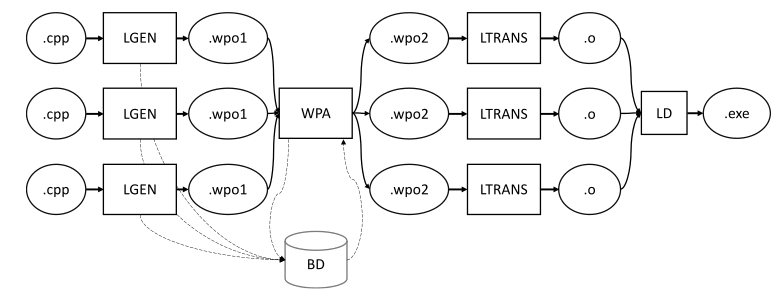
With this implementation, we can run LTO in parallel threads (with the exception of the WPA stage). We do not have to load large files into RAM.
A lot of things in this part of the article is just background information delivered from the point of view of the author. As noted in the beginning, the author isn't an expert in this subject. That is why it seems interesting to him to understand the peculiarities of the mechanisms written by great minds. Most of them are hidden behind tools that simplify the development. And this is certainly correct. However, it's useful to know what's going on under the hood of the machines we use every day. If this article was entertaining, welcome to the second part, in which we will apply the information we gained after inspecting the solutions above.
0
0
0
0