
Our website uses cookies to enhance your browsing experience.

C++ is a truly controversial language. Good ol' C was created in 1972. C++ appeared in 1985 and had backward compatibility with C. Since then, C++ was pronounced dead many times: Java did it first, then Go and Rust. All disadvantages of C++ were discussed many times.
We published and translated this article with the copyright holder's permission. The author is Max Voloshin (mvolloshin@gmail.com). The article was originally published on Habr.

If you came to the C++ world from other OOP languages, here you won't find:

It's really hard to use C++, especially in large projects, but this language provides great capabilities. It's not going to retire yet. C++ is used in game engines, in software for embedded systems. Google, Microsoft, Yandex, lots of financial technologies, crypto and blockchain startups use this language. All because it has lots of advantages:
Besides, over the long life of C++, a huge number of frameworks, libraries, as well as many books and thousands of articles have been written for it and about it. Overall, it's really interesting to write in C++. But you have to be ready that it's a semi-finished product that you'll have to cook.
Modern-day development and Internet are inseparable in most cases. Now any iron can pass the REST data back and forth in some JSON. We, developers, need to somehow turn the data into language constructs and work with them.
To make it easier to think about the problem, imagine that we want to send data from a temperature/humidity monitor and receive it on the server side. The data looks like this:
struct TempHumData {
string sensor_name;
uint sensor_id;
string location;
uint update_interval_ms;
struct Value {
int temperature;
uint humidity;
};
Value value;
}Usually programming languages allow to work with JSON as a DOM (Domain Object Model), i.e. a tree-like data structure that describes an object. The object properties can be a number, a string, or another object. There are no other options in C++:
#include "nlohmann/json.hpp"
nlohmann::json json;
json["sensor_name"] = "living_temp_hum";
json["sensor_id"] = 47589431;
json["location"] = "living_room";
json["update_interval_ms"] = 1000;
nlohmann::json nested_val;
nested_val["temperature"] = 24.3;
nested_val["humidity"] = 48;
json["value"] = nested_val;Luckily, we can create an object by parsing a JSON string:
auto json = nlohmann::json::parse(json_str);And get data from the object somewhere else in the project:
auto sensor = json["sensor_name"].get<std::string>();The more fields there are in an object and the more widely this object is used, the worse the consequences will be. Any more or less serious changes become painful and routine:
And of course, the application will work incorrectly, and you won't find out about it right away, perhaps in production.
There's an option to manually assign the structure field values from DOM in a separate file:
TempHumData deserialize(const nlohmann::json& json) {
TempHumData result;
result.sensor_name = json["sensor_name"].get<std::string>();
result.sensor_id = json["sensor_id"].get<uint>();
result.location = json["location"].get<std::string>();
result.update_interval_ms = json["update_interval_ms"].get<uint>();
result.value.temperature = json["value.temperature"].get<int>();
result.value.humidity = json["value.humidity"].get<uint>();
return result;
}After that we can use the structure. The errors will be in one place, but it won't help much. Imagine what will happen if the number of fields exceeds 100+ or if you need to parse a lot of different JSONs obtained through the REST API or from the database. We'll have to write hundreds of lines, use Ctrl+C, Ctrl+V, and the human factor will definitely show itself somewhere. Besides, we'll have to do this every time something changes in the object. In this case, manual mapping into a structure brings more pain than benefit.
If we use another programming language, we can serialize the object directly and deserialize JSON into an object.
The code on Go that has this behavior:
import "encoding/json"
type TempHumValue struct {
Temperature float32 `json:"temperature"`
Humidity uint `json:"humidity"`
}
type TempHumData struct {
SensorName string `json:"sensor_name"`
SensorId uint `json:"sensor_if"`
Location string `json:"location"`
UpdateIntervalMs uint `json:"update_interval_ms"`
Value TempHumValue `json:"value"`
}
// somewhere
data := TempHumData{/* some data */}
bytes, _ := json.Marshal(data)
json_str := string(bytes)In C#, Newtonsoft Json has similar functionality, and in Java — Jackson2 ObjectMapper.
In this case, the code of the structure's parsing and conversion is already written and hidden behind the interface. The value type is determined automatically, and any changes to the object remain only in one place — in the structure definition file. The source code becomes a kind of a contract for us. Besides, JSON will either be parsed correctly as a whole or won't be parsed at all.
All of it is possible because of reflection, i.e. the program's ability to understand how it was written — how the objects are called, what type they are, what fields they have and how many, private or public, etc. All of it is stored in some place of the built program and there's logic that allows you to request such information.
[SPOILER BLOCK BEGINS]
Reflection is useful not only for serialization/deserialization but also for calling methods by their names, for example, by events in game engines, or for implementing RPC. I'm not going to describe this in this article. We're solving a specific problem here and reflection is just a way to do it.
[SPOILER BLOCK ENDS]
One of the C++ main ideas is "We don't pay for what we don't use". And the absence of reflection in C++ fits well into this idea. Sample assembler code obtained after compiling Hello World:
section .data
msg db 'Hello world!'
len equ $-msg
section .text
mov rax, 1 ; set write as syscall
mov rdi, 1 ; stdout file descriptor
mov rsi, msg ; source buffer
mov rdx, len ; number of bytes
syscall ; call writeWe don't store information about the source code in the form familiar to the developer. Static data (the .data section) and a set of instructions (the .text section) are simply packaged into a binary file. This minimizes the file size and does not waste time on unnecessary initialization of objects in dynamic memory. In the end, classes, functions, variables are all high-level abstractions needed to a human, not a processor.
It's time to tell a little bit about Rust. It has a lot in common with C++. It is built on llvm (C++ compiler toolkit), it does not have a garbage collector, and it also does not support reflection. But nevertheless, he has a very cool serde, which is not inferior to solutions from other languages.
use serde::{Deserialize, Serialize};
#[derive(Serialize, Deserialize)]
struct TempHumValue {
temperature: f32,
humidity: u32,
}
#[derive(Serialize, Deserialize)]
struct TempHumData {
sensor_name: String,
sensor_id: u32,
location: String,
update_interval_ms: u32,
value: TempHumValue,
}
// somewhere
let data = TempHumData {/* some data */};
let json_str = serde_json::to_string(&data).unwrap());The secret here is simple, but not quite obvious. Rust has a powerful macro mechanism. Thanks to it, before compilation, code is generated containing the logic of serialization of the entire structure field by field. Almost like manual mapping but the compiler writes the code for us.
We will make a lot to look like Rust and serde, but at the same time we will separate the wheat from the chaff — separate serialization and reflection. With all this, we will never pay for what we don't use.
First of all, we need to determine the principles of our solution. In short, we will have to:
The first goal we need to achieve is to abstract from a specific type. This is quite an important point to understand, and we should consider it thoroughly. Intuitively, I wanted to write something like this:
template <typename T>
void serialize_recursive(const T* obj) {
std::vector<???*> fields = reflection::get_fields_of<T>(obj);
for (auto&& one_field : fields) {
serialize_recursive(one_field);
}
}
template <>
void serialize_recursive<int>(const int* obj) {
// serealize int
}
template <>
void serialize_recursive<bool>(const bool* obj) {
// serealize bool
}I wanted fields to store different types of pointers to object fields, but this is impossible due to the peculiarities of the language. The compiler simply does not know how to physically store such data. It also cannot know which types can be stored there in order to correctly output the one_field type, generate code for all <T> and recursively call the function. Now we're working with one object, a second later with another, and they all have a different number of fields and their types.
So, as an option, we can sort out types in runtime. In other words, dynamic typing. Well, almost.
The first entity we need is Var. The name implies that it's something variable-like. Var stores:
Var has a template constructor that takes a pointer of a random type, calculates the ID and erases the pointer type, converting it to void*.
Getting a type ID is one of the key points. Monotonically increasing ID makes it possible to build a table with pointers to functions, where ID acts as an index and allows you to quickly call the desired function. This is the main idea of the entire reflection library. If we have a type ID and void*, we can call on data either:
static void copy(void* to, const void* from) {
*static_cast<int*>(to) = *static_cast<const int*>(from);
}or:
static void copy(void* to, const void* from) {
*static_cast<float*>(to) = *static_cast<const float*>(from);
}This way we can copy variables, create new instances, etc. We just need to add a pointer to a function for a specific action to the table.
[SPOILER BLOCK BEGINS]
If we need to create a new object and return it from the function, unfortunately, we cannot do it without dynamic memory allocation. The compiler must know the type (size) of the object if memory is allocated on the stack. Therefore, we'll have to allocate memory on the heap, and we'll have to make the returned type universal, i.e. void* or Var.
[SPOILER BLOCK ENDS]
The standard C++ mechanism for obtaining ID of the typeid(T).hash_code() type will not give a monotonically increasing sequence, so we won't use this.
I'll have to create my own TypeId that will contain a single int as data and additional logic. By default, it is initialized with the value 0 — unknown type, the remaining values are set via specializations. For example:
TypeId TypeId::get(int* /*unused*/) {
static TypeId id(TheGreatTable::record(Actions(
&IntActions::reflect,
&IntActions::call_new,
&IntActions::call_delete,
&IntActions::copy)));
return id;
}I left only what is necessary for understanding, the original code is in the repository.
There is a rather tricky point. Specialization TypeId::get(T* ptr) uses the private TypeId constructor, which takes a number — ID. We get this number by calling TheGreatTable::record(). It remains in a static variable. Therefore, it's initialized only once, then it will be simply returned.
Properly written template code will reduce the number of boiler plate, and static initialization will allow us not to think about which type has which ID. Everything will happen automatically.
TheGreatTable is another key entity of the library. The table with pointers to functions. We can only write to it via the record() method, which registers pointers and returns an index in the table, i.e. the type ID. In the example above, pointers to four functions are written to it.
Thus, we can quickly and painlessly determine the type in runtime and call the relevant code. Various checks that the compiler usually does will also have to be done in runtime, for example:
Expected<None> reflection::copy(Var to, Var from) {
if (to.is_const()) {
return Error("Cannot assign to const value");
}
if (to.type() != from.type()) {
return Error(format("Cannot copy {} to {}", type_name(from.type()),
type_name(to.type())));
}
TheGreatTable::data()[to.type().number()].copy(to.raw_mut(), from.raw());
return None();
}In order to store all the necessary information about the type and have a universal logic for working with it, we will need another entity.
TypeInfo is a sum type based on std::variant with a slightly more object-oriented interface. By calling the match() method, we can determine what exactly the type is:
info.match([](Bool& b) { std::cout << "bool\n"; },
[](Integer& i) { std::cout << "integer\n"; },
[](Floating& f) { std::cout << "floating\n"; },
[](String& s) { std::cout << "string\n"; },
[](Enum& e) { std::cout << "enum\n"; },
[](Object& o) { std::cout << "object\n"; },
[](Array& a) { std::cout << "array\n"; },
[](Sequence& s) { std::cout << "sequence\n"; },
[](Map& m) { std::cout << "map\n"; },
[](auto&&) { std::cout << "something else\n"; });Any type can be one of the following options:
In order to abstract from specific types, type erasure is used. Template code for different types (int32_t, uint64_t, char) is hidden behind a common interface (linteger) and works with Var and other universal entities.
All work begins with calling the main reflection function — er::reflection::reflect(), which returns TypeInfo. Then we have the opportunity to recursively parse our type — understand how it works and what data it stores.
I don't want to turn this article into documentation. So, I'll leave the code for supporting standard types here. If one of these standard types is not used in the application, then static initialization won't generate TypeId, won't add pointers to functions in TheGreatTable. The compiler will cut out unnecessary code and we won't pay for what we won't use.
We have figured the basic principles of the library, and now we need to add support for custom structures and classes.
As we know, only the compiler and the developer know exactly what is written in the source code files. After compilation, the binary file doesn't have any information about this — only the constant data and a set of machine instructions.
[SPOILER BLOCK BEGINS]
I don't like the existing solutions for reflection in C++ because they force me to write a bunch of code using ugly macros. I have to do this because the information should be somehow added to the binary file with the program, and I have to add it by hand.
[SPOILER BLOCK ENDS]
We'll go the other way. We'll use the compiler's API to automate collecting the necessary information. Fortunately, the first version of Clang and LLVM was released in 2007. Since then, many useful utilities have appeared to analyze the source code. For example, clang-format, clang-tidy and clangd that combines them. Using the same principles, we'll write our own utility to analyze the source code. The sources can be compiled with anything — gcc or MSVC (but, as always, with pitfalls).
Clang provides libTooling – a set of libraries for analyzing source code. With this, we can analyze the code in the same way as the compiler does, i.e. via the Abstract Syntax Tree. This will give us a lot of bonuses compared to manual analysis of the source code. AST contains data from many files, therefore, it provides more information, allows us to understand in which namespace an object is located. With AST, it is easy to distinguish a declaration from a definition, etc.
In addition to access to the AST, we will have access to the preprocessor. It will allow us to use empty macros as attributes:
#define ER_REFLECT(...) // expands to nothing
ER_REFLECT()
struct TempHumData {
// struct fields
}Interaction with libTooling mainly is held through callbacks. For example, when the preprocessor expands a macro, or a class definition is encountered during AST traversal. Inside them, we can analyze AST subtrees and get field names, types, access modifiers, etc. The collected information should be stored in some intermediate data structure. You can see how this happens in the parser_cpp.h file.
Also, we need to somehow generate code based on the collected information. Template engines like go template, mustache, jinja, etc. are great for this. We'll write only a couple of templates, on which we'll generate hundreds of new source code files. I decided to use inja in this project. It's a sort of C++ port of jinja for Python.
A simplified template file for objects looks like this:
template <>
struct TypeActions<{{name}}> {
static TypeInfo reflect(void* value) {
auto* p = static_cast<{{name}}*>(value);
static std::map<std::string_view, FieldDesc> map {
{% for item in fields_static -%}
{"{{item.alias}}",
FieldDesc::create_static(Var(&{{name}}::{{item.name}}),
{{item.access}})},
{% endfor %}
{% for item in fields -%}
{"{{item.alias}}",
FieldDesc::create_member(value, Var(&p->{{item.name}}),
{{item.access}})},
{% endfor %}
};
return Object(Var(p), &map);
}
};
template <>
TypeId TypeId::get({{name}}* /*unused*/) {
static TypeId id(
TheGreatTable::record(Actions(&TypeActions<{{name}}>::reflect,
&CommonActions<{{name}}>::call_new,
&CommonActions<{{name}}>::call_delete,
&CommonActions<{{name}}>::copy)));
return id;
}The original code is here.
TypeActions<T> is just a wrapper so as not to clutter up the code and not to abuse autocompletion in the IDE with generated class and function names.
Instead of {{name}}, the name of the class or structure will be inserted.
When reflect() is called the first time, a static std::map is filled in two stages, where the key is the field name and its descriptor is the value. Later, thanks to this descriptor, we'll be able to get FieldInfo, which stores Var and an access modifier — public, private, etc. At the first stage, only static fields are registered. This will allow access to them even without an instance of the class.
ClassWithStaticFields* ptr = nullptr;
auto info = reflection::reflect(ptr);At the second stage, pointers to all other fields are registered, including private ones. Thanks to this, you can flexibly control access to them — deserialize data only to public fields, and private data only to read and print to the console.
Next, the pointer to std::map is placed in Object, which is packed in TypeInfo and is returned from the function.
In the TypeId::get specialization, pointers to functions are registered in TheGreatTable.
The generated code for all custom types will be in reflection.h Therefore, reflection.cpp is compiled into a separate object file. Such an organization will simplify the project build, but more on that later. For convenience, all settings for the generator, including the path to the analyzed and generated files are described in the YAML file.
The code of serializers for JSON, YAML, and byte array can be found in the repository. Binary serialization, like protobuf, quickly optimizes the data size.
Serialization's performance is about the same as that of rapid_json. For deserialization, I wrote JSON and YAML parsers using a lexer. Unfortunately, I'm just a code monkey and not an algorithms guru. So, the native parser is a bit quicker than nlohmann::json, but slower than rapid_json. Nevertheless, using simdjson as a parser allows us to outrun rapid_json a little.
Benchmarks allow us to compare the performance on various hardware.
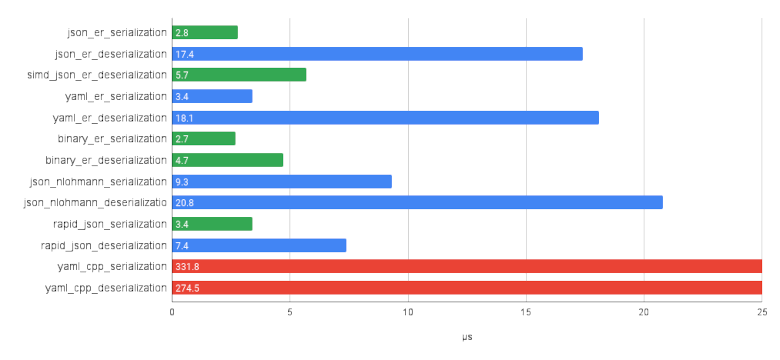
As of now, we have:
All we have to do is arrange attributes in the source code and configure the build system so that before the compilation of the main project, code is generated for reflection of new types. In Cmake, this can be done via add_custom_command:
set(SOURCES
main.cpp
${CMAKE_CURRENT_SOURCE_DIR}/generated/reflection.cpp)
add_custom_command(
OUTPUT
${CMAKE_CURRENT_SOURCE_DIR}/generated/reflection.cpp
COMMAND er_gen -p -c ${CMAKE_CURRENT_SOURCE_DIR}/config.yaml
DEPENDS
data/temp_hum.h
COMMENT "Generating reflection headers")
add_executable(${PROJECT_NAME} ${SOURCES})Fortunately, the generated source code is located in one .h and one .cpp file, so it's enough to include reflection.h to access the API and add reflection.cpp to the list of source code files. If the files in the DEPENDS section change, the code generator will start automatically.
Then we need to enjoy programming and serialize the object with one string:
auto json_str = serialization::json::to_string(&obj).unwrap()And in opposite direction:
auto sensor_data =
serialization::simd_json::from_string<TempHumData>(json_str).unwrap();You can find a more detailed example in the repository with the project.
This solution allows us to get the experience as close to other languages as possible. The difference lies only in a little magic over the build process. Besides, we can easily expand its functionality.
The project was tested and can be used in the production. Nevertheless, some things can still be improved. If you have any ideas or suggestions — I will always accept any help and, of course, stars on github.
This article is quite long, but some topics were not described in full detail. For example, how JSON or YAML parsing works or how binary serialization works. If you want to see something in the next article, please, let me know.
0
0
0
0