
Our website uses cookies to enhance your browsing experience.

Even though we write code every day, we often view the compiler as a "black box." Today, let's explore how a compiler actually works, discuss its lifecycle, and see where trees come into play.

To put it simply, a compiler is a translation program. It translates human-written text (source code) into machine code, which is a sequence of zeros and ones that the processor can understand.
A machine is, basically, a huge set of switches (transistors). The compiler generates instructions that enable program execution. It decides which switch to enable or disable and when to do so.
By the way, you can see the most basic form of such instructions in a Turing machine, which is a theoretical model where programs are created using only 0s and 1s. This model laid the foundation for modern computers.
If you like more challenging experiments, I invite you to check out our new webinar series, "Let's make a programming language." You'll learn what a programming language is and how to formally describe it so that a machine can understand it.
A language processing system
The compiler consists of multiple modules and is also part of a larger code-processing chain. It takes source code as input and returns binary code as output.
You can see the whole sequence in the diagram:
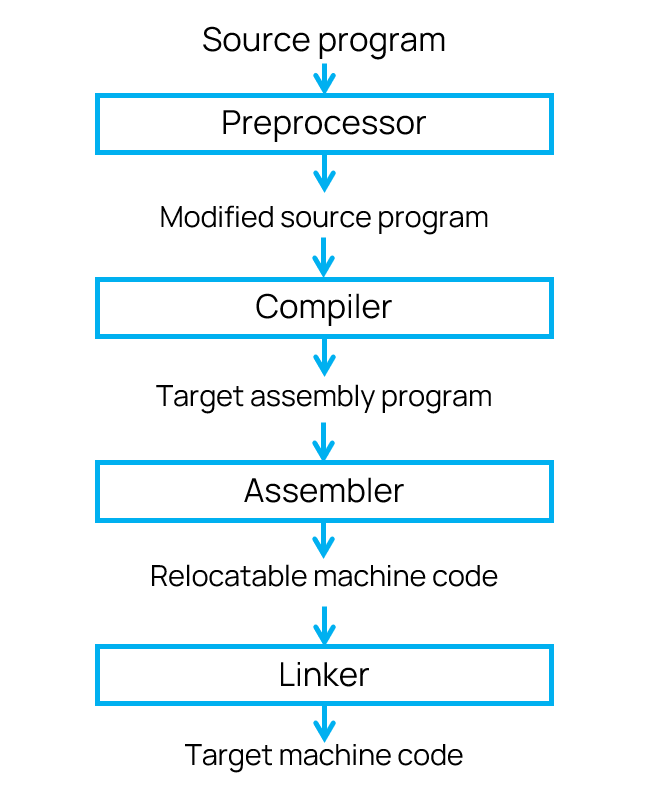
Let's walk through each stage to understand how the language processing system works.
Preprocessor. First, the source code is passed to the preprocessor that expands macros, includes header files, and removes comments. The code is ready to pass to the compiler only after this preparation.
Compiler. After receiving the processed code, the compiler starts its main routine. However, it doesn't output the machine code right away. First, it produces an intermediate result: assembly code that humans can understand but that is as close as possible to the processor's instructions.
Assembler. Then, the assembler comes into play. It translates commands that humans can understand into real machine code.
Linker. Large programs are usually compiled from many object files. To compile them into a single unit and link all function calls to their actual addresses, a linker is needed. It creates the final executable file.
Another approach to executing code is interpretation. Unlike a compiler, which translates the entire program, an interpreter executes commands line by line.
However, some modern languages, such as Java, employ a hybrid approach. Source code is first compiled into a special intermediate bytecode that is independent of the processor and OS. A special program, the Java virtual machine, executes it, acting as an interpreter.
What's interesting is that Java can also be compiled into machine code, bypassing the virtual machine. However, there are some nuances to this that we discussed in the article "Closed-world assumption in Java."
Today, however, we're going to talk specifically about how a classic compiler works.
The compiler's work is divided into three stages: code analysis (creating a tree), code optimization, and code generation. Let's walk through each one.
When we look at code, we automatically break it down into words and see constants, variables, functions, and other parts. Lexical analysis enables the compiler to "read" the code in a similar manner.
Tokenization happens at this stage. The source text is broken down into the smallest meaningful units, which are called tokens. Each token is a pair consisting of a type and a value. A type is a number, an operator, or an identifier, while a value holds specific data, such as 12 or +. Spaces, comments, and line breaks are ignored at this stage because they aren't needed to understand the program structure.
After the lexical analysis, we get a token list instead of a long string of source code. For example, this one:

When parsing code, the lexical analyzer looks ahead by one or more characters. This enables it to accurately decipher the code for a specific language. For example, in the C language, when it encounters the > character, it must check the next character to distinguish the > operator from >= or >>.
Templates in C++ are even more complicated. The Foo<Bar> construct can refer to either a template with the Bar argument or comparison operators. How to tell the difference? The lexical analyzer can't tell on its own; it needs to know that Foo is a template name. To do this, a lexer hack is used, where the lexer uses results from a semantic analyzer that already knows which names are patterns. Modern C++ compilers integrate lexical and syntactic analysis: the parser provides the lexer with information on how to interpret the current token.
Now we have a token sequence, but that's not a structure yet. We need to understand how they're connected. This is what a syntactic analyzer, or parser, does. It checks whether the token sequence complies with the grammar rules of the language and, in most cases, instantly generates an abstract syntax tree.
Grammar is a set of rules that describe how to put together expressions and instructions from smaller parts. For example, here's a rule for arithmetic expressions:

This is where the concepts of formal grammars come into play:
Terminals are actually tokens. In this case, number is a terminal, since it has been parsed into a token by the lexer. For a lexer, the terminal symbols are individual characters, but it groups them into larger units so that the parser doesn't have to parse them individually (for example, it groups numbers into digits).
The parser builds a hierarchy based on the grammar rules. The result is a concrete syntax tree (CST). It even has nodes for such little things as a semicolon or a comma.
Such a tree can be quite cumbersome, so compilers almost immediately convert it into a more compact form—an abstract syntax tree (AST). It contains no service nodes; only the essentials remain: operators, operands, and blocks. When discussing trees in compilers, people most often refer to ASTs.
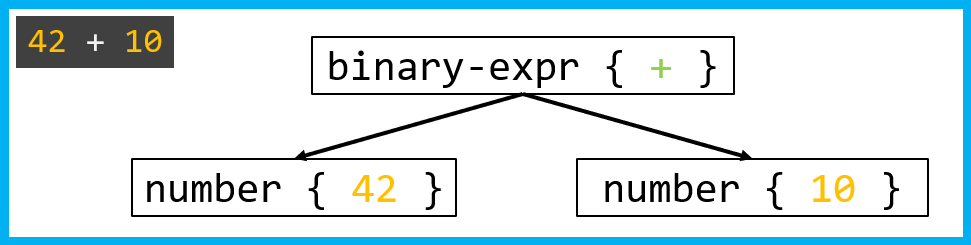
How does a parser build a tree?
Once the lexical analyzer has converted the 42 + 10 line into the number { 42 }, op { + }, and number { 10 } tokens, the real fun begins. The parser must understand how these tokens are related to one another in order to construct a tree.
Several ways to build a tree exist, such as top-down and bottom-up parsing. They reach the same result from different sides and rely on their own grammar. However, if two different trees can be constructed for the same expression, then the grammar is considered ambiguous. These ambiguities are often resolved simply by the word order. For example, a declarative expression always takes precedence over an imperative one.
The top-down approach Parsing begins at the root (the start non-terminal) and attempts to expand it by selecting the appropriate grammar rules. Among compiler tools such as GCC, Clang, and MSVC, the most common approach is recursive descent: for each non-terminal, a separate function is written to determine which rule to apply.
The parsing process works like this: when the parser encounters the number { 42 } token, it recognizes it as literal-expr and applies the literal_expr() rule. Then, it encounters op { + } and applies binary_expr() to the + operator. After that, it does the same for the second number.
Each parsing type has a class of grammars that it can parse. Left-recursive parsing with leftmost derivation (LL(k)), with a lookahead of k (k is a constant), is a top-down parsing method. Left-recursive parsing with rightmost derivation (LR(k)), with the k lookahead, is a bottom-up approach.
The bottom-up approach This algorithm can handle a wide range of grammars and is most commonly used in BISON and YACC parsers. In this type of parsing, the parser doesn't try to "guess" the rule in advance. Instead, it accumulates tokens and, as soon as they form the right-hand side of the rule, the parser "collapses" them into a non-terminal. Parsing tables are usually used to implement such a parser. It reads the token, consults the table, and decides what to do: whether to move on to the next token or to stack the top few elements into the non-terminal.
Here's how it works, using 42 + 10 as an example:
number { 42 } and push it onto the stack.op { + }. As the table shows, it's too early to fold, so we push + onto the stack.number { 10 }. Now we see what we can fold into additive-expr. As a result, one non-terminal remains on the stack—the tree has been built.If you're interested in seeing how modern C++ can simplify the handling of complex tree structures, I invite you to read the "How to climb a tree" article.
Although the tree has been built, the compiler still needs to verify that the program makes sense from the language logic perspective. At this stage, it checks everything that grammar can't describe.
Scopes. The compiler must know which declaration each variable use refers to. It creates a symbol table as it traverses the tree. It adds an entry to the current scope when it encounters a declaration and searches for the name in the table when it encounters a usage. It returns an error if it doesn't find the name.
Type checking. Each operator must receive the correct types of operands. For example, the + operator in the 42 + 10 expression works with numbers—everything is fine. But if we wrote 42 + true, the compiler would throw an error, because Boolean values can't be added to numbers. Languages often allow implicit conversions, though. If types can be converted to one another, the compiler adds a special node into the tree, for example booltoint.
l-values and r-values. The left side of the assignment should contain the l-value, which stores the address in memory (a variable or an array element). The 42 constant doesn't have this property, so 42 = 10 is a semantic error. The semantic analyzer tracks this by checking to which node the assignment operator applies.
As a result, the tree "grows" by adding more information. Each node is assigned attributes, including the data type, a reference to the variable declaration, and conversion information. This tree is called an annotated syntax tree and is used for code generation.
The symbol table
During the semantic analysis, the compiler actively uses the symbol table. It's a data structure that stores all information about identifiers. Each entry includes a name, type, scope, and any other necessary information, as well as the memory address if it's known.
The most fascinating part is how the compiler locates names when it encounters the use of an identifier. For more information on name lookup in C++, check out the article "How far does lookup see in C++?"
Once the semantic analysis is complete and the tree has been annotated with all necessary attributes, the compiler moves on to the next stage: generating the Intermediate Representation (IR).
IR is abstract code that is closer to machine code but isn't tied to a specific processor yet. It enables platform-independent optimizations that work on any target platform.
The most common IR type is the three-address code. It's a sequence of statements, each one performing a simple operation. Let's look at an example:
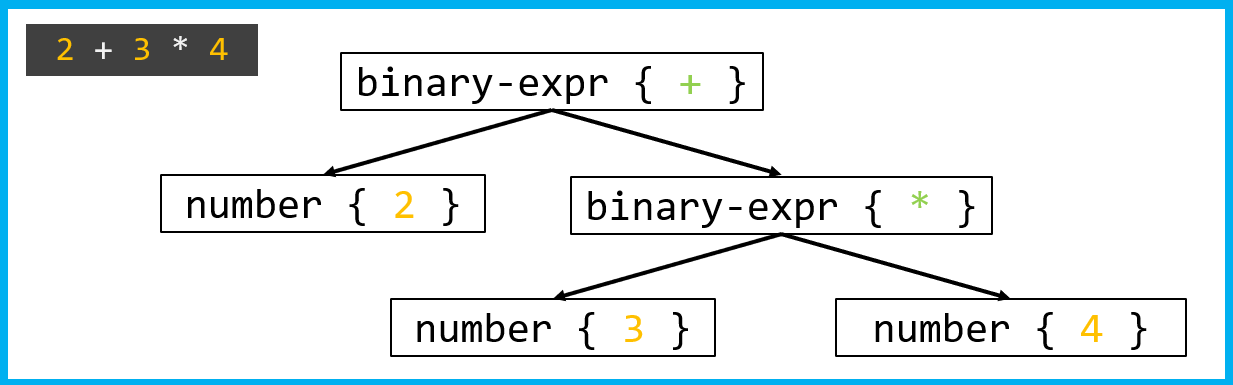
The traversal starts at the + root. The generator recognizes that two operands need to be added together. First, it generates code for the 2 left subtree, then for the * right subtree. A new temporary variable, t1, is created for the multiplication. Next, a second temporary variable, t2—which represents the result of the entire expression—is created for the + root. Here are the statements:
t1 = 4 * 3
a = 2 + t1After parsing the syntax, verifying the semantics, and generating an intermediate representation, the compiler receives linear code that the optimizer can easily work with. At this stage, the compiler tries to optimize the program by making it faster, smaller, or more memory-efficient.
Let's look at this code fragment:
int a = some_complicated_function();
int b = a * 0;
std::cout << "value = " << b;If the compiler were to simply translate the code, it would first have to evaluate a, then multiply it by zero, only then would it output the b value.
But the compiler knows arithmetic rules: multiplying by zero equals zero. This is true regardless of what a holds. So, the optimizer can fold the whole expression and replace the b variable with the 0 constant. Since a isn't used anywhere else, its evaluation can also be removed. In the end, what remains is:
std::cout << "value = " << 0;In order to be applied, the optimization must meet the following requirements:
The compiler reorders instructions, replaces some constructs with others, and removes unnecessary elements. The result must be the same as if we had executed the source code.
This is where machine-dependent optimizations, such as register allocation, instruction selection, and instruction ordering, come into play to ensure efficient execution.
Note. In fact, static analyzers also create IR and search for redundant code during their execution, but for a different purpose. In some cases, redundancy may indicate a typo or logical error in the code. For example, PVS-Studio issues the V547 warning here, indicating that the last condition is always false.
void x(int a, int b, int c)
{
if (a < b)
if (b < c)
if (c < a)
foo();
}Once all optimizations are complete, the compiler finally moves on to the most critical phase: code generation. In this phase, the optimized IR is converted into actual machine instructions, including register loads, arithmetic operations, branch instructions, and function calls.
That's when the program transitions from an abstract tree to a sequence of zeros and ones, ready for execution.
At the beginning of this article, the compiler was a "black box" to us. Now, however, we know that it contains a whole pipeline of transformations. The entire process can be summarized as follows:
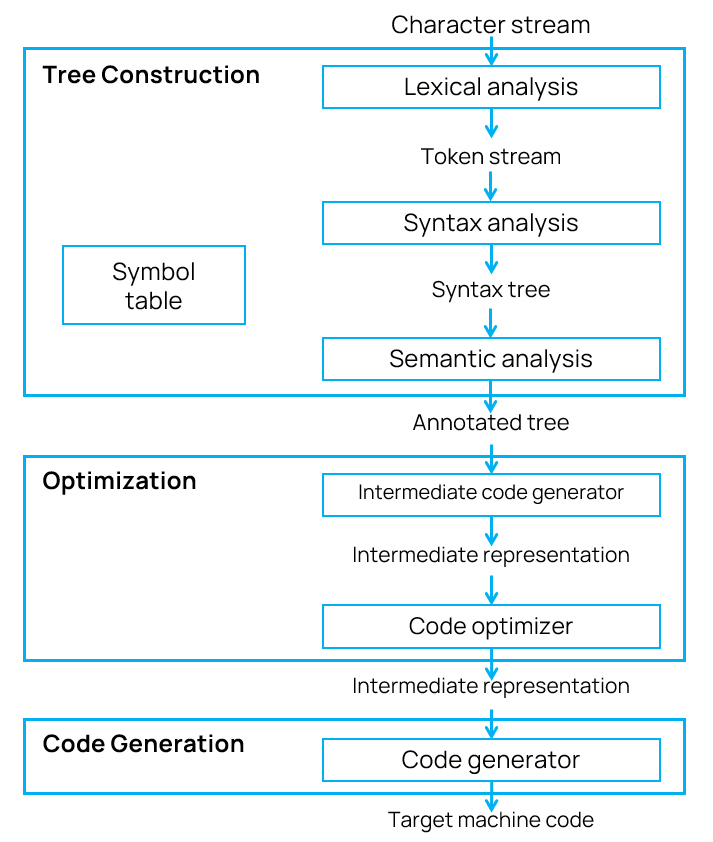
The intermediate representation lies at the heart of this entire chain. It's created from trees during the code generation phase and serves as the foundation for all further transformations. Optimization tools focus on IR, rewriting the code to make it faster, more compact, and more efficient for specific architectures.
Trees are created during syntactic parsing, assigned attributes during semantic analysis, and serve as the foundation for further transformations. Without them, the compiler wouldn't be able to "understand" the program structure.
If you want to understand the theory and learn how to build such trees yourself, check out our webinar series, "Let's make a programming language." In these coding sessions with Yuri Minaev, a PVS-Studio architect, you'll learn how to formally describe a language so that a machine can understand it.
0
0
0


0