
Our website uses cookies to enhance your browsing experience.

Looking to build a .NET library, but unsure where to begin? Already developing something similar, but want to discover something new? Looking for ways to extend automation? Not sure what to do with users? I'll try to answer the above and other frequently asked questions in the following article.

As an illustrative example I will take my own open source library – DryWetMIDI. With it, we can observe all aspects of creating a project of this kind. Although this article focuses on .NET/C#, many of the things mentioned here apply to different platforms and programming languages.
We published and translated this article with the copyright holder's permission. The author is Maxim Dobroselsky (melanchall (Maxim Dobroselsky) GitHub). The article was originally published on Habr [RU].
First of all, it would be great if you knew clearly why you need to build a library. Sure, you may come up with a lot of good reasons:
But whatever your motivation is, I'm pretty sure you see the benefit to society as the primary reason for creating a library (or anything else), just as I do. Society has some needs and demands, and it is definitely worth taking them into account.
You can be 99% sure that someone has already put your idea into practice. That's why you would do well to study the achievements of your predecessors.
Before starting developing DryWetMIDI, I studied the already existing MIDI projects and found that they all were not properly application-oriented. Or rather, they were not application-oriented at all. Sure, you can use them to read a MIDI-file and get a .NET representation of it according to the protocol specification. However, MIDI is about music itself, and technical specifications terms are not applied to music. In music there are other terms, such as bars, quarter notes, chords, scales, etc. In projects of this kind, I see a huge gap between musicians and programmers.
For example, the timing in MIDI-files is recorded as the difference between two consecutive events, or as delta times. Delta times are measured in ticks. But you can call them whatever you like and nothing will change. The meaning of the ticks is set in the file's header. The length of a tick (in seconds) is defined by the tempo changes contained in the file. DryWetMIDI has introduced the API for working with time and length in "human" units of measure. It has become the first feature that other projects lack. Anyway, who even needs another library that doesn't provide any new features?
In addition to sneaking a peek at the other projects, it's also good to search for people's current problems on specialized forums. At the beginning of my project, I searched for the discussions of this kind on Stack Overflow by the midi tag. And the question "how to get musical notes from a MIDI file" was one of the most frequent. That's why you can get notes, chordes, pauses, and combinations in DryWetMIDI. By the way, in case anyone doesn't know, on Stack Exchange sites (like Stack Overflow) you can subscribe to certain tags and get emailed any new questions that are tagged.
You can find out the demands of your potential users another way. For example:
{{PROMO_POPULAR}}
You may find tips mentioned in this section obvious (or even terrible). Let me point out in advance, that most of the major software development vendors provide free licenses for their products for non-commercial open-source projects. For example, Microsoft provides Visual Studio Community, while JetBrains offers a license for all their products, including Rider, ReSharper, etc. So, if you would like to use a tool when developing your project, you can probably legally use it for free.
Software architecture, in my experience, is the most difficult thing. Yes, it is quite easily designed on the basis of current requirements, but far more important is to understand the development vector of your project. Vector strongly influences the set of types you use and the relationship between them, and this in turn affects the simplicity (or complexity) of adding new features and changing old ones. If you focus on users, the architecture affects the frequency of breaking changes and user complaints about this fact.
Having a clear idea of the API's future is quite challenging, I rarely succeed. Let me show you a real example. Generally speaking, MIDI consists of two main parts: MIDI files and MIDI devices. The first version of DryWetMIDI was released in May 2017. In January 2018, I told the user the following about MIDI data playback:
″Thank you for using the DryWetMIDI. At now there is no way to play a MIDI file with the library. Concept of the library is to provide reading, writing and creating MIDI files. Sound generation is not supposed to be a part of it. ... Hmm, it seems that playing a MIDI file (especially not saved) doesn't fit the DryWetMIDI concept. There are other libraries that provide sound generation for MIDI files so I recommend to use them. ″
In January 2019, version 4.0.0 was released. The new version had API for working with devices, as well as data playback and recording. The 5.0.0 version contained plenty of breaking changes due to the renaming of namespaces. Since the names originally came from the concept illustrated by the quote above, they became wrong as the project was gradually enhanced. The 6.0.0 version added support for macOS in the API, which required reorganization of related types, to work with devices. All this is about forecasting the development of the project.
Of course, I'm not going to provide any practical guidelines for creating the proper architecture in this article. Much more experienced people than me have already written many books and articles on this topic. In this article I only recommend you to spend a little more time and plan your library in as much detail as possible to make things easier for you and your users in the future.
Interestingly, Visual Studio offers the calculation of some code metrics:
Figure 1. Let's find out what VS thinks about our code
You will get a table similar to this one:

Figure 2. The unbiased opinion of the program.
Although all these parameters are defined by quite specific formulas, this function will rather show you all your code's flaws (if there are any) than show you how well your code is organized. But that's also quite useful.
Tests are not a recommendation, but an urgent request. I came to writing tests rather late. During the first months of the DryWetMIDI developing, I checked the library by attaching a debug DLL to a separate console application (and that's awful, I admit). But, having tried the tests once, it is already impossible to quit.
I'm not going to convince you to use certain software development approaches (such as TDD or BDD), you're free to alternate code and test writing however you like. But tests are crucially important for your project. It's impossible to operate more or less complex logic (and your project will have one soon enough) in your project without tests. Otherwise, you will be constantly patching holes in your project, while your users will discover all the new and new bugs. Or no one will actually use your library because of the constant bugs.
Tests make you feel peace and quiet when refactoring, since you're able to run tests and immediately see if something is broken. Always write tests when implementing a new API. I encourage you to make tests an obligatory criterion for implementing any new feature.
After you find a bug, you need to fix it and add a test which checks an error scenario. After your user finds a bug, follow the same steps and provide the user with the fixed build.
Sometimes you may want to enhance the API for the reasons mentioned in the Architecture section. You may want to refactor it, unify existing classes and methods, and so on and on. The question arises: what should you do with an existing API that someone still uses?
You can completely abandon the old interfaces, announce breaking changes and upgrade the library version (see the Releases section). However, there's a chance that users who constantly have to change their code will end up preferring a more user-friendly library. Sure, all this doesn't matter if your project is "for personal use only". But even so, I assume that developing something for free has an incentive — to make someone's life a little better and solve someone's problems with your product. The user's life is clearly not going to get any better if they have to change their code all the time.
Once you feel the urge to update your API, I recommend you to keep supporting the old one by declaring it deprecated. You can use the Obsolete attribute for this purpose:
[Obsolete("OBS19")]
public static IEnumerable<MidiFile> SplitByNotes(
this MidiFile midiFile,
SplitFileByNotesSettings settings = null)This code fragment from the current version of the DryWetMIDI. OBS19 may say nothing to you. But I have configured generation of Obsolete attribute descriptions using a particular JSON file. I'm going to tell you more about it the CI and automation section bellow.
Until then, pay attention to the following: what you write in this attribute will eventually be seen by users in tooltips in the IDE, in build warnings and in the information section (if you make any). That's why it would be better to write something meaningful and useful in it. Don't write the following:
[Obsolete("This method is obsolete.")]
public static void Foo()The presence of the attribute already signs that the method is deprecated, so there's no sense in repeating it in the message. Write:
[Obsolete("Use Bar method instead.")]
public static void Foo()It would be great if users could find the information that they use something outdated and switched to an updated one. Sure, the reality may not be so idyllic, since people may just put off changing their code, dismiss warnings and so on. However, in this case you'll remove the old API with a clear conscience.
I also encourage you to change the implementation of the previous functions on their lifetime to enable the new code calls. This way you can make the new logic available to users, but at the same time they don't have to change anything in their code. Moreover, you will be able to start testing the new API in real-world conditions as soon as possible.
However, at some point of the project development, you may want to eventually get rid of this burden of the past. You have to do it someday, but the reasons should be valid.
I hope everyone is able to imagine the true value of static analysis. We are all human beings and we regularly make logical mistakes. Surely, it's much better to be aware of these mistakes before the new library version is released. Tests find most of the errors. However, static analysis can be of great help in any case. You can configure the analysis to be performed regularly while you are working in the code editor, or you can run it manually just before the release. All that matter is to use it.
I run the code through ReSharper and PVS-Studio before the release (It took me long to try static analysis, but numerous articles on Habr made me finally give it a shot). The developers of both products provide free licenses for open-source projects.
Moreover, JetBrains provides a free InspectCode CLI utility, so that you can run static analysis within CI builds. You can also run PVS-Studio via the command line, but it's a little trickier.
Obviously, static analyzers cannot get into your head, so they only deal with stuff that can be found in the code. Be prepared for a large number of false positives. But don't worry, you can always set up exceptions for some diagnostic rules or change their categorization (e.g. mark a lack of XML documentation as an error rather than a warning, and vice versa).
There are also built-in diagnostics in the IDE that you use. You can even configure something in the csproj file.
Donald Knuth once said:
″premature optimization is the root of all evil″
Premature optimization means improving algorithms before they are implemented and their behaviour is fixed. When starting developing a new feature, it's far more important to create a working API than to spend ages trying to improve the algorithm. Optimization is important, but it should only be done once you are sure that the feature operates correctly. I do not think publishing the build with an algorithm that has some flaws (but still does its job) is a bad thing. You can always complete the algorithm in future releases.
Another smart idea is expressed here:
″There are obvious optimizations (like not doing string concatenation inside a tight loop) but anything that isn't a trivially clear optimization should be avoided until it can be measured. ″
And there is another important rule that should be followed (if you don't want to get bogged down in a mire of broken code, getting new bugs that turn your hair gray) – always measure the optimization result. Without code metrics, you can only hope that you make your code better.
Metrics may vary depending on the option optimized. Performance? Then, probably, you should focus on the execution time of the method or the CPU usage. Memory usage? In this case, studying the dynamics of the memory allocation in time or studying it at certain moment will show you how much the function consumes and what the other biggest consumers in your code are.
I suppose everyone knows about this awesome library – BenchmarkDotNet. This library allows you to measure the time of operations, considering the warm-up, multiple runs, and producing a report on the results. When improving the algorithm in terms of execution time, be sure to create benchmarks that measure the performance of the old and new versions of the code. Thus, you can clearly see the difference (if any) and confidently say that the feature is now faster. Or it's not. Sometimes it happens.
There's another perfect tool – dotTrace. You can use it to see which instructions in your code are taking the longest, and then optimize certain problem areas. This way you can make a simple console application that calls the examined function of your library, run dotTrace and select the built application for profiling (performance measurement). This tool will also be very helpful when examining the most common features. For example, DryWetMIDI is often used to read MIDI files. That's why I have profiled the MidiFile.Read method once, found out some problems in the API and then significantly enhanced the performance.
Another JetBrains product – dotMemory – allows you to analyze memory usage. For example, reading a MIDI file now looks like this in terms of memory consumption dynamics:
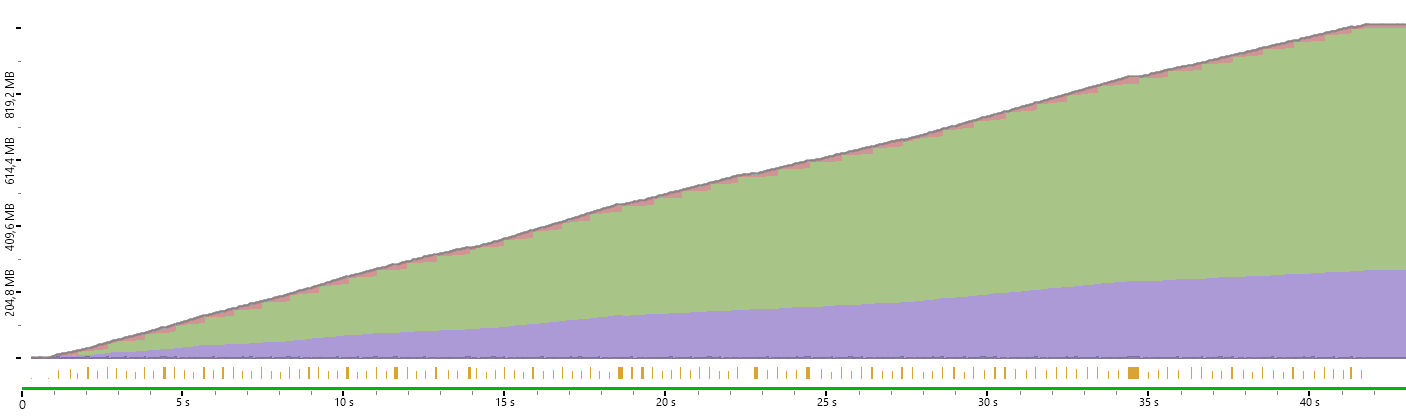
Figure 3. The amount of allocated memory went to the top.
The figure shows reading a very large file into a MidiFile type object and iterating over MIDI events inside it. When I came across this question on Stack Overflow, I decided to create an API for stream reading. The difference between what we have now and stream reading can be compared to whether an XML file is read with XDocument or with XmlReader. So, I created the MidiFile.ReadLazy method (code in an unreleased version), which returns a MidiTokensReader, from which you can call ReadToken sequentially. The situation with the memory iteration over events is the following:
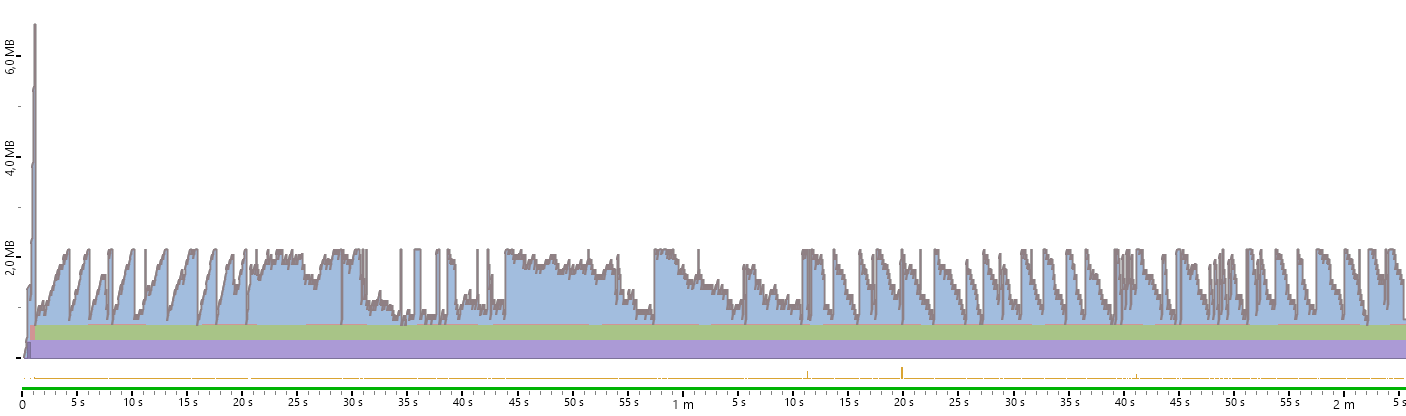
Figure 4. It takes more time, but there will be enough memory space.
In other words, memory consumption is constant, and it has a decrease of two orders of magnitude when reading a test file comparing with reading the whole file.
Think ahead about the target platforms you are going to support and specify TFM in the csproj file. For example, DryWetMIDI specifies the following:
<TargetFrameworks>netstandard2.0;net45</TargetFrameworks>Thus, the library can only be used in the .NET Standard 2.0+ and .NET Framework 4.5+ projects. Sure, now .NET Framework 4.5 is a rather outdated version of the framework. But why not just support modern .NET Standard 2.0 and abandon outdated platforms?
And for those who focus on users, the answer is simple. Your library can be used in many projects, including those that use obsolete technologies. Sure, you may keep up with the times and state in your documentation that you do not support outdated technologies. And it's up to you to decide which is more important: supporting more platforms or keeping your code up to date.
Curiously enough, I started my project on the .NET Framework 4.6.1. However, I was once asked about using the library in the Unity 2017.x project through source code files (they can be added to the project's Assests folder and the library will become available for Unity projects). It turned out that Unity supported the 4.5 framework at that time, so I targeted the library on that version (the first version of .NET Standard was only supported in the Unity 2018.1, as you can see in this table). Moreover, I used C# 6 instead of the latest released version, as Unity did not support the newer versions of the language at the time:
<LangVersion>6</LangVersion>By following these two simple steps, I managed to cover development cases for Unity game projects.
Surely you should not go to extremes and support too outdated versions of .NET. If you begin your project now, it may be a good decision to choose netstandard2.1 or even net5.0 as TFM. However, be careful, since .NET 5 is not a long-term support version (see .NET and .NET Core Support Policy).
Sometimes, when implementing a new API, I put away some minor things for later (for example, checking arguments for null in public methods). So as not to freak out the day before the release, I mark these things with the // TODO comment. You may also want to write a comment for the future when you're working on some algorithm and suddenly have a thought like: "I'll go back to that matter later, but now I should deal with this upper-level structure of steps".
And if you want to implement a new feature as soon as possible — it may also become a valid reason to accumulate a little more tech debt. It may happen when the feature operates correctly, but not too effectively (see the Optimization section). Or you may decide to improve the feature's implementation in further releases, and give users the opportunity to use the new API in the coming one. In this case it's would be great to make the // TODO comment too. There is an example in DryWetMIDI, the release documentation in the 6.0.0 version said:
″Also HighPrecisionTickGenerator implemented for macOS too so you can now use Playback with default settings on that platform. Its implementation for macOS is not good (in terms of performance) for now but will be optimized for the next release of the library.″
And I fixed everything in the next version (6.0.1), as I promised.
Any popular IDE shows a list of all special comments in code (this includes the // TODO comment). In VS, this is the Task List window, in Rider – TODO.
While preparing this article, I was surfing Wikipedia and came across the definition of continuous integration, or CI. It states:
″In software engineering, continuous integration (CI) is the practice of merging all developers' working copies to a shared mainline several times a day.″
In other words, CI is basically working in the version control system. It's embarrassing to admit, but I was rather surprised, since I've always treated CI as something similar to the automatic actions for pushing a commit. But it turned out that CI is pushing a commit, while other actions are triggered by continuous integration. It wasn't just me thinking this way, was it?
I use Azure DevOps pipelines on Microsoft-hosted agents as an automation mechanism within CI. With Azure Pipelines you can run your tasks on Windows, macOS and Ubuntu. Many of us remember that times when .NET denoted binding to Windows, but now I find it necessary to test the library on different supported platforms. Sure, your product may not be fully cross-platform. For example, working with MIDI devices requires a separate implementation for each target platform, and DryWetMIDI has the implementations for Windows and macOS. That's why the corresponding API can only be used on Windows and macOS. However, any other API relies on regular .NET tools and that's why it is tested on the three platforms mentioned above. I would really like to run tests on mobile platforms, but so far, I am struggling to imagine the whole process.
The first thing I want to do when pushing changes to the main branch is to build the library. And I don't mean just dotnet build. In my project, a pipeline called Build library does the following:
At the same time, the above steps contain the following actions that are performed beforehand:
As I promised earlier, I'm going to tell you more about the generation of descriptions for Obsolete attributes. I made a simple JSON file of this kind:
{
"OBS19": {
"Hint": "Use Splitter.SplitByObjects method.",
"ObsoleteFromVersion": "6.1.1",
"InLibrary": true
},
...
"OBS9": {
"Hint": "Use AddObjects methods from TimedObjectUtilities.",
"ObsoleteFromVersion": "5.2.0",
"InLibrary": false,
"RemovedFromVersion": "6.0.0"
},
...
}The string from the Hint field is inserted into the attribute description. As a result, the description is transformed into the following:
[Obsolete("OBS19: Use Splitter.SplitByObjects method. More info:
https://melanchall.github.io/drywetmidi/obsolete/obsolete.html#obs19.")]As you can see, a link to the documentation section dedicated to this API is also inserted in the description. You can follow the link to see how it looks like.
The fields left in the JSON file affect the display of sections on this page: https://melanchall.github.io/drywetmidi/obsolete/obsolete.html. Here you can always see the list of obsolete library functions.
Let's come back to the project build. As I previously said, I use Azure DevOps. The releases are handled in this way:
So, building my project is mainly the creation of the artifacts that will later be used to release a new version of the library.
The second obvious reason to automate pushing changes to a branch is to run a set of tests.
And it gives you scope for imagination as to what kind of tests you want to run. The most obvious option is unit testing. That's actually not only obvious, but also mandatory. In addition to unit tests, I also run NuGet package integration tests. In short, I test if the NuGet package installed in different types of projects works properly. For this purpose, I've created several console applications:
Pipelines build a NuGet package, install it into test applications and run these applications, expecting no errors to occur. Tests of these kind are particularly useful because the DryWetMIDI package includes native binaries. In general, tests help to make sure that all calls made to unmanaged code are correct.
You are free to create any other tests for your library. Try think about where and how your library can be used. Some use cases are quite complex to be automated. For example, DryWetMIDI is used in game development in the Unity projects, but I can't imagine how to test this Unity integration if not manually. So, when working with Unity, I do everything the same old way: open the editor, change the files, run a test script and check the debug log. I will explain the Unity work process in more detail in the Distribution options section.
Moreover, DryWetMIDI allows monitoring whether or not test pipelines are passed via Project health. Public status shows users your interest in making the project better. When you're open to public, it motivates you not to kick project's problems into the long grass and solve them as soon as possible.
To find out more information about how the documentation in DryWetMIDI works, see the Documentation section. However, in this small subsection I would like to mention that when making any changes to your project you should also auto-generate the corresponding documentation. In DryWetMIDI, the Build docs pipeline is used for this purpose. Build docs prepares the files necessary for the Release docs pipeline, which in turn deploys the site https://melanchall.github.io/drywetmidi.
Automation trigger is not limited to pushing to the repository. Some tasks can be performed on schedule.
I think it's necessary to take care even of the smallest elements of your project. Even a broken link in the documentation can make your users feel neglected. That's why DryWetMIDI has special pipelines that check several times a day in different files whether the links work:
Also, you may want to know your library usage statistic. I created an account in InfluxDB Cloud and, using the console applications and the InfluxDB.Client library to upload data from:
The corresponding pipelines are launched every day at midnight as scheduled.
In fact, it's odd enough to see a subsection on manual actions in the CI and automation section. Let me explain you what's the matter.
Sometimes users contact me with various issues or suggest a new feature. Fixing the problem and creating a new API is only half of the job. You still need to provide the changes to the user. I used to set up this process the following way:
″The fix will be in the next release. Or you can take the last version of sources from develop branch and build them to use in your application.″
It's not very user-friendly, is it? However, many developers on GitHub do it the same way, and for some people manual build is the "truest" option ever. I strongly disagree. Users should feel comfortable. Finally, I decided to make a pipeline that builds a pre-release package of a library. The pipelines (Build library prerelease and Release library prerelease) build a NuGet package with the -prereleaseN suffix in its name and then publish it. And now users are informed on the updates by the following messages:
″Changes are available in a prerelease version of the DryWetMIDI on NuGet – 6.1.2-prerelease3.″
However, I don't think that building a pre-release package for every change made to the code is necessary (since the N-number in the suffix grows with each project build, and you hardly want to have the 6.1.2-prerelease100 versions). That's why I run this pipeline manually. At the same time, it performs actions automatically. This is the reason why we're talking about it in the CI and automation section.
A NuGet package is definitely the main artifact of your development process. The majority of users will use the library API through a NuGet package. So, let's discuss it in more detail.
The nuspec file contains metadata that is required to build and set up the package. Back in the day, you had to prepare this file manually. You can still do this manually now, but it's far more convenient to keep all the project metadata in one place – in the csproj file.
You can have a look at the Melanchall.DryWetMidi.csproj file (see PropertyGroup with the Label="Package" attribute) or consult the official Microsoft guidelines – Create a NuGet package using MSBuild. As you can see, you can also specify not only the package's name, version, description, and icons, but also a repository, license, and release information. Now you can also pack the README.md file and display it on nuget.org:
<PackageReadmeFile>README.md</PackageReadmeFile>
...
<None Include="..\README.md" Pack="true" PackagePath="\" />The dotnet pack command packs the code into a NuGet package. I also specify the current branch from which the package is made within the CI pipeline.
Take the time to check the package with the NuGetPackageExplorer. Visit https://nuget.info to use NuGetPackageExplorer for Web. You can load the nupkg file from the build using the File menu. On the left side of the page you see information about the package, as it is seen by the user. Note the Health section. For my package, it looked the following way:

Figure 5. Can you see that too?
These red icons made me ask myself: what the hell? For this article, I screenshotted the information about the System.Text.Json package. Then the next question arises: why should I pay attention to these red icons when even Microsoft does not do this for its package (which has over 500 million downloads as of this writing). Maybe I shouldn't worry about that either? For me the answer is obvious – I should. All these little issues make your project look messy. That's why I think it necessary to sort the things out.
Let's firstly talk about Source Link. This technology enables debugging the source code of a third-party library. If there are debug symbols, of course. Follow the link to learn the way it works. In this article I will briefly explain how to enable Source Link for your library. Firstly, you need to insert the following elements into the csproj file:
<IncludeSymbols>true</IncludeSymbols>
<SymbolPackageFormat>snupkg</SymbolPackageFormat>Secondly, insert the element to add the Microsoft.SourceLink.GitHub package:
<PackageReference Include="Microsoft.SourceLink.GitHub" Version="1.0.0">
<PrivateAssets>all</PrivateAssets>
<IncludeAssets>
runtime; build; native; contentfiles; analyzers; buildtransitive
</IncludeAssets>
</PackageReference>Pay attention to the server you are using to host your project. It could be integrated with Bitbucket and GitLab, so be sure to add the corresponding package (Microsoft.SourceLink.YourHostingService).
Now when building a package with dotnet pack or the latest versions of nuget.exe, the snupkg file will be created along with the nupkg file, and the first red icon will change to green at https://nuget.info.
In the article mentioned above, you can see the following recommendation:
✔️ CONSIDER enabling deterministic builds.
Here it is, our second red icon. Determenistic builds enable verification that the resulting binaries were built from the specified repository and from the specified commit. Here you can find out how to enable a determenistic build in the csproj file. To build it as a part of the Azure DevOps pipelines the following elements are required:
<PropertyGroup Condition="'$(TF_BUILD)' == 'true'">
<ContinuousIntegrationBuild>true</ContinuousIntegrationBuild>
</PropertyGroup>As @HavenDV suggested in the comments, you can avoid doing the above steps manually and just use the DotNet.ReproducibleBuilds package in your project.
The last point – Compiler Flags – is rather unclear to me. I assume it means that your library should be built with .NET 5.0.300 or MSBuild 16.10 at least. So, build your packages with the latest .NET version.
When you fix everything, the information field will look like this:
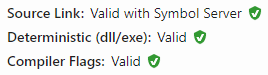
Figure 6. That's much better
Note that you can remove the package from https://www.nuget.org (although it says you can't) upon request to technical support. You can also simply unlist it. When unlisting the chosen version of the package, you remove it from the search results. For those who have already installed it, there will be no problem, the package will still be available. But this version will not appear in search, for example in Visual Studio.
After the dotnet nuget push command is executed successfully, the package is not immediately available for download, it must first be indexed. I use a very simple PowerShell script in the release pipeline that checks if a package is available and if so, the pipeline is completed:
while ($true)
{
Write-Host "Checking if version $(Version) is indexed..."
$response = Invoke-RestMethod -Uri "https://azuresearch-ussc.nuget.org/" + `
"query?q=PackageId:$(PackageId)&prerelease=$(CheckPrerelease)"
$latestVersion = $response.data.version
if ($latestVersion -eq "$(Version)")
{
break;
}
Start-Sleep -Seconds 10
}
Write-Host "Version $(Version) is indexed."Yes, I know that using a direct URL https://azuresearch-ussc.nuget.org/query is wrong, it's better to get the current address by requesting https://api.nuget.org/v3/index.json:
{
"@id": "https://azuresearch-ussc.nuget.org/query",
"@type": "SearchQueryService",
"comment": "Query endpoint of NuGet Search service (secondary)"
}But haven't I earned my right to slack off?
Another important point is the native binaries. If your API depends on the platform, you should also create native files. Your API can access the functions of these native files by using the DllImport attribute. You should box these files in the NuGet package together with the binaries. I described the whole process in detail in my other article: Creating a NuGet package for a library with a platform-dependent API.
In my opinion, you cannot consider a project to be more or less serious without documentation and reference materials. In addition, such materials free you from repeating the same answers when users have difficulties. And many questions will simply not be asked, because people will find the answers in the documentation themselves, without wasting your time.
The first thing to do is to create documentation for the API, making a complete reference to it. In .NET, there is a concept of XML documentation, also known as triple-slash comments. They allow you to place documentation comments to a method, class, etc. just before them:
/// <summary>
/// This class performs an important function.
/// </summary>
public class MyClass {}In the Recommended XML tags for C# documentation comments article, you can learn about recommended tags for XML documentation. I recommend that you read the article carefully to understand when to use a particular element.
The resulting descriptions can be large. Here is an example from DryWetMIDI:
/// <summary>
/// Represents a MIDI file.
/// </summary>
/// <remarks>
/// <para>An instance of <see cref="MidiFile"/> can be obtained via
/// one of <c>Read</c>
/// (<see cref="Read(string, ReadingSettings)"/> or
/// <see cref="Read(Stream, ReadingSettings)"/>)
/// static methods or via constructor
/// which allows to create a MIDI file from scratch.</para>
/// <para>Content of MIDI file available via
/// <see cref="Chunks"/> property which contains instances of
/// following chunk classes (derived from <see cref="MidiChunk"/>):</para>
/// <list type="bullet">
/// <item>
/// <description><see cref="TrackChunk"/></description>
/// </item>
/// <item>
/// <description><see cref="UnknownChunk"/></description>
/// </item>
/// <item>
/// <description>Any of the types specified by
/// <see cref="ReadingSettings.CustomChunkTypes"/> property of the
/// <see cref="ReadingSettings"/> that was used to read the file</description>
/// </item>
/// </list>
/// <para>To save MIDI data to file on disk or to stream
/// use appropriate <c>Write</c> method
/// (<see cref="Write(string, bool, MidiFileFormat, WritingSettings)"/> or
/// <see cref="Write(Stream, MidiFileFormat, WritingSettings)"/>).</para>
/// <para>
/// See <see href=
/// "https://www.midi.org/specifications/file-format-
/// specifications/standard-midi-files"/>
/// for detailed MIDI file specification.
/// </para>
/// </remarks>
/// <seealso cref="ReadingSettings"/>
/// <seealso cref="WritingSettings"/>
/// <seealso cref="MidiChunk"/>
/// <seealso cref="MidiEvent"/>
/// <seealso cref="Interaction"/>
public sealed class MidiFileThere is no need to be afraid of such large fragments. All IDEs highlight such comments in a different color, so it's always easy to see where the code or its documentation is.
Okay, we added documentation comments, but for what? First of all, don't forget to enable the creation of an XML file with documentation. To do this, add the following element to the csproj file:
<GenerateDocumentationFile>true</GenerateDocumentationFile>When a project is built, an XML file will now be created along with the main library binary. The file will contain information about all the documentation comments. By distributing the library with this file, you give users the ability to see tooltips that appear in the IDE when you mouse over a method, class, etc., or when you type code. And this is the first important point – the contextual help for your API.
The second one is generation of a reference guide for triple-slash comments. It seems pretty obvious to create, for example, a set of HTML pages with cross-references to your API, doesn't it? Or to create the help file. And it's possible. There are various tools for these needs, for example Sandcastle Help File Builder. For DryWetMIDI, I chose DocFX.
DocFX allows you to create a website with documentation for your project. Moreover, in addition to auto-generation of the API documentation, you can manually create separate pages in the Markdown format. The website with help on DryWetMIDI contains the following sections:
DocFX has all necessary instructions on the official website. The key element is the docfx.json file describing what the utility should do. Here you can see the file's contents in DryWetMIDI. In addition, DocFX is uploaded to Chocolatey, so it's easy to set up documentation creation within CI builds.
Note that in DryWetMIDI I only create XML documentation at the stage of release preparation, when no changes will be made to the API. This avoids the need to change the documentation comments several times before the signatures come to the final form (speaking of architecture, it's very hard to know immediately what parameters a method needs, what the relationships will be between classes, etc.).
GitHub has an option to get a site for your project for free — GitHub Pages. By default, the address is https://<user>.github.io /<project>, but you can set up your own domain. I used the simplest option:
I got the following configuration:
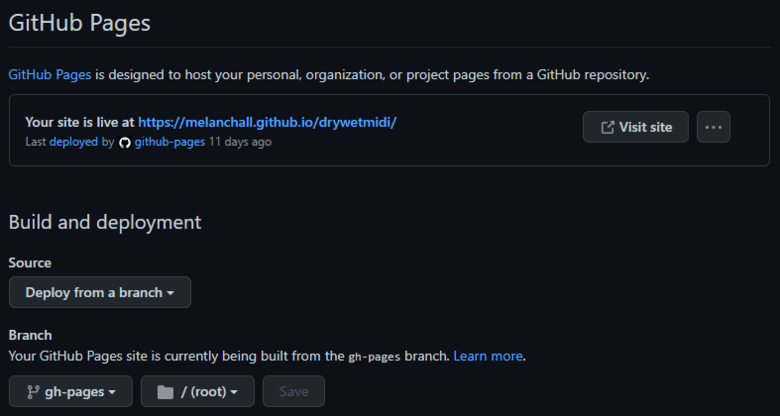
Figure 7. The site will be deployed directly from the branch
And now pushing a commit with documentation files into the gh-pages branch automatically leads to the site deployment. That is, one pipeline automatically builds the reference. The second pipeline — the release one — takes the files received by the first one at launch and pushes them into the gh-pages branch.
Also, you cannot simply ignore the README.md file at the root of your repository on GitHub. Pay attention to it, as it is the business card of your project. Give small examples of using the popular API, leave links to more detailed information, etc.
Most people will use your library through the NuGet package. This is the main way of distributing your product.
But as your project develops, users may start approaching you with questions about integration in a particular environment. For example, pretty soon after the first release of DryWetMIDI, people started writing me about the use of the library in Unity game projects. Initially, people just took the built binary files (which I distribute along with releases on GitHub) and put them in the Assets folder in the project's directory. Who is interested, the process is described in the Manual installation section in the Using in Unity article.
However, there is Unity Asset Store. Assets include model sets, textures, audio files, and software libraries. The distribution of DryWetMIDI in the form of an asset would greatly simplify the process of integration into the game project. But, in my opinion, the asset publication is not the easiest process. That forced me to postpone the publication for a long time. One of the difficulties is the need for manual actions. The package with the asset is uploaded to the publisher account from the Unity editor via another asset — Asset Store Publishing Tools. There is no API for programmatically uploading a file to an account.
But in 2022, I pulled myself together and created an asset — DryWetMIDI (by the way, the process turned out to be not so terrible, but rather long at the first publication). And now installing the library in the Unity project takes a couple of clicks.
And in this section of the article, I would like to suggest thinking about what environment your toolkit can be used in, and to create user-friendly integrations. Initially, provide manual installation instructions while you are creating such integrations.
Another interesting thing is the UWP app. Quite a long time ago, I got an issue on GitHub — the user pointed out the unsuccessful validation of his project. The reason of the unsuccessful validation was my library. Namely, calls to unmanaged code are used inside it through DllImport attributes. The point is that UWP supports a limited set of Windows APIs, and it is better to simply assume that calls to this API are forbidden (in fact, there are options). Speaking of that issue, initially, I was ready to make a separate version of DryWetMIDI, replacing the implementation of the problematic API using UWP's standard tools. Especially as there have been other issues related to the Universal Windows Platform.
As a result, I did not make a separate version for UWP. There are several reasons for that. Firstly, some articles claim that Microsoft has officially declared the platform obsolete, which is in fact confirmed by the official instructions on porting projects from UWP to the Windows App SDK. In general, the platform is rather dead. And secondly, the APIs I need work in a strange manner — I'm not happy with that. As a result, I have stopped working in this direction and have no plans to resume.
The point is that there are different technologies and environments using slightly different approaches. You may well want to implement a library for the same UWP and make life better for some percentage of users.
One user asked for a version of the library without any native code at all (to use it in the UWP application, by the way). I thought it might be a good idea. If one doesn't need an API for MIDI devices , or if API even interferes with their work for some reason, one can now download the Melanchall.DryWetMidi.Nativeless package from NuGet or DryWetMIDI.Nativeless from Unity Asset Store.
First of all, consider how version numbers are assigned to the library. One of the approaches is semantic versioning. Its main postulates are as follows:
Given a version number MAJOR.MINOR.PATCH, increment the:
1. MAJOR version when you make incompatible API changes.
2. MINOR version when you add functionality in a backwards compatible manner.
3. PATCH version when you make backwards compatible bug fixes.
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
I.e. the version is made up of three integers, and the rules for incrementing each of them are specified. By the way, there is an interesting point further in the text:
Major version zero (0.y.z) is for initial development. Anything may change at any time. The public API should not be considered stable.
What's interesting about this statement is that I've seen just a huge number of popular libraries that have been around for years, and still have the 0 major version. We do not need to go far in search of proof — BenchmarkDotNet. I honestly don't understand what the point of this is. Is it modesty? Obviously, the API of such projects has been stable for a long time.
And although the concept of semantic versioning is clear and appealing to me, I rely on it in DryWetMIDI with some deviations:
There is, of course, another approach — to almost always increase the major version. An example is well known to everyone — Google Chrome, its version at the time of writing starts with the 106 number.
Any approach is acceptable. The main thing is that you yourself understand the versioning of the library. But, regarding the backward incompatible changes, I think in such cases you should always increase the major version. This will make it clear to users: if the first number has changed, it means there has been a major change. Based on this information, user can decide whether to spend time integrating the new version or stick to the current version for the time being.
Having decided on versioning, you can proceed to the main thing. Namely, the development of the release publishing process. Below is a list of steps that are performed in DryWetMIDI. You can learn something useful from the list (or tell how flawed it is).
But the work on the release doesn't end there. Why not promote the new version additionally on specialized resources? For example, I post about releases on the midi.org forum and write about new versions of assets in the separate thread on the Unity forum.
Remember when I wrote about monitoring Stack Overflow questions by the midi tag to see if I could give an answer that contains my library? What if the answer to a question has long been given, but the code example contains an API which has been changed in a new version, or removed altogether? A person looking for a solution to their problem stumbles across your answer, tries the approach described there, and sees compilation errors when using the new version of the library. That's not acceptable. So, after the release, I look at the answers I once gave on various sites and correct them if necessary.
Also, as I provide early access to new APIs and bug fixes via pre-release NuGet packages, it's a good idea to notify users in the appropriate threads that the stable version is out:
🚀 6.1.2 version is released now!
Prerelease NuGet packages will be unlisted soon, so please update the package references to the new version.
Thanks for using the library!
After about a week (or however your heart desires) I hide the pre-release packages from the nuget.org.
The inevitable and never–ending process of working on a project is support. I don't mean code base support, but interaction with users. In passing I touched on this topic, talking about focusing on the users' needs. Here I will reflect a little more in detail.
If you take a quick look at the issues of more or less large projects on GitHub, it is likely that you will see this response from the repository owners to a user request - "we are not planning to do that, but you can open a pull request". This is a very frequent response. It doesn't seem like a bad thing when the project already exists on its own, it has a name that is recognizable in wide and not so wide circles, and people are willing to invest their time and energy into its development.
However, in the early stages of winning the hearts of users, I think this approach would be detrimental. People who want to try out your new (surely the coolest library invented and yet to be invented) library will be waiting for your active help. During this stage of the project's development, answers like "you need to do that, then do it by yourself" will turn the majority of users away from you. Therefore, be ready to dive deep into their problems, request additional information, meet their needs, and work out possible changes in the API.
Follow the specialized platforms. I am subscribed to the midi tag on Stack Exchange. For the most part, I am interested in questions from Stack Overflow, but some other websites (for example, Music) also sometimes give food for thought. I use these questions not only as ideas for the library, but also as a way to communicate with users. If the question is about MIDI, and even more so related to .NET, why not answer it by showing an example using your library? It works both as the support for users and as good promotion (because you show how to solve a problem with your product, rather than just spamming about it). It's also a good way to help people on forums and other similar resources.
Sometimes the project stops being supported. For example, let's take a look at the managed-midi library, which at the time of writing has more than 600 thousand NuGet package downloads. In one of the issues, the author writes the following:
″I welcome patches but don't plan to actively working on this project by myself unless they are relevant to my related projects.″
According to the totality of signs (few stars, few pull requests), the project did not gain critical mass for independent life, and died due to the lack of support from the author. And although it may look sad for us, the developer, as we understood, did the project more for their needs.
Projects for personal use, diploma theses, "hello worlds" of newbies' — all these are very common on GitHub. I don't criticize repositories with this kind of code in any way. However, the article focuses on developing a library to solve the problems of a wide range of people. If you feel burned out and the project is no longer makes you happy, try to find someone who can pick it up and develop it further.
We looked at many aspects related to the development of the library, and in general the software product. I hope this article will inspire someone and encourage them to put their ideas into practice and be a good guide for someone else.
You can tell by how long the article is, how much more there is to come up with and do. Maybe some lines have caused you a storm of indignation, or you see room for further action. Anyway, if you have something to say, I would be happy to get your feedback.
0
0
0
0