
Our website uses cookies to enhance your browsing experience.

Or why one shouldn't be afraid of convenient things.

Wait! Get your hands off the keyboard, let the man speak! There are good reasons for this article, and it serves a good purpose! In my previous article on arrays (which isn't necessary to read for grasping the current one), some readers expressed concern that std::array might be slower than the built-in C array.
Several sources of truth exist on this matter, and today we'll go through each of them. Let's first find out what the standard states about it, then look at the std::array implementations in libc++ and libstdc++, and finally look at the assembler of some operations on these objects. Oh, and we'll top it off with benchmarking, of course.
The standard doesn't provide any information to help us with the dilemma. We will refer to the draft of the latest freely available version. The 24.3.7 [array] paragraph describes general requirements for std::array and its interface, but this is where the description ends. Okay, we checked that off our list, now let's get to the code!
No matter what the standard says, we programmers have to deal with specific implementations. Let's take a look at two of them: one from the LLVM project (libc++) and the other from the GNU project (libstdc++). There's plenty of interesting things that we're just looking for!
Let's start with the easy part. How are the collection elements stored?
template <class _Tp, size_t _Size>
struct _LIBCPP_TEMPLATE_VIS array {
//...
_Tp __elems_[_Size];
//...
};Elements of the _Tp type are stored as, well... a built-in C array. A single demonstration isn't enough, of course, so let's dig a little deeper.
How are the elements accessed?
_LIBCPP_HIDE_FROM_ABI _LIBCPP_CONSTEXPR_SINCE_CXX17 reference
operator[](size_type __n) _NOEXCEPT {
_LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(
__n < _Size, "out-of-bounds access in std::array<T, N>");
return __elems_[__n];
}
_LIBCPP_HIDE_FROM_ABI _LIBCPP_CONSTEXPR_SINCE_CXX14 const_reference
operator[](size_type __n) const _NOEXCEPT {
_LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(
__n < _Size, "out-of-bounds access in std::array<T, N>");
return __elems_[__n];
}Aha! There's some kind of a _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS check! So, indexing takes longer!
Let's get to the bottom of this. LLVM has a hardening mechanism called _LIBCPP_HARDENING_MODE. We can use it to enable additional checks depending on the mechanism level, which has a total of four levels. Enabling the weakest one removes the checks from the code. In other cases, there may or may not be a check, depending on the check and the level of the mode. We'll prove it.
To understand what expands to what, we need to look at the source code. There, we see that depending on the given value of _LIBCPPP_HARDENING_MODE, _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS may expand to _LIBCPPP_ASSERT.
#define _LIBCPP_ASSERT(expression, message) \
(__builtin_expect(static_cast<bool>(expression), 1) \
? (void)0 \
: _LIBCPP_ASSERTION_HANDLER(__FILE__ ":" \
_LIBCPP_TOSTRING(__LINE__) ": assertion " \
_LIBCPP_TOSTRING(expression) " failed: " \
message "\n"))The __builtin_expect compiler intrinsic (a built-in function implemented in the compiler) specifies the most likely value of an integer expression, which can help the processor by giving hints during branch prediction. This suggests that such checks in production code don't affect performance much. But let's look beyond that. What does _LIBCPP_ASSERTION_HANDLER expand to? According to this and this code, they expand to either __builtin_abort, __builtin_verbose_trap, or __libcpp_verbose_abort. In other words, they expand to the compiler intrinsic that makes the program crash, just like the std::abort library function.
Good. When the hardening mechanism is enabled, it validates whether the index is within the array bounds, which may slow down program execution.
If the mechanism is disabled, the _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS macro expands to the _LIBCPP_ASSUME macro, which is defined as follows:
# define _LIBCPP_ASSUME(expression) ((void)0)No checks, just a harmless useless operation. There will be no slowdown in this case.
Note that enabling and disabling additional checks has nothing to do with the build type. They may or may not be present in both release and debug versions. Only the hardening mechanism controls them, as we could see when examining the code above. -DNDEBUG has nothing to do with it.
The hardening mechanism was introduced in LLVM 18, replacing the _LIBCPP_ENABLE_ASSERTIONS mechanism. According to the source code, this setting is equivalent to the extensive mode.
You can learn more about the hardening mechanism in the code comments or from the developers' post.
Did we miss anything?
In theory, the iteration through the range-based loop could suffer from replacing the built-in array with std::array. As we learn from the standard ([stmt.ranged]), such iteration over a built-in array uses native pointers. Otherwise, it uses iterators obtained via begin and end respectively (methods or free functions). In the case of std::array, iterators are used. How are they defined?
using value_type = _Tp;
using pointer = value_type*;
using const_pointer = const value_type*;
#if defined(_LIBCPP_ABI_USE_WRAP_ITER_IN_STD_ARRAY)
using iterator = __wrap_iter<pointer>;
using const_iterator = __wrap_iter<const_pointer>;
#else
using iterator = pointer;
using const_iterator = const_pointer;As we can see, in some cases, a regular pointer is used, just like when iterating over built-in arrays. However, the _LIBCPP_ABI_USE_WRAP_ITER_IN_STD_ARRAY macro is always defined, as indicated in the file that contains it. So, the iteration is done using a wrapper over the pointer - __wrap_iter. As we can see from the code, this iterator is used in containers that guarantee the contiguous order of elements in memory, such as std::basic_string, std::basic_string_view, std::vector, std::span, and our buddy std::array.
Why do we need such a wrapper? Based on the code comments and, for example, this discussion, we can conclude the following: __wrap_iter is needed so that the generic client code knows the iterator points to an element located in contiguous memory block. There are also more elements after that element. Note, such wrapping is used only in containers that guarantee the elements are stored contiguously in memory. So, a function template taking std::array<T,S>::iterator knows for sure that the iterator points to the contiguous memory block. Actually, a random iterator doesn't have to do this, and neither does a regular pointer. By the way, here are a few more reasons why standard library implementations often don't use a regular pointer as an iterator over containers.
But let's get back to the question of how much such wrappers affect performance. Technically, I haven't found anything in the above implementation that would slow down the program. For example, accessing the element with this iterator doesn't involve any checks, even with the hardening mechanism enabled. After all, this wrapper is very thin. Of course, as we introduce new templates into the program, compilation time and object file sizes will increase. But we're talking about performance here, right?
On that note, let's finish with the LLVM implementation.
Moving on to how std::array is implemented in the GNU project. How are elements stored?
template<typename _Tp, std::size_t _Nm>
struct array {
//...
typename __array_traits<_Tp, _Nm>::_Type _M_elems;
//...The __array_traits<_Tp, _Nm>::_Type is an alias of the stored array type. By using this utility class, developers can get a zero-length std::array that behaves differently from other std::arrays. Usually, _Type is an array type carried by the std::array object, but the __array_traits<_Tp, 0>::_Type overrides _Type and implements some operators in its own way. For example, the subscript operator calls __builtin_trap. By the way, the LLVM implementation of std::array fixes the same issue with a separate partial specialization of std:: array<_Tp, 0>.
Okay, the array is stored just like regular arrays in most cases. How does indexing work?
[[__nodiscard__]]
_GLIBCXX17_CONSTEXPR reference
operator[](size_type __n) noexcept
{
__glibcxx_requires_subscript(__n);
return _M_elems[__n];
}
[[__nodiscard__]]
constexpr const_reference
operator[](size_type __n) const noexcept
{
#if __cplusplus >= 201402L
__glibcxx_requires_subscript(__n);
#endif
return _M_elems[__n];
}Again, the situation is similar to what we saw in the LLVM implementation: there's a check, and only after that indexing is done. The __glibcxx_requires_subscript macro is defined as follows:
#ifndef _GLIBCXX_DEBUG
// ....
# define __glibcxx_requires_subscript(_N) \
__glibcxx_assert(_N < this->size())
// ....
#else // Use the more verbose Debug Mode checks.
// ....
# define __glibcxx_requires_subscript(_N) \
__glibcxx_check_subscript(_N)
// ....Interesting. So, the check is present in the code all the time, right? First, let's explore the case when the _GLIBCXX_DEBUG macro isn't defined. Given that, we'll check it with __glibcxx_assert. This is how it's defined:
#if defined(_GLIBCXX_ASSERTIONS)
// Enable runtime assertion checks, and also check in constant expressions.
# define __glibcxx_assert(cond) \
do {\
if (__builtin_expect(!bool(cond), false)) \
_GLIBCXX_ASSERT_FAIL(cond); \
} while (false)
#elif _GLIBCXX_HAVE_IS_CONSTANT_EVALUATED
// Only check assertions during constant evaluation.
namespace std
{
__attribute__((__always_inline__,__visibility__("default")))
inline void
__glibcxx_assert_fail()
{ }
}
# define __glibcxx_assert(cond) \
do {\
if (std::__is_constant_evaluated())\
if (__builtin_expect(!bool(cond), false)) \
std::__glibcxx_assert_fail(); \
} while (false)
#else
// Don't check any assertions.
# define __glibcxx_assert(cond)
#endifAs we can see from the else branch, there are cases when the macro expands to nothing, i.e. there will be an empty ";" expression in the code.
The _GLIBCXX_ASSERTIONS case is referred as "debug mode lite" and is designed to enable some asserts without defining the _GLIBCXX_DEBUG macro. We can also enable this macro via the hardened checkbox, which is the analog of the LLVM mode. So, we can choose to disable it if we want to.
The case of _GLIBCXX_HAVE_IS_CONSTANT_EVALUATED is a little more intriguing. It's defined here (twice), inside the body of the std::__is_constant_evaluated function that is called in the check. This function enables us to execute a code block only if it's executed in a constant-evaluated context. In other words, at compile time. In other words, not at run-time. In other words, we won't be sacrificing performance because this code isn't present at runtime.
If the _GLIBCXX_DEBUG macro is defined, __glibcxx_requires_subscript expands to __glibcxx_check_subscript, which expands to _GLIBCXX_DEBUG_VERIFY. What happens next isn't our concern, since we're focused on the performance of release builds, not of debug builds.
What happens when iterating through the range-based loop? Let's look at how iterators are defined via std::array (we'll skip constant iterators this time and ask the reader to trust or test for themselves whether they're implemented in a similar way).
typedef _Tp value_type;
typedef value_type* pointer;
typedef value_type* iterator;As we can see from the code, regular iterators are defined as native pointers. What do begin and end return?
// Iterators.
[[__gnu__::__const__, __nodiscard__]]
_GLIBCXX17_CONSTEXPR iterator
begin() noexcept
{ return iterator(data()); }
[[__gnu__::__const__, __nodiscard__]]
_GLIBCXX17_CONSTEXPR iterator
end() noexcept
{ return iterator(data() + _Nm); }
}
[[__nodiscard__, __gnu__::__const__, __gnu__::__always_inline__]]
_GLIBCXX17_CONSTEXPR pointer
data() noexcept
{ return static_cast<pointer>(_M_elems); }Well, there's not much to look into. Functions return pointers to the first element and to the element following the last.
We've looked at the std::array implementations from two major compiler builders. We, the author, haven't found a single fragment in any of them that would cause a slowdown in production. Of course, we, the author, are ready to discuss this in the comments.
But let's not dwell on the source code. Maybe std::array compiles into something fundamentally performance-inefficient?
Using several operations as examples, let's see what assembler the compiler can get. We're using the latest Clang for the x86-64 platform available on Compiler Explorer.
Let's start with a simple iteration over the array and over std::array, filling both of them sequentially with random numbers.
The prologue of both functions is identical, as memory is allocated and then zeroed:
push rbp
mov rbp, rsp
sub rsp, 4032 ; allocated memory
lea rdi, [rbp - 4000]
xor esi, esi ; decided what we'll use for zeroing
mov edx, 4000
call memset@PLT ; zeroedThe code for retrieving iterators is different, which is expected. In the case of arrays, the pointers that enclose the array are loaded:
lea rax, [rbp - 4000] ; got the begin value
mov qword ptr [rbp - 4008], rax ; saved the begin value
mov rax, qword ptr [rbp - 4008]
mov qword ptr [rbp - 4016], rax ; saved the iterator value
mov rax, qword ptr [rbp - 4008]
add rax, 4000 ; got the end value
mov qword ptr [rbp - 4024], rax ; saved the end valueThe assembly of the std::array option differs only in that the respective methods are called to get the iterators. The rest is the same.
lea rax, [rbp - 4000]
mov qword ptr [rbp - 4008], rax
mov rdi, qword ptr [rbp - 4008]
call std::array<int, 1000ul>::begin()
mov qword ptr [rbp - 4016], rax
mov rdi, qword ptr [rbp - 4008]
call std::array<int, 1000ul>::end()
mov qword ptr [rbp - 4024], raxThe iteration code is exactly the same (except for the labels used for jumps).
.LBB8_1: ; compared the iterators
mov rax, qword ptr [rbp - 4016]
cmp rax, qword ptr [rbp - 4024]
je .LBB8_4 ; got out of the loop if necessary
mov rax, qword ptr [rbp - 4016]
mov qword ptr [rbp - 4032], rax ; got the element address
lea rdi, [rip + dis]
lea rsi, [rip + gen]
call int std::uniform_int_distribution ; a lot of text
mov ecx, eax
mov rax, qword ptr [rbp - 4032]
mov dword ptr [rax], ecx ; saved the new value
mov rax, qword ptr [rbp - 4016]
add rax, 4
mov qword ptr [rbp - 4016], rax
jmp .LBB8_1
.LBB8_4: ; got out of the function
add rsp, 4032
pop rbp
retAs we can see from the example, the functions are nearly identical. If we tweak the code a bit and enable the O3-level optimizations, they will be completely identical (except for the labels). In case of std::array, there will be no calls to the begin and end methods.
One reason against using std::array may be that if we pass it to a function by reference, accessing its elements leads to additional indirection . Let's check if it's true. This time we'll pass an array and a the std::array object to the functions. To make it fair, we'll access a random element.
As we can see from the generated assembly code, the instructions are almost identical. We'll focus only on the parts that differ, starting with write operation to a regular array.
mov edx, dword ptr [rbp - 28] ; read the new value
mov ecx, eax ; read the index
mov rax, qword ptr [rbp - 24] ; read the pointer value
movsxd rcx, ecx ; convert
mov dword ptr [rax + 4*rcx], edx ; write the new valueThis write operation takes five instructions, one addition, and one multiplication. In the case of std::array, things are a bit different.
mov rdi, qword ptr [rbp - 32] ; a pointer to the first element
movsxd rsi, eax ; index
call std::array< >::operator[] ; get the pointer to the element
mov ecx, dword ptr [rbp - 20] ; read the new value
mov dword ptr [rax], ecx ; write the new valueHere, an additional call to the operator[] member function occurs, which returns an lvalue reference to the std::array element. The same address arithmetic as in the previous case is likely to occur within this function: [rax + 4*rcx]. This might indeed be a bit slower (due to an extra function call).
But what would happen if we enabled all the optimizations? The assembler would become exactly the same (except for the labels, of course). There would be no call to operator[] at all.
By the way, we somewhat skipped the topic of dual indirect addressing. Most thoughtful readers might say that when passing std::array by reference to a function, we encounter double indirection. So, when we want to access an element, we need to get the object first, and then access the array stored in it. As we've seen, it doesn't happen, at least not in the code with the optimization enabled.
Okay, without optimizations enabled, the compiler generates different code for operations over array and std::array. While the differences are minor, they still exist. Perhaps in some cases, for certain operations and scales, this may not work best for std::array. When optimizations are enabled there's really no concern about slowdowns because the code is just the same.
Since we're talking about performance, why don't we compare these two entities and do a little benchmarking?
Benchmarking is a thankless task that's also not always reliable. Test results can vary from one machine to another, from one compiler to another, and even from one run to another. So, we use it as an additional source of truth on our valiant quest for better performance, but not as its primary measure.
As with the assembly code analysis, let's look at two types of operations: sequentially filling an array with random numbers, and randomly accessing arbitrary array elements when we pass it to a function. To compile the code, we used GCC and Clang. We checked both debug (with the -DDEBUG flag) and release builds (with the -O3 level optimizations and the -DNDEBUG flag). And of course, we used Google Benchmark to run the tests.
The author's setup:
We ran each test on arrays and std::array of different sizes, fully utilizing the first, second, and third caches, respectively. Each test was run for 10,000 iterations to roughly even out results.
Technically, we could do with one graph instead of six since the ratio between the different builds is the same for all cache lines, only the absolute numbers change. However, we'll show all the results for the sake of clarity.
The Y-axis shows the time taken to run 10,000 iterations of each test in nanoseconds.
Let's start with the results of sequential memory fill tests.
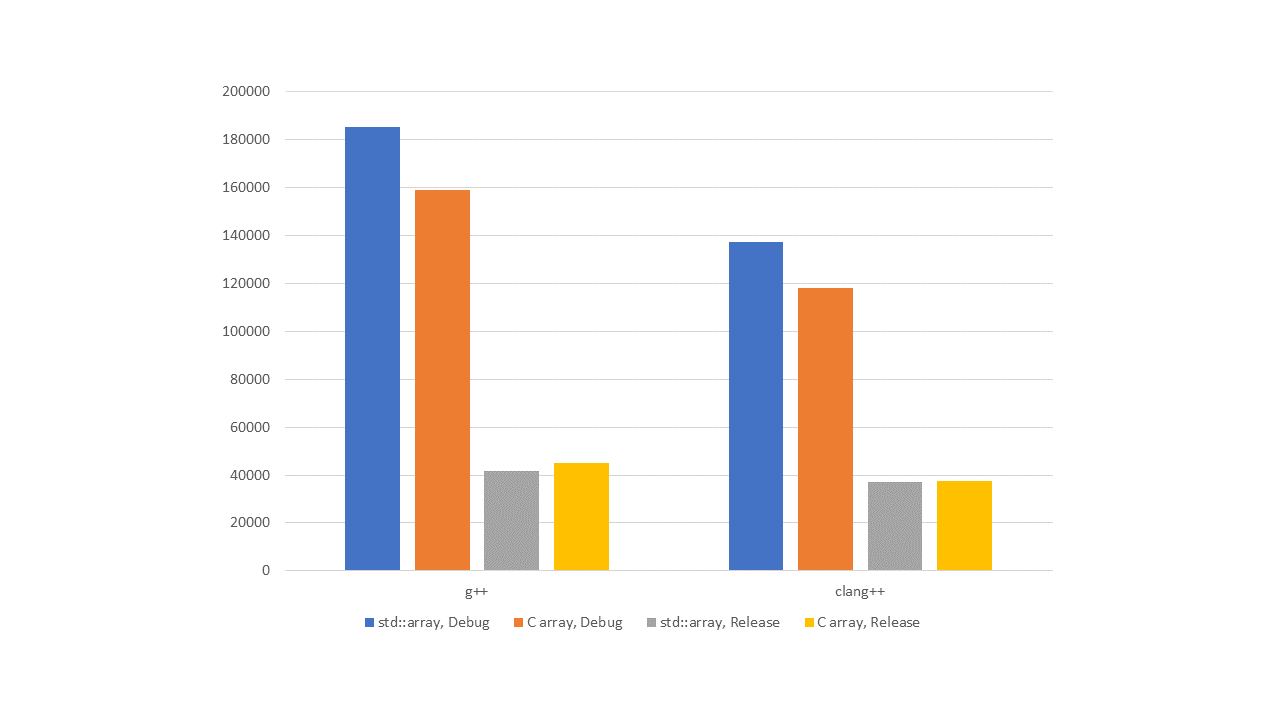
Figure 1 — L1, sequential indexing
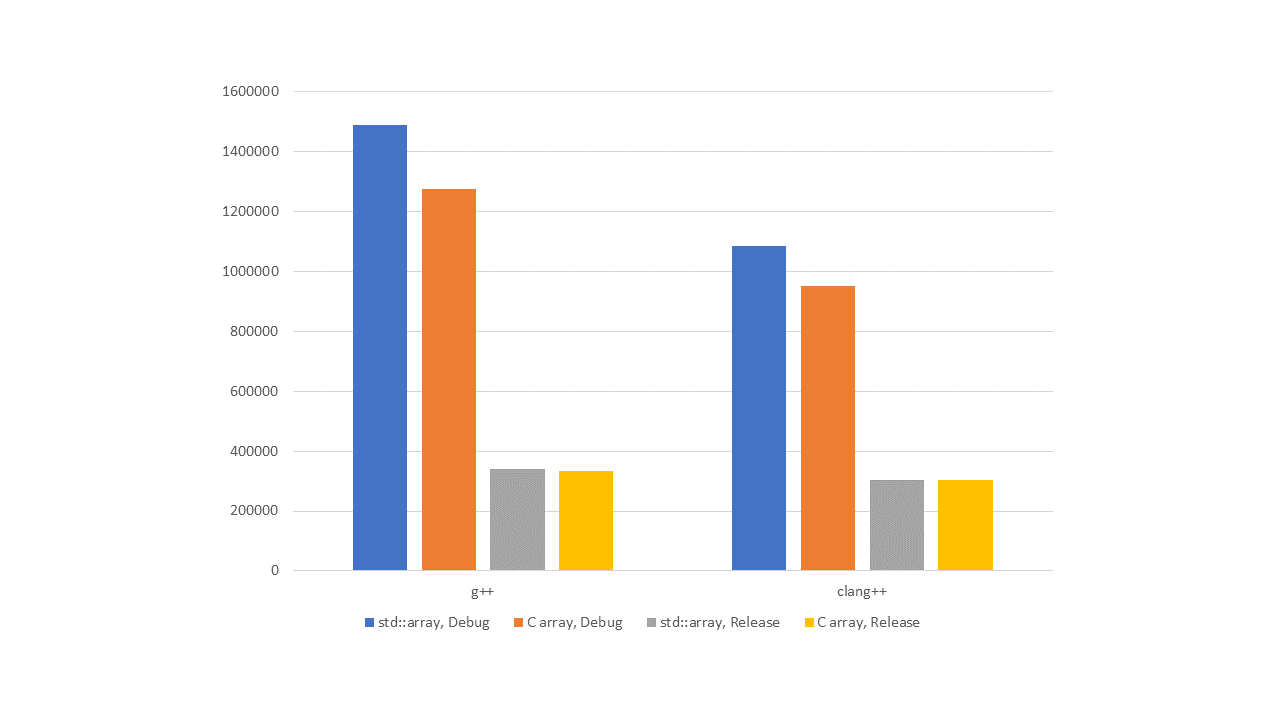
Figure 2 — L2, sequential indexing
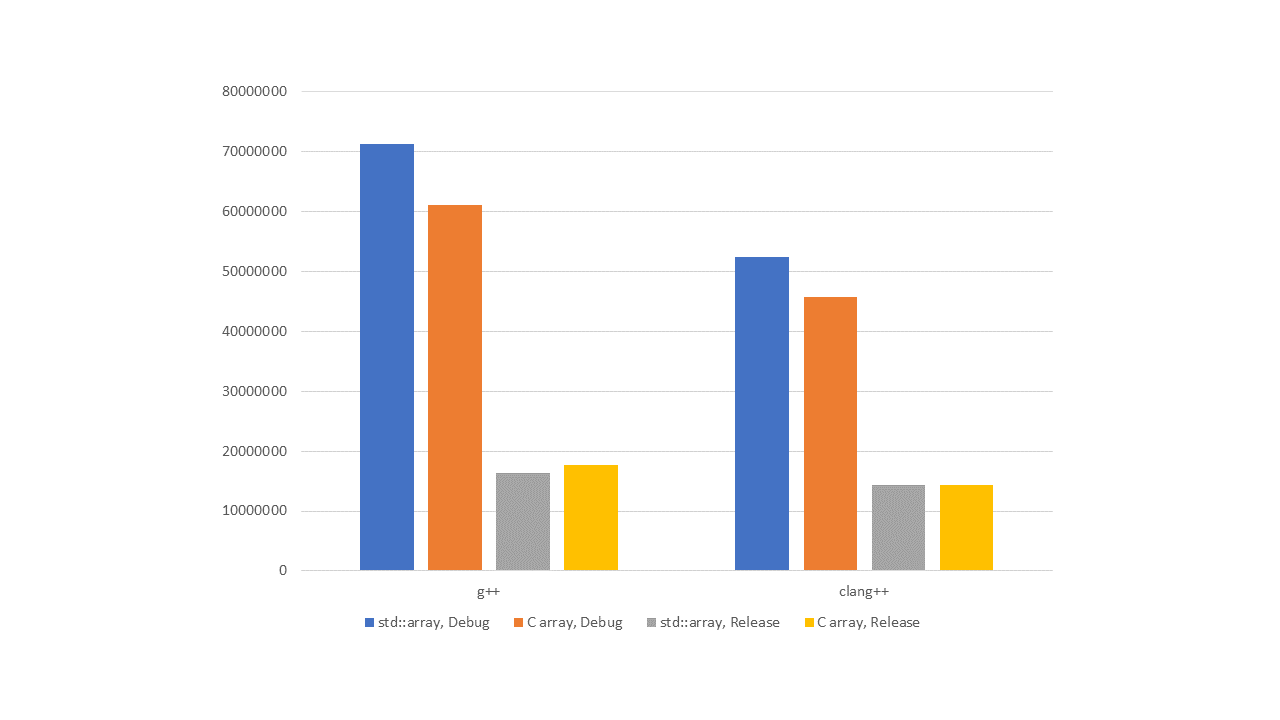
Figure 3 — L3, sequential indexing
As we can see from the graphs, in debug versions, std::array performs worse than the built-in array. Of course, we've seen higher up in the article calls to the operator[] function appear in the assembler. They are slower than direct array addressing. In addition, by examining library implementations, we've shown that when we use std::array, sometimes there are additional checks for array overrun.
But as soon as we enable optimizations, everything changes. Not sure about you, but the author doesn't see any breaking difference in performance. There are no slowdowns in std::array compared to the built-in array.
Are random memory access tests somehow different? Let's see.
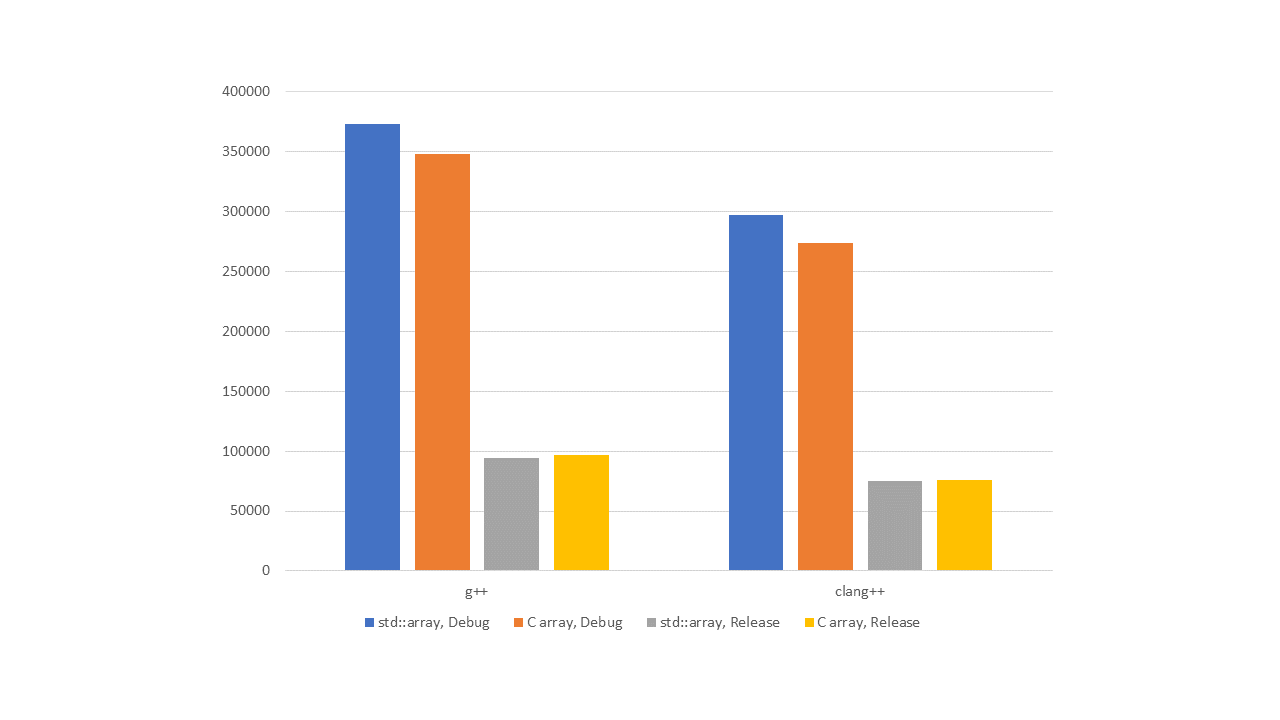
Figure 4 — L1, random indexing
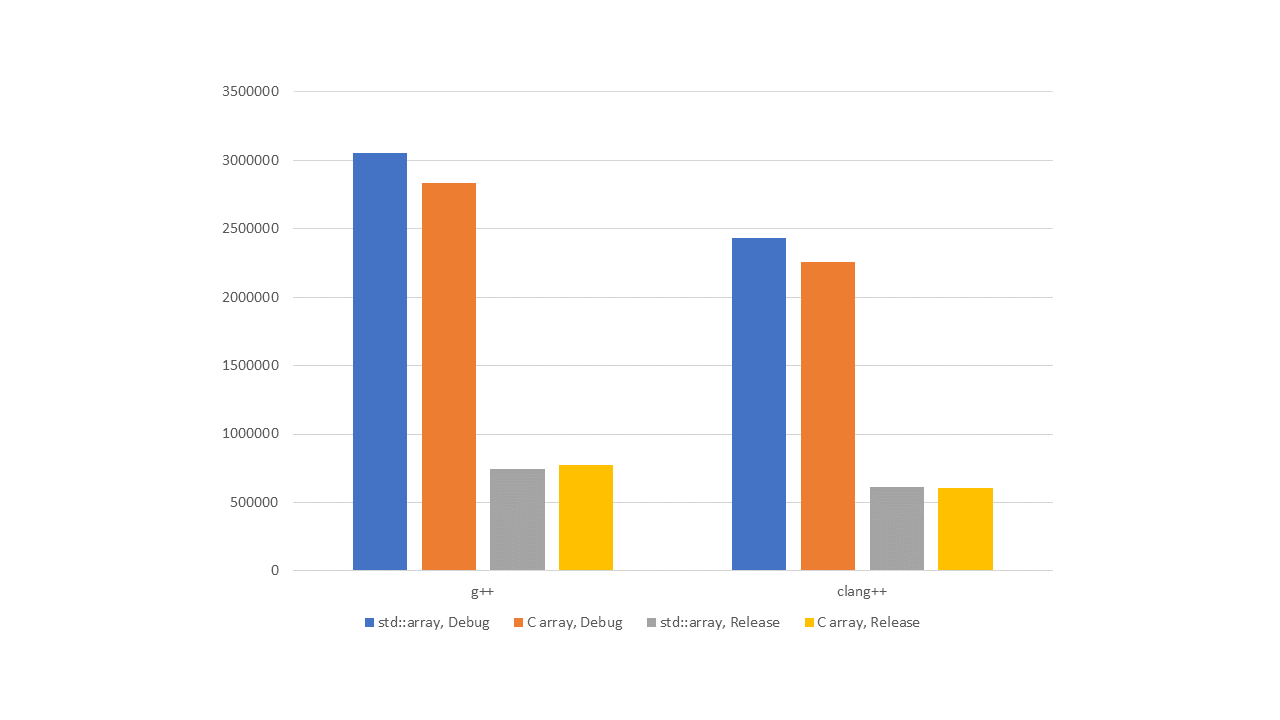
Figure 5 — L2, random indexing
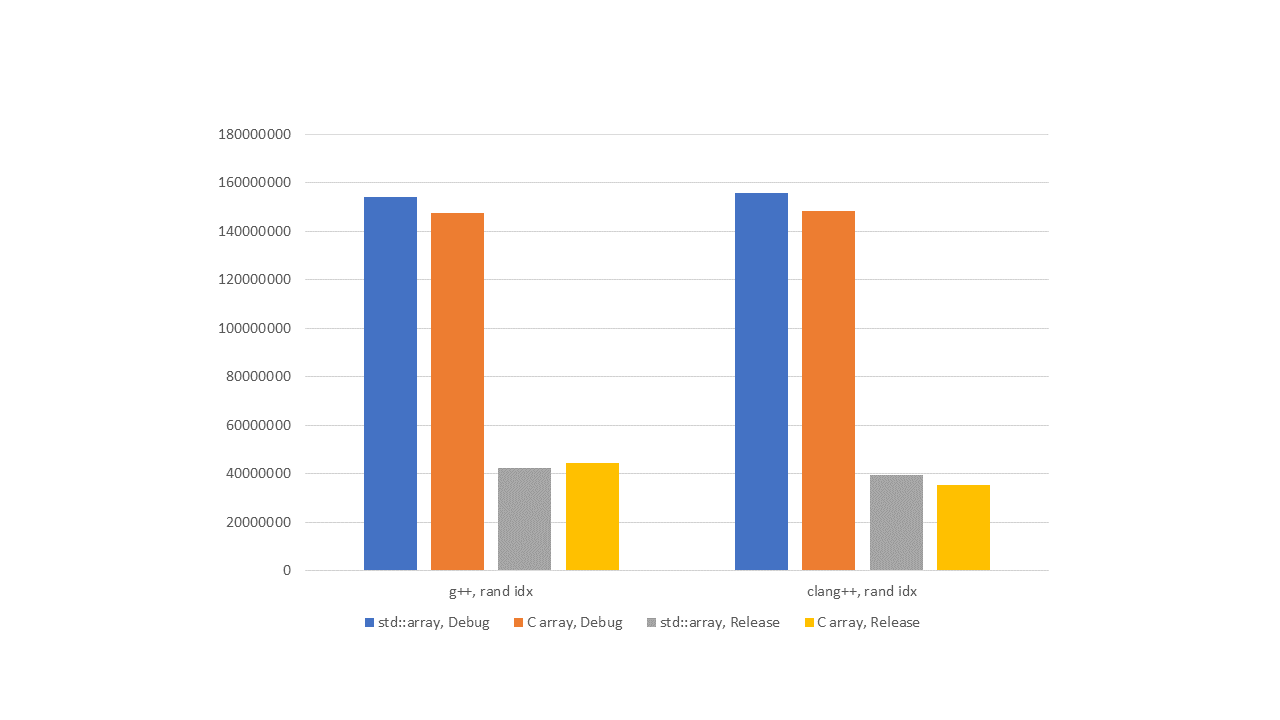
Figure 6 — L3, random indexing
Except for the increased elapsed time, the graphs are the same.
Let's say we've convinced you that switching to std::array isn't that scary. What concerns may keep you from doing this (assuming it's a new project, and you don't have to rewrite the old code)?
For example, consider the growing object file sizes (the worst-case scenario). Imagine this: a programmer used to have a function that could take a pointer and a length, and it worked just fine:
void foo(int *arr, size_t len)
{
/* ... */
}Now they want to change it to use std::array:
template<std::size_t N>
void bar(std::array<int, N> arr)
{
/* ... */
}Once this change is made, they'll need to use templates! Even if our hypothetical foo function previously used templates to deduct the type of an array element, the new bar implementation deducts sizes of the arrays too. This leads to a proportional increase in the size of object files, because different functions are instantiated in the type*size quantity instead of just type, like when passing a built-in array to a function.
If your project uses C++20, std::span can be a handy replacement here:
void bar(std::span<int> s)
{
/* ... */
}The std::span class is a light wrapper around a pointer to contiguous memory, which also stores the size of that memory. We can iterate over it, we can index it, and we can build it from std::array. We could say it acts like a handy pointer to the entire array. The array size can either be stored inside the object or passed as a template argument (for this, we have a second parameter that takes the std::dynamic_extent constant value by default).
In fact, the class carries a certain philosophical elegance. Since the early days of pure C, arrays have been in limbo—neither fully objects nor pointers to the first element. With the introduction of std::span, this dichotomy has effectively been split into two distinct classes: std::array behaves purely as an array, and std::span acts only as a pointer (that abstracts a particular container away from a programmer). Neat! No need for custom wrappers.
As a result, the array is stored where it should be as std::array. Its objects can be passed to functions that use them as objects of the std::span class.
In addition, by switching to std::array, we get built-in checks for array overflows when debugging (as we've seen in the benchmarking section), easier code maintenance and extension, and the capability to abandon custom utilities for handling built-in arrays. And, most importantly, the std::array objects behave consistently like full-fledged objects instead of turning into pointers whenever they get the chance.

That's it. The std::array container is a solid alternative to built-in C arrays, since it lacks many of their drawbacks. If having a standard library in a project isn't forbidden, why not taking advantage of a handy abstraction instead of the built-in feature? After all, we pay the same price for both.
If you have any thoughts on this, we'd love to see you in the comments!
Thank you for reading to the end! El Psy Kongroo.
0
0
0


0