
Our website uses cookies to enhance your browsing experience.

For a start, it is worth to remember what is vulnerability, and why one shouldn't trust data received from outside. The vulnerabilities are simple bugs that will make you famous all over the Internet. More formally - it's a system flaw, which allows to disrupt its integrity intentionally, cause malfunction, remove or modify private data. Obviously, you should protect your software from vulnerabilities of this kind by all means.

One of the loopholes, through which an intruder can negatively use your system is data, that comes from the outside, more precisely - excessive trust for this data. This could be expressed, for example, in the absence of check to meet certain requirements that guarantee proper program operation.
How can we make such a mistake to use external data without a check? Everybody knows the simple truth - "first test - then use".
There are a few obvious explanations:
As for the sources of incorrect data, everything should be clear. This is the data received from the server, user input, external files, environment variables, etc.
For better understanding how problem situations look like, it's better to set eyes on examples of actual vulnerabilities.
Let's start with a fairly well-known vulnerability found in OpenSSL CVE-2014-0160, also known as Heartbleed. This is an interesting fact that vulnerability was added to OpenSSL repository in December 2011, and closed only in April 2014. At the time of reporting about the vulnerability, number of vulnerable assailable Web sites was terrifying and constituted half a million, representing approximately 17% of protected Internet Web sites.

The error contained in the extension for TSL - Heartbeat. Without going into details, let's note that during the work a client and a server were constantly exchanging random length packages and maintained a connection in the active state. The query consisted of payloads, and as well as its length.
The problem was that by forming an incorrect request in which the specified length of payload exceeds its actual length, it was possible to obtain private information during the reply, as when generating the reply the correspondence of the actual and specified lengths wasn't checked. Thus, it was possible to read data from RAM of size up to 64 Kb per request. Much data from memory could be read using multiple repeating of error exploitation.
Confusing code looked as follows:
int tls1_process_heartbeat(SSL *s)
{
unsigned char *p = &s->s3->rrec.data[0], *pl;
unsigned short hbtype;
unsigned int payload;
unsigned int padding = 16; /* Use minimum padding */
/* Read type and payload length first */
hbtype = *p++;
n2s(p, payload);
pl = p;
....
}As it was mentioned above, the number of bytes for the return request was copied in accordance with the value of the payload, rather than the actual length of the payload.
memcpy(bp, pl, payload);The problem was solved by adding two checks.
The first of them was checking that the payload length was non-null. The message was simply ignored, if the length of the payload was zero.
if (1 + 2 + 16 > s->s3->rrec.length)
return 0;The second check was verifying if the specified length value corresponded with the actual length of the data payload. Otherwise, the request is ignored.
if (1 + 2 + payload + 16 > s->s3->rrec.length)
return 0;In the end, after adding the appropriate checks, data reading code became as follows:
/* Read type and payload length first */
if (1 + 2 + 16 > s->s3->rrec.length)
return 0;
hbtype = *p++;
n2s(p, payload);
if (1 + 2 + payload + 16 > s->s3->rrec.length)
return 0; /* silently discard per RFC 6520 sec. 4 */
pl = p;Another vulnerability has an identifier CVE 2017-17066, also known as GarlicRust. It was found in the Kovri and i2pd projects - I2P implementations in C++, and led to data leak from RAM when sending specially crafted messages (Doesn't that remind you of something?). The irony is that in this case, the necessary check was in code, but it was performed only after sending the reply.
In i2pd the vulnerability was closed several hours later after receiving information about it, and the fix was included in the version 2.17. In case of Kovri, the fix was commited in the master-branch on GitHub.
Problem code (reduced) is given below:
void GarlicDestination::HandleGarlicPayload(
std::uint8_t* buf,
std::size_t len,
std::shared_ptr<kovri::core::InboundTunnel> from)
{
....
// Message is generated and sent until performing
// the necessary check
if (tunnel) {
auto msg = CreateI2NPMessage(buf,
kovri::core::GetI2NPMessageLength(buf), from);
tunnel->SendTunnelDataMsg(gateway_hash, gateway_tunnel, msg);
} else {
LOG(debug)
<< "GarlicDestination:
no outbound tunnels available for garlic clove";
}
....
// Check in progress. After the message has been
// sent
if (buf - buf1 > static_cast<int>(len)) {
LOG(error) << "GarlicDestination: clove is too long";
break;
}
....
}It won't be a difficulty to find other vulnerabilities that arise from excessive trust to external data and lack of checks. Take at least some vulnerabilities from OpenVPN. But we will no longer linger here - let's see how much correction of such errors will cost you and how to deal with it.
It is a fact that the longer an error stays in code, the higher is complexity and cost of its fixing. As for security defects - everything is more critical here. Based on data from the National Institute of Standards and Technology of the United States (NIST), PVS-Studio team created a picture showing the cost of security fixes at different stages of the software life cycle.
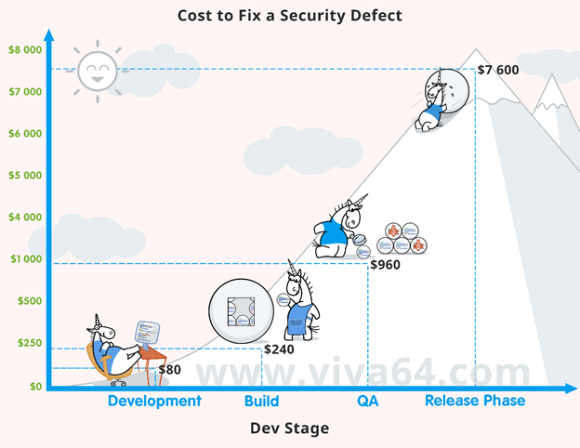
Hardworking unicorns and laughing sun look very pretty, until you pay attention to the figures. The picture perfectly illustrates the statement in the beginning of the section: the sooner the error is found - the better (and cheaper).
Note that the listed figures are average. Some security defects do not lead to noticeable effects and are just gradually eliminated. Others become known to the whole Internet and incur losses worth millions of dollars. It is a luck of the draw... Or rather a bad luck.
Gradually, after ascertaining the causes and sources of dangerous data, as well as looking at how unsafe/insecure code looks in practice, we come to the basic question - how to secure the application?
The answer is obvious - to check the external data. However, as we have considered above, the mere knowledge of this fact is not enough. Hence, it would be nice to take additional measures to identify such places.
One should understand that there is fine line between simple errors and vulnerability - remember if only the critical vulnerability CVE-2014-1266 from iOS (although it seems very innocuous - just two goto operators one by one). That's why it's so important to take focus on improving the quality of the software in general. Within this article, we will focus on two automated techniques of code checking - static analysis and fuzzing.
Fuzzing is a testing technique, consisting of passing to the application incorrect / unexpected / random data and tracking the system's behavior. If during the fuzzing testing the system hung up / crashed / behaved incorrectly — this is an indication of an error.
Unlike the static analysis, fuzzing identifies problems that exactly occur during the work of your application. In other words, such approach is deprived of false alarms. And this is the great advantage of it.
But, of course, such an approach has several disadvantages: only available (executable) interfaces are analyzed, multiple program performance with different sets of data is needed. It is also important to remember about preparing a special environment for fuzzing, to not to damage the main / working one accidentally.
Vulnerabilities / errors search in code using static analysis goes by the research of program code without executing programs. The negative side of static analysis the presence of false alarms (it is worth noting that the number of them can be reduced by a correct analyzer configuration). The advantages - the coverage of the entire code base, no need to run the application, generate data on input.
Thus, static analysis is a good candidate for searching of dangerous data, from the point of view that it is possible to detect the problem sooner (thus cheaper to fix), and it does not require input data sets. You wrote problem code, ran the project build, then the static analyzer started automatically and said: "Buddy, you take data from the outside and use it in here. And who is going to check? "
Although static analysis is typically used for diagnosing errors in general, the team of PVS-Studio static analyzer, recently became interested in the topic of searching vulnerabilities and is currently working on a solution for detecting the use of tainted data without prior check.
Quite possibly, you have a question - what is better to use - static analysis or fuzzing? The answer is simple - both. They're not mutually exclusive, but complementary means, each with its own advantages and disadvantages. Dynamic analyzers work long, but hit the bull's eye, static - do it significantly faster, but sometimes miss a shot. Dynamic analyzers are able to identify those errors that are not so easy to detect by static analyzer. But the reverse is equally true!
If you look at Microsoft Security Development Lifecycle, you can see that it includes both static analysis (implementation phase) and fuzzing (verification phase).
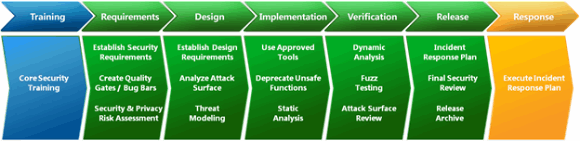
The moral is simple: both techniques answer the question "What else can I do to improve the quality of software?" and for best effect use them together.
Do not trust the data coming from the outside, as much as possible. Check not only the fact of receiving data, but also see what exactly you received. Use automated tools to search places, working with external data not verifying them. And then, perhaps, your application will be able to become famous in a nicer way than the mention in the list of CVE.
0
0
0
0