
Our website uses cookies to enhance your browsing experience.

Many programmers know firsthand that C and C++ program builds very long. Someone solves this problem by sword-fighting at build time, someone is going to the kitchen to "grab some coffee". This article is for those who are tired of this, and who decided it is time to do something about it. In this article, various ways of speeding up compilation time of a project are regarded, as well as treatment of a disease "fixed one header - a half of a project was rebuilt".

Before we start, let's find out/recall the main phases of the translation of C/C++ code into an executable program.
According to p. 5.1.1.2 of the draft N1548 "Programming languages — C" and p.5.2 N4659 "Working Draft, Standard for Programming Language C++"(published versions of the standards can be purchased here and here), 8 and 9 translation phases are defined respectively. Let's leave out the details and consider the translating process in the abstract:
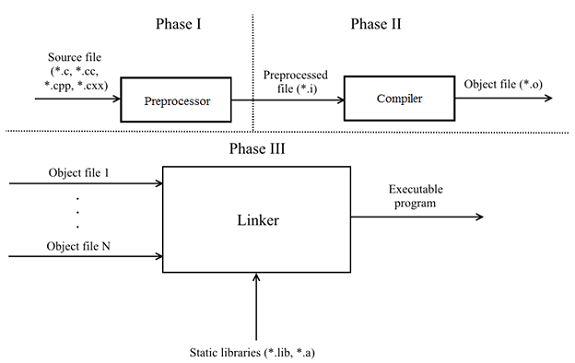
The program is compound of translation units (*.c, *.cc, *.cpp, *.cxx), each is self-sufficient and can be preproccessed/compiled independently from the other. It also follows that each translation unit has no information about the other units. If the two units have to exchange any information (such as a function), this is solved by linking by name: the external entity is declared with the keyword extern, and at the phase III the linker links them. A simple example:
TU1.cpp file:
// TU1.cpp
#include <cstdint>
int64_t abs(int64_t num)
{
return num >= 0 ? num : -num;
}TU2.cpp file:
// TU2.cpp
#include <cstdint>
extern int64_t abs(int64_t num);
int main()
{
return abs(0);
}To simplify the harmonization of different translation units, a header files mechanism was figured out, which is a declaration of clear interface. Subsequently, each translation unit in case of need includes the header file through the #include preprocessor directive.
Next, let's look at how you can speed up the build at different phases. In addition to the principle itself, it will also be helpful to describe how to implement this or that way in the build system. The examples will be given to the following build systems: MSBuild, Make, CMake.
Dependencies when compiling is something that most closely affects the speed of C/C++ projects builds. They appear every time you include the header file via the preprosseccor directive #include. This creates the impression that there is only one source to declare an entity. However, the reality is far from ideal - a compiler has to repeatedly process the same declarations in different translation units. Macros blemish the picture even more: once you add a macro declaration before the header including, its content might change at the root.
Let's look at a couple of ways how you can reduce the number of dependencies.
Option N1: remove the unused includes. No need to pay for what you don't use. This way you reduce the work of both the preprocessor and compiler. You can both manually "dig through" headers/source files, and use the utilities: include-what-you-use, ReSharper C++, CppClean, Doxygen + Graphviz (for visualization of chart inclusions), etc.
Option N2: use the dependency on declaration rather than on the definition. Here are the two main aspects:
1) In header files do not use objects in the places, where you can use references or pointers. For links and pointers, forward declaration is sufficient, because the compiler knows the size of the reference/pointer (4 or 8 bytes depending on the platform), and the size of the passed objects has no significance. A simple example:
// Foo.h
#pragma once
class Foo
{
....
};
// Bar.h
#pragma once
#include "Foo.h"
class Bar
{
void foo(Foo obj); // <= Passing by value
....
};Now, when you change the first header, a compiler has to recompile the translation units, dependent both on Foo.h, and Bar.h.
To break such a connection, it is enough to refuse from passing the obj object by value in favor of passing by a pointer or a reference in the Bar.h header:
// Bar.h
#pragma once
class Foo; // <= Forward declaration of a Foo class
class Bar
{
void foo(const Foo &obj); // <= Pass by const reference
....
};There is also another fact which everyone hardly remembers and knows: you can even declare a function that returns object by value and/or you can declare a function, the arguments of which are passed by value (!!!), just add a forward declaration before this. It is only important to remember that before such a function you have to provide the class definition, which the function is using. Such an example will compile:
// Bar.h
#pragma once
class Foo; // <= Forward declaration of a Foo class
class Bar
{
Foo foo(const Foo obj); // <= A passing of a const object
// by value
....
};As for standard headers, there is no need to worry, so just include them in the header file if necessary. The exception may be just iostream. This header file increased in size so much that it additionally comes the header iosfwd, which contains only the necessary forward declarations of needed entities. It is the file that is worth to be included in your header files.
2) Use the Pimpl idioms or the idioms of interface class. Pimpl removes implementation details, storing them in a separate class, the object of which is available through a pointer. The second approach is based on creating an abstract base class, implementation details of which are transferred in a derived class that overrides the pure virtual functions. Both options eliminate the dependencies at the compiling stage, but also add their overhead expenses during the operation of the program, namely: dynamic object creation and removing, an addition of a level of indirect addressing (pointer); and separately in case of the interface class - calling virtual functions.
Way N3 (optional): you can additionally create headers containing only forward declarations (similar to iosfwd). These "forward" headers then can be included in other regular headers.
When using a standard approach, a new file will get to the compiler for preprocessing and compiling. As each translation unit is self-sufficient, then a good way of speeding up is to parallelize I-II translation phases, processing simultaneously N files at a time.
In Visual Studio, the mode is enabled by the flag /MP[processMax] at the project level where the processMax is an optional argument, responsible for a maximum number of compilation processes.
In Make the mode is enabled by the flag -jN, where N is a number of threads.
If you are using CMake (in addition, in the cross-platform development), you can generate files with it for an extensive list of build systems via the -G flag. For example, CMake generates a solution for PVS-Studio C++ analyzer for Visual Studio, working under Windows. Unix Makefiles does the same for Linux. Add the following lines in your CMakeLists.txt, so that CMake generated projects in Visual Studio solution with the /MP flag.
if (MSVC)
target_compile_options(target_name /MP ...)
endif()You can also call the build system with parallelization flags via CMake (from the 2.8.0 version). For MSVC (/MP is specified in CMakeLists.txt) and Ninja (parallelization is already enabled):
cmake --build /path/to/build-dirFor Makefiles:
cmake --build /path/to/build-dir -- -jNUsing the previous piece of advice you can reduce the build time in several times. However, when the project is huge, this may still be not enough. By increasing the number of processes, you face a difficulty of a maximum number of simultaneously compiled files due to CPU/RAM/disk operations. Here distributed compilation comes to the aid, which uses free resources of a companion next to it. The idea is simple:
1) we preprocess the source files on one local machine or on all available machines;
2) compile preprocessed files on a local and remote machines;
3) expect the result from other machines in the form of object files;
4) link object files;
5) ????
6) PROFIT!
Let's outline the main features of a distributed compilation:
The best known representatives are:
In Linux, you can quite easily integrate distcc and Icecream in several ways:
1) Universal, through a symbolic link
mkdir -p /opt/distcc/bin # or /opt/icecc/bin
ln -s /usr/bin/distcc /opt/distcc/bin/gcc
ln -s /usr/bin/distcc /opt/distcc/bin/g++
export PATH=/opt/distcc/bin:$PATH2) for CMake, starting with version 3.4
cmake -DCMAKE_CXX_COMPILER_LAUNCHER=/usr/bin/distcc /path/to/CMakeDirAnother way to reduce the build time is the use of a compiler cache. Let's change a little bit the II phase of code translation:
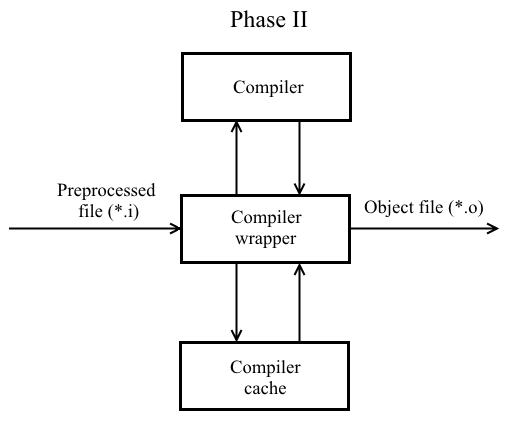
Now, when compiling the preprocessed file on the basis of its content, compiler flags, the output of the compiler, the hash value is computed (taking into account the compilation flags). Subsequently, the hash value and the corresponding object file is registered in the compiler cache. If you recompile the unchanged file with the same flags, a ready-made object file will be taken from the cache and fed to the linker input.
What can be used:
CCache registration for its subsequent use can be made by several ways:
1) Universal, through a symbolic link
mkdir -p /opt/ccache/bin
ln -s /usr/bin/ccache /opt/ccache/bin/gcc
ln -s /usr/bin/ccache /opt/ccache/bin/g++
export PATH=/opt/ccache/bin:$PATH2) for CMake, starting with version 3.4
cmake -DCMAKE_CXX_COMPILER_LAUNCHER=/usr/bin/ccache /path/to/CMakeDirYou can also integrate compiler cache in a distributed compilation. For example, to use ccache with distcc/Icecream, follow these steps:
1) Set the variable CCACHE_PREFIX:
export CCACHE_PREFIX=distcc # or icecc2) Use one of the 1-2 points of a ccache registration.
When compiling a large number of source files, the compiler, in fact, executes the same work of parsing the heavy headers (for example, iostream) many times. The basic idea is to make these heavy headers in a separate file (usually called prefix header) that is compiled once and then included in all translation units the very first.
In MSVC to create a precompiled header file, two files are generated by default: stdafx.h and stdafx.cpp (you can use other names). The first step is to compile stdafx.cpp with the flag /Yc"path-to-stdafx.h". By default, the file with extension .pch is created. To use a precompiled header file when compiling the source file, we use the flag /Yu"path-to-stdafx.h". You can use Fp"path-to-pch" together with /Yc and /Yu flags to specify the path to the .pch file. Now we will need to connect prefix title first in each translation unit: either directly through #include "path-to-stdafx.h", or forced through flag /FI"path-to-stdafx.h".
The approach in GCC/Clang differs a little: you need to pass to the compiler the prefix header instead of the usual compiled file. The compiler will automatically generate the precompiled header file with the extension . gch by default. By using the -x key, you can further specify whether it should be regarded as a c-header or a c++-header. Now enable the prefix header manually via #include or the flag -include.
You can read in more details about the precompiled headers here.
If you are using CMake, we recommend trying the module cotire: it can analyze source files in automatic mode, generate a prefix and precompiled headers, and connect them to the translation units. It is also possible to specify your own prefix header (for example, stdafx.h).
The main point of this method is to create a single compiled file (translation block), which includes other translation units:
// SCU.cpp
#include "translation_unit1.cpp"
....
#include "translation_unitN.cpp"If a single compiled file includes all translation units, then this method is also called Unity build. Here are the main features of the Single Compilation Unit:
Let's note possible problems when applying the approach:
Maximum benefit on multi-core systems will be gained from the schemes:
A replacing one of the translation components with a faster equivalent can also increase the speed of a build. However, it is worth making at your own risk.
You can use Zapcc as a quicker compiler. The authors promise a repeated acceleration of projects recompiling. You can follow this by the example of recompiling of the Boost.Math (click the animation to enlarge):

Zapcc does not make sacrifices of programs performance, it is based on Clang and is fully compatible with it. Here you can get acquainted with the Zapcc principle of work. If your project is based on CMake, then it is very easy to replace the compiler:
export CC=/path/to/zapcc
export CXX=/path/to/zapcc++
cmake /path/to/CMakeDiror as follows:
cmake -DCMAKE_C_COMPILER=/path/to/zapcc \
-DCMAKE_CXX_COMPILER=/path/to/zapcc++ \
/path/to/CMakeDirIf your operating system uses ELF format object files (Unix-like systems), you can replace the GNU ld linker with GNU gold. GNU gold comes with binutils starting from the version 2.19, and is activated by the flag -fuse-ld=gold. In CMake it can be activated, for example, by the following code:
if (UNIX AND NOT APPLE)
execute_process(COMMAND ${CMAKE_CXX_COMPILER}
-fuse-ld=gold -Wl,--version
ERROR_QUIET OUTPUT_VARIABLE ld_version)
if ("${ld_version}" MATCHES "GNU gold")
message(STATUS "Found Gold linker, use faster linker")
set(CMAKE_EXE_LINKER_FLAGS
"${CMAKE_EXE_LINKER_FLAGS} -fuse-ld=gold")
set(CMAKE_SHARED_LINKER_FLAGS
"${CMAKE_SHARED_LINKER_FLAGS} -fuse-ld=gold ")
endif()
endif()An obvious "bottle neck" in the build is the speed of disk operations (especially of random access). A porting of temporary files or project itself to quicker memory (HDD with a high speed of random access, SSD, RAID from HDD/SSD, RAMDisk) in some cases, can help greatly.
Most of the ways mentioned above historically appeared due to choosing of the principle of C/C++ languages translation. A mechanism of header files, despite its apparent simplicity, gives a lot of hassle for C/C++ developers.
A question of including the modules in the C++ standard (possibly will appear in C++20) has been already discussed for a long period of time. The module will be considered to be a related set of translation units (modular unit) with a specific set of external (exported) names, called a module interface. A module will be available for all translation units, importing it, only via its interface. Non-exportable names are placed in the implementation of the module.
Another important advantage of modules is that they do not subject to changes through macros and preprocessor directives, unlike header files. The reverse is also true: macros and preprocessor directives within the module do not affect the translation units, importing it. Semantically, modules are self-contained, fully compiled translation units.
In this article the arrangement of future modules will not be considered in detail. If you would like to learn more about them, we recommend to check out the report of Boris Kolpackov on C++ modules at the CppCon 2017:
and let me leave a small part from his presentation, which shows the difference between the new and old approach of build:
Nowadays compilers MSVC, GCC, Clang offer experimental support modules.
In this section, let's examine how effective and useful the described approaches can be.
Let's take the core of PVS-Studio analyzer as a basis for analyzing the C and C++ code. Of course, it is written in C++ and is a console application. The kernel is a small project comparing with such giants as the LLVM/Clang, GCC, Chromium, and etc. For example, here is what CLOC issues on our code base:
----------------------------------------------------------------
Language files blank comment code
----------------------------------------------------------------
C++ 380 28556 17574 150222
C/C++ Header 221 9049 9847 46360
Assembly 1 13 22 298
----------------------------------------------------------------
SUM: 602 37618 27443 196880
----------------------------------------------------------------Note that before conducting any work, our project was building for 1.5 minutes (parallel compilation and one precompiled header were used) on the following machine configuration:
Let's take a build of a project on HDD as a baseline indicator, disabling all time optimizations of the build. Further let's denote the first phase of measurements:

Figure 1. Build of PVS-Studio, 1 thread, without optimizations. Above - Debug version build, below - Release.
As you can see from the chart, due to the greater speed of a random access, a project builds a little bit quicker on a RAMDisk without optimizations in 1 thread.
The second phase of measurements is a modification of the source code: we remove unnecessary includes of headers, eliminate dependencies on a definition, improve the precompiled header (remove often modified headers from it) and add optimizations:
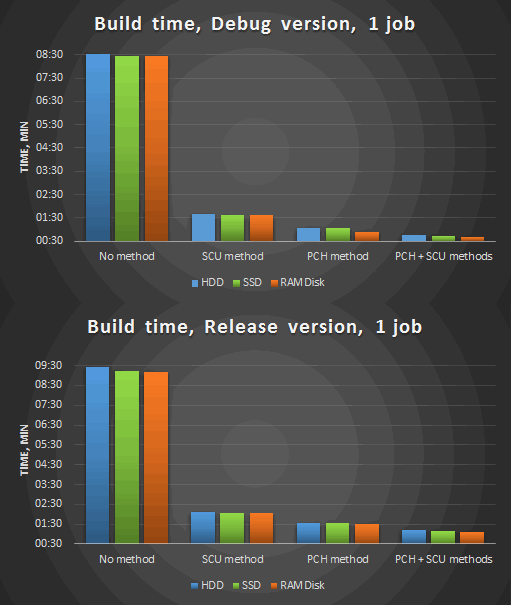
Figure 2. Compilation in 1 thread after the optimizations.
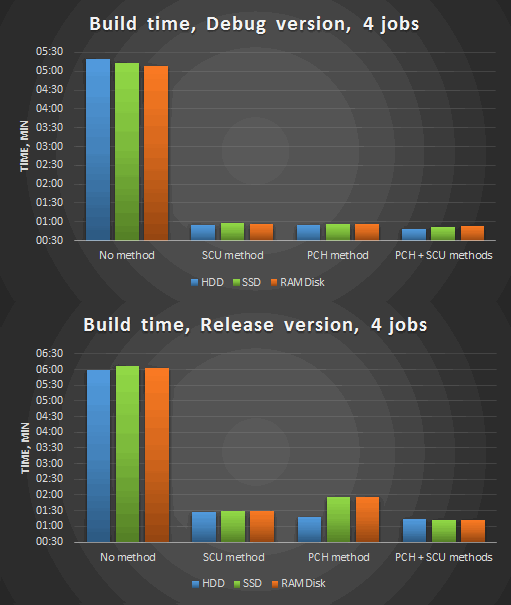
Figure 3. Compilation in 4 threads after the optimizations.
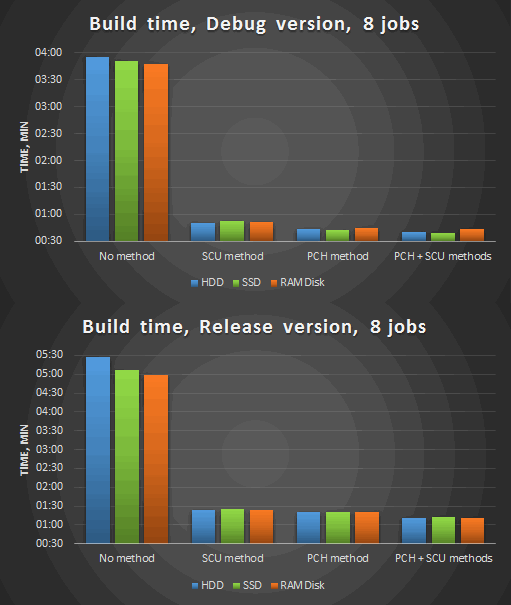
Figure 4. Compilation in 8 threads after the optimizations.
Summary conclusions:
For many developers, C/C++ languages are associated with something "long-compiling". There are some reasons for it: the way of translation chosen at one time, metaprogramming (for C++), thousands of them. Thanks to the described methods of optimization, you can deprive yourself of such prejudices about the excessively long compilation. In particular, our kernel build time of the PVS-Studio analyzer for analyzing C and C++ code has been reduced from 1 minute 30 seconds to 40 seconds through the integration of the Single Compilation Units and processing header and source files. Moreover, if a parallel compilation and precompiled headers were not used before the optimizations, we'd receive the sevenfold reduction of the build time!
In the end I would like to add that the Committee of standardization remembers about this problem and a solution of it is well under way: we are all looking forward to the new standard C++20, which will, perhaps, "deliver" modules as one of the innovations of the language, adored by many programmers and will make life of C++ developers much easier.
0
0
0
0