
Our website uses cookies to enhance your browsing experience.

When talking about PVS-Studio's diagnostic capabilities in our articles, we usually leave out its recommendations about the use of microoptimizations in C and C++ code. These are not as crucial as diagnostics detecting bugs, of course, but they make an interesting subject for discussion as well.

This paper continues the series of articles about the analysis of the Tizen operating system's source code. The size of the Tizen project (including the third-party libraries) is 72,500,000 lines of code in C and C++, which makes it a perfect example for demonstrating the various aspects of the use of static code analysis.
The previous article "27 000 errors in the Tizen operating system" showed how to estimate the total amount of bugs of a certain type that the analyzer could potentially find in a given project, and examined numerous code fragments showcasing the analyzer's capabilities in the detection of various defect patterns. Our tool, however, not only detects bugs but also suggests small fixes to make the code faster.
PVS-Studio is definitely not meant or able to replace software profiling tools. Only dynamic analyzers can detect bottlenecks; static analyzers do not know what input data are fed to programs and how often a certain code fragment is executed. That is why we are talking about "micro-optimizations", which do not guarantee a performance boost at all.
If we cannot expect a noticeable performance gain from microoptimizations, then do we need them at all? Yes, we do, and these are the reasons:
PVS-Studio currently has few diagnostics dealing with microoptimizations (see diagnostics V801-V820), but we will be adding more. We did not talk much about those diagnostics in our previous articles, so it is just the right time to do it now that we are exploring Tizen source code.
Let's see what diagnostics PVS-Studio offers for microoptimizations.
As I mentioned in the previous article, I had studied 3.3% of Tizen's code. This allows me to predict how many warnings of a certain type PVS-Studio will generate for the whole project, by multiplying the number of issues already found by 30.
Remember this multiplier, 30, as I will be using it in my calculations throughout the article.
Functions receiving "heavy" arguments by value are inefficient. This diagnostic is triggered when arguments are constant and are sure to remain unchanged in the function body.
Example from Tizen:
inline void setLogTag(const std::string tagName) {
m_tag = tagName;
}PVS-Studio: V801 Decreased performance. It is better to redefine the first function argument as a reference. Consider replacing 'const .. tagName' with 'const .. &tagName'. Logger.h 110
An extra object tagName is created, which is an expensive operation. This code performs such expensive operations as memory allocation and data copying, but they are actually not necessary. The easiest way to avoid them is to pass the argument by a constant reference:
inline void setLogTag(const std::string &tagName) {
m_tag = tagName;
}This code no longer performs memory allocation and string copying.
There is also another way. You could remove const and have the data moved rather than copied:
inline void setLogTag(std::string tagName) {
m_tag = std::move(tagName);
}This solution is as efficient as the previous one.
This example, with std::string, is, of course, harmless. Having an extra string in your code is not nice, but it can't harm performance in any way. However, there could be worse cases such as allocation of an array of strings. One such case will be discussed a bit later, in the section about diagnostic V813.
The analyzer issued 76 warnings for the projects I have already examined.
Please keep in mind that the analyzer sometimes generates false-positive warnings. For example, it may fail to distinguish a user-defined smart pointer from an element of a singly linked list. Both are pointers (to a string / the next element). Both have an integer variable (string length / list element's value). They look the same, but there is a huge difference in the cost of copying these objects. Analyzer could look into the copy constructor and try to figure it all out, of course, but it is generally hopeless. For that reason, it may be a good idea to ignore such warnings and suppress them using one of PVS-Studio's message suppression mechanisms. Perhaps, I am going to write a separate article about these later.
Remember the multiplier 30 I mentioned earlier? I can use it to estimate the total number of V801 warnings PVS-Studio will issue for the entire Tizen project, and this number is 76*30=2280.
Diagnostic V802 looks for structures and classes whose size can be reduced by sorting the fields in descending size order. Here is an example of a non-optimal structure.
struct LiseElement {
bool m_isActive;
char *m_pNext;
int m_value;
};This structure will take up 24 bytes of memory in the 64-bit version of the program (LLP64) due to data alignment. Changing the fields' order would reduce its size to just 16 bytes. The optimized version:
struct LiseElement {
char *m_pNext;
int m_value;
bool m_isActive;
};Note that the size of this structure is always 12 bytes in the 32-bit version, regardless of the fields' order. That is why the 32-bit version (ILP32LL) would not trigger a V802 warning.
Another thing you should know is that structure optimization is not always possible or necessary.
It is impossible when you need to keep data format compatibility. In even more cases, there is simply no need in optimization. If non-optimal objects are created in tens or hundreds, you will not get any noticeable performance boost. Optimization makes sense only when there are millions of elements: in that case, the less memory each structure occupies the more of such structures the CPU caches will be able to store.
All said above suggests that V802 diagnostic has a narrow scope of use, so you want to turn it off in most cases so that it does not clutter the analysis report. In that case, I do not see any point in estimating the total number of non-optimal structures that PVS-Studio could find in Tizen. I think that over 99% of those cases could do without optimization. I will only demonstrate that such analysis is possible using just one example from Tizen.
typedef struct {
unsigned char format;
long long unsigned fields;
int index;
} bt_pbap_pull_vcard_parameters_t;PVS-Studio: V802 On 32-bit platform, structure size can be reduced from 24 to 16 bytes by rearranging the fields according to their sizes in decreasing order. bluetooth-api.h 1663
If the analyzer is right, the type long long unsigned is to be aligned on an 8-byte boundary when compiling the code for the Tizen platform. To be honest, we have not figured this out yet, as this platform is new to us, but that is how things are in the systems that I know :).
So, since the fields variable is aligned on an 8-byte boundary, this is how the structure will be kept in the memory:

The class members can be rearranged like this:
typedef struct {
long long unsigned fields;
int index;
unsigned char format;
} bt_pbap_pull_vcard_parameters_t;This solution will help to save 8 bytes and the structure will be kept in the memory like this:
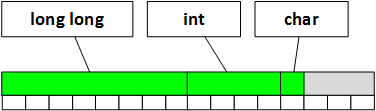
It has obviously become smaller.
Books on programming recommend using prefix, rather than postfix, increment for loop iterators. Whether this advice is still appropriate is discussed in the following articles:
In brief, it makes no difference for the Release version; but it does help a lot in the case of the Debug configuration. So, yes, this recommendation is still appropriate and you should follow it. You normally want the Debug version to be fast too.
Example of a warning:
void ServiceManagerPrivate::loadServiceLibs()
{
auto end = servicesLoaderMap.end();
for(auto slm = servicesLoaderMap.begin(); slm !=end; slm++ ){
try{
ServiceFactory* factory=((*slm).second->getFactory());
servicesMap[factory->serviceName()] = factory;
}catch (std::runtime_error& e){
BROWSER_LOGD(e.what() );
}
}
}PVS-Studio: V803 Decreased performance. In case 'slm' is iterator it's more effective to use prefix form of increment. Replace iterator++ with ++iterator. ServiceManager.cpp 67
It is better to replace slm++ with ++slm. One replacement will not make a difference, of course - it will only work if you apply this systematically. There are currently 103 issues of this type in Tizen, which means the developers will have to optimize about 3000 such operations in total if they feel like doing that. These fixes would make the Debug version a bit faster.
Sometimes you come across code that calculates the length of a given string more than once. In the Debug configuration, this definitely means a performance drop, especially if such code is executed multiple times. How the Release version would work is unknown, but the compiler is very likely to fail to understand that it must unite several calls of the strlen function into one call.
Look at the following example.
static isc_result_t
buildfilename(...., const char *directory, ....)
{
....
if (strlen(directory) > 0U &&
directory[strlen(directory) - 1] != '/')
isc_buffer_putstr(out, "/");
....
}PVS-Studio: V804 Decreased performance. The 'strlen' function is called twice in the specified expression to calculate length of the same string. dst_api.c 1832
The size of the directory name is calculated twice. By the way, this code also triggers a V805 warning, but we will discuss it in the next section.
This code can be improved by adding a temporary variable to store the string length:
const size_t directory_len = strlen(directory);
if (directory_len > 0U &&
directory[directory_len - 1] != '/')
isc_buffer_putstr(out, "/");I am not insisting on this fix. I, personally, think that this code is good enough as it is; I just needed an example to explain the diagnostic. That said, the fix making no difference in this particular case doesn't mean it's useless in any other case: there are certain string processing loops that could benefit from it.
The code I have checked so far triggered 20 warnings of this type. The total number to be issued is, therefore, 600.
Let's get back to the previous example.
if (strlen(directory) > 0U &&
directory[strlen(directory) - 1] != '/')PVS-Studio: V805 Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) > 0' construct. A more efficient way is to check: str[0] != '\0'. dst_api.c 1832
Besides saving the string length to an intermediate variable, the code can be optimized in one more way. The first call of strlen is needed to check if the string is empty or not, but calling the strlen function for that purpose is actually an unnecessary operation, as checking only the first byte of the string would suffice. The code, therefore, can be optimized like this:
if (*directory != '\0' &&
directory[strlen(directory) - 1] != '/')Or like this:
if (directory[0] &&
directory[strlen(directory) - 1] != '/')And so forth. There are many ways to implement the check. The form does not actually matter; what matters is the fact that you do not have to traverse every character of a string to find out if it's empty or not. Sure, the compiler might understand the programmer's intent and optimize the check in the Release version, but you should not count on such luck.
One more example:
V805 Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) != 0' construct. A more efficient way is to check: str[0] != '\0'. bt-util.c 376
void _bt_util_set_phone_name(void)
{
char *phone_name = NULL;
char *ptr = NULL;
phone_name = vconf_get_str(VCONFKEY_SETAPPL_DEVICE_NAME_STR);
if (!phone_name)
return;
if (strlen(phone_name) != 0) { // <=
if (!g_utf8_validate(phone_name, -1, (const char **)&ptr))
*ptr = '\0';
bt_adapter_set_name(phone_name);
}
free(phone_name);
}PVS-Studio: V805 Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) != 0' construct. A more efficient way is to check: str[0] != '\0'. bt-util.c 376
There is nothing special about this code. I just wanted to show that it is a typical and very common way to check for an empty string. I am actually surprised at C having no standard function or macro for this operation. You cannot even imagine how many inefficient checks like that are lurking in our programs. And now I'm going to tell you one horrible thing.
The part of the Tizen code, that I have already checked, contains 415 cases where the function strlen or its counterpart is used to check for an empty string.
The estimated number of warnings of this type for the whole project is, therefore, 12450.
Just think of this huge number of meaningless loops the CPU has to repeat over and over looking for a terminal null, stuffing its caches with data it may never need!
I believe it does make sense to throw away such inefficient calls of strlen. Possible alternatives are:
However, I do not like these implementations either because they are not clear enough. A much better and clearer way is to make a special macro in C or inline function in C:
if (is_empty_str(phone_name))As I already said, I find it strange that no universal standard means to check for empty C-strings has been created over all these years. If there were one, it would make huge amounts of code a little faster. 12450 inefficient checks are something worth paying attention to, aren't they?
Unlike V805 warnings, which were issued in huge amounts, there were just two V806 warnings for the code analyzed so far. Here's one of those rare birds:
static void
panel_slot_forward_key_event (
int context, const KeyEvent &key, bool remote_mode)
{
....
if (strlen(key.get_key_string().c_str()) >= 116)
return;
....
}PVS-Studio: V806 Decreased performance. The expression of strlen(MyStr.c_str()) kind can be rewritten as MyStr.length(). wayland_panel_agent_module.cpp 2511
Code like this is a typical side effect of the refactoring of old C code turned into C++. The length of a string in a variable of type std::string is computed by the strlen function. This method is obviously inefficient and cumbersome. Here's a better solution:
if (key.get_key_string().length() >= 116)
return;The code has become shorter and faster. The expected total number of warnings is 60.
Sometimes you may come across expressions with lots of operators "->" and ".", like this one:
To()->be.or->not().to()->be();In Russia, we call it "train coding" (or "conga-line coding"). I do not know if there is an English term for this programming style, but the pattern clearly explains the train metaphor.
Code like that is considered bad, and books on code quality recommend avoiding it. A much worse situation is when "trains" are repeated many times. Firstly, they clutter the program text; secondly, they may decrease performance. Here is one such example:

PVS-Studio: V807 Decreased performance. Consider creating a reference to avoid using the same expression repeatedly. ImageObject.cpp 262
This code would look better if rewritten in the following way:
for (....) {
auto &keypoint = obj.__features.__objectKeypoints[keypointNum];
os << keypoint.pt.x << ' ';
os << keypoint.pt.y << ' ';
os << keypoint.size << ' ';
os << keypoint.response << ' ';
os << keypoint.angle << ' ';
os << keypoint.octave << ' ';
os << keypoint.class_id << '\n';
}Would it be faster? No. Because stream insertion is a slow operation, speeding up the other operations will not help, even in the Debug configuration.
Yet the second version is shorter, clearer, and more maintainable.
As I already said, we would not get a performance boost here, but such optimization may be useful elsewhere - for example, when the "train" is made up of calls to slow, lengthy functions. The compiler may fail to figure out how to optimize such code, and leave you with tons of unnecessary function calls.
The analyzer issued 93 warnings of this type so far. The predicted total number is 2700.
This diagnostic is quite an interesting one; it detects unused variables and arrays. Such artifacts usually appear as a side effect of bad refactoring, when programmers forget to remove the declaration of a variable no longer in use.
Unused variables may also be the sign of a logical error, but such cases are uncommon, as far as I know.
The warning is issued when:
As a side note, the analyzer ignores superfluous variables such as those of type float or char; otherwise, there would be too many false positives. These variables are common in code that extensively uses macros or preprocessor directives #if..#else..#endif. These extra variables are harmless, since the compiler will delete them while optimizing.
Let's take a look at a couple of warnings of this type in Tizen:
void CynaraAdmin::userRemove(uid_t uid)
{
std::vector<CynaraAdminPolicy> policies;
std::string user =
std::to_string(static_cast<unsigned int>(uid));
emptyBucket(Buckets.at(Bucket::PRIVACY_MANAGER),true,
CYNARA_ADMIN_ANY, user, CYNARA_ADMIN_ANY);
}PVS-Studio: V808 'policies' object of 'vector' type was created but was not utilized. cynara.cpp 499
The policies variable is not used and must be removed.
The following code is more suspicious:
static void _focused(int id, void *data, Evas_Object *obj,
Elm_Object_Item *item)
{
struct menumgr *m = (struct menumgr *)data;
Elm_Focus_Direction focus_dir[] = {
ELM_FOCUS_LEFT, ELM_FOCUS_RIGHT, ELM_FOCUS_UP, ELM_FOCUS_DOWN
};
int i;
Evas_Object *neighbour;
if (!obj || !m)
return;
if (m->info[id] && m->info[id]->focused)
m->info[id]->focused(m->data, id);
for (i = 0; i < sizeof(focus_dir) / sizeof(focus_dir[0]); ++i)
{
neighbour = elm_object_focus_next_object_get(obj, i);
evas_object_stack_above(obj, neighbour);
}
}PVS-Studio: V808 'focus_dir' array was declared but was not utilized. menumgr.c 110
The focus_dir array is not used, which is strange and may indicate the presence of some error, but this is not necessarily so. I would have to examine this code more closely to say for sure.
There are currently 30 warnings of this type. The predicted number for the whole project is 900.
We have finally reached the diagnostic that produces the most warnings. Programmers tend to use the following code pattern:
if (P)
free(P);
if (Q)
delete Q;It's redundant. The free function and delete operator alone can handle null pointers well enough.
The code can be simplified:
free(P);
delete Q;The extra check does not make it any better and only decreases its performance.
You could probably argue that the original code is faster: if the pointer is null, you do not have to enter the free function or delete operator and do the check inside.
I do not agree with that. Most code is written based on the assumption that pointers are not null. A null pointer is generally an uncommon/dangerous situation that does not occur often. Therefore, almost every time we call free/delete, we pass a non-null pointer. The prior check only harms the performance and clutters the code.
Look at the following example:
lwres_freeaddrinfo(struct addrinfo *ai) {
struct addrinfo *ai_next;
while (ai != NULL) {
ai_next = ai->ai_next;
if (ai->ai_addr != NULL)
free(ai->ai_addr);
if (ai->ai_canonname)
free(ai->ai_canonname);
free(ai);
ai = ai_next;
}
}Here the analyzer reports two superfluous checks at once:
Let's delete the extra checks:
lwres_freeaddrinfo(struct addrinfo *ai) {
struct addrinfo *ai_next;
while (ai != NULL) {
ai_next = ai->ai_next;
free(ai->ai_addr);
free(ai->ai_canonname);
free(ai);
ai = ai_next;
}
}I find this version much simpler and neater. It is just a fine example of what refactoring is about.
620 warnings about superfluous checks of this type so far!

It means you should expect about 18600 warnings for the entire Tizen project! Wow! Just imagine that - 18600 if statements could be deleted without any risk!
#define TIZEN_USER_CONTENT_PATH tzplatform_getenv(TZ_USER_CONTENT)
int _media_content_rollback_path(const char *path, char *replace_path)
{
....
if (strncmp(path, TIZEN_USER_CONTENT_PATH,
strlen(TIZEN_USER_CONTENT_PATH)) == 0) {
....
}V810 Decreased performance. The 'tzplatform_getenv(TZ_USER_CONTENT)' function was called several times with identical arguments. The result should possibly be saved to a temporary variable, which then could be used while calling the 'strncmp' function. media_util_private.c 328
This diagnostic detects code where a function is called with the arguments represented by several calls to another function, each with the same arguments. If these calls are slow, the code could be optimized by storing the result in an intermediate variable.
In the example above, the tzplatform_getenv function is called twice with the same argument.
The already checked part of the Tizen code triggered 7 warnings, and none of them looked interesting enough, so no estimates.
This diagnostic detects inefficient string copying operations, for example:
std::string A = Foo();
std::string B(A.c_str());The string B is created by a constructor that receives a pointer to a basic null-terminated string. Before allocating the buffer, the program needs to calculate the length of the string A. To do that, it will have to traverse all of its characters. This is inefficient, since the length could be retrieved from the A string directly. The code would look better if rewritten as follows:
std::string A = Foo();
std::string B(A);This implementation is both faster and shorter.
The following example is from Tizen:
void PasswordUI::changeState(PasswordState state)
{
....
std::string text = "";
....
switch (m_state) {
case PasswordState::ConfirmPassword:
text = TabTranslations::instance().ConfirmPassword.c_str();
m_naviframe->setTitle("IDS_BR_HEADER_CONFIRM_PASSWORD_ABB2");
break;
....
}PVS-Studio: V811 Decreased performance. Excessive type casting: string -> char * -> string. Consider inspecting the expression. PasswordUI.cpp 242
The analyzer reported 41 issues of this type so far. It means the expected total number of inefficient string copying operations is 1230.
There were no V812 warnings for Tizen, so I'll just briefly explain what type of defects this diagnostic deals with.
The return result of standard library function count or count_if is compared with zero. This operation could be slow since these functions have to scan the whole container to count the number of elements required. Since the function's return value is compared with zero, we want to know if there is at least one such element. A more efficient way to check for a container element is to use function find or find_if.
Slow code:
void foo(const std::multiset<int> &ms)
{
if (ms.count(10) != 0) Foo();
}Fast code:
void foo(const std::multiset<int> &ms)
{
if (ms.find(10) != ms.end()) Foo();
}An argument, represented by a structure or class, is passed by value. The analyzer checks the function's body and concludes that the argument has not been modified. It means the argument could be passed as a constant reference, which is faster. This could speed up the execution since only the address, rather than the whole object, will be copied when calling the function.
V813 diagnostic is similar to V801, except that the variable is not marked as const. It means that the analyzer has to figure out itself if the variable changes in the function or not. If it does, there is no need to report it. False positives are possible, but this diagnostic generally works flawlessly.
Example of a function triggering this diagnostic in Tizen:
void
addDescriptions(std::vector<std::pair<int, std::string>> toAdd)
{
if (m_descCount + toAdd.size() > MAX_POLICY_DESCRIPTIONS) {
throw std::length_error("Descriptions count would exceed "
+ std::to_string(MAX_POLICY_DESCRIPTIONS));
}
auto addDesc = [] (DescrType **desc, int result,
const std::string &name)
{
(*desc) = static_cast<DescrType *>(malloc(sizeof(DescrType)));
(*desc)->result = result;
(*desc)->name = strdup(name.data());
};
for (const auto &it : toAdd) {
addDesc(m_policyDescs + m_descCount, it.first, it.second);
++m_descCount;
}
m_policyDescs[m_descCount] = nullptr;
}PVS-Studio: V813 Decreased performance. The 'toAdd' argument should probably be rendered as a constant reference. CyadCommandlineDispatcherTest.h 63
An array of type std::vector<std::pair<int, std::string>> is passed by value. Copying an array that size is quite an expensive operation, isn't it?
Besides, it is used only for reading. It would be much better to declare the function as follows:
void addDescriptions(
const std::vector<std::pair<int, std::string>> &toAdd)Most cases are not that critical, of course. For example:
void TabService::errorPrint(std::string method) const
{
int error_code = bp_tab_adaptor_get_errorcode();
BROWSER_LOGE("%s error: %d (%s)", method.c_str(), error_code,
tools::capiWebError::tabErrorToString(error_code).c_str());
}PVS-Studio: V813 Decreased performance. The 'method' argument should probably be rendered as a constant reference. TabService.cpp 67
This code creates only one extra string. No big deal, but it still makes a perfectionist programmer sad.
I got 303 warnings on the projects analyzed so far, so the estimate for the whole project is 9090. I am sure many of those will need optimization.
You must have already noticed that microoptimizations are mostly suggested for strings. It is because most of these diagnostics were created at the request of one of our customers who needed efficient string handling in his code. The next diagnostic is no exception - it also deals with strings.
It detects loops with calls of the function strlen(S) or its counterpart. The S string does not change, so its length can be computed in advance.
Here are two examples of messages produced by this diagnostic. Example 1.
#define SETTING_FONT_PRELOAD_FONT_PATH "/usr/share/fonts"
static Eina_List *_get_available_font_list()
{
....
for (j = 0; j < fs->nfont; j++) {
FcChar8 *family = NULL;
FcChar8 *file = NULL;
FcChar8 *lang = NULL;
int id = 0;
if (FcPatternGetString(fs->fonts[j], FC_FILE, 0, &file)
== FcResultMatch)
{
int preload_path_len = strlen(SETTING_FONT_PRELOAD_FONT_PATH);
....
}PVS-Studio: V814 Decreased performance. The 'strlen' function was called multiple times inside the body of a loop. setting-display.c 1185
The length of the "/usr/share/fonts" string will be computed as many times as the loop will iterate. The compiler will probably figure out how to optimize this code, but you cannot be sure. Besides, the Debug version will still be slower than it possibly could.
To improve this code, you simply need to cut the line computing the string length and paste it before the loop's start.
Example 2.
static void
BN_fromhex(BIGNUM *b, const char *str) {
static const char hexdigits[] = "0123456789abcdef";
unsigned char data[512];
unsigned int i;
BIGNUM *out;
RUNTIME_CHECK(strlen(str) < 1024U && strlen(str) % 2 == 0U);
for (i = 0; i < strlen(str); i += 2) {
const char *s;
unsigned int high, low;
s = strchr(hexdigits, tolower((unsigned char)str[i]));
RUNTIME_CHECK(s != NULL);
high = (unsigned int)(s - hexdigits);
s = strchr(hexdigits, tolower((unsigned char)str[i + 1]));
RUNTIME_CHECK(s != NULL);
low = (unsigned int)(s - hexdigits);
data[i/2] = (unsigned char)((high << 4) + low);
}
out = BN_bin2bn(data, strlen(str)/2, b);
RUNTIME_CHECK(out != NULL);
}PVS-Studio: V814 Decreased performance. Calls to the 'strlen' function have being made multiple times when a condition for the loop's continuation was calculated. openssldh_link.c 620
The analyzer does not like this line:
for (i = 0; i < strlen(str); i += 2) {The length of the string, passed as an argument, will be computed at every iteration of the loop. A perfectionist programmer's nightmare.
Note. Code like that is usually written by programmers who previously coded in Pascal (Delphi environment). In Pascal, the loop termination condition is computed just once, so it is legitimate and commonly used there. For details, see Chapter "18. The knowledge you have, working with one language isn't always applicable to another language").
By the way, do not rely on the compiler to optimize it. The pointer to the string comes from outside. Sure, the string cannot be modified inside the function (because it's of type const char *), but it doesn't mean it can't be modified from outside. Function strchr, for example, could do that, so you'd better play safe...
Some of you may find it strange that a constant reference can be modified. Look at the code below.
int value = 1;
void Foo() { value = 2; }
void Example(const int &A)
{
printf("%i\n", A);
Foo();
printf("%i\n", A);
}
int main()
{
Example(value);
return 0;
}Although the argument A is of type const int &, the program will first print the value 1, and then 2.
That's it. You see, const is part of an access interface that prohibits variable modification, but it doesn't mean the variable can't be modified at all.
Optimized code:
static void
BN_fromhex(BIGNUM *b, const char *str) {
static const char hexdigits[] = "0123456789abcdef";
unsigned char data[512];
unsigned int i;
BIGNUM *out;
const size_t strLen = strlen(str);
RUNTIME_CHECK(strLen < 1024U && strLen % 2 == 0U);
for (i = 0; i < strLen; i += 2) {
const char *s;
unsigned int high, low;
s = strchr(hexdigits, tolower((unsigned char)str[i]));
RUNTIME_CHECK(s != NULL);
high = (unsigned int)(s - hexdigits);
s = strchr(hexdigits, tolower((unsigned char)str[i + 1]));
RUNTIME_CHECK(s != NULL);
low = (unsigned int)(s - hexdigits);
data[i/2] = (unsigned char)((high << 4) + low);
}
out = BN_bin2bn(data, strLen / 2, b);
RUNTIME_CHECK(out != NULL);
}The already analyzed projects contain 112 calls of the strlen function in loops that could be executed just once. The expected total number of warnings is 3360.
Are you dying to get a PVS-Studio copy for yourself and go make this world a better place? We are all for it! Get the demo version here.
String classes implement efficient means for string clearing or empty-string checks. I mean it is better to rewrite the following code:
void f(const std::string &A, std::string &B)
{
if (A != "")
B = "";
}in the following way:
void f(const std::string &A, std::string &B)
{
if (!A. empty())
B.clear();
}Will the compiler manage to optimize the Release version and build the same binary code for both the first and the second versions of the function?
I played with the compiler I had at hand, Visual C++ (Visual Studio 2015), and it managed to build the same code for both versions of the empty-string check but failed to optimize the first version of the string clearing, so the call of the std::basic_string::assign function was still there in the binary code.
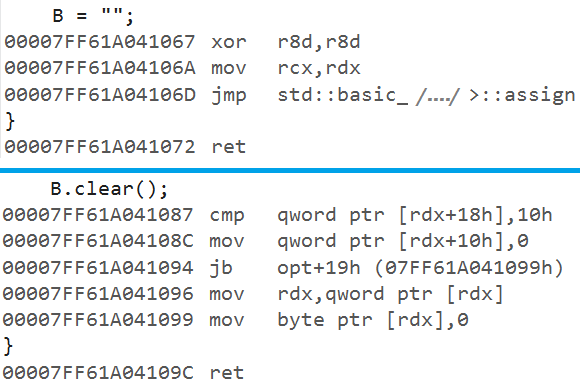
This is an example of the warning from Tizen:
services::SharedBookmarkFolder
FoldersStorage::getFolder(unsigned int id)
{
BROWSER_LOGD("[%s:%d] ", __PRETTY_FUNCTION__, __LINE__);
std::string name = getFolderName(id);
....
if (name != "")
folder = std::make_shared<services::BookmarkFolder>(
id, name, count);
return folder;
}PVS-Studio: V815 Decreased performance. Consider replacing the expression 'name != ""' with '!name.empty()'. FoldersStorage.cpp 134
That was a slow check for an empty string, but I also have an example of slow string clearing:
....
std::string buffer;
....
bool GpsNmeaSource::tryParse(string data)
{
....
buffer = "";
....
}PVS-Studio: V815 Decreased performance. Consider replacing the expression 'buffer = ""' with 'buffer.clear()'. gpsnmea.cpp 709
Sure, this diagnostic is quite arguable. Some programmers prefer using the expression (str == "") to check for an empty string, and assignment to clear strings. They believe such code is clearer. I can't argue against that, especially after my experiment proved that the check (str == "") would be optimized by the compiler in the Release configuration.
It is up to you to decide if you should use these microoptimizations or not. If you decide against them, simply turn off this diagnostic. However, it may be useful sometimes, as it was requested by our customer, which means people need it.
PVS-Studio issued 63 warnings of this type so far. If Tizen developers find these warnings worthy, they should expect 1890 of them in total.
It is better to catch exceptions by reference than by value. Besides making the code faster, this also saves you from some other errors such as slicing. We will not discuss it here because slicing-related issues are handled by diagnostic V746.
Here's an example:
std::string make_message(const char *fmt, ...)
{
....
try {
p = new char[size];
} catch (std::bad_alloc) {
Logger::getInstance().log("Error while allocating memory!!");
return std::string();
}
....
}PVS-Studio: V816 It is more efficient to catch exception by reference rather than by value. LoggerTools.cpp 37
It is better to rewrite that line as follows:
} catch (std::bad_alloc &) {I got 84 warnings on the checked code. The estimate is: about 2500 warnings in total.
This diagnostic deals with inefficient search of single characters in strings. The easiest way to explain this is to examine two examples. The first:
void URIEntry::_uri_entry_editing_changed_user(void* data,
Evas_Object*, void*)
{
....
if ((entry.find("http://") == 0)
|| (entry.find("https://") == 0)
|| (entry.find(".") != std::string::npos)) { // <=
self->setDocIcon();
} else {
....
}PVS-Studio: V817 It is more efficient to seek '.' character rather than a string. URIEntry.cpp 211
It is better to search for a period as a character rather than a substring:
|| (entry.find('.') != std::string::npos)) {The second case is similar:
char *_gl_info__detail_title_get(
void *data, Evas_Object *obj, const char *part)
{
....
p = strstr(szSerialNum, ",");
....
}PVS-Studio: V817 It is more efficient to seek ',' character rather than a string. setting-info.c 511
It is better to search for a comma using the strchr function:
p = strchr(szSerialNum, ',');The projects I have already checked contain 37 issues of this type. The expected total number is 1110.
As I'm writing this article, new diagnostics have been added to PVS-Studio 6.16: V818, V819, V820. They weren't yet ready when I was checking Tizen, so I have no examples from there to show you. Follow these links to find out what they do:
I hope you have learned a lot from this article about the set of PVS-Studio diagnostics that we almost never mention. Perhaps they will help some of you to improve your code. Although they currently deal with cases of inefficient string handling (std::string, CString, etc.) for the most part, we are going to include diagnostics for other non-optimal code patterns in the future.
Let's count just how many warnings we should expect that, in my opinion, could help to make Tizen and libraries better.
TOTAL: about 59000 warnings
I'm not saying you must go and fix each and every of these warnings. I know this wouldn't make Tizen any noticeably faster. Moreover, applying so many fixes poses a risk of breaking something with just a small typo.
Still, I believe these warnings make sense. Handling them wisely could help you create simpler and more efficient code.
If you ask me, the old code should be left as it is, but the new code should make use of these microoptimizations. This article clearly shows that much of the code could be improved if only a little.
Welcome to install PVS-Studio and try it with your projects. If you use Windows, the demo version is available right away. If you want to launch it on Linux, please email us to get a temporary license key.
Thank you for reading!
0
0
0
0