
Our website uses cookies to enhance your browsing experience.

Container is an object which stores a collection of related objects (or elements). The container manages the storage space that is allocated for its elements.

The C++ standard library includes a variety of containers. Moreover, there is a number of Open Source containers that cover much more use cases. I'm going to describe the arrangement of the most curious non-STL containers and their differences from the standard containers.
Containers can be roughly divided into two categories – sequence and associative, since these two kinds of containers are too different. In this article we will only discuss sequence containers. And who knows, maybe one day I'll write an article about associative containers as well...
We published and translated this article with the copyright holder's permission. The author is Evgeny Shulgin (mizaronplatz@gmail.com). The article was originally published on Habr.
An element requires a storage space where the values of its data members are located. In standard applications, memory is taken from the stack or the heap. It would be good to revise some basic concepts to understand this article better.
Stack allocation is an increment of the stack pointer to a hard-coded value. Heap allocation may be a system call, some custom allocators with complex logic (like tcmalloc, jemalloc) may also be used, or memory pools – a lot is going on "under the hood".
You can see from the infographics below that these two types of allocation differ greatly in performance:
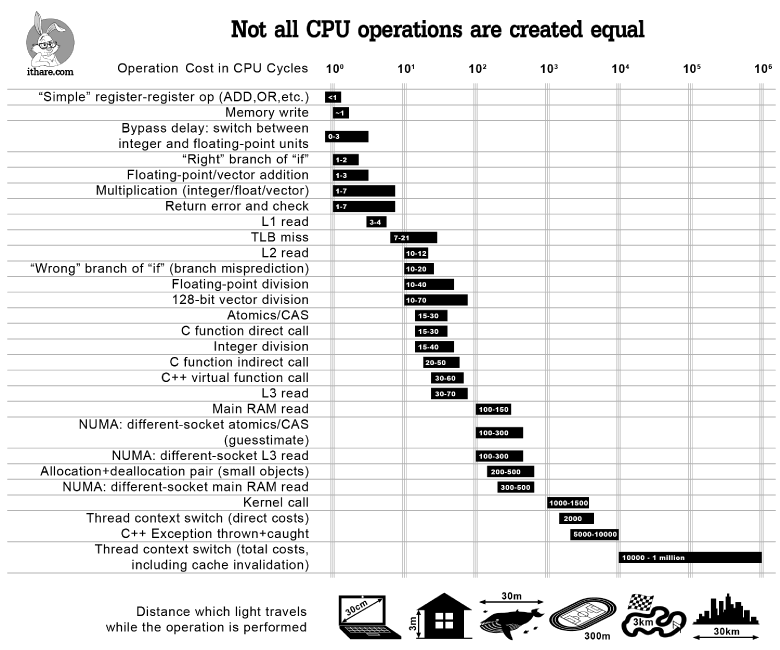
Stack allocation takes a few CPU operations, heap allocation may take thousands, depending on the allocator. That is why you can significantly increase heap allocation performance. You can read more about other allocators on Habr [RU].
The C++ standard only covers the container interface and imposes some requirements for performance, gives some guarantees, and so on.
STL has several implementations. The same containers in different implementations do not usually differ that much from each other. Currently, there are three the most popular STL implementations by Clang, GCC, and Microsoft.
It's hard enough to read their implementations, since the same code should compile to all standards. That's why implementations are usually a hodgepodge of #ifdef's and some freaky code.
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_AFTER_CXX17
allocator() _NOEXCEPT = default;The code for non-standard containers is normally more readable. Many libraries compile to a specific standard and/or can change the interface (which is not possible in STL).
The std::array<T, N> is the basic container. Its semantics is no different from the usual T[N] array. The elements are located on the stack. You can neither insert nor erase elements — their number is exactly N.
The distinctive feature of the std::array (or more precisely, of the T[N] array) is that all its elements are initialized immediately and ready for use.
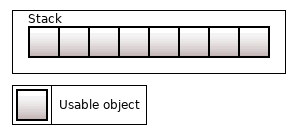
Figure 1. The std::array<T, 8>
All containers perform two stages: "get memory for an element" and "initialize the element in that memory". The second stage may occur much later than the first. But in std::array all N elements are initialized immediately.
According to the C++ rules, elements in the array are initialized "from left to right" and destructed "from right to left".
A brief note: the constructor/destructor of an element may perform no action at all (may not change the memory, may not call any other methods, and so on). This type of constructor/destructor is called trivial. If T has a trivial constructor and destructor, then nothing but memory allocation for std::array<T, N> happens.
The std::vector<T> allocates memory for elements in the heap. Three pointers to elements are on the stack: the pointer to the first element (begin), one past the last element (end), and one past the last unused memory area (end_cap).
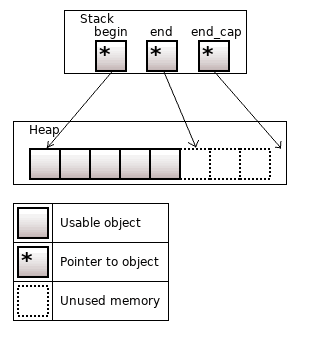
Figure 2. The std::vector<T>, size = 5, capacity = 8
An element is created in pre-allocated memory via the placement new operator. Since C++11 with the introduction of perfect forwarding, a new element for a vector can be constructed in-place (using the emplace/emplace_back member function) without any redundant copy/move constructor calls.
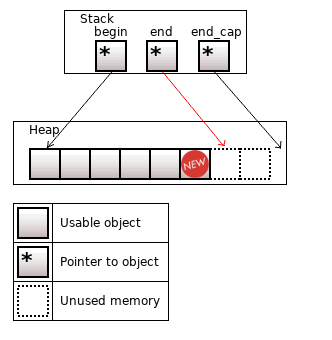
Figure 3. After inserting an element; size = 6, capacity = 8; end is changed
The vector contains the .size() member function, which stands for the number of existing elements; and the .capacity() member function, which denotes the number of elements that can be held in currently allocated storage.
An empty vector does not allocate anything (begin = end = end_cap = nullptr), so it has size and capacity equal to 0.
When inserting a new element, if it does not "fit" into the memory, the memory is reallocated for max(1, 2 * capacity) elements. Old elements are moved into the new memory. The size of the vector grows in the sequence of 0, 1, 2, 4, 8, 16, ..., 2N.
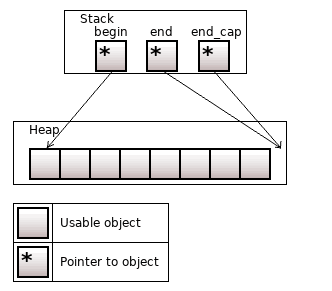
Figure 4. size = capacity = 8, before inserting an element the reallocation is needed
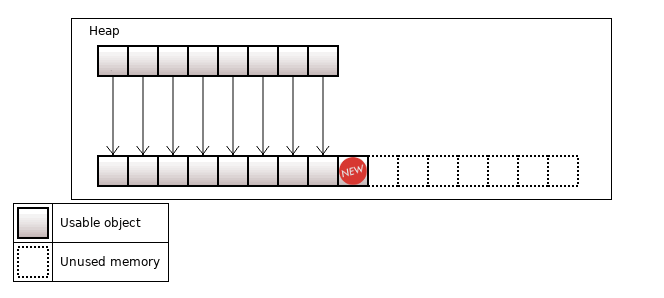
Figure 5. capacity grows from 8 to 16
We need to move elements from the old memory into the new memory, and then free the old memory. We can move elements in different ways, I'll describe the most convenient ones later in this article. Now we'll look at the custom std::vector implementation.
Folly is an open-source C++ library with a variety of useful things. Folly has its own vector implementation – folly::fbvector, and the documentation for it.
The key difference from std::vector is that the capacity grows not by 2 times, but by 1.5 times. The documentation explains in detail why this growth factor is more cache-friendly.
Moreover, this container cooperates with the jemalloc allocator (if it's enabled) and allocates memory for it.
Another optimization is related to moving objects from the old memory to the new memory during vector reallocation. For the CPU, any object is just a set of bytes. If these bytes are moved, the object will still be usable in most cases. Objects of this kind can be referred as relocatable.
Here's an example of non-relocatable object, since one data member points to another:
class Ew
{
char buffer[1024];
char * pointerInsideBuffer;
public:
Ew() : pointerInsideBuffer(buffer) {}
....
};Folly treats objects of custom classes as non-relocatable by default. To specify that the custom Widget class is relocatable, you need to write this:
// at global namespace level
namespace folly
{
struct IsRelocatable<Widget> : boost::true_type {};
}I promised to tell you how to choose the relocation strategy, these are the options for folly::fbvector:
Some more information on the first point: memcpy is the fastest way to copy bytes to another memory area, and the implementation of this feature contains environment optimizations.
As for the second point: why are the move constructors required to be noexcept? It's necessary to provide "strong exception guarantee". Let's look at the code fragment:
// using std::vector or folly::fbvector
void TryAddWidget(std::vector<Widget>& widgets)
{
// execute some code...
Widget w;
try
{
widgets.push_back(std::move(w));
}
catch (...)
{
// caught an exception...
// expect the widgets to remain usable
}
}"Strong exception guarantee" is required for keeping the vector in its consistent state. In this case, the state of the vector is rolled back to the state just before the object inserting.
If move constructor throws an exception, we have a risk to break up the original vector. For example, we reallocate memory and exception occurred during the move:
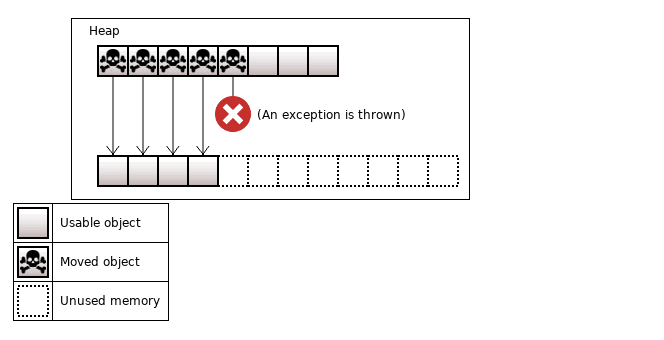
Figure 6. An exception is thrown when we move the fifth object
In general, objects should not be used after the move. Since some of the objects have been moved to the new memory, you must move them back to the old memory. And if you catch another exception again, the program execution is fully broken.
Noexcept move constructors have no problems of this kind. C++ has rules on which classes can have implicitly-defined default constructors, if possible, they should be noexcept.
Many C++ style guides do not allow exceptions at all (for instance, Google C++ Style Guide), so this class of problems does not exist there.
Some more information on the third point: if the class has no copy constructor (which is relevant for the std::unique_ptr class), then the move constructor is called whether there is noexcept specifier or not. The call may break up the consistency of the vector (no exception guarantee), but this is unlikely, since there are quite few such classes.
As for the last point: if all the previous points are not met, then we copy an object as usual.
To implement such logic, special utilities from the standard library are used, for example, std::move_if_noexcept.
The std::vector has the same logic for moving objects as folly::fbvector, except for the first point. The std::vector implementation treats the objects of Widget class as relocatable, if std::is_trivially_move_constructible<Widget>::value == true, and this cannot be changed.
The std::deque (double-ended queue) is a container that allows fast insertion of objects at both its beginning and its end. While the std::vector uses a single piece of memory, the std::deque splits memory into equal chunks.
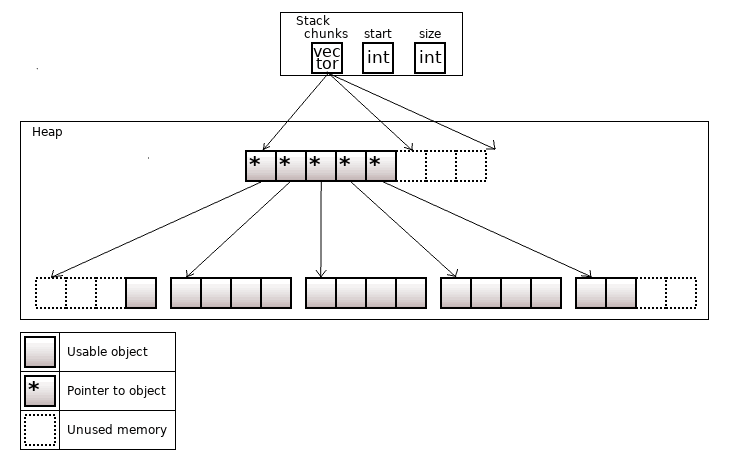
Figure 7. The std::deque<T>, start = 3, size = 15 in the image
Pointers to the chunks are in a container similar to the vector (with small differences in details).
The object reference is obtained through 2 dereferences (instead of 1 for the std::vector).
If you fail to insert an object in the beginning/end, a new memory chunk is allocated first. At worst, the pointer container reallocation to the chunks may be needed, so in this case there are two allocations.
The advantage of the container is that when we're inserting new objects in the beginning/end, no references/pointers are invalidated.
The disadvantage is the memory overhead, which is more noticeable if there are few objects in the container. The std::deque<T> with a single object allocates a rather large chunk (4096 bytes in the STL implementation by Clang).
In fact, I've not written anything about iterator and pointer invalidation in detail yet.
Even though the subject is already familiar to experienced C++ developers, we should talk about it precisely in the context of non-standard containers.
An iterator of the container<T> is a sort of a ''light'' object, that should be similar to the T* pointer. Every container has its own iterator. The iter++ call advances the pointer to the next element inside the container, while the *iter call gets the reference on the element pointed to. That's the main purpose of iterators, which are needed a lot, for example, for range-for.
The most primitive iterator of the std::array<T> is the T* pointer itself.
The std::deque<T> has a more complex iterator, consisting of two pointers: the pointer to the current chunk and the pointer to the current object of the chunk. The iter++ call safely updates these pointers and the *iter call returns the current object of the chunk. Thus, iterators provide ''seamless'' traversal through the container elements.
Iterators and pointers may become invalidated, which means they may no longer point to the object. Usually people create all sorts of large tables where they analyze corner cases and many other things to describe the conditions for the invalidation.
It's always better not to cram these tables, but to read the source code of the iterator's and the container's classes. The insight into the question will come by itself. For example, if you don't understand the inner workings of the std::vector and the std::deque containers, then it's more challenging to understand why, after the push_back call, an object reference in the first container may "expire", while in the second container it remains valid.
While describing the inner structure of non-standard containers I don't go into details on the conditions for the invalidation, since a lot is explained by the inner workings of the container.
The std::forward_list is a singly linked list, the easiest implementation of the linked list. The list consists of a collection of nodes. The node of the list is the object itself and the reference to the next node in the sequence (the pointer is nullptr, if the object is the last in the sequence). Memory is allocated independently for every node, sizeof(T) + sizeof(void*) bytes.
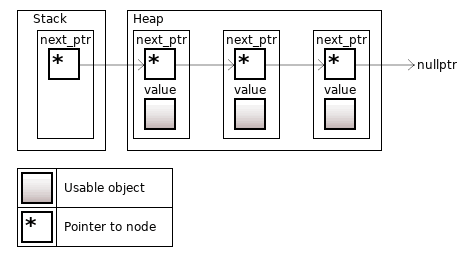
Figure 8. The std::forward_list<T> consists of three objects, the root node on the stack
The container supports fast insertion and removal of elements from anywhere, since we only need to change the next_ptr for the left node. However, the "fast insertion" refers specifically to the "algorithmic complexity". Memory allocation for the new node may be not so fast.
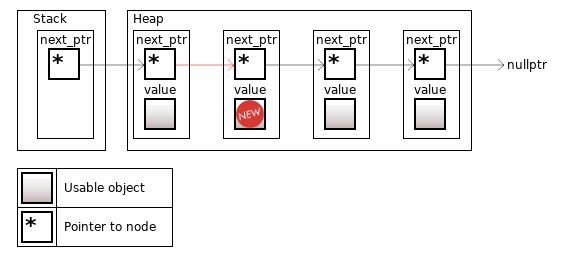
Figure 9. Inserting a new object into middle positions
You can't get the N-th object quickly. Firstly, you need to traverse from the root node to the next_ptr N times. Also, the list size can only be obtained by traversing all next_ptr's until we see nullptr. The container doesn't even have the .size() member function.
Among non-STL containers there are some other implementations of a singly linked lists, in which the .size() member function is implemented for O(1), for the overhead as a storing size variable on the stack.
Iterators and pointers to an object in this container are never invalidated unless the object is deleted. Thus, the std::forward_list provides the strongest guaranties among all containers.
The std::list is a more complex implementation of the linked list. It has all the same properties as the std::forward_list, but the nodes can also reference to the previous nodes, moreover, the container supports fast insertion of elements into the end of the list.
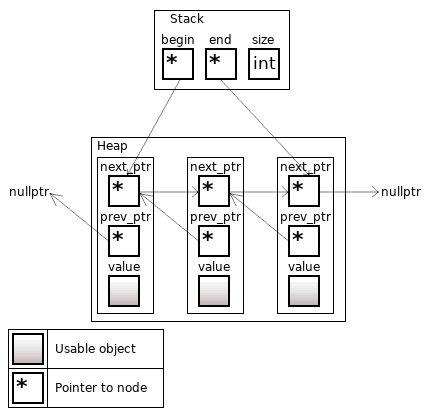
Figure 10. The std::list<T>, size = 3
Fun fact: since C++11, the .size() member function must have a constant complexity. A variable where the list size is written is supported for this purpose. Until C++11, the .size() member function implementation could have a linear complexity, traversing all nodes.
Some containers do not have a tricky internal arrangement, their distinctive functionality is based on the other container's functionality. There are three STL containers of this kind: std::stack, std::queue, std::priority_queue, and you can choose a "real'' container for each of them.
Template <class T,
class Container = std::deque<T>>
class stack;
template <class T,
class Container = std::deque<T>>
class queue;
template <class T,
class Container = std::vector<T>,
class Compare = std::less<typename Container::value_type>>
class priority_queue;In most cases an interface of an adapter container simply redirects the member function call, such as in the std::stack:
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
reference top() { return c.back(); }
void push(const value_type &__v) { c.push_back(__v); }
void pop() { c.pop_back(); }Bit containers are needed to manage a sequence of N bits. Which means that these containers store only bits.
An object cannot "weigh" less than 1 byte, but one byte holds as much as CHAR_BIT bits (usually CHAR_BIT = 8). That is why a special container for bits is 8 times more efficient in terms of memory management.
Physically, such containers contain several numbers, usually, of the size_t type (their size is 64 bits on a 64-bit machine).
Just as with "standard" containers, data can either be on the stack or on the heap.
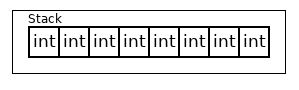
Figure 11. The std::bitset<512> on a 64-bit machine (8 size_t numbers are enough)
For the std::bitset<N>, which is on the stack, you need to know the number of bits "in advance". Initially, all bits are filled with zeros. The container has several approaches to manage bits (all bits or a specific bit).
Group operations like the .count() are much faster compared to the ones in the common for loop. Processor produces bit operations on a number in a single instruction, which is at least 64 times faster than if they were done in a loop.
Bit operations done via the operator[] are supported in a special way:
std::bitset<512> b;
b[128] = 1; // or b[128] = trueThe operator[](size_t pos) is overloaded so that its call returns the "light" std::bitset::reference object, which contains a pointer to the number and the bitmask. At the same time, the object has the operator=(bool x) overloaded. The operator writes to the required bit.
As you may have already noticed, C++ uses many such tricks with the proxy objects (iterators, bit references) to make it convenient for users to work with objects.
The std::vector<bool> is a similar class that allocates data on the heap (where the number of bits can be set in run-time). Many developers don't like this class, some consider it to be a bad design in C++ [RU]. For example, those who try to use it as a conforming container instead of the "std::bitset on a heap", find it impossible to use direct pointers to an object (you cannot point to an individual bit). But, if you have problems of this kind, you can always use std::vector<char>, std::vector<int>, std::deque<bool>.
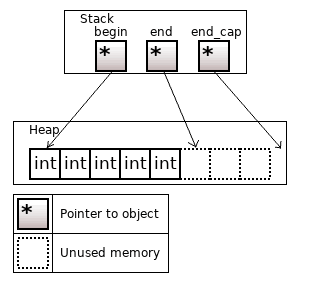
Figure 12. The std::vector<bool> or the boost::dynamic_bitset
The std::vector<bool> is extremely poor in the bit operations available. The container lacks basic group bit operations, which, as I mentioned above, the processor produces much more effectively.
There is a more advanced analog of std::vector<bool> in Boost – boost::dynamic_bitset. It has a fast implementation of every bitset operation imaginable. This container has a wide range of uses.
"Non-standard" containers are great since they can be easily patched. A few years ago, I patched boost::dynamic_bitset to make bit counting faster and add new member functions to control the bit sequence.
The previously discussed std::array<T, N> has a property of initializing all N objects at once. If you don't need this property and want to manage memory for N objects, you can use the boost::static_vector.
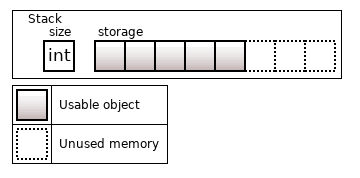
Figure 13. The boost::static_vector<T, 8>
This container behaves just as the usual std::vector, but its memory is allocated on the stack for N objects.
How do you allocate raw memory on the stack without an existing object? Until C++23, you could do it through std::aligned_storage with a high risk to make a mistake and to shoot yourself in the foot. Since C++23, you can do it more easily:
alignas(T) std::byte buff[sizeof(T)];and then create objects in buff using the placement new.
An exception is thrown when you try to insert N+1 object into the boost::static_vector. You can write code and run it through godbolt, which supports Boost. To enhance the performance greatly you can set the template not to throw an exception, so the program just crashes.
The boost::small_vector is some kind of a hybrid of the boost::static_vector and the std::vector. It statically allocates memory for N objects, but in case of overflow it allocates memory on the heap.
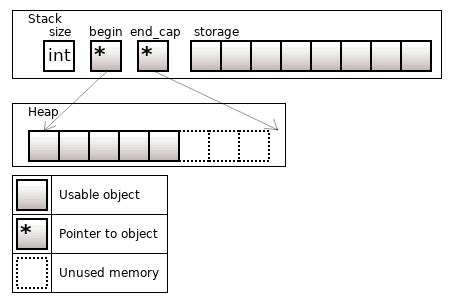
Figure 14. The boost::small_vec<T, 8> with 13 objects
In the image N objects are on the stack and size - N objects are on the heap. In some implementations all size objects are allocated on the heap to ensure that the objects are in a contiguous storage area (when size > N).
You can effectively use this container if a number of elements that can be held is not likely to be greater than a predicted one.
The authors of this container say that they took inspiration from SmallVector in LLVM. That's no surprise – the containers described in this article were reinvented numerous times.
Boost has its own reinvented wheel implementation of STL containers with various features. For example, you can set growth factor of a vector or set the block size for a deque.
The boost::devector is a hybrid of the std::vector and the std::deque. This container allows fast insertion at both its beginning and its end, just like the deque. But this container still keeps the vector features, such as the contiguous storage area and the conditions for the invalidation of iterators/pointers.
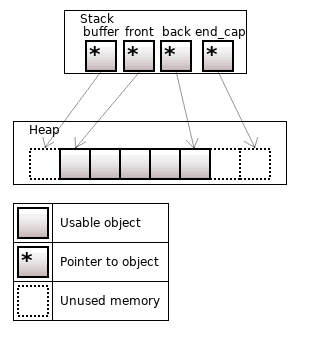
Figure 15. The boost::devector<T>, size = 5, front_capacity = 1, back_capacity = 2
When the vector is reallocated, we select in which direction the vector should be expanded (right or left), depending on which limit was exceeded.
If sizeof(std::vector) == 3 * sizeof(T*), then the devector requires an additional pointer. Therefore sizeof(boost::devector) == 4 * sizeof(T*).
The boost::stable_vector is a hybrid of the std::vector and the std::list.
The std::vector has a disadvantage – references and iterators are easily invalidated. This happens when a vector is reallocated, or when an object is erased/inserted closer to the beginning.
Containers can be divided into "stable" and "unstable" types. "Stable" containers keep references and iterators to the object valid until the object is erased from the container. The std::list is a perfect example of a "stable" container. While the std::vector is "unstable" container.
If you cancel the linear arrangement requirement for the std::vector, you can implement a "stable" analogue of a vector:
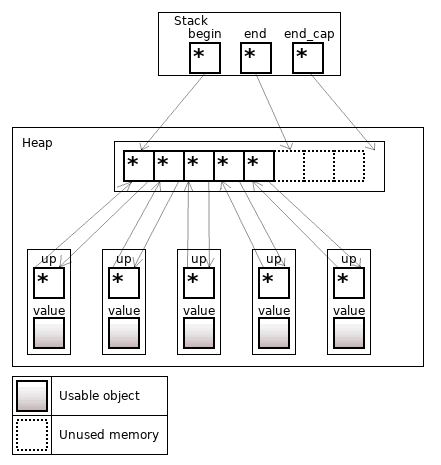
Figure 16. The boost::stable_vector<T>, contains 5 objects
Where the std::vector has objects, the boost::stable_vector has an array of references to node instead.
A node contains value – the object, and up – the back reference to the certain position in the array with the value pointing to the node.
Just as for the std::list, the node for each object is allocated separately.
The iterator to an object is a reference to a node.
References and iterators to an object are valid until the object is erased in the container. Inserting/erasing an object that is "closer" to the beginning of the vector will rewrite the pointer up, but neither the reference (to value) nor the iterator (node*) will change. Reallocation of the array of references to nodes does not invalidate references/iterators to an object (the container fixes the up value during the reallocation).
Now look at how the iterator works on the oversimplified pseudocode. For example, there is a vector with pointers to the nodes (as in the picture):
template <typename T>
struct node;
template <typename T>
std::vector<node<T>*> node_ptrs;The node contains two values: the reference to the certain position in the node reference array; and the object itself.
template <typename T>
struct node
{
node<T>** up;
T value;
};The iterator works with a reference to the node:
template <typename T>
class stable_vector_iterator
{
public:
using self = stable_vector_iterator;
self& operator++()
{
p = *(p->up + 1);
return *this;
}
T& operator*()
{
return p->value;
}
private:
node<T> *p;
};To get the reference to the ''next'' node, you have to follow up to the array location where the current reference is, move to the next location, and dereference the resulting value.
Algorithmic complexity of the boost::stable_vector member functions is exactly the same as the corresponding std::vector member functions. In particular, unlike the std::list, an object can be obtained by any index for O(1).
There is an article on Wikipedia about the circular buffer. In C++, it can be implemented as a fixed-size container (on the stack or on the heap). An object is created at the beginning of the array when the array is out of bounds.
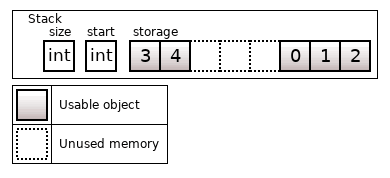
Figure 17. Circular buffer with the memory on the stack for 8 objects; start = 5, size = 5
Circular buffer can also be implemented as a usual vector. The container's advantage is the fast insertion/removal at its beginning. The disadvantage is a strict memory limit of N objects. And that's all. There is nothing else special about this container.
Circular buffer is implemented in Boost as well: boost::circular_buffer.
Container colony is a hybrid of the std::deque and the std::list. This container was proposed to the C++ standard library, but hasn't yet been adopted. Here is a document with the detailed description of this container.
In many projects, objects more often do not "own" other objects, but only refer to them. For example, in video games entity objects may refer to (rather than contain) shared resources like sprites, sounds and so on.
Those shared resources are usually located in containers. The container should stay stable regardless of its resource changes (insertion/erasure). Unfortunately, the std::vector is not stable, while the std::list is not okay with cache and decreases performance, especially during iteration.
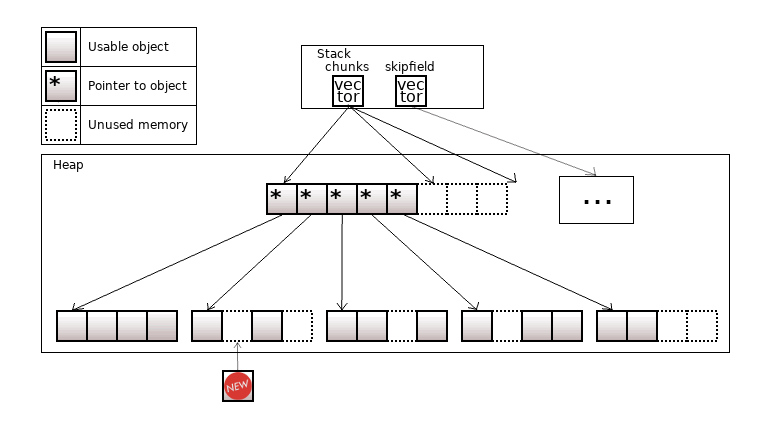
Colony is quite fast and "stable" container. The objects it contains are allocated into chunks, as in the std::deque. In the std::deque objects are allocated closely to each other, while the colony may have 'skips' (erased elements) in the chunks. The overall view of the colony changed several times over the past years, but schematically it looks like this:
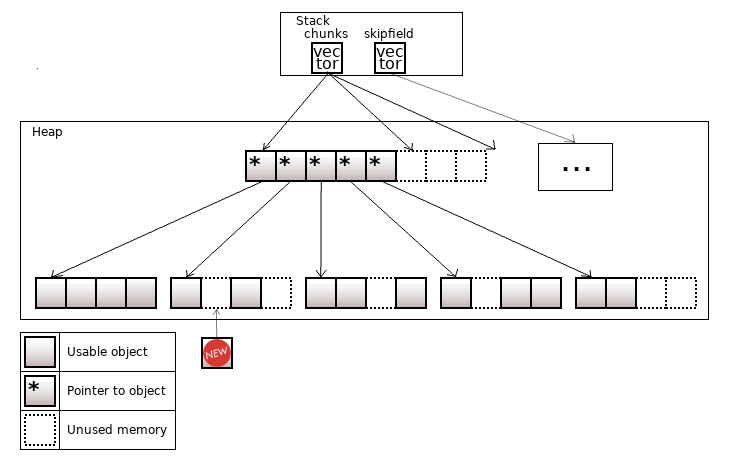
Figure 18. The colony<T>
When an object is erased from the colony, the objects to its right will not move to its place. Thus, pointers to an object stay valid.
Colony has the skipfield structure, which encodes information about 'skips'. 'Skips' are reused – when a new object is inserted, it is written in the leftmost 'skip'. The skipfield is also required in order to skip over erased elements during iteration.
In addition to stability, the container has these guarantees for basic operations:
This container is the best option if you need a structure that allows fast insertion/erasure of objects and to keep the references valid. At the same time, this container is faster than the std::list. However, it is not possible to quickly obtain an object by an arbitrary index, the container is not built for that.
See the container's implementation on github.
Now that we've discussed both standard and non-standard containers, we can examine a practical case.
For example, you're developing the display of fast food ads on a website. You need to display the top 5 most relevant meals. They depend on the user's region, the meals that are available in the nearest fast food joint, promotions, current local time, etc.
Requests come to the service API. Suppose that all data that determines the top meals is represented by C++ classes/structures.
Let's imagine an API class that defines one of the nearest fast food joints to the user. It contains the distance to a user (the longer, the less important), occupancy, the meals available, promos, and the history of user's visits.
struct Restaurant
{
double Distance; // distance
double Occupancy; // occupancy
std::vector<Meal*> Meals; // meals available
std::vector<Promo*> Promos; // promos
std::vector<Visit> VisitHistory; // the history of visits
};Some data is "owned" by the object (like visit history), and some data is just referenced because it is common to all users.
Here we have a problem – suppose we have the std::vector<Meal> Meals objects somewhere in the program. If we create Restaurant-es and then add some new dish, we can get a vector reallocation, and then all Meal* references will become dangling.
You can turn objects into a smart pointer (std::vector<std::shared_ptr<Meal>> Meals), but that's clumsy and even not for free.
But you can solve multiple issues at once – all API classes must be made non-copyable. And non-movable. What are the advantages:
The C++ compiler will not allow the container to be used as the std::vector, which can potentially invalidate references. But it will compile a safe container such as the std::list. If the containers are non-standard, then, for example, the stable_vector or the colony will be compiled.
0
0
0
0