
Our website uses cookies to enhance your browsing experience.

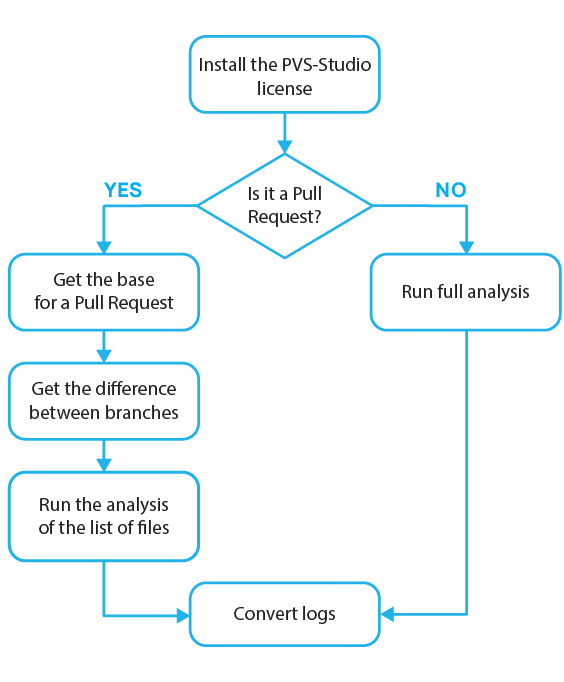
Starting from the version 7.04, the PVS-Studio analyzer for C and C++ languages on Linux and macOS provides the test feature of checking the list of specified files. Using the new mode, you can configure the analyzer to check commits and pull requests. This article covers setting up the check of certain modified files from a GitHub project in such popular CI (Continuous Integration) systems, as Travis CI, Buddy and AppVeyor.
To get current information about it follow the updated documentation page "Analyzing commits and Pull Requests".

PVS-Studio is a tool designed to detect errors and potential vulnerabilities in the source code of programs, written in C, C++, C# and Java. Works in 64-bit systems on Windows, Linux and macOS.
In the PVS-Studio 7.04 version for Linux and macOS there is now the mode of checking the list of files. It works for projects, whose build system allows generating the compile_commands.json file. It is needed in order for the analyzer to get information about the compilation of certain files. If your build system doesn't support generation of the compile_commands.json file, you can try generating such file using the Bear utility.
This mode of checking the list of files can also be used with the compiler run tracing log generated by strace (pvs-studio-analyzer trace). To do it, first you need to complete a full project build and trace it so that the analyzer collected full information about the compilation parameters of all checked files.
However, this option has a significant drawback - you'll have to either perform full build tracing of the entire project with each run, which goes against the idea of a quick commit checking. Or if you cache the tracing result itself, subsequent analyzer runs might be incomplete in case if after tracing the structure of source files dependencies changes (for example, a new #include is added in one of the source files).
Therefore, we don't recommend using the mode of checking the list of files with a tracing log to check commits or pull requests. If you can perform an incremental build when checking a commit, consider using the incremental analysis mode.
The list of source files for the analysis is saved in the text file and passed to the analyzer using the -S parameter:
pvs-studio-analyzer analyze ... -f build/compile_commands.json -S check-list.txtThis file comprises relative and absolute paths to files where each new file comes on a new line. You can specify both file names for the analysis and different text. As for the text, the analyzer will notice that it is not a file name and will ignore the line. It might be useful for commenting if files are manually specified. However, often the list of files will be generated during the CI analysis, for example, it can be files from a commit or a pull request.
Now using this mode you can quickly check new code before it gets into the main development branch. The --indicate-warnings flag was added in the plog-converter utility so that the check system responded to the presence of analyzer warnings.
plog-converter ... --indicate-warnings ... -o /path/to/report.tasks ...With this flag, the converter will return a non-zero code if there are warnings in the analyzer report. You can block the pre commit hook, commit or pull request and display the generated analyzer report, share or send it by mail.
Note. During the first analysis of the list of files, the whole project will be checked, as the analyzer has to generate the file with dependencies of project source files from header files. This is a peculiarity of C and C++ files analysis. In the future, this dependency file can be cached and will be automatically updated by the analyzer. The advantage of checking commits using the mode of checking the list of files over the incremental analysis mode is the fact that you have to cache only this file, not the object files.
The entire project analysis takes quite a lot of time, so it makes sense to check only a part of it. The problem is that you need to separate new files from the rest of the project files.
Let's look at the example of a two-branch commit tree:
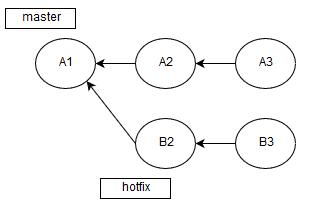
Imagine that the A1 commit contains quite large amount of code that has already been checked. Previously, we've made a branch from the A1 commit and changed some files.
Of course, you've noticed that after A1 other two commits took place, and two other branches merged, as we don't commit in master. Here comes the moment when hotfix is ready. That's why we got a pull request for B3 and A3 merging.
We could check the result of their merging, but it would be too long and unreasonable, as only a few files have been modified. Therefore, it's more efficient to analyze only the changed ones.
To do it, we'll receive the difference between branches, being in HEAD of the branch, from which we want to merge into the master:
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.listWe'll consider $MERGE_BASE in detail later. The fact is that not every CI service provides the needed information on the merge base, so every time we have to think of new ways of getting this data. This will be regarded in details below for each of the web services described.
So we got difference between branches, which is the list of modified files names. Now we need to feed this .pvs-pr.list file to the analyzer. We've redirected the output to it earlier.
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
-S .pvs-pr.listAfter the analysis, we need to convert the log file (PVS-Studio.log) into a user-friendly format:
plog-converter -t errorfile PVS-Studio.log --cerr -wThis command will output the list of errors in stderr (standard error stream).
The catch is that we need not only to output the errors, but also to report our build and test service about the problems. To do this, the -W (--indicate-warnings) flag was added in the converter. If there is at least one analyzer warning, the return code of the plog-converter utility will change to 2, which in turn will report CI service about potential errors in pull request's files.
The configuration is made in the form of the .travis.yml file. For convenience, I advise you to isolate all commands related to PVS-Studio in a separate bash script with functions that will be called from the file .travis.yml (bash script_name.sh function_name).
By expanding the script, you'll get more functionality. In the install section write the following:
install:
- bash .travis.sh travis_installIf you had some instructions, you can move them in the script, having removed hyphens.
Open the .travis.sh file and add the analyzer installation in the travis_install() function:
travis_install() {
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt \
| sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
sudo apt-get update -qq
sudo apt-get install -qq pvs-studio
}Now let's add the analyzer run in the script section:
script:
- bash .travis.sh travis_scriptAnd in the bash script:
travis_script() {
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
if [ "$TRAVIS_PULL_REQUEST" != "false" ]; then
git diff --name-only origin/HEAD > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
-S .pvs-pr.list \
--disableLicenseExpirationCheck
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fi
plog-converter -t errorfile PVS-Studio.log --cerr -w
}You have to run this code after building the project, for example, if you had a build on CMake:
travis_script() {
CMAKE_ARGS="-DCMAKE_EXPORT_COMPILE_COMMANDS=On ${CMAKE_ARGS}"
cmake $CMAKE_ARGS CMakeLists.txt
make -j8
}You'll get the following:
travis_script() {
CMAKE_ARGS="-DCMAKE_EXPORT_COMPILE_COMMANDS=On ${CMAKE_ARGS}"
cmake $CMAKE_ARGS CMakeLists.txt
make -j8
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
if [ "$TRAVIS_PULL_REQUEST" != "false" ]; then
git diff --name-only origin/HEAD > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
-S .pvs-pr.list \
--disableLicenseExpirationCheck
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fi
plog-converter -t errorfile PVS-Studio.log --cerr -w
}Most likely, you've already noticed the environment variables $TRAVIS_PULL_REQUEST and $TRAVIS_BRANCH. Travis CI declares them itself:
Here's the operational algorithm of this function:
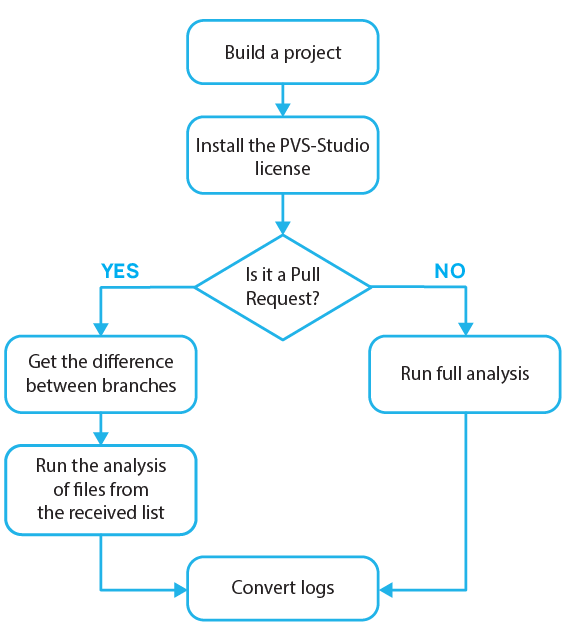
Travis CI responds to return codes, so the presence of warnings will report the service to mark the commit as containing errors.
Now let's take a closer look at this line of code:
git diff --name-only origin/HEAD > .pvs-pr.listThe fact is that Travis CI automatically merges branches when analyzing a pull request:
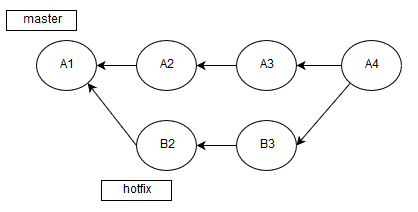
That's why we analyze A4, not B3->A3. Due to this peculiarity, we need to evaluate the difference with A3, which is the head of the branch from origin.
One important detail remains - caching the dependencies of header files from compiled translation units (*.c, *.cc, *.cpp and other). The analyzer evaluates these dependencies during the first run in the mode of checking the list of files and then stores them in the .PVS-Studio directory. Travis CI allows caching repositories, so we'll save data in the .PVS-Studio/ directory:
cache:
directories:
- .PVS-Studio/This code has to be added in the .travis.yml file: This directory stores various data, collected after the analysis. This data significantly speeds up subsequent runs of files list analysis or incremental analysis. If you don't do it, the analyzer will analyze all files every time.
The same as Travis CI, Buddy enables you to automatically build and test projects from GitHub. Unlike Travis CI, it is configured in the web interface (bash support is available), so there is no need to store configuration files in the project.
First, we need to add a new step to the pipeline:
Let's specify the compiler used for building the project. Pay attention to the docker container, installed during this step. For instance, there is a special container for GCC:
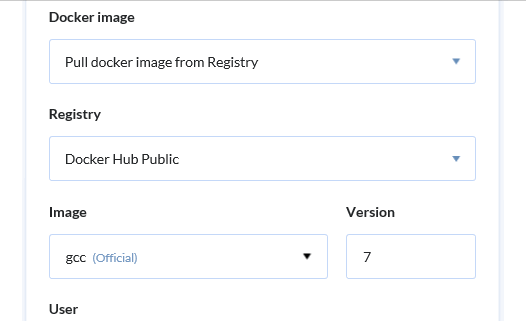
Now let's install PVS-Studio and necessary utilities:
Add the following lines to the editor:
apt-get update && apt-get -y install wget gnupg jq
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt | apt-key add -
wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
apt-get update && apt-get -y install pvs-studioLet's move on to the Run tab (first icon) and add the following code to the appropriate editor field:
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
if [ "$BUDDY_EXECUTION_PULL_REQUEST_NO" != '' ]; then
PULL_REQUEST_ID="pulls/$BUDDY_EXECUTION_PULL_REQUEST_NO"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${BUDDY_REPO_SLUG}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck \
-S .pvs-pr.list
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fi
plog-converter -t errorfile PVS-Studio.log --cerr -wIf you read the section about Travs-CI, this code is familiar to you. But here there is a new step:
The fact is that now we analyze not the result of merging, but the branch's HEAD with the checked pull request:
So we're in a B3 commit and we need to get the difference with A3:
PULL_REQUEST_ID="pulls/$BUDDY_EXECUTION_PULL_REQUEST_NO"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${BUDDY_REPO_SLUG}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.listTo define A3 let's use API GitHub:
https://api.github.com/repos/${USERNAME}/${REPO}/pulls/${PULL_REQUEST_ID}We used the following variables, which Buddy provides us with:
Now let's save changes, using the button below and enable the pull request analysis:
Unlike Travis CI, we don't have to specify .pvs-studio for caching, as Buddy automatically caches all files for subsequent runs. So the last thing left is to save the login and password for PVS-Studio in Buddy. After saving changes we'll get back in the Pipeline. We need to move on to setting up the variables and insert the login and key for PVS-Studio:
After this, a check will start with every new pull request or commit. If a commit contains errors, Buddy will point it out on the pull request page.
The AppVeyor setting is similar Buddy, as it all happens in the web interface and there is no need to add the *.yml file in the project repository.
Let's go to the Settings tab in the project review:
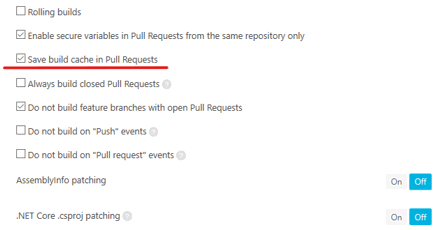
Scroll this page down and enable cache saving for pull request build:
Now let's move on to the Environment tab, where we'll specify the image for the build and needed environment variables:
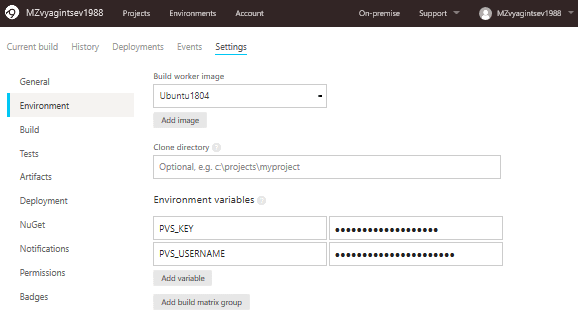
If you've read previous sections, you're already familiar with these two variables - PVS_KEY and PVS_USERNAME. If not, let me remind you that they are needed for checking the PVS-Studio analyzer license. In the future, we will meet them again in Bash scripts.
On the same page at the bottom, let's specify the cache folder:
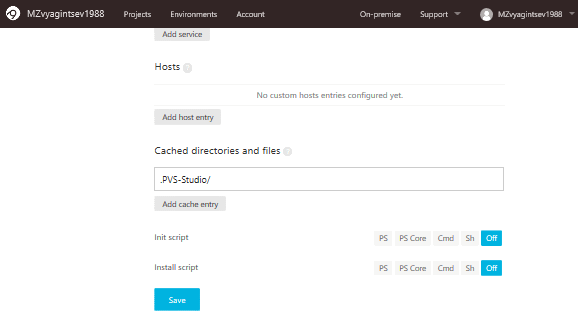
If we don't do it, we'll analyze the whole project instead of a couple of files, but will receive the output for specified files. So it's important to enter the correct name of the repository.
Now the time has come for the checking script. Open the Tests tab and choose Script:
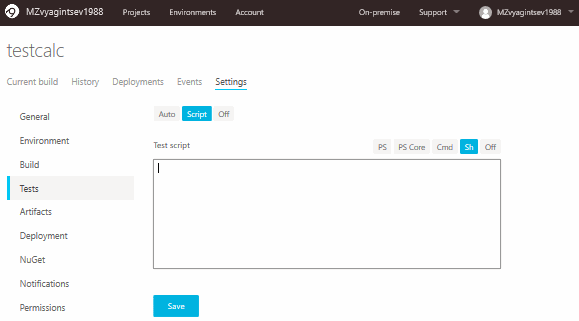
The following code should be inserted into this form:
sudo apt-get update && sudo apt-get -y install jq
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt \
| sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
sudo apt-get update && sudo apt-get -y install pvs-studio
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
PWD=$(pwd -L)
if [ "$APPVEYOR_PULL_REQUEST_NUMBER" != '' ]; then
PULL_REQUEST_ID="pulls/$APPVEYOR_PULL_REQUEST_NUMBER"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${APPVEYOR_REPO_NAME}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck \
--dump-files --dump-log pvs-dump.log \
-S .pvs-pr.list
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fi
plog-converter -t errorfile PVS-Studio.log --cerr -wLet's pay attention to the following part of the code:
PWD=$(pwd -L)
if [ "$APPVEYOR_PULL_REQUEST_NUMBER" != '' ]; then
PULL_REQUEST_ID="pulls/$APPVEYOR_PULL_REQUEST_NUMBER"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${APPVEYOR_REPO_NAME}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck \
--dump-files --dump-log pvs-dump.log \
-S .pvs-pr.list
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fiIt's a quite specific assignment of the pwd command's output value to the variable, which has to store this value by default. At first is seems strange, but let me explain everything.
While setting up the analyzer in AppVeyor, I stumbled upon highly strange analyzer behavior. On the one hand, everything worked correctly, but the analysis didn't start. It took a lot of time to notice that we were in the /home/appveyor/projects/testcalc/ directory, whereas the analyzer was sure that we were in /opt/appveyor/build-agent/. At that moment I realized that the $PWD variable is deceitful. For this reason, I manually renewed its value before running the analysis.
Further order of actions was the same as previously:
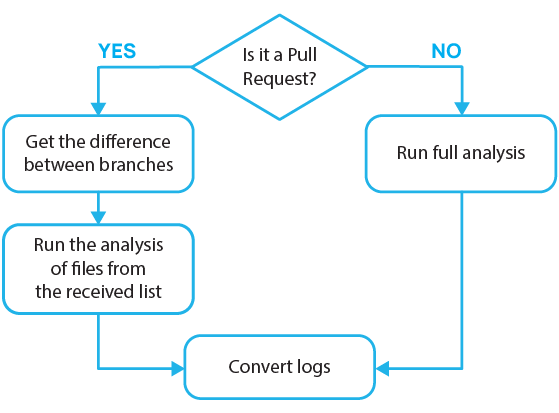
Now take a look at this fragment:
PULL_REQUEST_ID="pulls/$APPVEYOR_PULL_REQUEST_NUMBER"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${APPVEYOR_REPO_NAME}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`In it we get the difference between branches, related to the checked pull request. To do this, we need the following environment variables:
Well, we haven't considered all possible continuous integration services, however, they all have similar operational specifics. But as for caching, each service reinvents its own wheel, so it's always different.
In some cases (as in Travis-CI) it takes a couple of code lines - and caching works flawlessly. In other cases (as in AppVeyor), you just have to specify the directory in settings. But there are some services, where you need to create special keys and try to convince the system to give you the opportunity to rewrite a cached fragment. Therefore, if you want to configure pull request analysis on a continuous integration service, which wasn't considered above, first, make sure you won't have problems with caching.
Thank you for your attention. If something doesn't work out, you can safely write to our support. We'll give you a hint and help.
0
0
0
0