This article is the most complete collection of examples of 64-bit errors in the C and C++ languages. The article is intended for Windows-application developers who use Visual C++, however, it will be of use to other programmers as well.
Viva64 tool became a part of PVS-Studio product and is no longer distributed separately. All the abilities of searching for specific errors related to developing 64-bit applications, as well as porting code from 32-bit to 64-bit platform are now available within PVS-Studio analyzer.
Our company OOO "Program Verification Systems" develops a special static analyzer, Viva64, which detects 64-bit errors in the code of C/C++ applications. During this development process, we constantly enlarge our collection of examples of 64-bit defects, so we decided to gather the most interesting ones in this article. Here you will find examples taken directly from the code of real applications, and composed synthetically, relying on real code since such errors are too "extended" throughout the native code.
The article only demonstrates types of 64-bit errors, and does not describe methods of detecting and preventing them. If you want to know how to diagnose and fix defects in 64-bit programs, please see the following sources:
You may also try the demo version of the PVS-Studio tool, which includes the Viva64 static code analyzer, which detects almost all errors described in this article. The demo version of the tool can be downloaded here.
struct STRUCT_1
{
int *a;
};
struct STRUCT_2
{
int x;
};
...
STRUCT_1 Abcd;
STRUCT_2 Qwer;
memset(&Abcd, 0, sizeof(Abcd));
memset(&Qwer, 0, sizeof(Abcd));In this program, two objects of the STRUCT_1 and STRUCT_2 types are defined, which must be zeroed (all the fields must be initialized with nulls) before being used. While implementing the initialization, the programmer decided to copy a similar line and replaced "&Abcd" with "&Qwer" in it. However, he forgot to replace "sizeof(Abcd)" with "sizeof(Qwer)". Due to mere luck, the sizes of the STRUCT_1 and STRUCT_2 structures coincided on a 32-bit system, and the code has been working correctly for a long time.
When porting the code on the 64-bit system, the size of the Abcd structure increased, and it resulted in a buffer overflow error (see Figure 1).
Figure 1 - Schematic explanation of the buffer overflow example.
Such an error is difficult to detect, if the data which should be used much later gets spoiled.
char *buffer;
char *curr_pos;
int length;
...
while( (*(curr_pos++) != 0x0a) &&
((UINT)curr_pos - (UINT)buffer < (UINT)length) );This code is bad, yet it is real. Its task is to search for the end of the line marked with the 0x0A symbol. The code will not process lines longer than INT_MAX characters, since the length variable has the int type. But we are interested in another error, so let's assume that the program works with a small buffer, and it is correct to use the int type here.
The problem is that the buffer and curr_pos pointers might lie outside the first 4 Gbytes of the address space in a 64-bit system. In this case, the explicit conversion of the pointers to the UINT type will throw away the significant bits, and the algorithm will be violated (see Figure 2).
Figure 2 - Incorrect calculations when searching for the terminal symbol.
What is unpleasant about this error, is that the code can work for a long time as long as buffer memory is allocated within the first four Gbytes of the address space. To fix the error, you should remove the type conversions which are absolutely unnecessary:
while(curr_pos - buffer < length && *curr_pos != '\n')
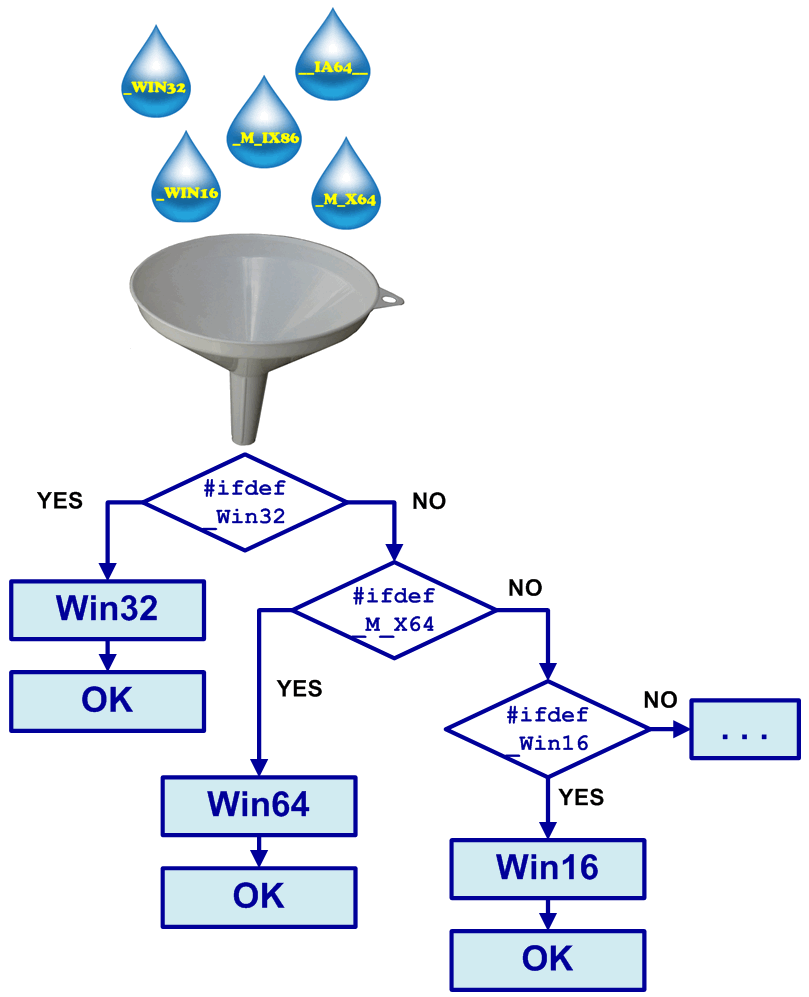
curr_pos++;You may often see code fragments wrapped in #ifdef - -#else - #endif constructs in programs with long history. When porting programs to the new architecture, the incorrectly written conditions might result in compilation of code fragments other than those intended by the developers (see Figure 3). For example:
#ifdef _WIN32 // Win32 code
cout << "This is Win32" << endl;
#else // Win16 code
cout << "This is Win16" << endl;
#endif
//Alternative incorrect variant:
#ifdef _WIN16 // Win16 code
cout << "This is Win16" << endl;
#else // Win32 code
cout << "This is Win32" << endl;
#endifFigure 3 - Two variants - this is too little.
It is dangerous to rely on the #else variant in such cases. It is better to explicitly check behavior for each case (see Figure 4), and add a message about a compilation error into the #else branch:
#if defined _M_X64 // Win64 code (Intel 64)
cout << "This is Win64" << endl;
#elif defined _WIN32 // Win32 code
cout << "This is Win32" << endl;
#elif defined _WIN16 // Win16 code
cout << "This is Win16" << endl;
#else
static_assert(false, "Unknown platform ");
#endifFigure 4 - All the possible compilation ways are checked.
In obsolete programs, especially those written in C, you may often see code fragments where a pointer is stored in the int type. However, sometimes it is done through lack of attention rather than on purpose. Let's consider an example with confusion caused by using the int type and a pointer to the int type:
int GlobalInt = 1;
void GetValue(int **x)
{
*x = &GlobalInt;
}
void SetValue(int *x)
{
GlobalInt = *x;
}
...
int XX;
GetValue((int **)&XX);
SetValue((int *)XX);In this sample, the XX variable is used as a buffer to store the pointer. This code will work correctly on 32-bit systems where the size of the pointer coincides with the int type's size. In a 64-bit system, this code is incorrect and the call
GetValue((int **)&XX);will cause corruption of the 4 bytes of memory next to the XX variable (see Figure 5).
Figure 5 - Memory corruption near the XX variable.
This code was being written either by a novice, or in a hurry. The explicit type conversions signal that the compiler was resisting the programmer until the last hinting to him that the pointer and the int type are different entities. But crude force won.
Correction of this error is elementary, and lies in choosing an appropriate type for the XX variable. The explicit type conversion becomes unnecessary:
int *XX;
GetValue(&XX);
SetValue(XX);Some API-functions can be dangerous when developing 64-bit applications, although they were composed for compatibility purpose. The functions SetWindowLong and GetWindowLong are a typical example of these. You may often see the following code fragment in programs:
SetWindowLong(window, 0, (LONG)this);
...
Win32Window* this_window = (Win32Window*)GetWindowLong(window, 0);You cannot reproach the programmer who once wrote this code. During the development process, he created this code relying on his experience and MSDN five or ten years ago, and it is absolutely correct from the viewpoint of 32-bit Windows. The prototype of these functions looks as follows:
LONG WINAPI SetWindowLong(HWND hWnd, int nIndex, LONG dwNewLong);
LONG WINAPI GetWindowLong(HWND hWnd, int nIndex);The explicit conversion of the pointer to the LONG type is also justified, since the sizes of the pointer and the LONG type coincide in Win32 systems. However, I think you understand that these type conversions might cause a crash or false behavior of the program after its being recompiled in the 64-bit version.
What is unpleasant about this error is that it occurs irregularly or very rarely at all. Whether the error will reveal itself or not depends upon the area of memory where the object is created, referred to by the "this" pointer. If the object is created in the 4 least significant Gbytes of the address space, the 64-bit program can work correctly. The error might occur unexpectedly long into the future, when the objects start to be created outside the first four Gbytes due to memory allocation.
In a 64-bit system, you can use the SetWindowLong/GetWindowLong functions only if the program really saves some values of the LONG, int, bool types and the like. If you need to work with pointers, you should use the following extended function versions: SetWindowLongPtr/GetWindowLongPtr. However, I should recommend to you to use new functions anyway, in order to avoid new errors in the future.
Examples with the SetWindowLong, and GetWindowLong functions are classic and cited in almost all the articles on 64-bit software development. But you should understand that it is not only these functions that you must consider. Among other functions are: SetClassLong, GetClassLong, GetFileSize, EnumProcessModules, GlobalMemoryStatus (see Figure 6).
Figure 6 - A table with the names of some obsolete and contemporary functions.
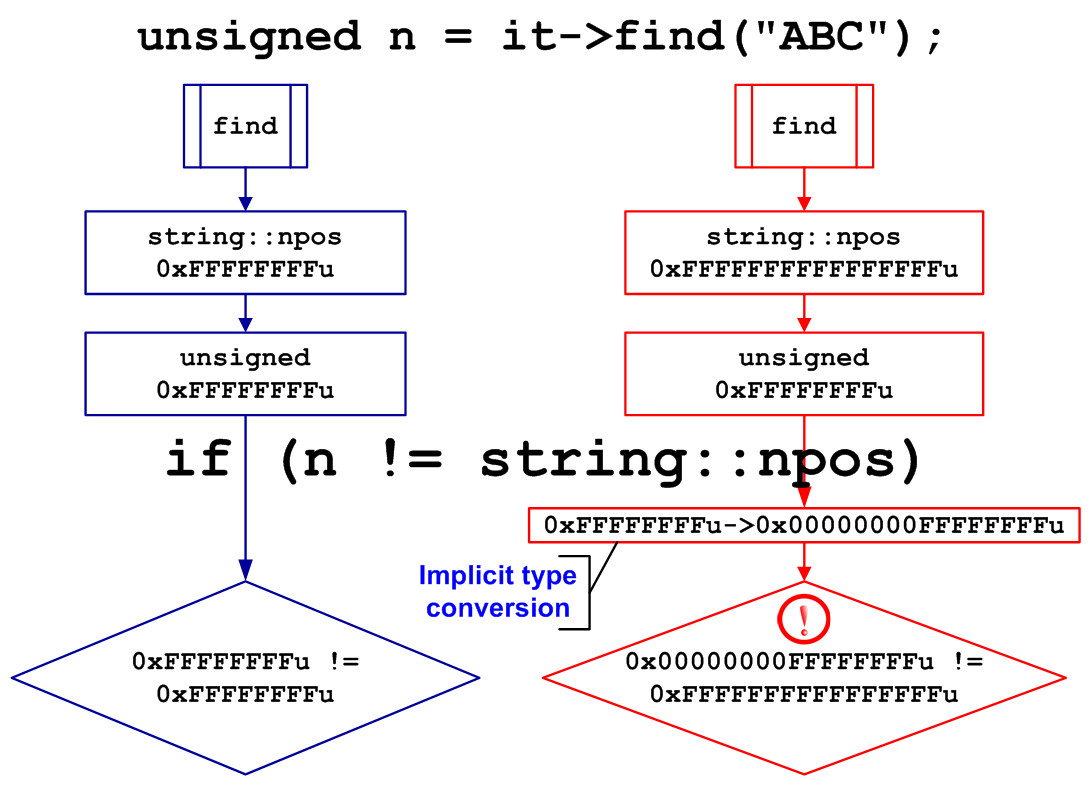
An implicit conversion of the size_t type to the unsigned type, and similar conversions, are easily diagnosed by the compiler's warnings. But in large programs, such warnings might be easily missed. Let's consider an example similar to real code, where the warning was ignored because it seemed to the programmer that nothing bad should happen when working with short strings.
bool Find(const ArrayOfStrings &arrStr)
{
ArrayOfStrings::const_iterator it;
for (it = arrStr.begin(); it != arrStr.end(); ++it)
{
unsigned n = it->find("ABC"); // Truncation
if (n != string::npos)
return true;
}
return false;
};The function searches for the text "ABC" in the array of strings, and returns true if at least one string contains the sequence "ABC". After recompilation of the 64-bit version of the code, this function will always return true.
The "string::npos" constant has value 0xFFFFFFFFFFFFFFFF of the size_t type in the 64-bit system. When putting this value into the "n" variable of the unsigned type, it is truncated to 0xFFFFFFFF. As a result, the condition " n != string::npos" is always true since 0xFFFFFFFFFFFFFFFF is not equal to 0xFFFFFFFF (see Figure 7).
Figure 7 - Schematic explanation of the value truncation error.
The correction of this error is elementary - you just should consider the compiler's warnings:
for (auto it = arrStr.begin(); it != arrStr.end(); ++it)
{
auto n = it->find("ABC");
if (n != string::npos)
return true;
}
return false;Despite the passing years, programs, or some of their parts, written in C remain as large as life. The code of these programs is much more subject to 64-bit errors because of less strict rules of type checking in the C language.
In C, you can use functions without preliminary declaration. Let's look at an interesting example of a 64-bit error related to this feature. Let's first consider the correct version of the code where allocation takes place and three arrays, one Gbyte each, are used:
#include <stdlib.h>
void test()
{
const size_t Gbyte = 1024 * 1024 * 1024;
size_t i;
char *Pointers[3];
// Allocate
for (i = 0; i != 3; ++i)
Pointers[i] = (char *)malloc(Gbyte);
// Use
for (i = 0; i != 3; ++i)
Pointers[i][0] = 1;
// Free
for (i = 0; i != 3; ++i)
free(Pointers[i]);
}This code will correctly allocate memory, write one into the first item of each array, and free the occupied memory. The code is absolutely correct on a 64-bit system.
Now let's remove or write a comment on the line "#include <stdlib.h>". The code will still be compiled, but the program will crash right after the launch. If the header file "stdlib.h" is not included, the C compiler supposes that the malloc function will return the int type. The first two instances of memory allocation will most likely be successful. When the memory is being allocated for the third time, the malloc function will return the array address outside the first 2 Gbytes. Since the compiler supposes that the function's result has the int type, it will interpret the result incorrectly and save an incorrect value of the pointer in the Pointers array.
Let's consider the assembler code generated by the Visual C++ compiler for the 64-bit Debug version. In the beginning, there is the correct code which will be generated when the definition of the malloc function is present (i.e. the "stdlib.h" file is included in):
Pointers[i] = (char *)malloc(Gbyte);
mov rcx,qword ptr [Gbyte]
call qword ptr [__imp_malloc (14000A518h)]
mov rcx,qword ptr [i]
mov qword ptr Pointers[rcx*8],raxNow let's look at the incorrect code, when the definition of the malloc function is absent:
Pointers[i] = (char *)malloc(Gbyte);
mov rcx,qword ptr [Gbyte]
call malloc (1400011A6h)
cdqe
mov rcx,qword ptr [i]
mov qword ptr Pointers[rcx*8],raxNote that there is the CDQE (Convert doubleword to quadword) instruction. The compiler supposes that the result is contained in the eax register, and extends it to a 64-bit value in order to write it into the Pointers array. Correspondingly, the most significant bits of the rax register will be lost. Even if the address of the allocated memory lies within the first four Gbytes, we will still get an incorrect result if the most significant bit of the eax register equals 1. For instance, address 0x81000000 will turn into 0xFFFFFFFF81000000.
Large, old program systems, which have been developing for tens of years are abound with various atavisms and code fragments written with popular paradigms and styles of different years. In such systems, you can watch the evolution of programming languages when the oldest fragments are written in C, and the freshest ones contain complex templates of Alexandrescu style.
Figure 8 - Dinosaur excavations.
There are atavisms referring to 64 bits as well. To be more exact, these are atavisms that prevent contemporary 64-bit code from working correctly. Consider an example:
// beyond this, assume a programming error
#define MAX_ALLOCATION 0xc0000000
void *malloc_zone_calloc(malloc_zone_t *zone,
size_t num_items, size_t size)
{
void *ptr;
...
if (((unsigned)num_items >= MAX_ALLOCATION) ||
((unsigned)size >= MAX_ALLOCATION) ||
((long long)size * num_items >=
(long long) MAX_ALLOCATION))
{
fprintf(stderr,
"*** malloc_zone_calloc[%d]: arguments too large: %d,%d\n",
getpid(), (unsigned)num_items, (unsigned)size);
return NULL;
}
ptr = zone->calloc(zone, num_items, size);
...
return ptr;
}First, the function's code contains the check of accessible sizes of allocated memory, which are strange for the 64-bit system. Second, the generated diagnostic message is incorrect, because if we ask to allocate memory for 4 400 000 000 items, we will see a strange message saying that the program cannot allocate memory for (only) 105 032 704 items. This happens because of the explicit type conversion to the unsigned type.
One nice example of 64-bit errors, is the use of incorrect argument types in definitions of virtual functions. Usually it is not one's mistake but just an "accident". It is nobody's fault, but the error still remains. Consider the following case.
For a very long time there has been the CWinApp class in the MFC library which has the WinHelp function:
class CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};To show the program's own help in a user application, you had to override this function:
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};Everything was alright until 64-bit systems appeared. The MFC developers had to change the interface of the WinHelp function (and some other functions as well) in the following way:
class CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};The DWORD_PTR and DWORD types coincided in the 32-bit mode, but they do not coincide in the 64-bit mode. Of course, the user application's developers must also change the type to DWORD_PTR, but they have to learn about it somehow before doing this. As a result, an error occurs in the 64-bit version since the WinHelp function cannot be called in the user class (see Figure 9).
Figure 9 - The error related to virtual functions.
Magic numbers contained in bodies of programs provoke errors, and using them is bad styling. Such numbers are, for instance, numbers 1024 and 768 that strictly define screen resolution. Within the scope of this article, we are interested in those magic numbers that might cause issues in a 64-bit application. The most widely used magic numbers which are dangerous for 64-bit programs are shown in the table in Figure 10.
Figure 10 - Magic numbers dangerous for 64-bit programs.
Consider an example of working with the CreateFileMapping function, taken from some CAD-system:
HANDLE hFileMapping = CreateFileMapping(
(HANDLE) 0xFFFFFFFF,
NULL,
PAGE_READWRITE,
dwMaximumSizeHigh,
dwMaximumSizeLow,
name);Number 0xFFFFFFFF is used instead of the correct reserved constant INVALID_HANDLE_VALUE. It is incorrect from the viewpoint of a Win64-program, where the INVALID_HANDLE_VALUE constant takes value 0xFFFFFFFFFFFFFFFF. Here is a correct way of calling the function:
HANDLE hFileMapping = CreateFileMapping(
INVALID_HANDLE_VALUE,
NULL,
PAGE_READWRITE,
dwMaximumSizeHigh,
dwMaximumSizeLow,
name);Note. Some people think that value 0xFFFFFFFF turns into 0xFFFFFFFFFFFFFFFF while extending to the pointer; it is not so. According to C/C++ rules, value 0xFFFFFFFF has the "unsigned int" type since it cannot be represented with the "int" type. Correspondingly, value 0xFFFFFFFFu turns into 0x00000000FFFFFFFFu when extending to the 64-bit type. But if you write (size_t)(-1), you will get the expected 0xFFFFFFFFFFFFFFFF. Here "int" extends to "ptrdiff_t" first and then turns into "size_t".
Another frequent error, is using magic constants to define an object's size. Consider an example of buffer allocation and zeroing:
size_t count = 500;
size_t *values = new size_t[count];
// Only a part of the buffer will be filled
memset(values, 0, count * 4);In this case, in the 64-bit system, the amount of memory being allocated is larger than the amount of memory which is filled with zero values (see Figure 11) . The error lies in the assumption that the size of the size_t type is always four bytes.
Figure 11 - Only a part of the array is filled.
This is the correct code:
size_t count = 500;
size_t *values = new size_t[count];
memset(values, 0, count * sizeof(values[0]));You may encounter similar errors when calculating sizes of memory being allocated, or data serialization.
In many cases, a 64-bit program consumes more memory and stack. Allocation of more physical memory is not dangerous, since a 64-bit program can access much larger amounts of this type of memory than a 32-bit one. But increase of stack memory consumption might cause a stack overflow.
The mechanism of using the stack differs in various operating systems and compilers. We will consider the specifics of using the stack in the code of Win64 applications built with the Visual C++ compiler.
When developing calling conventions in Win64 systems, the developers decided to bring an end to different versions of function calls. In Win32, there were a lot of calling conventions: stdcall, cdecl, fastcall, thiscall and so on. In Win64, there is only one "native" calling convention. The compiler ignores modifiers like __cdecl.
The calling convention on the x86-64 platform resembles the fastcall convention in x86. In the x64-convention, the first four integer arguments (left to right) are passed in 64-bit registers used specially for this purpose:
RCX: 1-st integer argument
RDX: 2-nd integer argument
R8: 3-rd integer argument
R9: 4-th integer argument
All the other integer arguments are passed through the stack. The "this" pointer is considered an integer argument, so it is always put into the RCX register. If floating-point values are passed, the first four of them are passed in the XMM0-XMM3 registers, and all the following ones are passed through the stack.
Although arguments may be passed in registers, the compiler will still reserve space for them in stack, thereby reducing the value of the RSP register (stack pointer). Each function must reserve at least 32 bytes (four 64-bit values corresponding to the registers RCX, RDX, R8, R9) in the stack. This space in the stack lets you easily save the contents of registers passed into the function in the stack. The function being called is not required to drop input parameters passed through the registers into the stack, but stack space reservation allows this to be done, if necessary. If more than four integer parameters are passed, the corresponding additional space is reserved in the stack.
The described feature leads to a significant growth of stack consumption speed. Even if the function does not have parameters, 32 bytes will be "bit off" the stack all the same, and they will not be used then anyway. The use of such a wasteful mechanism is determined by the purposes of unification and debugging simplification.
Consider one more thing. The stack pointer RSP must be aligned on a 16-byte boundary before the next call of the function. Thus, the total size of the stack being used when calling a function without parameters in 64-bit code is 48 bytes: 8 (return address) + 8 (alignment) + 32 (reserved space for arguments).
Can everything be so bad? No. Do not forget that a larger number of registers available to the 64-bit compiler allows it to build a more effective code, and avoid reserving stack memory for some local function variables. Thus, the 64-bit version of a function in some cases uses less stack memory than its 32-bit version. To learn more about this question, see the article "The reasons why 64-bit programs require more stack memory".
It is impossible to predict if a 64-bit program will consume more or less stack memory. Since a Win64-program can use 2-3 times more stack memory, you should secure yourself and change the project option responsible for the size of stack being reserved. Choose the Stack Reserve Size (/STACK:reserve switch) parameter in the project settings, and increase the size of stack being reserved three times. This size is 1 Mbyte by default.
Although it is considered bad styling in C++ to use functions with a variable number of arguments, such as printf and scanf, they are still widely used. These functions cause a lot of problems while porting applications to other systems, including 64-bit ones. Consider an example:
int x;
char buf[9];
sprintf(buf, "%p", &x);The author of this code did not take into account that the pointer's size might become larger than 32 bits in future. As a result, this code will cause a buffer overflow on the 64-bit architecture (see Figure 12). This error might be referred to the type of errors caused by magic numbers (number '9' in this case), but the buffer overflow can occur without magic numbers in a real application.
Figure 12 - A buffer overflow when working with the sprintf function.
There are several ways to correct this code. The most reasonable way is to factor the code in order to get rid of dangerous functions. For example, you may replace printf with cout, and sprintf with boost::format or std::stringstream.
Note. Linux-developers often criticize this recommendation, arguing that gcc checks if the format string corresponds to actual parameters which are being passed; for instance, into the printf function. Therefore it is safe to use the printf function. But they forget that the format string can be passed from some other part of the program, or loaded from resources. In other words, in a real program, the format string is seldom present explicitly in the code, and therefore the compiler cannot check it. But if the developer uses Visual Studio 2005/2008/2010, he will not get a warning on the code like "void *p = 0; printf("%x", p);" even if he uses the /W4 and /Wall switches.
You may often see incorrect format strings in programs when working with the printf function, and other similar functions; because of this, you will get incorrect output values. Although it will not cause a crash, it is certainly an error:
const char *invalidFormat = "%u";
size_t value = SIZE_MAX;
// A wrong value will be printed
printf(invalidFormat, value);In other cases, an error in the format string will be crucial. Consider an example based on an implementation of the UNDO/REDO subsystem in one program:
// The pointers were saved as strings here
int *p1, *p2;
....
char str[128];
sprintf(str, "%X %X", p1, p2);
// In another function this string
// was processed in the following way:
void foo(char *str)
{
int *p1, *p2;
sscanf(str, "%X %X", &p1, &p2);
// The result is incorrect values of p1 and p2 pointers.
...
}The "%X" format is not intended to work with pointers, and therefore such code is incorrect from the viewpoint of 64-bit systems. In 32-bit systems, it is quite efficient, yet looks ugly.
We did not encounter this error ourselves. Perhaps it is rare, yet quite possible.
The double type has the size 64 bits, and it is compatible with the IEEE-754 standard on 32-bit and 64-bit systems. Some programmers use the double type to store and handle integer types:
size_t a = size_t(-1);
double b = a;
--a;
--b;
size_t c = b; // x86: a == c
// x64: a != cThe code of this example can be justified in the case of a 32-bit system, since the double type has 52 significant bits and can store 32-bit integer values without loss. However, when you try to store a 64-bit integer value into double, you might lose an exact value (see Figure 13).
Figure 13 - The number of significant bits in the types size_t and double.
Address arithmetic is a means of calculating an address of some object with the help of arithmetic operations over pointers, and also using pointers in comparison operations. Address arithmetic is also called pointer arithmetic.
It is address arithmetic which many 64-bit errors refer to. Errors often occur in expressions where pointers and 32-bit variables are used together.
Consider the first error of this type:
char *A = "123456789";
unsigned B = 1;
char *X = A + B;
char *Y = A - (-B);
if (X != Y)
cout << "Error" << endl;The reason why A + B == A - (-B) in a Win32 program is explained in Figure 14.
Figure 14 - Win32: A + B == A - (-B)
The reason why A + B != A - (-B) in a Win64 program, is explained in Figure 15.
Figure 15 - Win64: A + B != A - (-B)
You can eliminate the error if you use an appropriate memsize-type. In this case, the ptrdfiff_t type is used:
char *A = "123456789";
ptrdiff_t B = 1;
char *X = A + B;
char *Y = A - (-B);Consider one more of the error type related to signed and unsigned types. In this case, the error will immediately cause a program crash instead of an incorrect comparison operation.
LONG p1[100];
ULONG x = 5;
LONG y = -1;
LONG *p2 = p1 + 50;
p2 = p2 + x * y;
*p2 = 1; // Access violationThe "x * y" expression has value 0xFFFFFFFB, and its type is unsigned. This code is efficient in the 32-bit version, since addition of the pointer to 0xFFFFFFFB is equivalent to its decrement by 5. In the 64-bit version, the pointer will point far outside the p1 array's boundaries after being added to 0xFFFFFFFB (see Figure 16).
Figure 16 - Out of the array's boundaries.
To correct this issue, you should use memsize-types, and be careful when working with signed and unsigned types:
LONG p1[100];
LONG_PTR x = 5;
LONG_PTR y = -1;
LONG *p2 = p1 + 50;
p2 = p2 + x * y;
*p2 = 1; // OKclass Region {
float *array;
int Width, Height, Depth;
float Region::GetCell(int x, int y, int z) const;
...
};
float Region::GetCell(int x, int y, int z) const {
return array[x + y * Width + z * Width * Height];
}This code is taken from a real application of mathematic modeling, where the size of physical memory is a very crucial resource, so the possibility of using more than 4 Gbytes of memory on the 64-bit architecture significantly increases the computational power. In programs of this class, one-dimensional arrays are often used in order to save memory, and they are handled like third-dimensional arrays. To do this, there exist functions similar to GetCell, which provide access to necessary items.
This code works correctly with pointers if the result of the " x + y * Width + z * Width * Height" expression does not exceed INT_MAX (2147483647). Otherwise an overflow will occur, leading to an unexpected program behavior.
This code could always work correctly on the 32-bit platform. Within the scope of the 32-bit architecture, the program cannot get the necessary memory amount to create an array of such a size. But this limitation is absent on the 64-bit architecture, and the array's size might easily exceed INT_MAX items.
Programmers often make a mistake by trying to fix the code this way:
float Region::GetCell(int x, int y, int z) const {
return array[static_cast<ptrdiff_t>(x) + y * Width +
z * Width * Height];
}They know that the expression to calculate the index will have the ptrdiff_t type according to C++ rules, and try to avoid the overflow therefore. But the overflow might occur inside the "y * Width" or "z * Width * Height" subexpressions, since it is still the int type that is used to calculate them.
If you want to fix the code without changing the types of the variables participating in the expression, you may explicitly convert each subexpression to the ptrdiff_t type:
float Region::GetCell(int x, int y, int z) const {
return array[ptrdiff_t(x) +
ptrdiff_t(y) * Width +
ptrdiff_t(z) * Width * Height];
}Another, better, solution is to change the variables' types:
typedef ptrdiff_t TCoord;
class Region {
float *array;
TCoord Width, Height, Depth;
float Region::GetCell(TCoord x, TCoord y, TCoord z) const;
...
};
float Region::GetCell(TCoord x, TCoord y, TCoord z) const {
return array[x + y * Width + z * Width * Height];
}Sometimes programmers change the type of an array while processing it, for the purpose of convenience. The following code contains dangerous and safe type conversions:
int array[4] = { 1, 2, 3, 4 };
enum ENumbers { ZERO, ONE, TWO, THREE, FOUR };
//safe cast (for MSVC)
ENumbers *enumPtr = (ENumbers *)(array);
cout << enumPtr[1] << " ";
//unsafe cast
size_t *sizetPtr = (size_t *)(array);
cout << sizetPtr[1] << endl;
//Output on 32-bit system: 2 2
//Output on 64-bit system: 2 17179869187As you may notice, the output results differ in the 32-bit and 64-bit versions. On the 32-bit system, the access to the array's items is correct, because the sizes of the size_t and int types coincide, and we get the output "2 2".
On the 64-bit system, we got "2 17179869187" in the output since it is this very value 17179869187 which is located in the first item of the sizePtr array (see Figure 17). Sometimes this behavior is intended, but most often it is an error.
Figure 17 - Representation of array items in memory
Note. The size of the enum type by default coincides with the size of the int type in the Visual C++ compiler, i.e. the enum type is a 32-bit type. You can use enum of a different size only with the help of an extension, which is considered non-standard in Visual C++. That is why the example given is correct in Visual C++, but from the viewpoint of other compilers conversion of an int-item pointer to an enum-item pointer is also incorrect.
Sometimes pointers are stored in integer types. Usually the int type is used for this purpose. This is perhaps one of the most frequent 64-bit errors.
char *ptr = ...;
int n = (int) ptr;
...
ptr = (char *) n;In a 64-bit program, this is incorrect since the int type remains 32-bit, and cannot store a 64-bit pointer. The programmer will often not notice this straight away. Due to shear luck, the pointer might always refer to objects located within the first 4 Gbytes of the address space during the testing. In this case, the 64-bit program will work efficiently, and crash only after a long period of time (see Figure 18).
Figure 18 - Putting a pointer into a variable of int type.
If you still need to store a pointer in a variable of an integer type, you should use such types as intptr_t, uintptr_t, ptrdiff_t and size_t.
When you need to work with a pointer as an integer, it is sometimes convenient to use a union as shown in the example, and work with the numeric representation of the type without explicit conversions:
union PtrNumUnion {
char *m_p;
unsigned m_n;
} u;
u.m_p = str;
u.m_n += delta;This code is correct on 32-bit systems and incorrect on 64-bit. Changing the m_n member on a 64-bit system, we work only with a part of the m_p pointer (see Figure 19).
Figure 19 - Representation of a union in memory on a 32-bit system and 64-bit systems.
You should use a type that corresponds to the pointer's size:
union PtrNumUnion {
char *m_p;
uintptr_t m_n; //type fixed
} u;Mixed use of 32-bit and 64-bit types can cause unexpected infinity loops. Consider a synthetic sample illustrating a whole class of such defects:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; Index++)
{ ... }This loop will never stop if the Count value > UINT_MAX. Assume that this code worked with the number of iterations less than UINT_MAX on 32-bit systems. But the 64-bit version of this program can process more data, and it may require more iterations. Since the values of the Index variable lie within the range [0..UINT_MAX], the condition "Index != Count" will never be fulfilled, and it will cause an infinity loop (see Figure 20).
Figure 20 - The mechanism of an infinity loop.
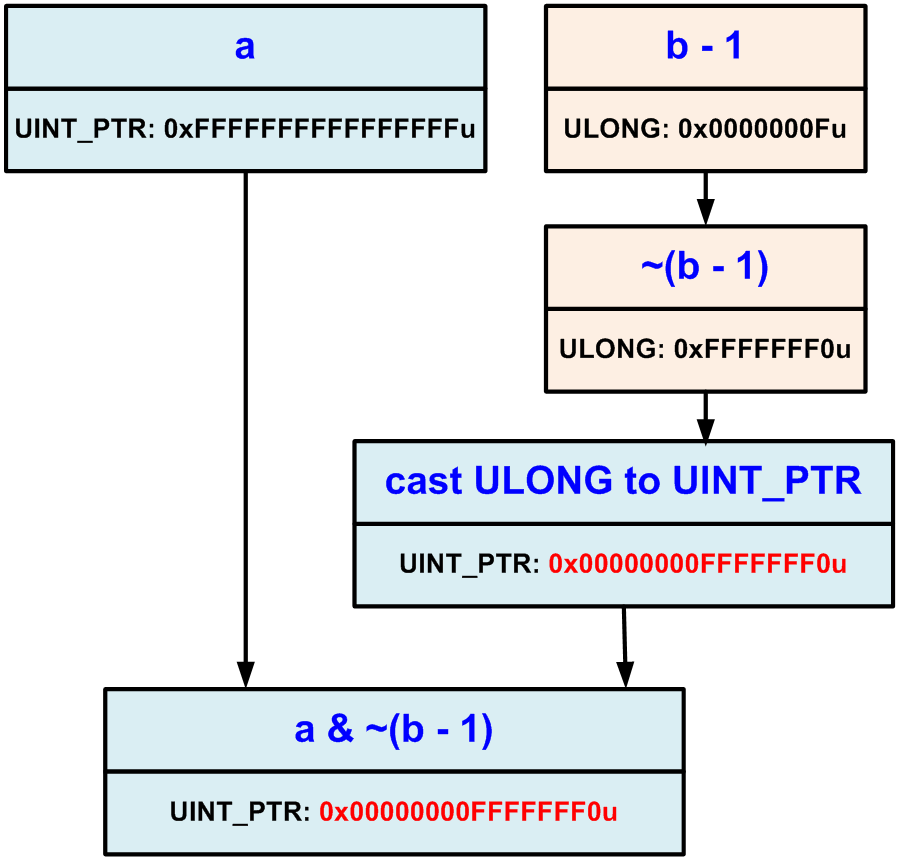
Bit operations require special care from the programmer, when developing crossplatform applications where data types may have different sizes. Since migration of a program to the 64-bit platform also makes the capacity of some types change, it is highly probable that errors will occur in those code fragments that work with separate bits. Most often, it happens when 32-bit and 64-bit data types are handled together. Consider an error occurring in the code because of an incorrect use of the NOT operation:
UINT_PTR a = ~UINT_PTR(0);
ULONG b = 0x10;
UINT_PTR c = a & ~(b - 1);
c = c | 0xFu;
if (a != c)
cout << "Error" << endl;The error consists of the mask defined by the "~(b - 1)" expression having the ULONG type. It causes zeroing of the most significant bits of the "a" variable, although it is only the four least significant bits that should have been zeroed (see Figure 21).
Figure 21 - The error occurring because of zeroing of the most significant bits.
The correct version of the code looks as follows:
UINT_PTR c = a & ~(UINT_PTR(b) - 1);This example is extremely simple, but it is perfect to demonstrate the class of errors that might occur when you actively work with bit operations.
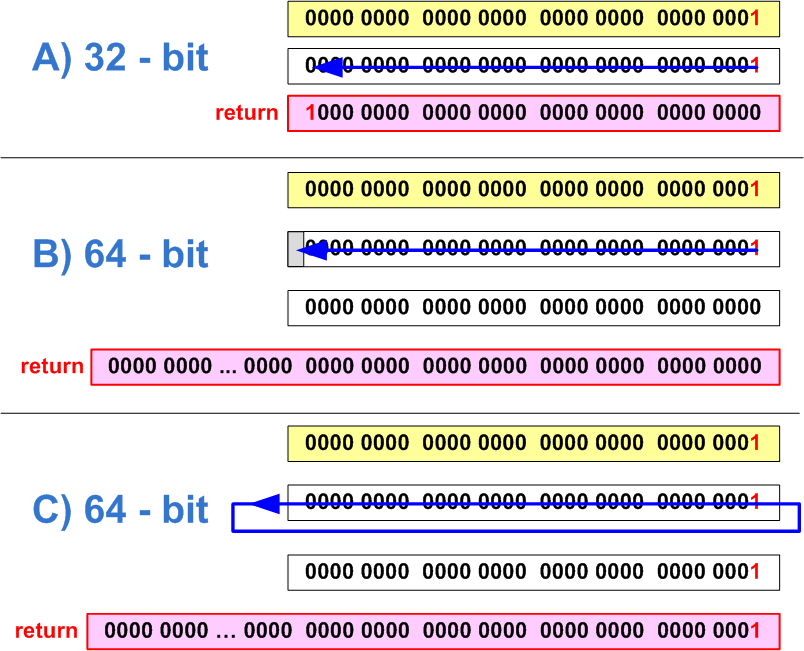
ptrdiff_t SetBitN(ptrdiff_t value, unsigned bitNum) {
ptrdiff_t mask = 1 << bitNum;
return value | mask;
}This code works well on the 32-bit architecture, and allows to set a bit with the numbers from 0 to 31 into one. After porting the program to the 64-bit platform, you need to set bits with the numbers from 0 to 63. However this code cannot set the most significant bits with the numbers 32-63. Note that the numeric literal "1" has the int type, and an overflow will occur after an offset at 32 positions, as shown in Figure 22. We will get 0 (Figure 22-B) or 1 (Figure 22-C) - depending on the compiler's implementation.
Figure 22 - a) correct setting of the 31st bit in the 32-bit code (the bits are counted beginning with 0); b,c) - The error of setting the 32nd bit on the 64-bit system (the two variants of behavior that depend upon the compiler)
To correct the code, you should make the "1" constant's type the same as the type of the mask variable:
ptrdiff_t mask = static_cast<ptrdiff_t>(1) << bitNum;Note also that the incorrect code will lead to one more interesting error. When setting the 31-st bit on the 64-bit system, the result of the function is 0xffffffff80000000 (see Figure 23). The result of the 1 << 31 expression is the negative number -2147483648. This number is represented in a 64-bit integer variable as 0xffffffff80000000.
Figure 23 - The error of setting the 31-st bit on the 64-bit system.
The error shown below is rare yet, unfortunately, quite difficult to understand. So let's discuss it in detail.
struct BitFieldStruct {
unsigned short a:15;
unsigned short b:13;
};
BitFieldStruct obj;
obj.a = 0x4000;
size_t x = obj.a << 17; //Sign Extension
printf("x 0x%Ix\n", x);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0xffffffff80000000In the 32-bit environment, the sequence of expression calculation looks as shown in Figure 24.
Figure 24 - Calculation of the expression in the 32-bit code.
Note that sign extension of the unsigned short type to int takes place during the calculation of the "obj.a << 17" expression. The following code makes it clearer:
#include <stdio.h>
template <typename T> void PrintType(T)
{
printf("type is %s %d-bit\n",
(T)-1 < 0 ? "signed" : "unsigned", sizeof(T)*8);
}
struct BitFieldStruct {
unsigned short a:15;
unsigned short b:13;
};
int main(void)
{
BitFieldStruct bf;
PrintType( bf.a );
PrintType( bf.a << 2);
return 0;
}
Result:
type is unsigned 16-bit
type is signed 32-bitNow let's see the consequence of a sign extension in 64-bit code. The sequence of expression calculation is shown in Figure 25.
Figure 25 - Calculation of the expression in 64-bit code
The member of the obj.a structure, is cast from the bit field of the unsigned short type into int. The "obj.a << 17" expression has the int type but it is cast to ptrdiff_t and then to size_t before being assigned to the addr variable. As a result, we will get value 0xffffffff80000000 instead of 0x0000000080000000 we have expected.
Be careful when working with bit fields. To avoid the described situation in our example, you just need to convert obj.a to the size_t type.
...
size_t x = static_cast<size_t>(obj.a) << 17; // OK
printf("x 0x%Ix\n", x);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0x80000000Succession to the existing communications protocols is an important element in migration of a software solution to a new platform. You must provide the possibility of reading existing project formats, data exchange between 32-bit and 64-bit processes, and so on.
In general, errors of this kind consist of serialization of memsize-types, and data exchange operations that use them:
size_t PixelsCount;
fread(&PixelsCount, sizeof(PixelsCount), 1, inFile);You cannot use types that change their size depending upon the development environment in binary data exchange interfaces. In C++, most types do not have strict sizes, and therefore they all cannot be used for these purposes. That is why the developers of development tools, and programmers themselves, create data types that have strict sizes such as __int8, __int16, INT32, word64, etc.
Even on correcting all the issues referring to type sizes, you might encounter the problem of incompatibility of binary formats. The reason lies in a different data representation. Most often it is determined by a different byte order.
Byte order is a method of writing bytes of multi-byte numbers (see Figure 26). The little-endian order means that writing begins with the least significant byte, and ends with the most significant byte. This writing order is accepted in the memory of personal computers with x86 and x86-64-processores. The big-endian order means that writing begins with the most significant byte, and ends with the least significant byte. This order is a standard for TCP/IP protocols. That is why the big-endian byte order is often called the network byte order. This byte order is used in Motorola 68000 and SPARC processors.
By the way, some processors can work in both orders. For instance, IA-64 is such a processor.
Figure 26 - Byte order in a 64-bit type in little-endian and big-endian systems.
While developing a binary data interface or format, you should remember the byte order. If the 64-bit system you are porting your 32-bit application to has a different byte order, you will just have to take this into account for your code. To convert between the big-endian and little-endian byte orders, you may use the functions htonl(), htons(), bswap_64, etc.
Besides change of size of some data types, errors might also due to changes of rules of their alignment in a 64-bit system (see Figure 27).
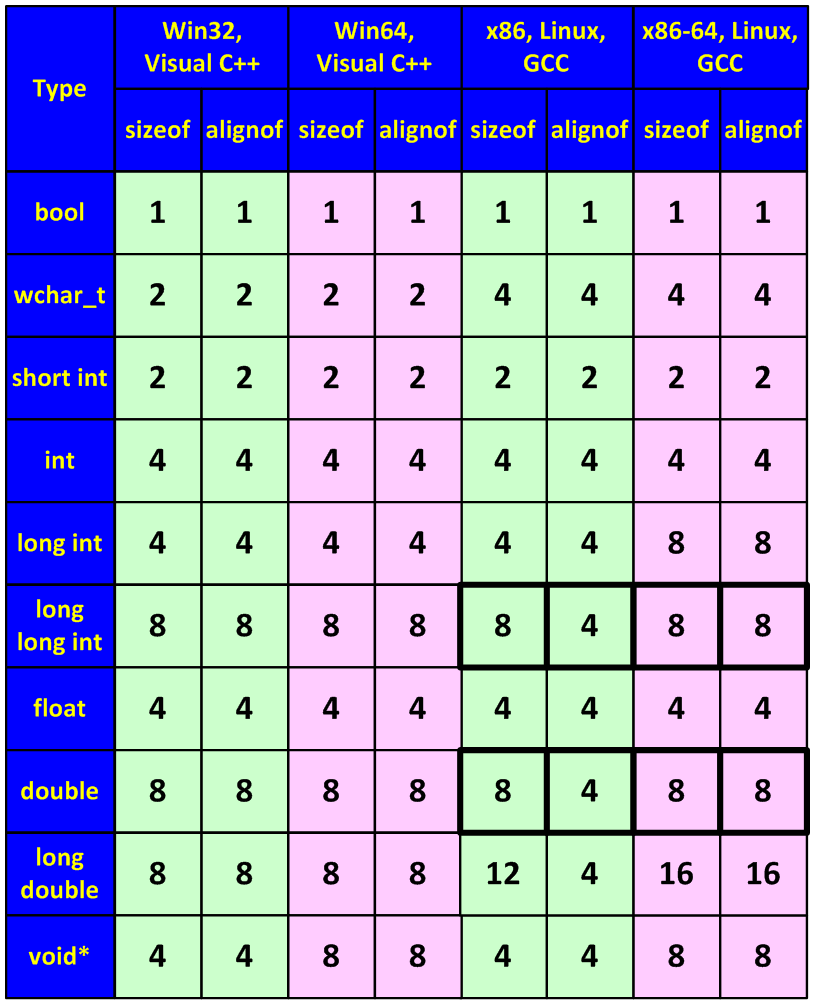
Figure 27 - Sizes of types, and their alignment boundaries (the figures are exact for Win32/Win64 but may vary in the "Unix-world", so they are given only for demonstration purpose).
Consider a description of the issue found in one forum:
I have encountered an issue in Linux today. There is a data structure consisting of several fields: a 64-bit double, 8 unsigned char, and one 32-bit int. All in all there are 20 bytes (8 + 8*1 + 4). On 32-bit systems, sizeof equals 20 and everything is ok. But on the 64-bit Linux, sizeof returns 24. That is, there is a 64-bit boundary alignment.
Then this person discusses the problem of data compatibility, and asks for advice on how to pack the data in the structure. We are not interested in this at the moment. What is relevant, is that this is another type of error that might occur when you port applications to 64-bit systems.
It is quite clear and familiar that changes of the sizes of fields in a structure cause the size of the structure itself to change. But here we have a different case. The sizes of the fields remain the same but the structure's size still changes due to other alignment rules (see Figure 28). This behavior might lead to various errors, for instance, errors in format incompatibility of saved data.
Figure 28 - A scheme of structures and type alignment rules
Sometimes programmers use structures with an array of a variable size at the end. Such a structure and the mechanism of memory allocation for it might look as follows:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr[1];
} object;
...
malloc( sizeof(DWORD) + 5 * sizeof(PVOID) );
...This code is correct in the 32-bit version but fails in the 64-bit version.
When allocating memory needed to store an object like MyPointersArray that contains 5 pointers, you should consider that the beginning of the m_arr array will be aligned on an 8-byte boundary. Data arrangement in memory on different systems (Win32/Win64) is shown in Figure 29.
Figure 29 - Data arrangement in memory in 32-bit and 64-bit systems.
The correct calculation of the size in shown in the following:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr[1];
} object;
...
malloc( FIELD_OFFSET(struct MyPointersArray, m_arr) +
5 * sizeof(PVOID) );
...In this code, we determine the offset of the last structure's member, and add this offset to its size. The offset of a structure's or class' member may be obtained with the help of the offsetof, or FIELD_OFFSET macros. You should always use these macros to obtain the offset in a structure without relying on your assumptions about sizes of types and rules of their alignment.
When you recompile a program, some other overloaded function might start to be selected (see Figure 30).
Figure 30 - Choosing an overloaded function in a 32-bit system and 64-bit system.
Here is an example of the problem:
class MyStack {
...
public:
void Push(__int32 &);
void Push(__int64 &);
void Pop(__int32 &);
void Pop(__int64 &);
} stack;
ptrdiff_t value_1;
stack.Push(value_1);
...
int value_2;
stack.Pop(value_2);The inaccurate programmer put, and then chose, from the stack values of different types (ptrdiff_t and int). Their sizes coincided on the 32-bit syste,m and everything was alright. When the size of the ptrdiff_t type changed in the 64-bit program, the number of bytes put in the stack became larger than the number of bytes that would be fetched from it.
The last example covers errors in 32-bit programs which occur when they are executed in the 64-bit environment. 64-bit software systems will include 32-bit units for a long time, and therefore we must provide for their workability in the 64-bit environment. The WoW64 subsystem fulfills this task very well by isolating a 32-bit application, so that almost all 32-bit applications work correctly. However, sometimes errors occur, and they refer most often to the redirection mechanism when working with files and Windows register.
For instance, when dealing with a system that consists of 32-bit and 64-bit units which interact with each other, you should consider that they use different register representations. Thus, the following line stopped working in a 32-bit unit in one program:
lRet = RegOpenKeyEx(HKEY_LOCAL_MACHINE,
"SOFTWARE\\ODBC\\ODBC.INI\\ODBC Data Sources", 0,
KEY_QUERY_VALUE, &hKey);To make this program friends with other 64-bit parts, you should insert the KEY_WOW64_64KEY switch:
lRet = RegOpenKeyEx(HKEY_LOCAL_MACHINE,
"SOFTWARE\\ODBC\\ODBC.INI\\ODBC Data Sources", 0,
KEY_QUERY_VALUE | KEY_WOW64_64KEY, &hKey);The method of static code analysis shows the best result in searching for the errors described in this article. As an example of a tool that performs this kind of analysis, we can name the Viva64 tool included in the PVS-Studio package we are developing.
The methods of static searching of defects, allows detecting defects, relying on the source program code. The program behavior is estimated at all the execution paths simultaneously. Because of this, static analysis lets you find defects that occur only at non-standard execution paths with rare input data. This feature supplements other testing methods, and increases security of applications. Static analysis systems might be used in source code audit, for the purpose of systematic elimination of defects in existing programs; they can integrate into the development process and automatically detect defects in the code being created.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}