
Our website uses cookies to enhance your browsing experience.
Episode 267 of CppCast was recorded on September 30th, 2020. Hosts Rob Irving and Jason Turner talked to Emery Berger, a Professor in the College of Information and Computer Science at the University of Massachusetts Amherst. They discussed New C++ features in GCC 10 and Pattern Matching from September C++ ISO Mailing. They talked about performance issues in C++ and garbage collectors' usage. They also chat about DieHard, an error-resistant memory allocator; Stabilizer, a compiler transformation and runtime library for dynamic memory layout randomization and Coz, a new kind of profiler.

Rob: Welcome to episode 267 of CppCast! Joining us today is Emery Berger. Emery is a Professor in the College of Information and Computer Science at the University of Massachusetts Amherst. He graduated with a Ph.D. in Computer Science from the University of Texas at Austin in 2002 and has been a Visiting Scientist at Microsoft Research. Professor Berger's research spans programming languages, runtime systems, and operating systems with a particular focus on systems that transparently improve reliability, security, and performance.

Figure 1. Emery Berger at work.
Rob: Emery, welcome to the show!
Emery: Thanks so much. Thanks for having me.
Rob: We got a couple of news articles to discuss. Feel free to comment on any of these and we'll start talking more about your work on performance. The first one we have is a blog post on the Red Hat Developer blog about New C++ features in GCC 10. We can get some of them but not everything is available yet from C++20 though. They're still working on some features.
Jason: Yeah, but for the stuff that I've been prototyping recently in C++20, GCC right now is my go-to compiler. It has at the moment the most solid support for the features that I care about. I'm using concepts pretty extensively.
Rob: The first thing they mentioned is that concepts are complete based on what's in C++20.
Jason: It's all early stuff. They say it's complete and I haven't hit a problem, but I assume I'm going to at some point. Because it is still largely untested to be fair. I'm sure it's complete, but how complete? How stable is it? I would definitely take a pessimistic view on that. Just nothing personal to the GCC developers. If any compiler said: "Work complete on the C++20 feature right now", I'd be sure there are corner cases left. It's just how it goes.
Jason: Emery, are you also playing with C++20 features right now?
Emery: I haven't started mostly because of compatibility fears. I'm definitely one of those people who likes to move to a newer standard as soon as possible. But there are people who use software that I make, who are not so quick. So, that's always a challenge. For reasons that are related to performance, I'm really excited about stuff like constinit.
So, we do a lot of stuff where we interpose on libraries. We have some static initialization that happens. The initialization definitely happens at the beginning. It's guaranteed but we have to tell the compiler that it's not a constexpr being initialized to, but it's constinit from here on out!
All of that stuff has the potential to make a pretty big difference in performance for some cases like replacing the memory manager, replacing some thread libraries, and things like that. I'm always looking for the things that will enhance performance.
Rob: Next thing we have is the ISO mailing list for September 2020.

Jason: I flipped through papers. Maybe it's a controversial statement, but I think the most important paper for C++23 is Pattern Matching. I do hope some version of it makes it into C++23.
Honestly, since I played with Rust and saw some of the power of what a good pattern matching syntax can do, and I've been doing versions of that using visitors in C++. So, I need this to go to the next step. It can clean up so many things.
Emery: I've not been following C++23 development. It's crazy to see something like this. When I was an undergrad in England, at one of the homes of functional programming, one of the languages that we learned was a predecessor to Haskell. It's just crazy to look at the code that comes out of the pattern matching stuff with. But a lot of it makes it look like this very nice and clean ML style, Haskell style way of doing pattern matching. It just avoids a lot of boilerplates. When you look at the code, you know what this code does. That's super cool. I'm going to send this paper around to some of my colleagues to show that this C++ no longer looks like C++ at all.
Jason: I read through the paper looking for more like implementation details. Because if it were an enhancement to lambdas, they would say it's as if the compiler did this, for example, and show you how it could be translated into C++20. But there's nothing like that in the pattern matching paper. I'm pretty sure it's going to be very much compiler "magic" compared to most features that get added these days. Not just syntactic sugar.
Emery: These things are kind of syntactic sugar in a way but in a very deep way. A compiler has to do a lot of work and there's no straightforward translation of these things. But this is incredibly mature language technology.
There's this term for pattern matching. It's called Hindley-Milner type inference. You can actually do this kind of destructuring without even adding types and it'll infer the right tags for you. This is something that functional programmers have had literally since the eighties. Seeing this enter C++ this way is great. I can see why it will be controversial though, cause it's definitely a shocking change in the look of everything.
Jason: I went to a C++ conference five or six years ago; I was watching talks on people who want a multi-method dispatch kind of libraries. That's painful to do in C++, you can do it with some tricks today.
Emery: I'll be interested to see what's going to be the interaction of these things. It looks really clean on paper right now. But I would be personally terrified of trying to implement this and making sure everything is good. So, we'll see what happens.
Jason: I've been using a std::visit and std::variant to do similar kind of pattern matching things. For those who don't know, you can take visit, pass in the visitor and then pass in multiple variants. So, if you've got four variants that you pass in, it's going to generate all the possible interactions of all of these to try to generate all of the calls to the visitors. That can be very painful at compile time, but it does seem to actually generate efficient code.
Emery: It's clearly a concern. Years ago, Rob Pike gave this keynote talking about Go when the language was just brand new. One of the primary motivations was compile time concerns that they had with C++.

Emery: I was wondering: "Are we building a whole new language because of compile times?" It seems insane, but it's Google, they can do things like this. And they're recompiling stuff all the time, so, it makes sense. And if you put something in, that is going to lead to explosion in compile time, it's definitely a risk. So, we'll see what happens. But you can already do it today. You can write your template meta-programs, that compute the Ackermann function or something, if you feel like it. So, there's nothing stopping you from shooting yourself in the foot in the finest of C++ traditions.
Jason: You know, you're doing something right if you have to up the template recursion limit on your compiler parameters.
Emery: I have to confess; I have that in a couple of my projects. Dirty little secret. Don't look too closely at the command line, everybody, please.
Rob: Emery gave a great talk at CppCon in 2020, where he talked about performance. You should definitely go and watch that talk on YouTube. Let's start off by talking a little bit about performance and some of the things that can affect it in C++.
Emery: People use C++ primarily because it can give you really great performance. There's no garbage collection, which I should stress. That is mostly a space trade-off. So, you can run your C++ programs in way smaller of memory footprints.
Jason: Because of garbage collection?
Emery: Yeah. I'll explain it briefly. We have a whole paper on this. It's quite old, but the lesson still holds. So, most garbage collectors trigger collection once the heap fills up to a certain amount. And you have some heap size parameter. If you set the heap super tight, you could be in a situation where you've got a bunch of memory in use, and then you allocate something and then you free it. It goes away. You're not using it anymore, but you're bumped up against the edge of the heap limit. It triggers a full garbage collection and reclaims one object. Then you could call new again and then, rinse and repeat. And so, you can be in a situation where the runtime just goes through the roof because the heap is too small.
As the heap gets smaller and smaller, you get almost an exponential curve that just goes up and up and up. It's actually power law, but anyway. Then as the heap gets bigger and bigger, the runtime that you spend collecting decreases because you allocate, allocate, a bunch of stuff dies, a bunch of stuff dies, a bunch of stuff dies. But at some point, you get to a steady state where you're pretty close to barely collecting at all.
This is especially true for a generational garbage collector that is periodically reclaiming very short-lived object. But it holds for any garbage collector. The problem is that the amount of space that you need to get basically the same runtime as C or C++ running malloc and free or new and delete, is like three to five times as much memory.

People think that garbage collection is great and super convenient, but it comes at a great space cost. If you have plenty of RAM – terrific, but if you would need that RAM or you're making really a lot of use of the RAM like it's a cash or it's an in-memory database or key-value store, you end up throwing away a lot of capacity by using a garbage-collected language.
Jason: Is this Quantifying the performance of garbage collection?
Emery: That's the paper. Exactly.
Jason: I know there's at least a few listeners who will be very curious in that.
Emery: Actually, Chris Lattner, who is the creator of LLVM and the co-designer of the Swift language, specifically cited that paper as a justification for why Swift doesn't use ordinary garbage collection and uses this reference counting.
Anyway, be that as it may, if you get rid of your garbage collection, what are you left with? You're left with the metal; you're left with whatever machine you're running on. The problem is these machines have gotten enormously complex. Processors used to be really simple.
When I started out, I actually had Apple II Plus. It had a 6502 microprocessor and in the 6502 were the instructions in the reference manual, literally said, how many cycles it takes for every instruction. Which now is hilarious. There were no caches. There was no virtual memory, there was no TLB, there's no pipeline. There was no dependency on the past.
There are all kinds of complexity in modern hardware and this complexity, unfortunately, surfaces in ways, that can be very surprising. For example, branch predictor. Branch predictors essentially recorded history of which way your if was taken, did you go the if way or the else way. So, it can prefetch the instructions and start loading them and executing them speculatively. If it guesses correctly, most of the time, it saves a lot of time. It's not just stuck waiting to evaluate the if expression. It just goes forwards and keeps running. So, you have all of this parallelism that's happening. It has to be pretty accurate and when it is that's terrific. The way that it actually manages all these history tables is by hashing the program counter, which is just the instruction pointer, the address.
This means that if you have a bunch of things that map to the same address, they can actually overflow the buffers and then you get misses. The predictor doesn't work as well. This is referred to as aliasing for branch predictors, but it's the same problem for caches, for the instruction level caches, for data caches, for the TLB because the TLB maps your pages of virtual memory, it's a physical memory.
Rob: Can you explain what TLB means?
Emery: Sure. So, it's a stupid name, unfortunately, it's almost better to not know what it means. It stands for translation lookaside buffer. Basically, you can think of it as just being a map that maps the start address of a page, that's in virtual memory, to the start address of the page, that's actually the physical memory in your machine. Your machine has a bunch of RAM, and it goes, and it puts pages wherever.
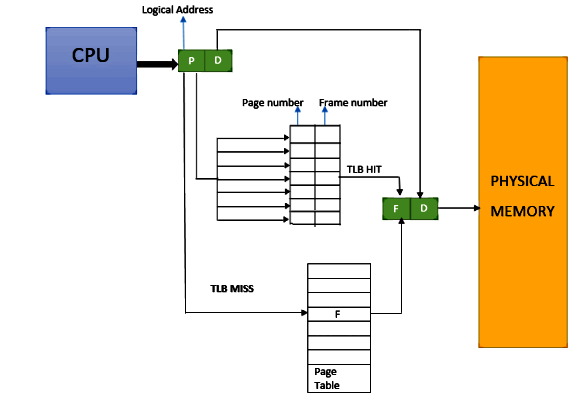
Figure 2. General working of TLB.
So, you have to have this map. This map is stored in memory in its full glory, but there's a cache to that map. The cash to that map is the TLB, that's all it is. It really should be called a virtual page cache or something, but it's not. So, if you have an application that actually spans more pages than fits in that cache, then it will go out to a data structure that's in RAM. This happens every single time you access any data at all or any instructions at all. If you're in a situation where it's in cache, then it's free. It returns typically in a cycle. It's essentially invisible. If it goes to RAM, it could miss L3 cache. It could go all the way out to RAM, and it could take hundreds of cycles.
This stuff is really nasty. I think it's poorly understood just how brittle performance can be. You can change a line of code, you can add another new, you can restructure things, you can change your makefile. This can lead to gigantic performance swings.
Rob: That kind of brings us to some of the toolings you went over in your talk. You talked about how performance is so brittle, and you introduced these tools that can be used to analyze performance in such a way to get around that brittleness. Can you tell us a little bit about those?
Emery: Yeah, sure. So, I have to say upfront that LLVM itself is a moving target. We were trying to make LLVM do things it's not meant to do. We changed LLVM to an extent where require months of work, for somebody to go and port it forwards. Unfortunately, it suffered from bit rot. We've talked about reviving it, but it just seems like such a thankless task. If somebody wants to actually do this, that'd be great, but we're not going to do it.
So, let me just explain what it does. If things in memory shift around, your performance can go one way or the other, and you can think that you have an awesome performance increase, cause you're a genius. Or you change something, and your performance may fell apart. It's just depending on where things ended up getting laid out in memory. This can even be affected by what directory you're in, what the day of the week is. I didn't mention it in a talk, but once I had a program that ran faster on Wednesdays then on Tuesdays.
Jason: And you were able to quantify this?
Emery: I actually changed the clock and went back to Tuesday and that was the problem. It was the length of the day, that somebody was storing in an environment variable.
Rob: Like the length of the string?
Emery: Literally Wednesday, it's longer than Tuesday. So, the moral of the story is obviously only program on Wednesdays.
Emery: What we did is we built the system that we jokingly called Stabilizer because it actually just messes everything up. It randomly moves everything in memory, periodically, during the runtime of the program. And here's the reason why we do this. First, if you just do random at startup, that's not enough. The effects will still manifest. You ended up in one layout. So, what you want to do is the moral equivalent of a randomized controlled trial. You basically randomizing everything. We randomized where the globals are, where the functions are. We have a randomizing heap. When you allocate new objects, that's a little bit decorrelated with where the previous one had been freed. Then you can actually run the code a bunch of times, try it with your optimization or whatever your code changes. Try it with something else. And then you can compare, and whatever the change is, it has nothing to do with the layout.
Rob: So, you mentioned that this tool has suffered from some bit rot. Do you know if there's any other similar tools like out there that someone could try if they wanted to?
Emery: Yeah, that's a great question. So, Stabilizer is super extensive in what it does, and this is why it relied on LLVM. It literally changes where the stacks are laid out. That's right at the heart of the compiler, generating stacks.
That said, we have a few randomizing allocators that we've built for various purposes, and any of these undermines the effect of layout in the heap. It doesn't affect the stack, it doesn't affect the globals, it doesn't affect functions. But it changes where objects will be laid out the heap. That particular kind of confounding factor goes away.
We have one called DieHard. It is actually for reliability. If you have a program with memory errors, DieHard makes it probabilistically that your program will run correctly. But as a side effect, it's also randomizing the location of things.
I know you're puzzled now, so let me explain how it helps really quickly. So, the way that it helps with use-after-free errors or dangling pointer errors. So conventional allocator, when you free something, is immediately available for reclamation, and then when you call new, it's almost certain to be the next object.
So, you call delete and you call new, you probably get that same object right back. The worst possible situation is if it gets immediately clobbered. This is the problem that garbage collection solves. Garbage collection makes sure nobody has a pointer into anything before anything gets reclaimed.
So, DieHard actually has a bitmap-based allocator, and it randomly chooses among all of the freed objects for the next object to be used. So, when you call delete, it just sets a bit, and the bit is set to zero. Zero means it's free. And it randomly pokes into this bitmap. And if it finds a zero, it returns that object. Suppose you have a million objects on the heap. A million objects have been freed. When you call new, you have a one in a million chance of clobbering the object you just freed.
So that's one thing that DieHard does. The other thing, which is maybe even easier to understand, is that the heap that it allocates is somewhat larger than required. And then it randomly places the objects in memory. So, there is a likelihood that if you have an overflow it will overflow into nothing.
Jason: I understand what you're saying, and I understand why it makes the program more stable, but to some extent, I wish that it made the program less stable so I could use it to find random kinds of errors.
Emery: Totally, this is actually part of work that we did. Some of this found its way into Windows. So as Rob mentioned, I've spent actually a lot of time at Microsoft. Microsoft had this genius thing that they did, which was an adaptation of this idea that they called The Fault Tolerant Heap. If a program had been crashing more than a certain amount of time, over a certain period, they would swap out the heap with a heap kind of like DieHard.
Then we built other stuff that follows on that actually designed to automatically find the bugs and fix them. We had a follow-on paper called Exterminator, which builds on DieHard.

And then we have another paper called DieHarder. DieHarder is a secure allocator. So, DieHarder actually is the opposite, it makes it very unlikely that you'll have any information that you can leverage for an attack.
It randomly allocates things, but everything is a chunk that's separated in virtual address space. It's super far away from the next chunk and it's randomly located. If you do a buffer overflow, it's very likely you'll segfault.
If you have a program and you run a program a bunch of times, and you'd normally look at the heap. Suppose it was deterministic, the heap is the same. Suppose you hit the exact same error five times in a row. If you look at the heap, the heap state is identical. It gives you no information. You could run it five times, a thousand times. You're getting the same heap over and over and over again. But by using the randomization, all the heaps are different. You can actually identify when the thing fails. Then we could use that information to basically create these things so that when you run the program again, they would patch the allocator. We indicate the number of bytes needed to allocate something at this line of code. You can use that information to send it home to the developer and also keep the program running. Win-win!
Jason: You said you've spent a lot of time in Microsoft Research. I don't know if you can speak to this at all, but I'm thinking, is this how we still get some of these old, like win32 windows 3.1 applications that can still run on Windows 10?
Emery: I wish I could say yes, but the answer is no. They've done a lot of engineering obviously to keep these things alive.
One of the things that is pretty funny when I first went to Microsoft, when I was a PhD student, I was like: "Hey, I have this super-fast allocator. Your allocator is garbage. I'm going to replace the Windows allocator. I'll speed up all Microsoft products!" Then I had access to Microsoft code. I could recompile things. I went to recompile some code and some SQL server, and everything crashed. Every single thing crashed as soon as I replaced the memory allocator. I thought I had a bug in my memory allocator. But the problem was that everybody who had written this code had debugged their code with Microsoft allocator. And as soon as I replaced it with another allocator that didn't have those exact same sizes, everything fell apart.
It was a good lesson to learn. Legacy software is hard, and maintaining things forever is hard.
Jason: Well, just for reviewing, you've touched on the day of the week that can change how fast the program runs, and then we talked about Stabilizer. Then you said about products that you have and their effect on the heap. And so, I was curious how much the StackLayout in memory is important versus the heap layout in memory for stable execution timing runs in these kinds of things.
Emery: That's a good question, I'm not sure I can give you a solid answer. I mean, the stack is always allocated by the compiler. It's a contiguous chunk. So, you've got all your local variables, they all appear in the stack frame and they're all together. This means that they're all going to be in cash almost certainly. That's something that takes away certain performance question. The cash is almost always hot. Because you're accessing the cash, you're executing functions. You're just visiting the same memory over and over and over again. The memory is always hot. That means that the stack has less performance impact, in general than the heap, because the heap has many objects and they're spread around.
It's all dependent. If I allocate one more object here or a different-sized object, it can change the whole layout of everything. So, it's a lot more brittle than the stack. That said we found significant impact just for moving it around. In fact, the stack is exactly what gets moved by the environment variable shift.
So that part is fixable by the way. In GCC, or at least in LD, you can tell it, you can give it a linker script. This is super obscure, but you can give it a linker script and you can align the segments where things get mapped to page boundaries. And then this brittleness goes away.
Rob: You mentioned that Stabilizer can't really be used today, but if you want to go back to an earlier version of LLVM, could you build and run a program with stabilizer, and is that still worth doing, if you want to do some profiling?
Emery: You could do it. I'm not sure if it's good or not. LLVM has moved on. Maybe the Codegen is a lot better. I don't think it's a gigantic difference, but it's going to be some difference. There's going to have been bug fixes and so on.
There's the specific version of LLVM. If you go to the GitHub site, here's all the information you need, but honestly, I think that using some sort of randomizing heap is probably the easiest thing for somebody to do just to try to iron out these things. But at the end of the day the performance may change a lot. And so, I need to be really careful when I get a regression.
One of my former students at UMass worked on the V8 project at Google, the JIT compiler for JavaScript. He was saying that they would actually roll back things that caused a performance regression on their benchmarks of 1%. I found that ridiculous. 1% is like thinking that if you jump up and down in the same room, where your program is running, maybe it'll warm up the temperature by one degree. And then it'll throttle down the CPU. You can't possibly be making software engineering decisions on the back of a 1% change. That's just freaking noise.
Rob: Can you tell us a little bit about Coz?
Emery: Sure. So, basically, what we discovered when we were doing some performance analysis and research into things is that the existing profilers that were out there really didn't help. The reason that they didn't help was they were kind of designed for the applications of the eighties or earlier. So, if you have a sequential program, that you just care about how long it takes from the start to the end, then these profilers are fine. They're not great, but they're fine. They tell you where's the line, how much time is spent on the line of code, how often that line of code is executed, and that can help point you to a place to optimize your code. So, this is how, classically prof worked from Unix and then Gprof, which is included with GNU. They've been improved for concurrent programs.
There's some stuff on finding critical paths. There might be a critical path, which just means the longest sequence of code. In principle, you should always optimize the critical path because if you have a concurrent program, the critical path is what's slowing everything down.
If everything is finishing super-fast and there's the one thing that takes a long time, that's the blocker, that's the bottleneck. The problem is in a real program. If you focus all your efforts on one critical path, it's like a whack-a-mole. That critical path goes away and then another thing becomes a critical path. It's not like you suddenly got the critical path and now your program runs 10 times faster. It could be much worse. Imagine if you went and spent weeks working on critical path one, and then you're done and you optimize it, and then critical path two will mean that you actually had no impact at all.
We also care about other things these days. You have programs that run forever, and you care about things like latency and throughput, not the program's total execution time. That's not what profilers tend to do. We were looking for some way where we could have a profiler telling us what would happen if you optimize this line of code, what would the impact beyond latency, or what would the impact beyond throughput.
What we wanted ideally was like a graph where on the x-axis is how much I optimize this line of code from zero to a hundred percent. And then on the y-axis is how much does the overall program speed up or how much does latency decrease or how much is throughput increase.
And so, if you have a flat line, you would never optimize that line of code at all. A flat line says, no matter how much I speed up this line of code, the program is unaffected. It doesn't affect performance.
But if you had one where you optimize that line of code by 10% and your program speeds up by a large factor, you would definitely work on that line of code. So, what we were looking for was this thing, we call a causal profile. It tells you if you do this, it will have this effect for sure. Coz gets these graphs through a kind of trickery. You can't really know just by looking at a line of code, how much performance would increase.
Coz basically takes advantage of this kind of place insight. You can get the effect of speeding something up by slowing everything else down. So, if I've got some line of code, I can look around and see all the other threads that are running and tell them to wait for a certain amount of time. I literally just like signaled them. They pause for some amount of time. I do this with sampling, I don't actually run the thing forever. I just hit it for a little bit, slow everything down with a kind of a pulse, and then I can observe the effect out the other side.
That's what Coz does, it randomly injects these delays, which it does with sampling. It doesn't have much effect on overall runtime. You can run Coz in production, and yet it produces these profilers that you can send on a socket if you want. You can look at the performance profilers and see the lines of code that I really should be working on.
Jason: So, is it just for multithreaded applications?
Emery: Good question. You can run it for a single threaded application. I'm super biased, but I actually use it even for sequential code. It's just convenient to get this result, where you get these causal graphs.
It really shines though, when you have concurrency, when you have an asynchrony, so it doesn't have to have multiple threads using async IO. You could have an event-driven server that conceptually has no threads. Concurrency is in there and Coz will work better on that. And then anytime you care about latency or throughput, a conventional profiler has nothing to say about those things. With Coz you can actually say here's the start of something and here's the end. Imagine it like a sequential server that just took in an input, did something with it, and produced a result. You could just say here's the begin points, we call them progress points. This is progress' beginning. This is progress' end. And Coz will try to find the lines of code that will reduce the latency.
Figure 3. Charlie Curtsinger speaks about Coz: finding code that counts with causal profiling. Click here to watch the full talk.
Jason: Do we actually have to put like markers in our code to tell Coz that this is what we care about?
Emery: You have to do that. There's literally just three macros. One is COZ_PROGRESS, which is for throughput. The others are COZ_BEGIN and COZ_END, which are for latency.
Jason: And then we run it, and it produces a magic graph that says how to speed up the line, so it'll be faster?
Emery: Exactly. Actually, it was funny. We built it, added some theorems and the paper. We had mathematical proofs in effect that this is going to work. We demonstrated it with some simple programs. Then, I told my student, who's now a professor at Grinnell College, Charlie Curtsinger to take this benchmark suite of concurrent multi-threaded programs that Intel put together with Princeton, spent no more than an hour on each program and see how much it can be optimized with Coz. These are programs he'd never even looked at. So, we had no idea at all of what was going on inside. He ran the programs, looked at the code, very quickly found places where you could insert these progress points and came out the other side with optimizations in ranging from 10% to 70%.
Rob: Coz doesn't rely on any LLVM internals or anything like that?
Emery: Yeah. It's pretty stable. I mean, you can go and install it with APT or Snap or what have you. It relies on this package that Austin Clements puts together. He's the head of Go development at Google. It's called libelfin. It manages reading stuff out of ELF format, which is something that it relies on and that's it.
Emery: I should also add, that even though this is C++, we're among friends, we can talk about other languages. It works for C of course; it works for Rust as well. Somebody made a version of it for Java. So, there's a version called JCoz, that works for Java programs and in principle, it could work for anything that generates debugging output. It's possible to do for JavaScript, but we just haven't done it.
Rob: Very cool. Well, Emery, is there anything else you want to share with us before we let you go?
Emery: Geez. I've shared so much. The only thing I would say is, obviously, we welcome feedback about these things. For those out there, who go and use Coz, please, if you discover some issue, let us know on GitHub. If you optimize something and you have a great experience with Coz.
Thanks so much for listening in as we chat about C++. We'd love to hear what you think of the podcast. Please let us know if we're discussing the stuff you're interested in, or if you have a suggestion for a topic, we'd love to hear about that too.
You can email all your thoughts to feedback@cppcast.com. We'd also appreciate it if you can like and follow CppCast on Twitter. You can also follow me at robwirving and Jason at lefticus on Twitter. We'd also like to thank all our patrons who help support the show through Patreon.
If you'd like to support us on Patreon, you can do so at patreon.com/CppCast. And, of course, you can find all that info in the show notes on the podcast website at cppcast.com. The music for this episode was provided by podcastthemes.com.
Podcast
News
Links
Sponsors
Guest
0
0
0
0