
Our website uses cookies to enhance your browsing experience.
Episode 276 of CppCast with guest Robert Leahy, recorded December 2nd, 2020.
We decided to introduce you, our readers, to foreign podcasts, where the most interesting topics about programming and IT are discussed. Therefore, our team is presenting a new format of articles – text transcripts of podcasts. We know that some people absorb information better in text format than by ear. Given the fact that hosts and guests are talking in English, there are additional difficulties in understanding the essence of the podcast. We hope that such content will take root and will be useful both for experienced programmers to discover something new and for beginners just starting their professional career in IT.

Today's podcast is about C++. We'll discuss the possibilities of using a new cross-platform C++ framework Plywood to create games in C++. You'll see the "terrible" C++20 initialization flowchart which is going to blow your mind. Also, we'll discuss the accuracy of using exceptions on modern 64-bit PC architectures, and the executor's implementation in the Networking TS standardization.
You'll find the link to the original podcast at the end of the article.
Note. The podcast text has been edited to correct speech errors. It reflects the meaning of the talk, rather than the literal representation of the speakers' statements.
So, let's start.

Joining us today is Robert Leahy, a graduate of the University of Victoria where he specialized in graphics, gaming, and digital geometry processing. After four and a half years in full-stack web development, he pivoted to financial technology in early 2017. He since has become involved in the ISO C++ committee and strives to deliver software, which is high quality and process driven while also meeting the rigorous performance standards for which finance is so well-known.
Note. Earlier, Jeff Preshing, the author of A Small Open Source Game In C++, posted another article How to Write Your Own C++ Game Engine, where he describes the process of creating one's own game in C++.
In A New Cross-Platform Open Source C++ Framework article the author notes that the Plywood framework is not a game engine but a framework for building all kinds of software using C++. Plywood's documentation is generated with the help of a C++ parser, formatted by a Markdown parser, and runs on a custom webserver all written using Plywood. Integrating third-party libraries into C++ can be a challenge, but Plywood aims to simplify it.
Rob Irving: Well, this first article we have is a small open source game in C++ on preshing.com. It's more advertising plywood, which is not a game engine but a C++ framework that the author builds the game with. The demo game is Flappy Hero or Flappy Bird clone, which kind of brought me back to the early 2010s when this was a real phenomenon for a little while.
Jason Turner: The guy who made Flappy Bird got so frustrated with all the attention, he dropped out of the world, and took the game off the App Store.
Rob Irving: He claims he did it just because he was upset that people were getting so obsessed with the game because he meant for it to just be something you play for a few minutes when you have some downtime, but people were being very, very obsessed with the game.
Robert Leahy: I remember that game as being like the Genesis of the mobile gaming phenomenon. Now I take the subway, and it seems every second person is playing some game on their phone, whereas before Flappy Bird or whatever they would be reading a book or just sitting there listening to the music or something like that.
Rob Irving: A very addictive, but easy game to play and just lose yourself.
Robert Leahy: I looked at the Plywood framework, and I think one of the things that was the most interesting is that it looks like you build the modules and declare them in C++ itself. You write a little function that takes in a parameter, and then you decoratively build your module. I've never even considered that as something that you could do with C++.
Rob Irving: Are these modules related at all to C++20 modules?
Robert Leahy: I have the webpage open and there's a little like information bullet here that says specifically Plywood modules should not be confused with C++20 modules.
Let's go on.
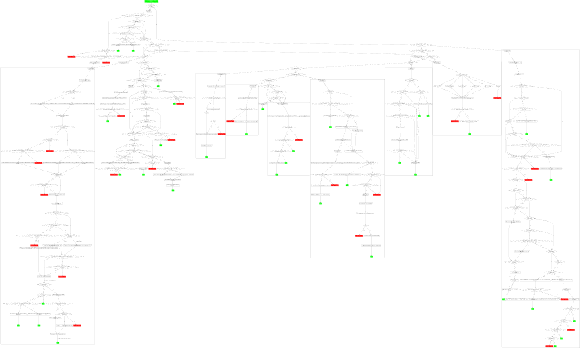
Rob Irving: Well next article we have is this post on the C++ subreddit. This is the C++20 initialization flow chart. A giant flow chart which is just kind of scary to look at and think that initialization is still this complex.
Jason Turner: Still? It's more complex of even a recent C++.
Rob Irving: It gets more complex. That's true.
Robert Leahy: Now one of the themes in the committee is that if anyone ever puts a paper out there that makes the language simpler in any way, people say this is amazing, how could you possibly think to do something like that? So, it seems like initialization. Just every single release or in every single meeting, another special case needs to be there. This thing doesn't quite work, let's add another couple of nodes with a couple more decision points to make this work. Do we think we should? The PNG is so big that whenever I switched back to the tab, it takes a few seconds to render it.
Jason Turner: I feel like some of these corner cases and stuff that ended up in the flow chart were perhaps apocryphal stories but discovered by compiler implementers when they're trying to write compilers and need another corner case.
Robert Leahy: It's interesting often that happens in software engineering in general, where you try and think of everything. And then you get to implementing, you realize this totally doesn't work. So, I can't decide whether it's heartening or disheartening that it happens with the committee too. You put the best minds in C++ in a room, and they still can't be a substitute for one guy trying to implement something in the compiler.
Jason Turner: I think it's funny though, the author of this says it honestly took a lot less time than I was expecting. When I read that before I clicked on it, I was expecting a relatively small flow chart. And then when I realized that you have to zoom in on it and scroll around as here unless you've got a 48-inch monitor or something.
Robert Leahy: I have a 49-inch monitor, and it still doesn't really fit. It fits, but you can't read it. You still have to zoom in.
Jason Turner: You need to upgrade to an 8K 49-inch monitor, and then you would be able to read it.
Robert Leahy: You have to lean in really close to the monitor.
Rob Irving: Next thing we have is this blog post on lordsoftech.com. And this is Error Codes are far Slower than Exceptions. They're basically saying that with modern 64-bit architectures, performance concerns should not be a reason to avoid exceptions. They did a couple of benchmarks, tests with an XML parser, one implemented with error codes, one implemented with exceptions, and found that the error code, using the implementation was about 6% slower than the exceptions.
Note. Click here to find the complete source code.
Jason Turner: I agree, but in nested cases particularly that error codes are going to be slower than exceptions, and if exceptions are truly exceptional because I've done my own study on that and I don't fully agree with the examples here because the author switched from an API that returns a value to an API that takes the value by reference. And if he had instead done something expected where it was, the value plus the error code as the return value, then I think we would have gotten slightly different numbers.
Rob Irving: That could be a third implementation to try out, do error codes, exceptions, and then expected.
Robert Leahy: I think that expected proposal is pretty much in like standards committee purgatory, but according to Neil Douglas' outcome, you can download and use Boost.Outcome. But I'm pretty sure when he was going through a Boost peer review, he ended up removing the monadic interfaces, but only halfway, two thirds the way down in the article, there's this example of how the code gets simpler when you use exceptions? And the fallback, is this PROPAGATE_ERROR macro?
I remember working with a version of expected that had the monadic interface then. That was really slick way to work with error codes. There was no boilerplate, I think they were calling it bind at the time. And then you got out the final value or any of the errors along the way. With this implementation though, like with the XML parser throwing exceptions on badly formed XML, that gets into a question that I've heard raised several times in the Networking Study Group. What do you mean by an error? Like whose error? Rarely gets into file an error? Is that XML exceptional? Are you reading random files and trying to figure out if they have XML in them or are you getting input that you think is XML? And what kind of error is exceptional?
Because the answer to that question isn't clear, you have to establish a taxonomy of errors and then that itself becomes complicated. It's like bad_alloc, but then you have people who truly believe that bad_alloc should never happen. And if it does, you're on Linux, and it's going to kill you anyway, and if it doesn't, you can't recover, you should just abort.
Robert Leahy: So, it's interesting to think about the fact that unless you know the domain you're in, you can't ever make the conclusion that something is truly exceptional because someone could be trying to use your XML library just to figure out is this random string XML, in which case it's not XML isn't exceptional, that's half their use case.
Jason Turner: Interesting point. Whenever students ask me about error codes versus exceptions or whatever, I'll say the key is that you're consistent in your code base. I hate it when I go to a code base and I have no idea what to expect. Is true an error, is false an error, are you using exceptions? Whatever. Just be consistent.
Robert Leahy: I think that typically on POSIX I remember correctly, you get back false values (zero values) on success and then in windows it's the opposite. And so, if you end up doing any cross-platform operating system programming, you can almost guarantee you're going to get the check wrong, at least once in your code base somewhere.

Note. Beman Dawes was one of the most influential people in C++ history. The C++ committee and communities owe Beman a lot. He was a member of the C++ standards committee (WG21) since 1992 and chair of the Library Working Group for five years during the completion of the first C++ standard, C++98. Beman Dawes was the original developer of <filesystem> from the standard.
Rob Irving: Beman Dawes has passed away recently. This was the author of Boost and File System. He was on the ISO committee and brought a lot of good things to the C++ language. Condolences to his family. I think we did try to reach out to him and get him on the show about two years ago, it's unfortunate we weren't able to get him on.
Robert Leahy: It's always sad to get that kind of news. Someone told me about it like 30 minutes for the show, you never want to hear something like that.
Rob Irving: Well, Robert, tell us a bit about the Networking TS. What's it looking like for C++23?
Robert Leahy: In the committee we still want to ship executors and Networking in C++23, clearly the whole COVID thing has thrown a wrench into the best laid plans. Right now, Study Group 4 has a lot of long-running tasks and investigations. Some people are doing to try and get a head start on the integration with executors, because if you look at the way that the TS is currently written, and then you look at the way that Asio is right now which is kind of the reference implementation.
Asio is incorporated what we think, or hope executors is going to look like whereas the TS is quite old at this point. There's a lot of work and investigation that has to go into to meshing them together. The calls that have been happening because as G4 has had work to do have been focused around that. So there still is some modicum of progress being made on Networking, but the work is quite slow because until executors set in stone, all the work is kind of tentative.

We think it's probably going to look this way, but there could be some last minute, like a live grenade thrown into a room where everyone changes everything and then all your work goes out the door, which is something that's been brought up in most of the executors discussions.
Rob Irving: So how exactly do executors and the Networking proposal relate?
Robert Leahy: I think that depends on the level at which you're writing the Networking code. If you're talking about bootstrapping your Networking code from nothing, the executor is basically a way for you to get that background context to execute work. One of the most fundamental problems with anything asynchronous is that when you're writing synchronous code, you have a context of execution. It's the fact that you descended from main or the fact that you descended from the start of some thread. So, you have the CPU, and you're executing, and you can go into a function and stay in there and then come back, and you still have somewhere that your code can execute.
When you're trying to execute asynchronous code, there's all this stuff going on in the background and that raises this question of where does that context to run the code come from? The analog between the executor and allocator kind of falls apart of it.
When you put some work to be done asynchronously, the executor determines how and where, and when that work is going to run in the background. If I try and read from a socket, on an asynchronous socket that work completes. And then where the next piece, the completion handler runs is determined by the executor.
So, if you're implementing something from the ground up, you need to be very aware of that. Otherwise, when you get to the higher levels of writing asynchronous code, the executor is something you kind of choose at the beginning.
In the code that I write professionally, what typically happens is that you just inherit the executor that some socket or something is using that you're given. I guess I'm using its executor now. And you don't think about that. And then at, in main, you think about that, cause you need four different threads. So, I need these four different contexts that have their executors, then you pass them around and that determines where the work runs and what kind of threading and synchronization guarantees you want to give. So, an executor is not just a place to run work, but also a policy about how that work can run.
Jason Turner: Does this have any relation at all to the execution policy that parallel algorithms take?
Robert Leahy: I'm not a hundred percent sure of the answer to that, but I think there may be some relation, but executors are obviously much more flexible, you can just write one from nothing.
Jason Turner: What is the interface to an executor look like since you just said we can write one from scratch?
Robert Leahy: So, the simple interface to an executor is literally one customization point object which is called execute, and you pass it an executor and something that can be invoked with no arguments. It invokes the thing with no arguments inside of the execution context that executors are handle too.
Rob Irving: So, you're talking about a Boost.Asio earlier, could you maybe tell us a little bit more about what it's going to look like when we have the Networking TS in practice?
Robert Leahy: The thing with the Networking facilities that we're trying to standardize and that are in Asio right now is they're very basic, low level. Kind of functionality. In C++ we want to make sure that you have the capability to build whatever you want on top of that. Because a lot of people want to have TLS by default, which is an interesting argument that makes sense at a lot of levels of analysis. Like if you're writing a phone app. It makes sense that it should kind of be impossible to make an unencrypted connection because if you make it possible, you can make the argument that most people are not going to end up doing. It's going to complicate things, and it's going to be insecure by default, and you don't want that. But at the same time, that's not really a low-level building block, which is what the TS and Asio set out to do.
Jason Turner: So, you mentioned the discussion about whether you would by default get a TLS socket. Does that mean the Networking TS support encryption?
Robert Leahy: The proposal itself doesn't have any facilities for encryption, but Asio does, which is another thing that has been discussed a bit in the Networking subgroup. Which encryption are we standardizing? If the implementation defined, how is it useful? Personally, I think that standardizing some form of encryption would be nice, but we want to ship the Networking TS in 23.
Whereas in Asio, for example, the TLS support is just a couple classes. It doesn't require any fundamental changes, but there are some operating systems that just aren't happy with that. I believe that some of the mobile operating systems can't really create raw TCP connections unless you have a certain level of permissions that most applications don't. I think that iOS has like that, although I could be totally wrong about that one.
Jason Turner: So, will you basically get TCP, UDP, IPV for IPV6?
Robert Leahy: Yup. And I'm not sure if the raw sockets are actually in the TS, there're raw sockets in Asio, but you basically get kind of an asynchronous analog of Berkeley sockets, like this thing in POSIX. I don't know if this is in the TS, but I'm pretty sure there's ICMP in Asio.
I think the most important thing that we're going to get from the TS in conjunction with the executors, is this model for making asynchronous I/O look and behave a certain way so that we can build all these libraries that just take a template parameter that's like an async stream or something like that. And they all work together, regardless of whether you choose to use like IOU ring or completion ports (IOCP), a file, or a socket.
You do get the kind of the canned stuff you need to do the most basic socket stuff, but I'm not quite sure the extent of the things that you get but you definitely get IP TCP, UDP and then you get both families, V4 and V6.
Jason Turner: So, you said the main thing now that you're waiting on is executors and for the most part, the actual Networking proposal has been stable.
Robert Leahy: It's been stable and the papers that we kind of have pending and were talking about seem stable. I think the last time we made progress in trying to update some older idioms to bring the TS into alignment with the executors TS. And it was using some older patterns that were kind of C++11-isms.
Jason Turner: It would seem to me that coroutines and executors and the Networking proposal, all have things in common. And I was just wondering, if the Networking proposal needs to be or had been updated recently to be able to take advantage of coroutines?
Robert Leahy: Well, I think we voted this paper in Belfast that would have been over a year ago now. We really liked this idea because the TS's framework includes this mechanism called completion tokens. So, when you pass the final argument, when you're beginning an operation, the final argument isn't a completion handler. It's not necessarily a function that gets invoked. It's a token, which means that it's a way of finding out what function should be used to indicate completion in there. The difference there is that you can fully customize the completion reporting mechanism. So, you can magically take any operation in the Networking TS or that's written in the style of the Networking TS, and you can pass it a token called Use Future. And suddenly, instead of calling a function, the operation returns a future and uses the promise internally totally seamlessly.
So, to your question, I'd say "yes" with a big "but". And the reason is as soon as you called what we call the initiating function, which is the function that gets it started, the operation was pretty much already going, like it returned to you. And often the background somewhere in this operation was already trying to make forward progress. And the problem with that is that when you were trying to transform your initiating function into something that used coroutines, the fact that it was off, running in the background potentially and could complete meant there was a race condition between the first suspension of a coroutine and the possible resumption. And so basically when you try to make any of these operations into something that used coroutines, you had to introduce him mutex that kind of belies the whole point of C++ and zero cost abstractions.
Within the completion token machinery in customizing the initiating function just capture and operate like a function that encapsulates what the operation would do to start itself and a whole bunch of arguments. And it can just put those away somewhere and then wait and start the operation again later. So, you can seamlessly transform one of these into something that uses coroutines. It will just capture what's called the initiation, the thing the operation wants to do to get started. It captures all the arguments; it puts them somewhere, and then it waits for the first suspend of the coroutine. And then it starts the operation, so it doesn't have to walk.
Chris was trying to implement kind of coroutine support and was like, now I have to put a mutex everywhere and that's not very performant. A lot of the machinery that he implemented kind of to stand beside this, makes implementing the operations themselves a lot simpler. There's like one helper function you call. You don't have to worry about how you actually go about deducing the final completion handler and all the stuff you had to do before you used to call this. One function, and you pass it to your initiation Lambda. It just takes care of all of it for you and magically, you get to write an operation that supports coroutines, promises, futures, and like anything anyone can dream up and implement. Chris calls it the universal model for asynchronous operations. If you google a universal model for asynchronous operations, the first hit that comes up is a paper by Chris laying out an early version of completion tokens. But the principles still the same.
Jason Turner: Are you using custom allocation strategies or PMR in the C++ standard?
Robert Leahy: So, we are not because maybe it's just the finance background in me talking. I just try and not allocate at a steady state. And that's what this double buffering strategy basically allows. If you're only caring about throughput, then the fact that this piece of data became available to microseconds earlier doesn't matter.
What I care about is that at some point in handling a very large high throughput connection, I stop allocating. We're trying to build a buffer then to send over TCP. When that buffer gets to be over 10 kilobytes, you need to send it, swap the buffers, and then fill the next one. And so, what ends up happening is, let's say these are the memory buffer from the format library, is that it's filling cause it's doing JSON. And so those are kind of vector-like. So, they'll start out being very small. And then as you put JSON in them, they're going to allocate and resize and resize and resize. But at some point, you're going to perform the largest allocation you ever need. And then after that, that's never going to fill up anymore and your connection can pump out, literally tens or hundreds of gigabytes of data. And it just doesn't allocate anymore because it's putting the JSON directly into this buffer using the format library, the buffer's reached the largest size it's ever going to reach. So, there's no need to allocate it all anymore. And then it just fills that buffer. So, while it's waiting on the operating system to send, still swapping them back and forth.
My company is processing live market data. We use all sorts of allocation strategies. Cause that's where every microsecond of incremental latency matter.
Rob Irving: Okay, cool. Thanks.
Jason Turner: I do have one other question. I've observed that some of the larger standard library proposals, Boost.Regex, Filesystem, Ranges, the parallel algorithms have a lag in their actual implementation inside our standard libraries, like LIB C++, clang standard library implementation, doesn't have the parallel algorithms yet. Do you think with the Networking is approved, an executor is approved, we'll see the same kind of lag or not in our standard library implementations?
Robert Leahy: That's a good question. I would anticipate that the lag might be minimal. One of the things that could end up happening is basically using Asio as a reference implementation. Chris puts a lot of work into making sure that Asio's backwards forwards compatible works with the current understanding of the TS. And so, I think that we're going to be lucky. The implementation depends by the vendors. If someone wants to implement their own from scratch, then that's going to take a while. And the TS is also quite large and there's a lot of stuff to implement, the same with executors. So, I'm not sure what the answer to that is.
I know that C++ package management is weird. But if you want to use the Networking TS right now, just get used to typing Boost.Asio and use Asio, and you get even more than what the TS offers. You get a synchronous handling of unique signals which is really useful. But that's not even considered to be in the TS. But then you don't have to deal with downloading Boost if you don't want to cause a lot of people really don't like Boost, that's why Chris also releases Asio as a standalone. So, you just get Asio and that's it. We do use Boost heavily in some of our projects, but in this project, we haven't pulled it in. And so, we're using standalone Asio, and it works great.
So, I would advise people who aren't terrified of package management and dependencies to use Asio until the TS is mature. And I think that's a luxurious place to be in because we're not depending on some language feature.

This is the end of the podcast text. Thank you for your time, we hope you've learned something new that will be useful in the future.
In the Resources section, you can find all the necessary links to information from the text above, as well as links to the hosts of this episode. We hope you are excited to see more of such content.
Thank you for your attention, see you soon! :)
Podcast
News
Links
Hosts
Sponsors
The sponsor of this episode of CppCast is the PVS-Studio team. The team promotes regular usage of static code analysis and the PVS-Studio static analysis tool designed to detect errors in code of programs in C, C++, C#, and Java. The tools are paid B2B solution, but there are various options for its free licensing for developers of open projects, Microsoft MVPs, students, and others. The analyzer is actively developing, new diagnostics pure regularly, along with expanding integration opportunities. As an example, PVS-Studio has recently posted the article, covering the analysis of pull requests in Azure DevOps, using self-hosted agents. Write #cppcast in the message field on the download page and get one month license.
And JetBrains, the maker of smart ideas and tools IntelliJ, pyCharm, ReSharper. To help you become a C++ guru, they've got CLion and IntelliJ IDEA and ReSharper C++, a smart extension for Visual Studio. Exclusively for CppCast JetBrains is offering a 25% discount on yearly individual licenses on both of these C++ tools, which applies to new purchases and renewals. Use the coupon code JetBrainsForCppCast during checkout at JetBrains.com, you should take advantage of this deal!
0
0
0
0