
Our website uses cookies to enhance your browsing experience.

Initially, the article must have been titled "Comparison of diagnostic abilities of PVS-Studio (VivaMP) and Intel C/C++ Compiler ("Parallel Lint")". Absence of sufficient information about "Parallel Lint" restrained the author's abilities and the article turned out to be just a preliminary variant of the comparison. The full variant with correct comparison will be available in future. Pay attention that the article's content is relevant at the time of publishing. Further, diagnostic abilities of the both products can change.
VivaMP support had been canceled in the year 2014. If you have any questions, feel free to contact our support.
PVS-Studio (VivaMP) is a static analyzer of parallel C/C++ code where parallel programming technology OpenMP is used. The analyzer allows diagnosing various types of errors leading to incorrect or inefficient work of OpenMP programs. For example, the analyzer can detect some synchronization errors, exceptions leaving the boundaries of parallel regions etc. VivaMP is included into PVS-Studio program product and is an add-in module for Visual Studio 2005/2008 environment.
Intel C/C++ Compiler ("Parallel Lint") is a subsystem of static analysis of OpenMP code built into Intel C/C++ compiler beginning with version 11.1. To use Intel C/C++ "Parallel Lint" you need to create a special configuration of the project, but in other aspects, working with Intel C/C++ "Parallel Lint" does not differ too much from the usual way of working with Intel C/C++ compiler. The compiler integrates into Visual Studio 2005/2008 environment. To learn more about "Parallel Lint" subsystem see the webinar by Dmitriy Petunin "Static Analysis and Intel C/C++ Compiler ("Parallel Lint" overview)".
It was very interesting for me, as VivaMP analyzer developer, to compare its diagnostic abilities with those of "Parallel Lint" subsystem implemented in Intel C/C++. Having waited until Intel C/C++ 11.1 was available to download I found time to begin the research and set for comparison of the tools. Unfortunately, these research and comparison were unsuccessful and the title of the article reflects this. But I am sure that developers will find much interesting information here.
I decided to begin my research with trying Intel C/C++ on the demo example ParallelSample included into PVS-Studio and containing errors related to use of OpenMP. ParallelSample program contains 23 patterns of errors which are detected by VivaMP analyzer. Analysis of this project must confirm that the analyzers perform similar diagnosis and can be compared.
Download and installation of Intel C/C++ Compiler 11.1.038 trial version were done successfully and did not cause any troubles. I was surprised a bit at the size of the distribution kit which was nearly one GB. But this is understandable considering that I chose the fullest version to download including MKL, TBB, IA64 support etc. After installation I decided to build and launch ParallelSample program before the analysis.
But I had troubles with compilation of the ParallelSample demo-example. The compiler showed the error "Catastrophic error: unable to obtain mapped memory (see pch_diag.txt)" as shown in Figure 1.

Figure N1. A error generated by the compiler when trying to build ParallelSample application.
Also, I did not manage to find pch_diag.txt file and addressed Google. And nearly at once I found a branch in the Intel forum devoted to this problem. The compilation error is related to using precompiled pch-files. I did not bother to examine the point of the problem and find out how to carefully alter the settings so that the subsystem of precompiled header files remained in action. It did not matter for a small project like ParallelSample and I simply disabled the use of precompiled headers in the project (see Figure 2).
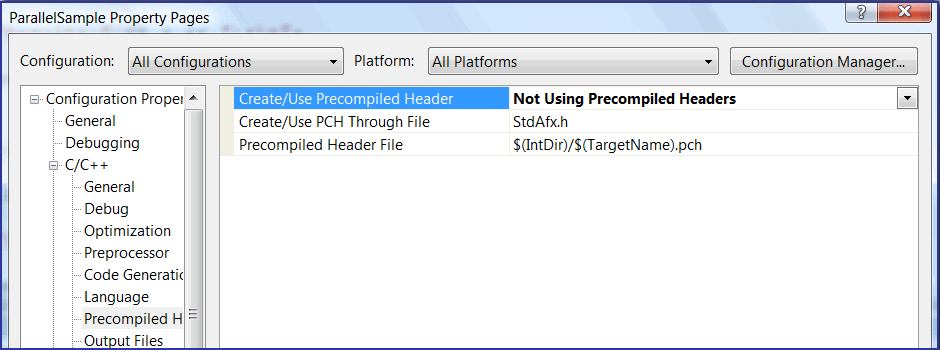
Figure 2. Disabling precompiled headers in the project's settings.
After that, the project was successfully built although I did not manage to launch it at once (see Figure 3).
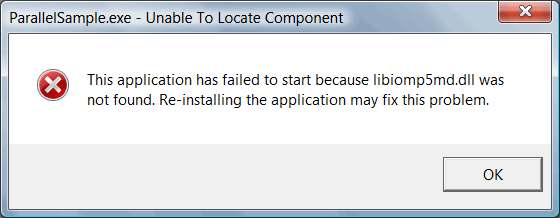
Figure 3. An error at the first launch of ParallelSample.
It happened because I had forgotten to write the paths to the necessary DLLs in the environment. To do this, you should use items "C++ Build Environment for applications running on IA-32" and "C++ Build Environment for applications running on Intel(R) 64", available through the Start menu as shown in Figure 4.
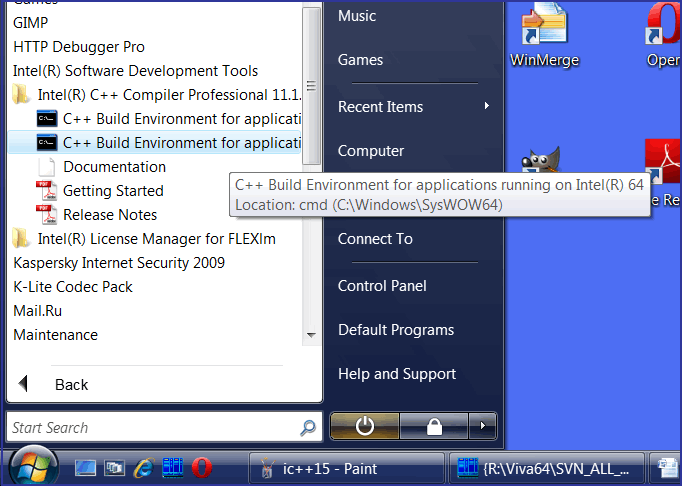
Figure 4. Setting of the environment to make applications built with Intel C++ work correctly.
Modification of the environment was the last step after which I could successfully compile, launch and work with ParallelSample application. Now we can set over to the most interesting thing - launch of "Parallel Lint".
The most convenient way to use Intel C++ "Parallel Lint" is to create a separate configuration of the project. The point is that you cannot get both an executable and diagnostic warnings from Intel C++ "Parallel Lint" simultaneously. You can get only either thing at a time. It is very inconvenient to constantly change the settings to build the EXE-file or to get diagnosis from "Parallel Lint". I should explain this behavior.
In the "classic" mode, the compiler creates object files with code which are then united with the help of the linker. As a result, the compilation process looks as shown in Figure 5.
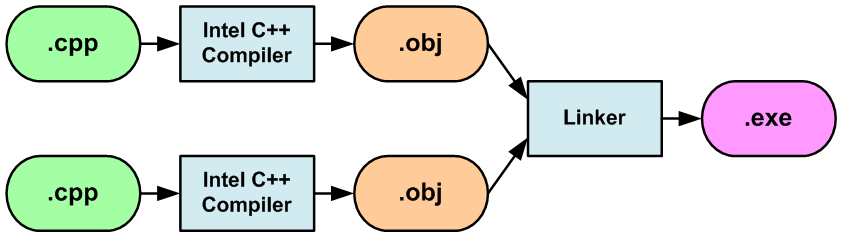
Figure 5. The standard working mode of the compiler and linker.
To perform a deeper analysis of parallel code you need to have information about all the program units. It allows you to understand if any function from one unit (cpp-file) is used in parallel mode from another unit (cpp-file) as shown in Figure 6.
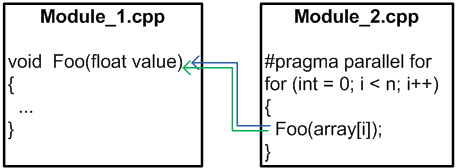
Figure 6. Inter-unit cooperation.
To gather the necessary information, Intel C++ uses the following strategy. The compiler still creates *.obj files but these are not object files, but the ones which contain the data necessary for the future analysis. That's why building of the executable file is impossible. When the compiler processes all the *.cpp files, the code analyzer begins to work instead of the linker. Proceeding from the data contained in *.obj files it diagnoses potential problems and generates the corresponding warnings about errors. On a whole, the analysis process can be presented as shown in Figure 7.
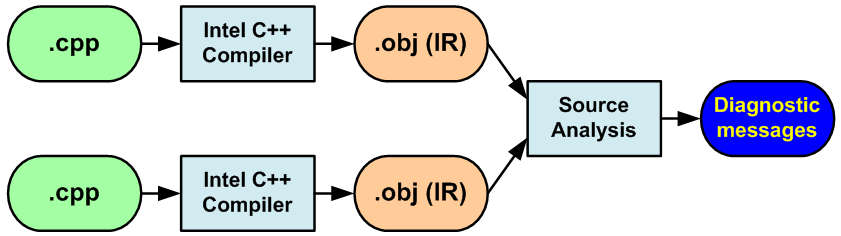
Figure 7. Gathering and processing of data with "Parallel Lint" analyzer.
Creation of a new configuration is performed with the help of "Configuration Manager" as shown in Figures 8-N10:
Figure 8. Launching Configuration Manager.
Figure 9. Creating a new configuration with the name "Intel C++ Parallel Lint" on the basis of the existing one.
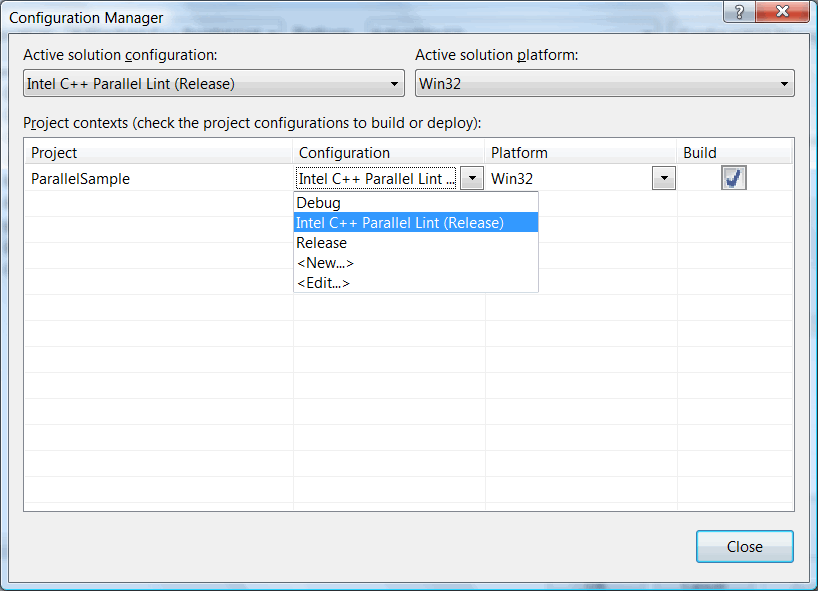
Figure 10. Making the created configuration active.
The next step is activation of "Parallel Lint" analyzer itself. To do this, you need to open "Diagnostics" inlay in the project's settings (see Figure 11).
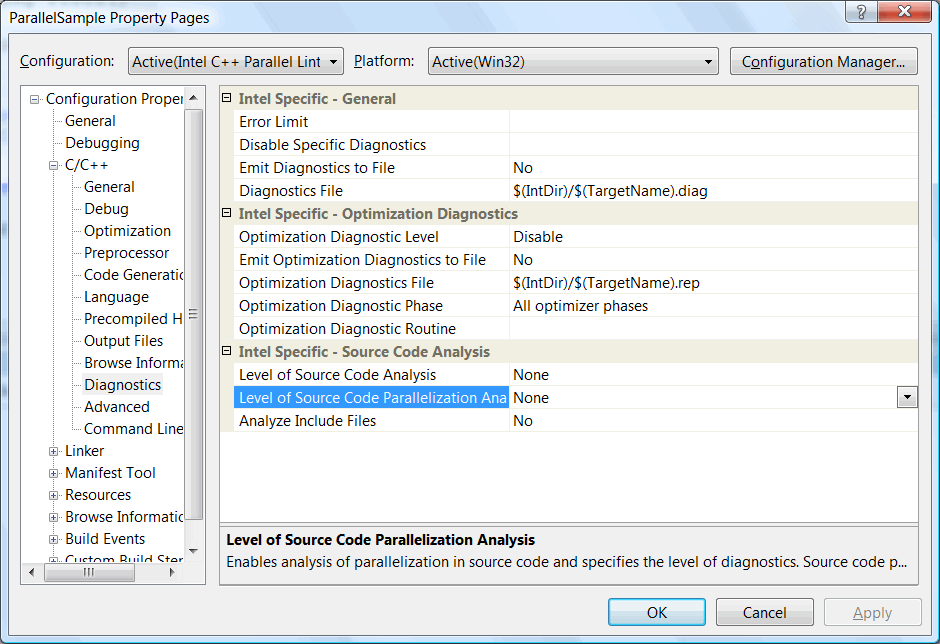
Figure 11. "Diagnostics" page in the project's settings where you can activate "Parallel Lint".
This page of the settings contains the item "Level of Source Code Parallelization Analysis" declaring the level of analysis of the parallel code. All in all, there are three variants as shown in Figure 12.
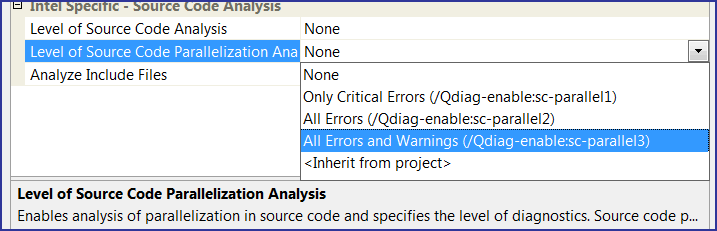
Figure 12. Choosing the level of diagnosing parallel errors.
I set the maximum third diagnosis level (see Figure 13). I did not enable analysis of header files (Analyze Include Files) for ParallelSample project contains errors only in *.cpp files.
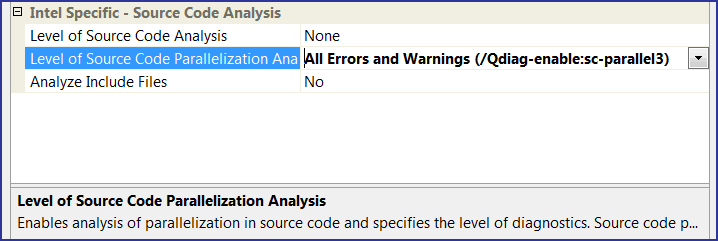
Figure 13. The maximum diagnosis level is chosen.
Preparation for the analysis is over and now you can start compiling the project to get diagnostic warnings. I did this and got a list of warnings. I think there is no sense in presenting it here, especially as it contains some warnings not related to OpenMP.
From the 23 examples containing errors, Intel C++ detected 5. It also found one error occurring in an incorrect function that VivaMP fails to diagnose. There were 2 false responses.
I also tried VivaMP on the parallel_lint example included into Intel C++ distribution kit. This example contains 6 errors. Coincidence here was complete: both VivaMP and Intel C++ detected these 6 errors.
Let's summarize for the moment. Complete coincidence of diagnosis on the parallel_lint example (from Intel C++ distribution kit) and the relation 5 to 23 errors on the ParallelSample example (from PVS-Studio distribution kit) shows that I have chosen the right way. These analyzers are similar and it is correct to compare them in the sphere of OpenMP parallel code analysis.
I was ready to begin comparison of PVS-Studio (VivaMP) and Intel C++ ("Parallel Lint") analyzers. I planned to perform this comparison on the basis of the following error patterns:
This is a good plan of comparison. But I was greatly disappointed: the third point turned out to be impossible to examine. I did not manage to find the description of the checks performed by Parallel Lint in Intel C++ documentation. Internet-search was unsuccessful too. I managed only to find scattered examples showing some abilities of Parallel Lint.
I resorted to the Intel developer community with asking a question in the forum where I could find more information about Parallel Lint. The answer was not a comforting one:
Presently, there's no such list in our current product release, other than what's presented in the compiler documentation under Parallel Lint section. But, we are developing description and examples for all messages, planned as of now for our next major release. Will keep you updated as soon as the release containing such a list is out. Appreciate your patience till then.
To sum it up: there is no description of Parallel Lint's abilities and examples, and there is no one expected in the near future. I faced the choice - to give up the comparison and continue it when documentation on Parallel Lint's abilities appeared or perform an incomplete comparison and enlarge it later. For the greatest part of the work had been done I decided to continue writing this article. Here I will give an incorrect comparison of the analyzers. And I am drawing your attention to it. By the title of the article as well.
Comparison will be performed on the basis of the data I possess now. In future, when there are more data, I will write a second version of this article where Intel C++ abilities will be considered in a better way. Now, comparison will be performed on the basis of the following error patterns:
Table 1 shows the results of the incorrect comparison of VivaMP and "Parallel Lint" analyzers. Below the table, there are explanations to each of the comparison points. I would like to stress it once more that the comparison results are incorrect. The data given in the table are one-sided. All the errors detected by VivaMP and only a part of the errors detected by Intel C++ ("Parallel Lint") are examined. Perhaps, Intel C++ ("Parallel Lint") detects 500 more error patterns I am not ware of and due to this is significantly more efficient than VivaMP.
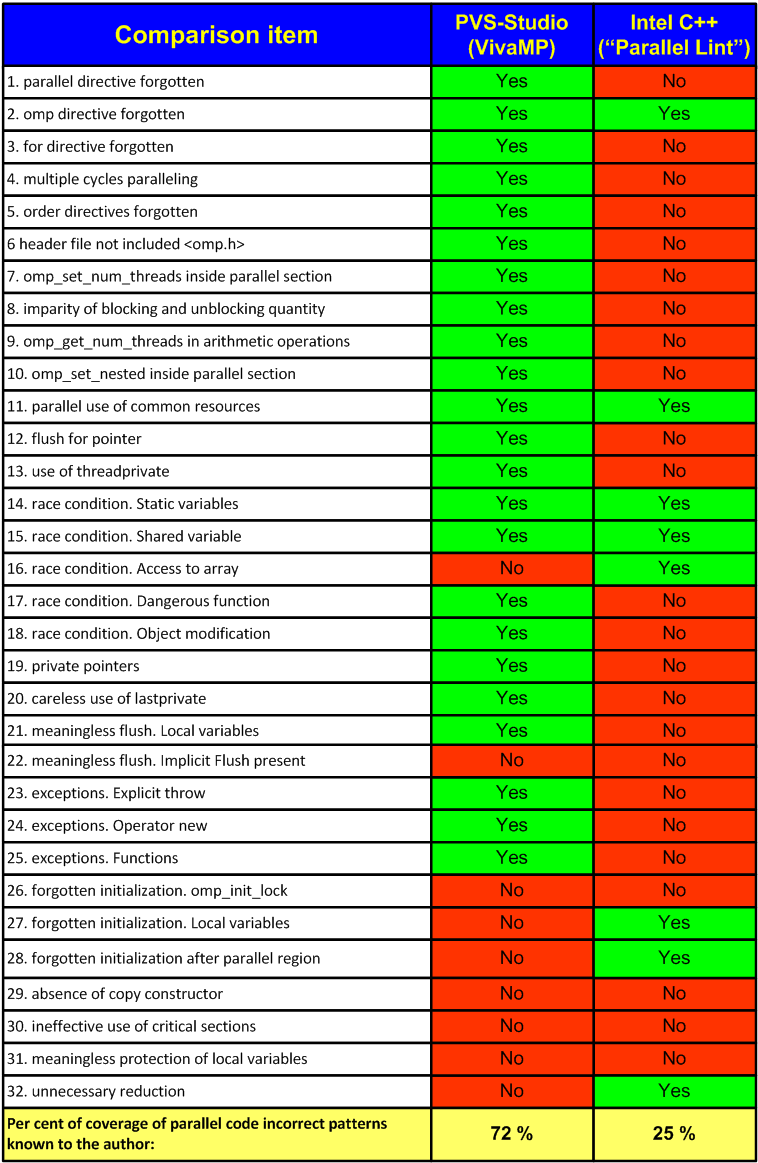
Table N1. The results of incorrect (partial) comparison of PVS-Studio (VivaMP) and Intel C++ ("Parallel Lint") analyzers.
The error occurs when parallel directive is forgotten. This error relates to the class of errors made through lack of attention and causes unexpected code behavior. Here is an example where a loop will not be paralleled:
#pragma omp for
for(int i = 0; i < 100; i++) { ... }Yet, absence of the word "parallel" in couple with the word "for", for example, does not mean a mistake by itself. If "for" or "sections" directive is situated inside a parallel section defined by "parallel" directive the code will be correct:
#pragma omp parallel
{
#pragma omp for
for(int i = 0; i < 100; i++)
...
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1001.
Intel C++ (Parallel Lint): not diagnosed.
The error occurs when omp directive has been obviously forgotten. The error is detected even during simple compilation of code (without using Parallel Lint) but we will consider it as well in our comparison. The error relates to the class of errors made through lack of attention and leads to incorrect code behavior. An example:
#pragma singleDiagnosis:
PVS-Studio (VivaMP): diagnosed as error V1002.
Intel C++ (Parallel Lint): diagnosed as warning #161.
Sometimes a programmer can forget to write "for" directive and it leads to execution of two loops instead of their paralleling. It is reasonable to warn the programmer that the code contains a potential error. An example of suspicious code:
#pragma omp parallel num_threads(2)
for(int i = 0; i < 2; i++)
...Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1003.
Intel C++ (Parallel Lint): not diagnosed.
Code containing multiple paralleling can potentially have an error or lead to inefficient use of computation resources. If a parallel loop is used inside a parallel section, it is most likely to be redundant and reduce performance. An example of code where it is logically possible to make an internal loop non-parallel:
#pragma omp parallel for
for(int i = 0; i < 100; i++)
{
#pragma omp parallel for
for(int j = 0; j < 100; j++)
...
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1004.
Intel C++ (Parallel Lint): not diagnosed.
You should consider unsafe using "for" and "ordered" directives together if no "ordered" directive is used after them inside the loop defined by for operator. For example:
#pragma omp parallel for ordered
for(int i = 0; i < 4; i++)
{
foo(i);
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1005.
Intel C++ (Parallel Lint): not diagnosed.
When <omp.h> header file is not included in the file where such OpenMP directives are used as, for example, "#pragma omp parallel for", it can theoretically lead to an error and is a bad style.
If a program uses OpenMP it should import vcomp.lib/vcompd.lib. Otherwise, an error will occur at the stage of execution if you use Visual C++ compiler. Import of this library is performed in the file omp.h. That is why if import of necessary libraries is not stated explicitly in the project, #include <omp.h> must be present at least in one of the project's files; or library import must be explicitly defined in the project's settings.
In PVS-Studio, this diagnostic warning has a low priority and is active only in "Pedantic Mode". So it will not bother you for nothing.
But despite its rare occurrence, this is a real error and that's why was included into comparison. Here is an example from practice. Open parallel_lint project included into Intel C++. Compile it with Visual C++. Launch it and get an error when launching the executable as shown in Figure 14.
Figure 14. The result of launching Primes_omp1 project built with Visual C++ 2005 compiler.
The cause is a forgotten #include <omp.h>. Note that if you build the project with Intel C++ no errors will occur.
Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1006.
Intel C++ (Parallel Lint): not diagnosed.
A call of omp_set_num_threads function is incorrect inside a parallel section defined by "parallel" directive. In C++ it leads to errors during execution of the program and its crash. An example:
#pragma omp parallel
{
omp_set_num_threads(2);
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1101.
Intel C++ (Parallel Lint): not diagnosed.
You should consider unsafe an odd use of the functions omp_set_lock, omp_set_nest_lock, omp_unset_lock and omp_unset_nest_lock inside a parallel section. An example of incorrect code:
#pragma omp parallel sections
{
#pragma omp section
{
omp_set_lock(&myLock);
}
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1102.
Intel C++ (Parallel Lint): not diagnosed.
omp_get_num_threads can be very dangerous when used in some arithmetic expression. An example of incorrect code:
int lettersPerThread = 26 / omp_get_num_threads();The error consists in that if omp_get_num_threads returns, for example, value 4, division with a remainder will take place. As a result, some objects will remain unprocessed. You can see a more thorough example in the article "32 OpenMP traps for C++ developers" or in Parallel Sample demo-example included into PVS-Studio distribution kit.
Other expressions using omp_get_num_threads can be quite correct. Here is an example which does not cause diagnostic warnings in PVS-Studio:
bool b = omp_get_num_threads() == 2;Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1103.
Intel C++ (Parallel Lint): not diagnosed.
A call of omp_set_nested function is incorrect inside a parallel section defined by "parallel" directive. An example:
#pragma omp parallel
{
omp_set_nested(2);
}But if omp_set_nested function is in a nested block created by "master" or "single" directives, it will be correct:
#pragma omp parallel
{
#pragma omp master
{
omp_set_nested(2);
}
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1104.
Intel C++ (Parallel Lint): not diagnosed.
You should consider unsafe unprotected use of functions in parallel sections if these functions use shared resources. Examples of such functions: printf, OpenGL functions.
An example of unsafe code:
#pragma omp parallel
{
printf("abcd");
}An example of safe code when the function call is protected:
#pragma omp parallel
{
#pragma omp critical
{
printf("abcd");
}
}Diagnosis:
PVS-Studio (VivaMP): partly diagnosed as error V1201.
Intel C++ (Parallel Lint): partly diagnosed as error #12158.
Diagnosis is partial due to the following reasons:
In VivaMP the list of unsafe functions is far from being complete and requires enlargement.
Unfortunately, Parallel Lint analyzer generates a false warning when the function call is protected. And again, there is no information about completeness of the function list.
"flush" directive serves for the threads to update values of shared variables. When using flush for a pointer it is very likely that the programmer is mistaken considering that the data at the pointer's target address will be updated. Actually, it is the value of the variable containing the pointer that will be updated. More than that, OpenMP standard clearly says that the variable-argument of flush directive must not be a pointer.
An example:
int *t;
...
#pragma omp flush(t)Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1202.
Intel C++ (Parallel Lint): not diagnosed.
threadprivate directive is very dangerous and using it is rational only at a last resort. If possible avoid using this directive. To learn more about the dangers of using threadprivate see the article "32 OpenMP traps for C++ developers" [1].
An example of unsafe code:
#pragma omp threadprivate(var)Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1203.
Intel C++ (Parallel Lint): not diagnosed.
One of the race condition errors. Initialization of a static variable inside a parallel section is forbidden without a special protection. For example:
#pragma omp parallel num_threads(2)
{
static int cachedResult = ComputeSomethingSlowly();
...
}A correct example of using protection:
#pragma omp parallel num_threads(2)
{
#pragma omp critical
{
static int cachedResult = ComputeSomethingSlowly();
...
}
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1204.
Intel C++ (Parallel Lint): diagnosed as warning #12246.
One of the race condition errors. Two or more threads modify the same shared variable which is not specially protected. For example:
int a = 0;
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 100000; i++)
{
a++;
}A correct example with protection:
int a = 0;
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 100000; i++)
{
#pragma omp atomic
a++;
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1204.
Intel C++ (Parallel Lint): diagnosed as warning #12246, warning #12247, warning #12248.
One of the race condition errors. Two or more threads try to work with the same array items using different expressions for calculating indexes. For example:
int i;
int factorial[10];
factorial[0]=1;
#pragma omp parallel for
for (i=1; i < 10; i++) {
factorial[i] = i * factorial[i-1];
}Diagnosis:
PVS-Studio (VivaMP): not diagnosed.
Intel C++ (Parallel Lint): diagnosed as warning #12246.
One of the race condition errors. Two or more threads call a function accepting as a formal argument a value by a non-constant link or non-constant pointer. When calling such a function inside a parallel section, a shared variable is passed into it. No protection is used during this process.
An example of potentially unsafe code:
void dangerousFunction(int& param);
void dangerousFunction2(int* param);
int a = 0;
#pragma omp parallel num_threads(4)
{
#pragma omp for
for (int i = 0; i < 100000; i++)
{
dangerousFunction(a);
dangerousFunction2(&a);
}
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1206.
Intel C++ (Parallel Lint): not diagnosed.
One of the race condition errors. Two or more threads are calling a non-constant class function from a shared object. No protection is used during this process.
An example of potentially unsafe code:
MyClass obj;
#pragma omp parallel for num_threads(2)
for (int i = 0; i < 100000; i++)
{
obj.nonConstMethod();
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1207.
Intel C++ (Parallel Lint): not diagnosed.
You should consider unsafe applying directives "private", "firstprivate" and "threadprivate" to pointers (not arrays).
An example of unsafe code:
int *arr;
#pragma omp parallel for private(arr)If a variable is a pointer, each thread gets a local copy of this pointer and as a result, all the threads work with shared memory through it. It is very likely that the code contains an error.
An example of safe code where each thread works with its own array:
int arr[4];
#pragma omp parallel for private(arr)Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1209.
Intel C++ (Parallel Lint): not diagnosed.
"lastprivate" directive after a parallel section assigns to a variable a value from the lexically last section or from the last loop iteration. The code where the marked variable is not modified in the last section is likely to be incorrect.
An example:
#pragma omp sections lastprivate(a)
{
#pragma omp section
{
a = 10;
}
#pragma omp section
{
}
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1210.
Intel C++ (Parallel Lint): not diagnosed.
You should consider senseless using "flush" directive for local variables (defined in a local section) and also variables marked as threadprivate, private, lastprivate, firstprivate.
"flush" directive is senseless for these variables for they always contain actual values. And thus reduce code performance.
An example:
int a = 1;
#pragma omp parallel for private(a)
for (int i = 10; i < 100; ++i) {
#pragma omp flush(a);
...
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1211.
Intel C++ (Parallel Lint): not diagnosed.
You should consider inefficient using "flush" directive in those places where it is executed implicitly. Here are cases when "flush" directive is implicit and using it is senseless:
Diagnosis:
PVS-Studio (VivaMP): not diagnosed.
Intel C++ (Parallel Lint): not diagnosed.
According to OpenMP specification, all exceptions must be processed inside a parallel section. An exception leaving the parallel section will lead to program fail and most likely to crash.
An example of incorrect code:
try {
#pragma omp parallel for num_threads(4)
for(int i = 0; i < 4; i++)
{
throw 1;
}
}
catch (...)
{
}Correct code:
size_t errCount = 0;
#pragma omp parallel for num_threads(4) reduction(+: errCount)
for(int i = 0; i < 4; i++)
{
try {
throw 1;
}
catch (...)
{
++errCount;
}
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1301.
Intel C++ (Parallel Lint): not diagnosed.
According to OpenMP specification, all exceptions must be processed inside a parallel section. In case of memory allocation error "new" operator generates an exception and this must be considered when using it in parallel sections.
An example of incorrect code:
try {
#pragma omp parallel for num_threads(4)
for(int i = 0; i < 4; i++)
{
float *ptr = new (MyPlacement) float[1000];
delete [] ptr;
}
}
catch (std::bad_alloc &)
{
}To learn more about this topic see the following blog-notes by PVS-Studio developers:
Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1302.
Intel C++ (Parallel Lint): not diagnosed.
According to OpenMP specification, all exceptions must be processed inside a parallel section. If inside a parallel section a function is used marked as explicitly throwing exceptions, the exception must be processed inside the parallel section.
An example of incorrect code:
void MyThrowFoo() throw(...)
{
throw 1;
}
try {
#pragma omp parallel for num_threads(4)
for(int i = 0; i < 4; i++)
{
MyThrowFoo();
}
}
catch (...)
{
}Diagnosis:
PVS-Studio (VivaMP): diagnosed as error V1303.
Intel C++ (Parallel Lint): not diagnosed.
You should consider incorrect using variables of omp_lock_t / omp_nest_lock_t type without their preliminary initialization in functions omp_init_lock / omp_init_nest_lock. By using we understand a call of omp_set_lock function etc.
An example of incorrect code:
omp_lock_t myLock;
#pragma omp parallel num_threads(2)
{
omp_set_lock(&myLock);
omp_unset_lock(&myLock);
}Diagnosis:
PVS-Studio (VivaMP): not diagnosed.
Intel C++ (Parallel Lint): not diagnosed.
You should consider incorrect using variables defined in a parallel region as local with "private" and "lastprivate" directives without their preliminary initialization. For example:
int a = 0;
#pragma omp parallel private(a)
{
a++;
}Diagnosis:
PVS-Studio (VivaMP): not diagnosed.
Intel C++ (Parallel Lint): diagnosed as error #12361.
You should consider incorrect using after a parallel code section those variables to which "private", "threadprivate" or "firstprivate" directives were applied. Before using them further, they must be initialized again.
An example of incorrect code:
#pragma omp parallel private(a)
{
...
}
b = a;Diagnosis:
PVS-Studio (VivaMP): not diagnosed.
Intel C++ (Parallel Lint): diagnosed as error #12352, error #12358.
You should consider unsafe applying "firstprivate" and "lastprivate" directives to class instances where copy constructor is absent.
Diagnosis:
PVS-Studio (VivaMP): not diagnosed.
Intel C++ (Parallel Lint): not diagnosed.
You should consider inefficient using critical sections or functions of omp_set_lock class where "atomic" directive is quite enough. "atomic" directive works faster than critical sections for some atomic operations can be directly replaced with processor commands. Consequently, it is desirable that you use this directive wherever you need protection of shared memory at elementary operations. According to OpenMP specification, to such operations the following ones refer:
Here x is a scalar variable, expr is an expression with scalar types where x variable is absent, binop is a non-overloaded operator +, *, -, /, &, ^, |, << or >>. In all the other cases atomic directive must not be used (this is verified by the compiler).
On the whole, from the viewpoint of performance decrease, methods of protecting data from simultaneous writing are arranged in this order: atomic, critical, omp_set_lock.
An example of inefficient code:
#pragma omp critical
{
e++;
}Diagnosis:
PVS-Studio (VivaMP): not diagnosed.
Intel C++ (Parallel Lint): not diagnosed.
Any protection of memory from simultaneous writing reduces performance of the program, being it an atomic operation, a critical section or a lock. Consequently, in those cases when you do not need it, it is better not to use this protection.
A variable should not be protected from simultaneous writing in the following cases:
if the variable is local for the thread (and also if it participates in expressions threadprivate, firstprivate, private or lastprivate);
if addressing to the variable takes place in the code which is guaranteed to execute in only one thread (in the parallel section of master directive or single directive).
An example, where protection from writing into "p" variable is senseless:
#pragma omp parallel for private(p)
for (i=1; i<10; i++)
{
#pragma omp critical
p = 0;
...
}Diagnosis:
PVS-Studio (VivaMP): not diagnosed.
Intel C++ (Parallel Lint): not diagnosed.
Sometimes, reduction directive can be used in code although the variables defined in it do not change in the parallel region. It may either indicate an error or show that you forgot about some directive or variable and did not delete it during code refactoring.
An example, where "abcde" variable is not used:
#pragma omp parallel for reduction (+:sum, abcde)
for (i=1; i<999; i++)
{
sum = sum + a[i];
}Diagnosis:
PVS-Studio (VivaMP): not diagnosed.
Intel C++ (Parallel Lint): diagnosed as error #12283.
Although comparison of the two analyzers cannot be called a full one yet, still this article allows the reader to learn about many patterns of parallel OpenMP errors and methods of detecting them at the very early stages of development. The possibility to detect an error at the stage of coding is a great advantage of static analysis method for these errors are very difficult to detect at the testing stage or even fail to be detected for a long time.
The tools we have considered - PVS-Studio (VivaMP) and Intel C/C++ ("Parallel Lint") will be quite helpful for parallel program developers. What tool to choose depends on the developers. Unfortunately, this article does not give an answer to this question. For the time, we can formulate the advantages of each analyzer as follows:
Intel C/C++ ("Parallel Lint") analyzer's advantages:
PVS-Studio (VivaMP) analyzer's advantages:
0
0
0
0