
Our website uses cookies to enhance your browsing experience.

The article is an introduction into parallel programs for beginners.
For instance, when a man cannot manage everything he creates a tally for himself, brainless, irresponsible, able only to solder pins, or carry heavy loads, or write from dictation but doing this very well.
Arkadiy and Boris Strugatskie
Hardly would we have seen the world around us as we see it if in its time mankind didn't invented the principle of labor division. Due to this there are professionals specializing in a particular sphere and able to perform their work perfectly. Implementation of this approach in the sphere of industry allowed us to increase product release tenfold. That's why it's no wonder that when computers appeared there arouse the question of applying the principle of labor division to computer programs' operation. Research in this sphere allowed us to detect also a pleasing fact that complicated mathematical calculations related, for example, to matrix operations, can be split into independent subtasks. Each subtask can be executed separately and then you can get the result of solution of the source task by combining the results of subtasks' solutions. As subtasks are independent they can be solved simultaneously by several executors. If a computer takes the role of the executor this approach allows us to find solutions for computationally very complicated tasks of realistic modeling of real-environment objects, cryptanalysis, real-time control of technological processes. It is this principle according to which all the supercomputers - the pride of scientific laboratories and computational centers - operate.
Having reached the limit of processors' performance increase relating to fundamental physical limits, computer manufacturers began to increase the number of computational nodes in their products. And now inside the chassis of a common PC you may find what has been earlier called a supercomputer - a multi-core computing device. Operation systems have been ready for this technology for a long time. Unix and Linux, OS/2, macOS and modern versions of Microsoft Windows show performance increase at simultaneous execution of several programs. For example, while you watch a film, antivirus scanning of your hard disk can be performed without your noticing it. But there are situations when solution of only one task can demand a lot of computational resources. Leaving aside the problem of nuclear fusion synthesis or cracking a password to an archive, let's think about such common things as music and video coding and computer games. Programs implementing these tasks enable fully the resources of CPU. But increase of the number of processors in the system won't give you marked performance gain in these examples if no special methods were used while developing the programs. Indeed, how does an operation system know the peculiarities of coding methods' implementation to be able to distribute calculations between processors? Can it know how to perform parallel calculation of a game-situation scene?
So, we have a multi-processor computer. We have analyzed the task and singled out the subtasks which can be solved simultaneously. How can we implement solution of these subtasks in a program? Modern operation systems offer us two variants of code execution - in the form of processes and in the form of threads.
A process is operation of a program loaded into main memory and ready for execution. So, when we simultaneously perform two actions - serf the news in the Internet and burn files on a CD, two processes are executed simultaneously - an internet-browser and a CD-writing program are operating. A process consists of program code, operated data and various resources, for example, files or system queues belonging to the program. Each process is executed in its address space, i.e. has access only to its own area of main memory. On the one hand it is good because one process cannot interfere with the other (until they both address the non-divisible resource, for example, the disk drive, but it is a different thing) and errors in operation of one program in no way will influence operation of the other. But on the other hand, if processes are meant for solving one common task, we face the question: how will they exchange information and interact at all?
What is interesting, developers of Mircosoft Windows and Unix (Linux) operation systems applied different approaches to the question of launching a child process. From the viewpoint of a programmer using WIN32 API everything is quite natural. In the point of launch of a support process CreateProcess() function is called whose one argument indicates the path to EXE-file with the program to be executed.
In Unix-like operation system this is implemented in a different way. In the code point where we need to create a new process, fork() system call is used. As the result the operating program "forks", that is the state of the program at the moment of fork() execution is copied (by the state we understand the values of the CPU registers, stack, data area and list of open files) and on the basis of this copy a new process is launched possessing the same information as the parent process. Both parent and child processes continue executing the same program beginning with the command following fork() system call. As execution of one and the same work by two processors is senseless, we face the question: how to implement solution of an independent subtask in each process we've got? The point is that from the viewpoint of the parent process the result of fork() function is the identifier of the child process, and fork() simply returns zero value into the child process. Each process can identify itself by this code. And all the rest is a technical matter. The child process has only to prepare an environment for executing a new program, load its code with the help of exec() system call and transfer control to it.
A thread is a means of forking a program inside a process. The process can contain several threads each of which is executed independently from the others keeping its own values of registers and its own stack. Threads have access to all the global resources of the executed process, for example, open files or memory segments. Each process has at least one executed thread, the main thread. When solution of the task comes to the section allowing paralleling, the processor spawns the necessary number of additional threads executed simultaneously, solving their subtasks and returning the results to the main thread.
To solve complex tasks it is not enough just to perform parallel execution of different code sections. You need also to arrange exchange of the results of their operation, that is organize interaction between these sections. One would think, in the case of threads it could be easily implemented by providing access to the defined common area of main memory. But this simplicity is deceptive because operations of writing into main memory by different threads can intersect very unpredictably so that the integrity of the information kept in this memory area will be broken.
Imagine a billing system of a cellular operator executed on a powerful multi-processor server. It's no wonder that charge-off from a client's account for the provided services is performed by one program thread while charge of payments on the client's account is performed by another thread. The first operation can be written in the form: S := S - A where S - balance of the account at the moment of operation, A - cost of phone calls made. The processor will execute this operation in three steps: at first the source value of S variable will be received, then A will be subtracted from it, after that the result will be written into S cell. Similarly the second operation is performed: S := S + B where B - sum of money paid by the client. Suppose the client make a call some time later after he has paid through a bank office. As charge of payments on the account occurs with some delay due to objective reasons, it is possible that both operations - charge-off and charge-on - will be executed in the billing system nearly at the same time. Suppose that charge-off operation be executed first and the charge-on operation follows it with one-beat lag (figure 1). After the three beats of the charge-off operation the current account balance will equal S-A but the fourth beat will make this value S+B.
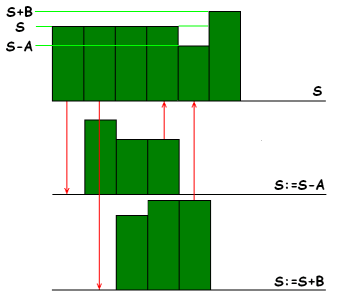
Figure 1 - An example of a billing system's operation
Thus, the final balance of the account will equal S+B instead of the right S-A+B value. In a different situation such a collision could be not so good for the client. That's why to avoid such problems it is necessary to take special measures to protect separate program sections from simultaneous execution.
In the next article sections about synchronization and interaction of simultaneously executed program sections the terms "process" and "thread" will be used together as the described mechanisms are in most cases applicable to both notions.
Modern operation systems offer a wide range of means for synchronizing parallel processes. The simplest way for synchronizing simultaneously executed code sections is waiting of one thread for termination of execution of the other. The same mechanism provides support of operation systems executing asynchronous operations, such as file input-output or data exchange through network. Besides, functions of waiting can be used at mutual announcing about the events taking place (figure 2).

Figure 2 - Event is an object of operation systems which can switch its state from "common" to "signal"
Thus, for example, while developing a system of bank trading day an event can be registered for announcing about receipt of funds to a client's account. This event can be waited for by the thread performing execution of client pay directions.
If there is a possibility that different program sections can simultaneously modify some variable it is necessary to implement protection of this variable. For example, if one thread deals with calculations of a game scene and the other deals with its repainting, the latter should be performed only after all the necessary calculations are done. For this purpose a special object mutex is introduced into operation systems (English "mutual execution").

Figure 3 - Mutex is a system object which can be in one of the two internal states - "free" or "busy".
Before a thread begins to change the variable it should perform capture of the mutex corresponding to this variable. If it succeeds the mutex changes its internal state and the thread continues execution. If the other thread tries to capture the corresponding mutex while the first thread works with the variable, it will be rejected and it will have to wait until the mutex is released by the first thread (figure 3). Thus, at a concrete moment of time it is guaranteed that only one section works with the variable.
While programming there can be situations when you need to modify several global variables in one code section. If there is a possibility that this code will be executed by several threads simultaneously, you should implement its protection. Specially for such cases operation systems offer to arrange the corresponding code into a critical section.
Figure 4 - Critical section is a program section which can be executed by only one thread at a time.
The critical section can be executed by only one thread at a time. The other thread can inquire if the critical section is available for execution and in case of negative answer can either wait until it is free or execute another operation (figure 4). Critical sections differ from mutexes also in that one and the same thread can enter the critical section it has captured many times while when trying to capture a mutex the thread's execution will stop and a so called "deadlock" can occur.
Suppose we have a set of single-type resources, for example, several windows for displaying information or a pool of network printers. To keep record of distribution of such resources between processors we use semaphores.
Figure 5 - Semaphore allows you to keep record of distribution of single-type resources between threads
Semaphore is a system object which is a counter. Before a thread starts working with the resource from the set it should address the semaphore associated with it. If the value of the semaphore counter is greater than zero the thread is allowed to work with the resource while the counter's value decrements by one (figure 5). But if all the resources of the set are used the thread will be enqueued. When the resource is free the thread announces the semaphore about it, the semaphore's value rises and the resource can be used again.
Sometimes it is necessary to urgently stop execution of a process to perform some urgent actions. Some operation systems use signals for this purpose. A process which has to execute a special operation sends a signal to the other process. When writing this other process a procedure of processing signals should be implemented: when the process gets a signal it can suspend execution or terminate its work, execute a special subprogram created for such a case or just ignore the signal.
As it was said above, to solve a common task together processors may need not only to coordinate their work but also to exchange information - for example, intermediate results. For this purpose you can use main-memory sharing, information exchange through a file, transfer of data through unidirectional pipes or imitation of network operation (figure 6).
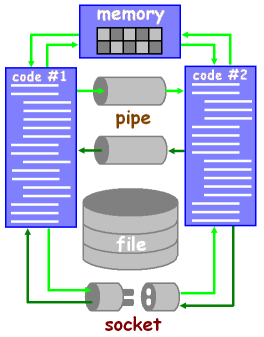
Figure 6 - Ways of exchanging data between processors
The quickest and most obvious way of information exchange between simultaneously executed code sections is to use the shared area of main memory. One process writes data into memory, the other reads them and vice versa. But in this case you need to implement synchronization of the processes by one of the above mentioned ways. If information exchange between the threads through the shared memory can be implemented directly the processes should at first request the necessary memory segment from operation systems and coordinate the procedure of its usage.
The next method of information exchange is using pipes. Pipe is a system object allowing you to transfer information in one direction, as a rule. The most known examples of pipes are standard input/output streams (stdin, stdout). Stdout of one process can be directed into the stdin of the other. After this the information being written into stdout of the first process can be read by the second process. Operation system allow us to create additional pipes. To work with pipes we use functions whose syntax is similar to functions of file operations.
You can perform data exchange with the help of files as well. Modern operation systems have embedded mechanisms of buffering information participating in file operations that's why this method is rather effective. But from the security viewpoint this approach yields to those described above as an unauthorized application can get access to the file used for inter-processor exchange. Before using this method you should study the guidance on implementation of file operations in a concrete operation system and take measures to protect data.
Duplex data exchange between processes can be implemented by operation system network means. With the help of sockets two processes can establish a channel between them to transfer data in the same way as a browser and a HTTP-server. The format of the data being transferred in this case can be absolutely of any kind - the point is that the processes use the same agreements of exchange procedure, the protocol. Moreover, nothing prevents these processes from being executed on different computers. And with this last notice we pass on to the next article section.
Speaking about parallel execution of programs, we suggested that we use a computer with several processors. But such a computer is not the only platform for executing parallel programs. Let's consider a simplest computational network consisting of ten common one-processor computers united by a FastEthernet twisted pair. Looks familiar, doesn't it? What is each computer in fact? Generally speaking, it is a processor with main and disk memory available to it. Each computer is a perfect area for executing one process. And what if on each of the ten computers we launch simultaneously programs which solve subtasks of cracking the password to an archive? Obviously, solution of the task will demand much less time than in case of using one computer. And what if the network consists not of 10 but of 100 computers? And this network is linked to the Internet?
From this example we see that even small local networks have a great potential computational power. And if you hardly can use this power for computer games, for CAD systems it will be good enough. A group of computers united by the bus of transferring data into a single computational system is called a cluster system or cluster. You need only to write a special program in which you should implement the possibility of information exchange between its simultaneously executed copies (processes) through the local network. Generally speaking, this program may have traditional client-server architecture, i.e. be able both to send messages to its neighbors and receive messages from them. But there already exist ready solutions for simplifying development of programs for cluster systems, for example, MPI and PVM, which offer a programmer means for performing both point-to-point and collective interaction between processes executed on the nodes of the cluster system, and also the methods of their synchronization.
MPI specification (Message Passing Interface) offers a programming model in which a program spawns several processes interacting with the help of addressing subprograms of message passing and receiving. Its implementations are libraries of subprograms which can be used in C/C++ and Fortran languages. When launching an MPI-program a fixed number of processes is created. MPI specification has been created as an industry standard that's why all its means are focused on getting high performance when used on symmetrical multi-processor systems and homogeneous cluster systems (supercomputers). There is a free implementation of MPI - MPICH (MPI CHamelion), whose Windows and Linux versions are available for download here: http://www.mpich.org/. Being installed on a PC MPICH system can perform development and debugging of programs for further usage without any modifications on clusters or supercomputers.
Unlike MPI the system of development and execution of parallel programs PVM (Parallel Virtual Machine) has been created within the framework of a research project meant for heterogeneous computational complexes. It allows you to quickly unite a heterogeneous set of computers connected through network into a computational resource which is called "Parallel Computing Machine". The computers may have different architectures and operate on different OS. PVM system is a set of libraries and utilities meant for development and debugging of parallel programs and also for controlling configuration of the Virtual Computing Machine. C/C++ and Fortran languages are supported. Configuration of the computational complex can change dynamically by means of excluding some nodes and adding new ones. Such universality is possible also because of some decrease of performance in comparison with MPI system.
Thus, both MPI and PVM allow you without much effort to turn the local network of your organization into a powerful computing machine able to solve complex tasks.
We should admit that parallel computational systems are very common nowadays. Operation system provide developers with the necessary low-level service, while for solving applied tasks there exist ready proved means in the form of specialized utilities and libraries for popular high-level programming languages. And a programmer should master methods of parallel program development to keep up with the modern tendencies.
0
0
0
0