
Our website uses cookies to enhance your browsing experience.

Static analysis allows checking program code before the tested program is executed. The static analysis process consists of three steps. First, the analyzed program code is split into tokens, i.e. constants, identifiers, reserved symbols, etc. This operation is performed by lexer. Second, the tokens are passed to parser, which builds an abstract syntax tree (AST) based on the tokens. Finally, the static analysis is performed over the AST. This article describes three static analysis techniques: AST walker analysis, data flow analysis and path-sensitive data flow analysis.
Application testing is an important part of software development process. There are many different types of software testing. Among them there are two types involving the application's code: static analysis and dynamic analysis.
Dynamic analysis is performed on executable code of a compiled program. Dynamic analysis checks only user-specific behavior. That is, only the code, executed during a test is checked. Dynamic analyzer can provide the developer with information on memory leaks, program's performance, call stack, etc.
Static analysis allows checking program code before the tested program is executed. Compiler always performs static analysis during the compilation process. However, in large, real-life projects it is often necessary to make the entire source code fulfill some additional requirements. These additional requirements may vary from variables naming to portability (for example, the code should be successfully executed both on x86 and x64 platforms). The most common requirements are:
All requirements can be divided into two categories: rules and guidelines. Rules describe what is mandatory, while guidelines describe what is recommended (by analogy with errors and warnings produced by built-in code analyzers of standard compilers).
Rules and guidelines form a coding standard. A coding standard defines the way a developer must and should write program code.
A static analyzer finds source code lines, which presumably do not fulfill the specified coding standard and displays diagnostic messages so that the developer can understand what is wrong with these lines. The static analysis process is similar to compilation except that no executable or object code is generated. This article describes the static analysis process step by step.
Static analysis process consists of two steps: abstract syntax tree creation and abstract syntax tree analysis.
In order to analyze source code, a static analysis tool should "understand" the code, that is, parse it and create a structure, describing the code in a convenient form. This form is named abstract syntax tree (often referred to as AST). To check, whether source code fulfils a coding standard, this tree should be built.
In general case, an abstract syntax tree is built only for an analyzed fragment of a source code (for example, for a specific function). Before the tree can be built, the source code is first processed by a lexer and then by a parser.
The lexer is responsible for dividing the input stream into individual tokens, identifying the type of the tokens, and passing tokens one at a time to the next stage of the analysis. The lexer reads text data line by line and splits a line to reserved words, identifiers and constants, which are called tokens. After a token is retrieved, the lexer identifies the type of the token.
If the first character of the token is a digit the token is a number, or if the first character is a minus sign the token is a negative number. If the token is a number it might be a real or an integer. If it contains a decimal point or the letter E (which indicates scientific notation) then it is a real, otherwise it is an integer. Note that this could be masking a lexical error. If the analyzed source code contains a token "4xyz" the lexer will turn it into an integer 4. It is likely that any such error will cause a syntax error, which the parser can catch. However, such errors can also be processed by lexer.
If the token is not a number it could be a string. String constants can be identified by quote marks, single quote marks or other symbols, depending on the syntax of the analyzed language.
Finally, if the token is not a string, it must be an identifier, a reserved word, or a reserved symbol. If the token is not identified as one of them, it is a lexical error. The lexer does not handle errors itself, so it simply notifies the parser that an unidentified token type has been found. The parser will handle the error [2].
The parser has an understanding of the language's grammar. It is responsible for identifying syntax errors and for translating an error free program into internal data structures, abstract syntax trees, that can be processed by static analyzer.
While lexer knows only language's syntax, parser also recognizes context. For example, let's declare a C function::
int Func(){return 0;}Lexer will process this line in the following way (see table 1):
|
int |
Func |
( |
) |
{ |
return |
0 |
; |
} |
|---|---|---|---|---|---|---|---|---|
|
reserved word |
identifier |
reserved symbol |
reserved symbol |
reserved symbol |
reserved word |
integer constant |
reserved symbol |
reserved symbol |
Table 1. Tokens of the "int Func(){return 0};" string.
The line will be identified as 8 correct tokens and these tokens will be passed to parser. The parser will check the context and find out that it is a declaration of function, which takes no parameters, returns an integer, and always returns 0.
The parser will find it out by creating an abstract syntax tree from the tokens provided by the lexer and analyzing the tree. If the tokens and the tree built from them will be considered to be correct, the tree will be used for the static analysis. Otherwise, the parser will report an error.
However, building an abstract syntax tree is not just organizing a set of tokens in a tree form.
An abstract syntax tree captures the essential structure of the input in a tree form, while omitting unnecessary syntactic details. ASTs can be distinguished from concrete syntax trees by their omission of tree nodes to represent punctuation marks such as semi-colons to terminate statements or commas to separate function arguments. ASTs also omit tree nodes that represent unary productions in the grammar. Such information is directly represented in ASTs by the structure of the tree.
ASTs can be created with hand-written parsers or by code produced by parser generators. ASTs are generally created bottom-up.
When designing the nodes of the tree, a common design choice is determining the granularity of the representation of the AST. That is, whether all constructs of the source language are represented as a different type of AST nodes or whether some constructs of the source language are represented with a common type of AST node and differentiated using a value. One example of choosing the granularity of representation is determining how to represent binary arithmetic operations. One choice is to have a single binary operation tree node, which has as one of its attributes the operation, e.g. "+". The other choice is to have a tree node for every binary operation. In an object-oriented language, this would results in classes like: AddBinary, SubtractBinary, MultiplyBinary, etc. with an abstract base class of Binary[3].
For example, let us parse two expressions: 1 + 2 * 3 + 4 * 5 and 1+ 2 * (3 + 4) * 5 (see figure 1):
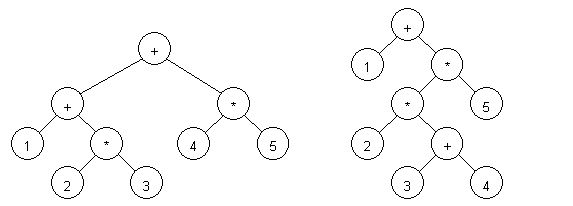
Figure 1. Parsed expressions: 1 + 2 * 3 + 4 * 5 (left) and 1+ 2 * (3 + 4) * 5 (right).
As one can see from the figure, the expression can be restored to its original form if you walk the tree from left to right.
After the abstract syntax tree is created and verified, the static analyzer will be able to check, whether the source code fulfils the rules and guidelines specified by the code standard.
There are many different analysis techniques, such as AST walker analysis, dataflow analysis, path-sensitive data flow analysis, etc. Concrete implementations of these techniques vary from tool to tool. Static analysis tools for different programming languages can be based on various analysis frameworks. These frameworks contain core sets of common techniques, which can be used in static analysis tools so that these tools reuse the same infrastructure. The supported analysis techniques and the way these techniques are implemented varies from framework to framework. For example, a framework may provide easy way to create an AST walker analyzer, but has no support for data-flow analysis[4].
Although all the three above mentioned analysis techniques use the AST created by parser, the techniques differ by their algorithms and purposes.
AST walker analysis, as one can see from the term, is performed by walking the AST and checking whether it fulfils the coding standard, specified as a set of rules and guidelines. This is the analysis performed by compilers.
Data flow analysis can be described as a process to collect information about the use, definition, and dependencies of data in programs. The data flow analysis algorithm operates on a control flow graph (CFG), generated from the source code AST. The CFG represents all possible execution paths of a given computer program: the nodes represent pieces of code and the edges represent possible control transfers between these code pieces. Since the analysis is performed without executing the tested program, it is impossible to determine the exact output of the program, i.e. to find out which execution path in the control flow graph is actually taken. That is why data flow analysis algorithms make approximations of this behavior, for example, by considering both branches of an if-then-else statement and by performing a fixed-point computation for the body of a while statement. Such a fixed-point always exists because the data flow equations compute sets of variables and there are only a finite number of variables available since we only consider programs with a finite number of statements. Therefore, there is a finite upper limit to the number of elements of the computed sets which means that a fixed-point always exists. In terms of control flow graphs, static analysis means that all possible execution paths are considered to be actual execution paths. The result of this assumption is that one can only obtain approximate solutions for certain data flow analysis problems[5].
The data flow analysis algorithm described above is path-insensitive, because it contributes all execution paths - whether feasible or infeasible, heavily or rarely executed - to a solution. However, programs execute only a small fraction of their potential paths and, moreover, execution time and cost is usually concentrated in a far smaller subset of hot paths. Therefore, it is natural to reduce the analyzed CFG and, therefore, to reduce the amount of calculations so that only a subset of the CFG paths are analyzed. Path-sensitive analysis operates on a reduced CFG, which does not include infeasible paths and does not contain "dangerous" code. The paths selection criteria are different in different tools. For example, a tool may analyze only the paths containing dynamic arrays declaration, which is considered to be "dangerous" according to the tool's settings.
The number of static analysis tools and techniques grows from year to year and this proves the growing interest in static analyzers. The cause of the interest is that the software under development becomes more and more complex and, therefore, it becomes impossible for developers to check the source code manually.
This article gave a brief description of the static analysis process and analysis techniques.
0
0
0
0