
Our website uses cookies to enhance your browsing experience.


The article tells developers about VivaCore library, preconditions of its creation, its possibilities, structure and scope of use. This article was written simultaneously with the development of VivaCore library and that's why some of the details of the final realization may differ from the features described here. But this won't prevent the developers from getting acquainted with the general work principles of the library, mechanisms of analysis and processing of C and C++ source code.
VivaCore is an open source library for work with C and C++ code. The library is intended for realizing code refactoring systems, systems of static and dynamic analysis, systems of transformation and optimization, systems of language extensions code, subsystems for syntax highlighting, systems for building documentation on the code and other similar tools on its basis.
The idea of the library appeared when our team was creating the Viva64 static code analyzer [1]. The Viva64 tool is intended for diagnosing errors in C/C++ programs related to the peculiarities of code migration on 64-bit Windows systems.
During the process of Viva64 development our team faced the absence of open libraries convenient for realization of such projects. OpenC++ (OpenCxx) library [2] was chosen as the basis and we were satisfied with our choice. But during the development of the static analyzer our team made a lot of corrections and improvements in OpenC++ library. And now when the development of the first versions of Viva64 is over we would like to offer thir-party developers our remade variant of OpenC++ library which we called VivaCore. We think that the changes we've made can help a lot to the developers who are going to begin the development of software products in the sphere of analysis or processing of C/C++ code.
The license of VivaCore library allows you to use, copy, distribute and modify it in binary form or as an original code both for commercial and non-commercial use free, without any payments to the library's authors. One should only mention the authors of the original libraries (OpenC++ and VivaCore).
You can download VivaCore here.
The main difference between VivaCore and OpenC++ is that VivaCore is a living project and it continues to gain functionality. Unfortunately, OpenC++ library hasn't been developed for a long time. The latest change in the library was in 2004. And the latest change related to support of new keywords was in 2003. This correction was an unlucky try to add wchar_t data type, which caused adding about five errors of different types.
It is evident why we introduce our own library and didn't make changes in OpenC++. We don't have enough free resources for that. A lot of modifications were carried out and it is a very difficult task to introduce all the changes into OpenC++. Many changes are of a specific type and may not fit the general ideology of OpenC++ library and that's why they will need additional adaptation. All this makes the task of OpenC++ library update very resource-intensive, and from our viewpoint unreasonable.
Let's list the key features implemented in the VivaCore library in comparison with OpenC++.
1. The classical C language is supported. A different set of tokens is used and it gives an opportunity to name the variables as 'class' or declare a function in the following old C style:
PureC_Foo(ptr)
char *ptr;
{
...
}2. Great work was carried out to support the peculiarities of C++ syntax used in the VisualStudio 2005/2008 environment. For example, the library processes keywords __noop, __if_exists, __ptr32, __pragma, __interface, etc.
3. Some new keywords and other constructions included into new language standards are supported. In particular we have added support for the register keyword and evocation of templated function with the use of the template word: object.template foo<int>();.
4. Computation of literal constants has been implemented.
5. The library is adopted and optimized for the work on 64-bit systems with the help of Viva64 code analyzer.
6. A lot of errors and defects are corrected. An example is support for string literals separated by space (const wchar_t *str = L"begin" L"end") or divided into two strings by a slash:
const char *name = "Viva\
Core";Another example is correct processing of expressions like "bool r = a < 1 || b > (int) 2;" which are treated as templates by OpenC++.
And so on.
7. The mechanism of primary preprocessing of the original text is created. This helps to implement some specific code modifications.
In the nearest future we are planning to implement the following features in the VivaCore library:
its own preprocessor (on the basis of The Wave C++ preprocessor library), instead of an external one (for example, Visual Studio preprocessor). This will allow avoiding some errors in positioning by code line numbers when showing the compilation errors, and also provide better control over the process of code parsing and analysis;
support for coding of complex types, which occupy more than 127 symbols in the coded form;
a simple application demonstrating the basic features of VivaCore library.
We should mention that despite all the listed differences between OpenC++ and VivaCore libraries, they have a lot in common and that's why the documentation on OpenC++ doesn't lost its relevance. Our team will try to pay attention to the documenting of VivaCore library. But as far as this documentation will cover the differences and new abilities realized in VivaCore library, it will be useful to get acquainted with the OpenC++ documentation in any case.
VivaCore library may be of interest for companies and organizations that are creating or planning to create tools for source code processing. Of course it is impossible to list all the acceptable spheres and methods of use, but we'll list some directions in order to show VivaCore from different viewpoints. In brackets we put the products related to every solution class. One shouldn't think that they are realized on the basis of VivaCore - it is just examples of solutions. So, with the help of VivaCore one can develop solutions for:
For more information on code parsing technology please see the fundamental book on compilers [3]. We also recommend you to get acquainted with principles of program analysis [4].
One shouldn't mix up VivaCore and professional multifunctional parsers for C/C++ code. If a user needs a front-end code parser with full support for the modern C++ language standard, which allows creating his own compiler for a specific platform, he should pay attention to GCC or other expensive commercial solutions. For example, such solutions are offered by Semantic Designs [5].
But if a company develops a tool requiring classical analysis of C/C++ code, then the rational solution is the use of a convenient and open source library, that is of VivaCore.
Before we begin to speak about VivaCore library in details, let's recollect some terms which will be used during the description.
Preprocessing - a mechanism browsing the incoming ".c/.cpp" file, executing preprocessor's directions in it, including the content of other files pointed in #include directions into it etc. As a result, a file appears which doesn't contain preprocessor's directions, all the used macros are open, instead of #include directions the content of the corresponding files is placed. The file containing preprocessing results usually has the ".i" suffix. The result of preprocessing is called a translation unit.
Syntax analysis (parsing) - the process of analysis of the incoming sequence of symbols to parse the grammatical structure. Usually syntax analysis is divided into two levels: lexical analysis and grammatical analysis.
Lexical analysis - the procedure of incoming sequence of symbols processing to get the sequence of symbols called lexemes (or "tokens") at the output. Each lexeme can be presented as a structure containing the lexeme type and, if necessary, the corresponding meaning.
Grammatical analysis (grammatical parsing) - the process of comparison of the linear sequence of lexemes (words, tokens) of the language with its formal grammar. The result is usually the derivation tree or the abstract syntax tree.
Abstract Syntax Tree (AST) - a finite, marked, oriented tree in which the inner nodes correspond to the programming language operators, and the leaves to the corresponding operands. So, the leaves are empty operators and they are just variables and constants. The AST differs from the Derivation Tree (DT) in that way that there are no nodes for those syntax rules which don't influence the program's semantics. The classical example of such absence is the grouping brackets, as in the AST the grouping of operands is defined by the tree structure explicitly.
Metaprogramming - development of programs which create other programs as the result of their work or change and complement themselves during execution. In the VivaCore library metaprogramming is the possibility of extending the syntax and functionality of C/C++ language with the purpose of creating one's own programming language. Metaprograms created on this programming language may be then translated into C/C++ code with the use of VivaCore and compiled by an external compiler.
Tree traversal - traversal of all the nodes and leaves of the syntax tree to gather information of different kinds, analyze and modify the tree.
The general functional structure of VivaCore library is shown on figure 1. At this moment the library is intended for the full integration with the user's application and is represented as a set of original source code.
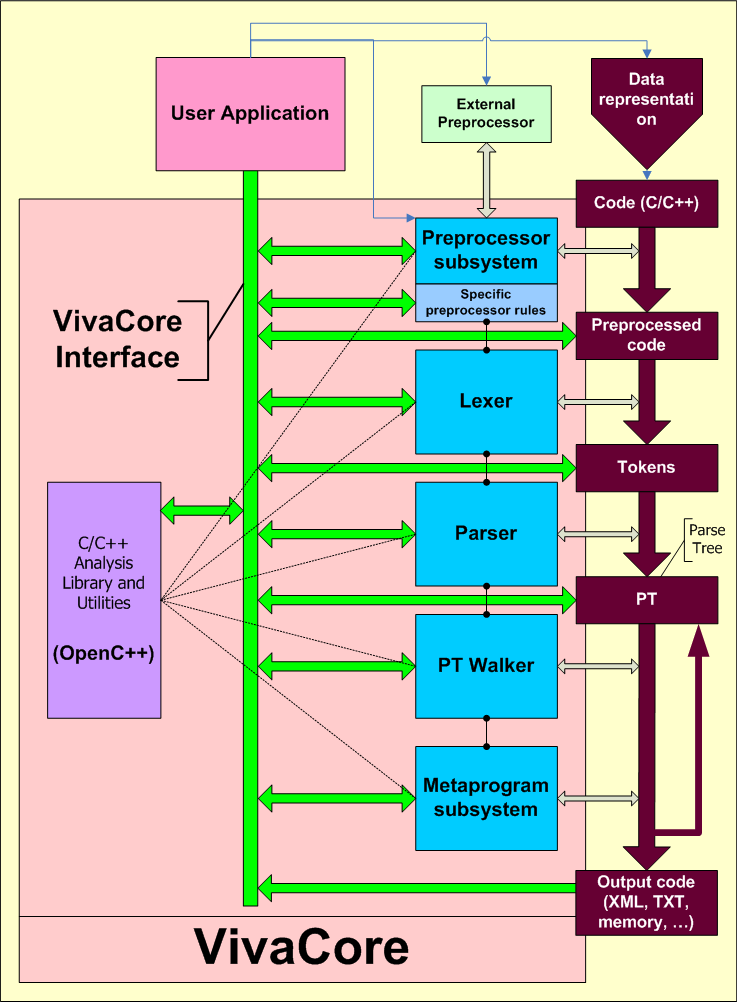
Figure 1. General functional structure of VivaCore library.
We suggest you examine the library's functional blocks in the order in which they process the incoming original source code as it is shown on figure 2. We'll see what actions a functional block performes, what information it allows to get and how it can be modified for specific purposes.
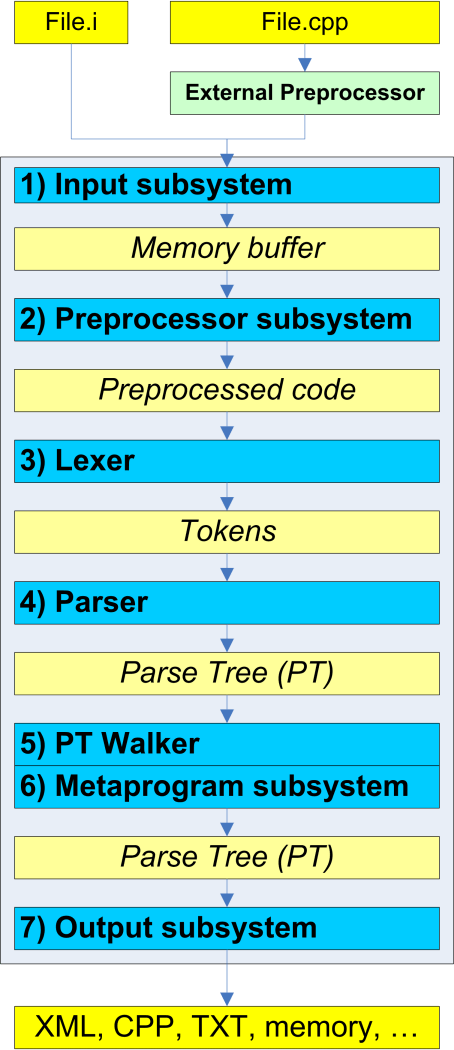
Figure 2. The sequence of code processing.
VivaCore library may correctly process only the original C/C++ code processed by the preprocessor. Further, the possibility of using the preprocessor from The Wave C++ preprocessor library is taken into consideration, but it won't be implemented in the first version of the VivaCore library. To get a preprocessed file one may use a compiler (for example, Microsoft Visual C++) and get a processed file which usually has the "i" extension.
In particular cases unprocessed C/C++ files may be input, but in this case one should work with VivaCore not further than on the level of splitting the file into lexemes. This will be enough for calculating metrics or for other purposes. But one shouldn't try to build and analyze the Parse Tree, because the result, most probably, will be unsuitable for processing.
Having the preprocessed code, the user may transfer it to the input subsystem as a file or memory buffer. The purpose of the input subsystem is to arrange the data in the inner structures of VivaCore library. The input system also takes configuration data, which states which libraries should be treated as system and which libraries should be treated as user's ones.
See in the code: VivaConfiguration, ReadFile.
We would like to point out that this subsystem doesn't provide code preprocessing in its classical meaning. As it has been mentioned before, it is the preprocessed code that should be input into VivaCore library. The subsystem under consideration designed for the following tasks:
See in the code: VivaPreprocessor, CreateStringInfo, IsInterestingLine, GetLineNumberByPtr, PreprocessingItem, SkipUninterestingCode.
So, we've come to those levels of data processing which are of practical interest for developers. Having parsed the code into lexemes, the user has an opportunity to calculate metrics, implement a specific algorithm of syntax highlighting in different applications.
VivaCore lexical analyzer parses the source code into a set of objects of Token type (see the Token.h file) which contain information about the lexeme type, its location in the program text and its length. The lexeme types are enumerated in the tokennames.h file. Examples of lexeme types:
CLASS - "class"-keyword
WCHAR - "wchar_t"-keyword
The user can extend the set of lexemes if necessary. It may be needed when it is necessary to support the specific syntax of a specific language imlementation or when developing one's own language extension.
When adding lexemes it is necessary to define them in the tokennames.h file and add them into the "table" or "tableC" tables in Lex.cc file. The former table is intended for processing of C++ files and the latter is for C files. This is natural, as the set of lexemes in C and C++ languages is different. For example, there is no CLASS lexeme in C language, because the word "class" is not a keyword in C and can indicate a name of a variable.
When you add new lexemes you should not forget to modify the isTypeSpecifier, optIntegralTypeOrClassSpec and other functions. We recommend you perform search for a keyword which has similar meaning and modify all the fragments of VivaCore code in which the keyword occurs.
The set of lexemes can be represented both as a simple array and as a file. Lexemes are kept in the tokens_array in the Lex class. You can either get the entire array or separate lexemes using the GetToken, LookAhead, CanLookAhead functions.
The user can get lexemes in unstructured text form or in the following formatted form using the DumpEx function:
|
Lexeme Type |
Lexeme |
Lexeme Length |
|---|---|---|
|
258 |
lc_id |
5 |
|
91 |
[ |
1 |
|
262 |
6 |
1 |
|
93 |
] |
1 |
|
59 |
; |
1 |
|
303 |
struct |
6 |
|
123 |
{ |
1 |
|
282 |
char |
4 |
|
42 |
* |
1 |
|
258 |
locale |
6 |
The user can also export the lexemes in XML file format.
See in the code: Token, Lex, TokenContainer.
The parser is intended for building the derivation tree that may be further subjected to analysis and transformation. Pay attention that the parser of VivaCore library builds not an abstract syntax tree but just the derivation tree. This allows user to implement support for metaprogram constructions, which may be added by the user into C or C++ language. If the user will urgently need to work just with the abstract syntax tree, we hope it won't be difficult to improve the analyzer so that it could traverse the whole derivation tree and remove nodes and leaves that are not used in abstract syntax.
Building of the tree in VivaCore library is performed in functions of the Parser class. Nodes and leaves of the tree are objects whose classes were inherited from the NonLeaf and Leaf base classes. A partial hierarchy of classes used to present the tree is shown on figure 3.
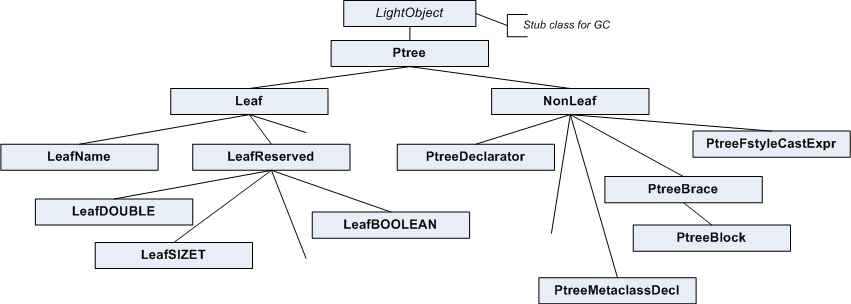
Figure 3. A part of hierarchy of classes used for building the derivation tree.
As it is seen from the figure, Ptree class is a base for all the others and serves as a single interface to work with other classes. The Ptree class contains a set of virtual functions which should be implemented in descendant classes. For example, the "virtual bool IsLeaf() const = 0;" function is implemented in the NonLeaf and Leaf classes. Actually the classes implement only this function and they are designed to make the hierarchy of classes more logical and nice.
As far as the work with the tree occupies a significant part of the library, Ptree has a large set of functions to work with the tree nodes. These functions are presented as analogs of list proressing functions in the Lisp language. Here are some of them: Car, Cdr, Cadr, Cddr, LastNth, Length, Eq.
To get the general idea of the parser's workflow let's examine a derivation tree which will be built from the following code:
int MyFoo(const float value)
{
if (value < 1.0)
return sizeof(unsigned long *);
return value * 4.0f < 10.0f ? 0 : 1;
}Unfortunately, it is impossible to show the entire derivation tree, that's why we'll show it in parts on figures 4.1-4.4.
Figure 4.1. Color indication of the semantic tree nodes.
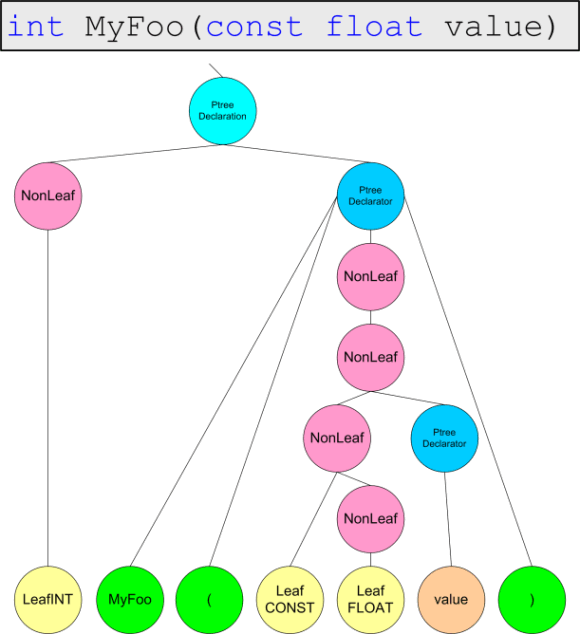
Figure 4.2. Presentation of the function header.
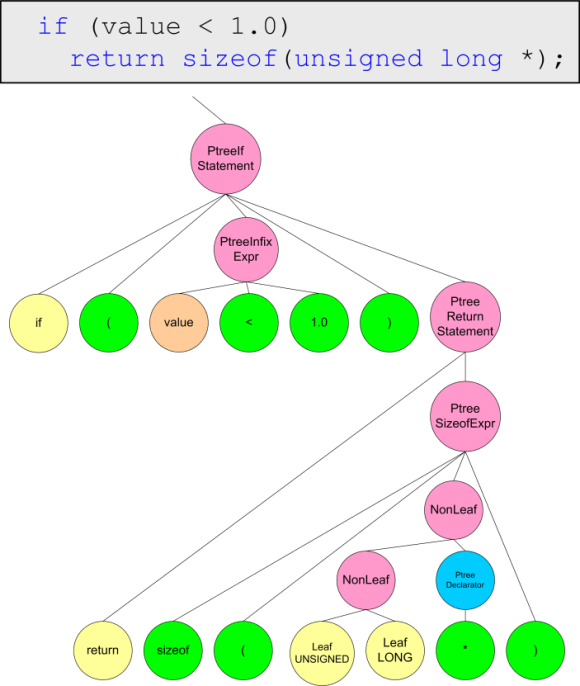
Figure 4.3. Presentation of the function body.
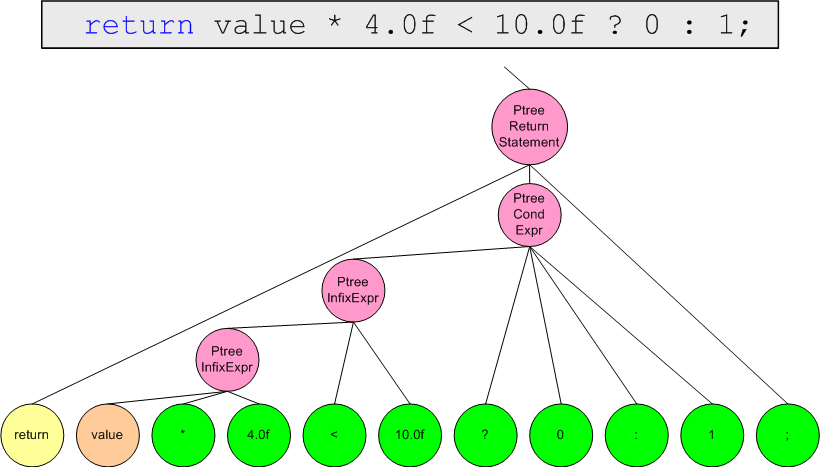
Figure 4.4. Presentation of the function body.
We should mention one more important component of the analyzer's work. This is the gathering of information about types of various objects (functions, variables etc), that is performed in the Encoding class. Information about a type is represented in the form of a specifically coded string. You may examine the format of this string in the Encoding.cc file. The library also contains a special class, TypeInfo. This class allows getting and modifying types information. For example, it is easy to identify the type of the processed element using functions like IsFunction, IsPointerType, IsBuiltInType.
The addition of new types of nodes and leaves is a difficult task and cannot be observed in this overview. The rational solution is to choose one of the classes, for example, the PtreeExprStatement class and examine all the places in the code where instances of this class are created, processed, and so on.
The tree that we finally get may be saved in a ".c /.cpp" file, but it is pointless. It will be reasonable after changing the derivation tree that can take place on the following steps. By saving the tree as a program source code at the moment we'll have the same code that we had on the input. However, this might be useful for testing changes introduced into lexer and parser.
The possibility to save the tree for further processing in any user-implemented format is more interesting. An example is the following textual presentation of the program code, described earlier:
PtreeDeclaration:[
0
NonLeaf:[
LeafINT:int
]
PtreeDeclarator:[
Leaf:MyFoo
Leaf:(
NonLeaf:[
NonLeaf:[
NonLeaf:[
LeafCONST:const
NonLeaf:[
LeafFLOAT:float
]
]
PtreeDeclarator:[
Leaf:value
]
]
]
Leaf:)
]
[{
NonLeaf:[
PtreeIfStatement:[
LeafReserved:if
Leaf:(
PtreeInfixExpr:[
LeafName:value
Leaf:<
Leaf:1.0
]
Leaf:)
PtreeReturnStatement:[
LeafReserved:return
PtreeSizeofExpr:[
Leaf:sizeof
Leaf:(
NonLeaf:[
NonLeaf:[
LeafUNSIGNED:unsigned
LeafLONG:long
]
PtreeDeclarator:[
Leaf:*
]
]
Leaf:)
]
Leaf:;
]
]
PtreeReturnStatement:[
LeafReserved:return
PtreeCondExpr:[
PtreeInfixExpr:[
PtreeInfixExpr:[
LeafName:value
Leaf:*
Leaf:4.0f
]
Leaf:<
Leaf:10.0f
]
Leaf:?
Leaf:0
Leaf::
Leaf:1
]
Leaf:;
]
]
Leaf:}
}]
]This format is shown only as an example. In practice you are likely to save more information and in a more convenient format - for example, the XML format.
See in the code: Parser, Ptree, Leaf, NonLeaf, Encoding, TypeInfo, Typeof, PtreeUtil.
The step of the tree traversal which is implemented in the Walker, ClassWalker, ClassBodyWalker classes is the most interesting for those who develop static code analyzers (see the [6] book for detailed introduction in this sphere) or systems for building documentation on source code. The tree traversal may be performed several times. This allows creating systems for source code modification in several traversals or providing analysis considering the information gathered in previous tree traversals.
The Walker class is designed for traversing basic C/C++ constructions.
The ClassWalker class is inherited from the Walker class and adds functionality concerning the specific features of classes, presented in the C++ language.
When it is necessary to traverse the class body, objects of the ClassBodyWalker class are created and used for a short time.
If no changes are introduced into the VivaCore library all the tree elements will be simply traversed. The tree won't be changed.
If a user implements functionality that will modify tree nodes the library may rebuild the tree. As an example, let's examine the code translating unary operations:
Ptree* ClassWalker::TranslateUnary(Ptree* exp)
{
using namespace PtreeUtil;
Ptree* unaryop = exp->Car();
Ptree* right = PtreeUtil::Second(exp);
Ptree* right2 = Translate(right);
if(right == right2)
return exp;
else
return
new (GC_QuickAlloc)
PtreeUnaryExpr(unaryop, PtreeUtil::List(right2));
}Please note that if the tree is changed while translating the expression staying on the right of the unary operation, the node of the unary operation will be changed (rebuilt) as well.
To make it clearer, let's examine this example in details.
The processing of the node that corresponds to a unary operation over some expression and that has PtreeUnaryExpr type begins. The first element in the list that is extracted with the help of exp->Car() operation, is the unary operation itself. The second element extracted with the help of PtreeUtil::Second(exp) is the expression with which the unary operation is performed.
The translation of the expression is performed and the result is assigned to the right2 variable. If this address differs from the current one it means that the expression was changed. In this case a new object of the PtreeUnaryExpr type is created. This object will be returned by the TranslateUnary function. Otherwise nothing was changed and the function returns the object, which was on the input.
If the user needs to gather information while traversing the tree or modify the tree, it is natural that the corresponding new classes should be inherited from the ClassWalker and ClassBodyWalker classes.
Let's examine an example taken from the Viva64 static analyzer where specialized analysis takes place while passing the "throw" operator.
Ptree* VivaWalker::TranslateThrow(Ptree *p) {
Ptree *result = ClassWalker::TranslateThrow(p);
Ptree* oprnd = PtreeUtil::Second(result);
if (oprnd != NULL) { //if oprnd==NULL then this is "throw;".
if (!CreateWiseType(oprnd)) {
return result;
}
if (IsErrorActive(115) &&
!ApplyRuleN10(oprnd->m_wiseType.m_simpleType))
{
AddError(VivaErrors::V115(), p, 115);
}
}
return result;
}In the beginning the ClassWalker::TranslateThrow(p) method call performs standard node translation. After that the necessary analysis is performed. Simple and elegant.
Speaking about the tree traversal, we should also mention a very important class, the Environment class, which gathers information on types of various objects in different scopes.
Here is an example demonstrating usage of the Environment class represented by the env object, for getting the type of the declTypeInfo object:
TypeInfo declTypeInfo;
if (env->Lookup(decl, declTypeInfo)) {
...
}See in the code: AbstractTranslatingWalker, Walker, ClassWalker, ClassBodyWalker, Class, Environment, Bind, Class, TemplateClass.
Metaprogramming is based on the approach to code generation when the program code is not written manually but is generated by a generating program on the basis of another, simpler program. This approach becomes reasonable if various additional rules are produced during development (high-level paradigms, fulfillment of the requirements of external libraries, stereotype ways of realization of particular functions). At this point, a part of the code loses its substantial sense and becomes just a mechanical fulfillment of the rules. When this part becomes considerable, a thought may appear to define only the substantial part manually and let all the rest be added automatically. This is the purpose of the generator.
Sometimes this generator is necessary for translation of an invented language into C/C++ operators. VivaCore has a mechanism for convenient creation of C/C++ extensions on the basis of metaobjects. It is possible to change or build new syntax trees in order to save them into C/C++ code.
You may get acquainted with the metaprogramming paradigm and ways of using metaobjects in detail in the documentation on OpenC++ library.
See in the code: Metaclass.
As it has already been said, you can save the necessary information on any step of the original source code processing inside VivaCore library. We have also mentioned that the derived and changed derivation tree may be saved in the form of source code or in any other format. So, we won't repeat it once more. It is also clear that one may gather the necessary information, for example during static analysis or calculation of metrics in different ways and that's why it's senseless to enumerate the means of implementation.
Let's say only some words about the use of XML format that was mentioned more than once in this article. XML is a textual format intended for keeping of structured data, for exchange of information between programs and different subsystems of information processing. XML is a simpler subset of SGML language.
We use XML for exporting various information hoping that it will make it easier for third-party developers to use VivaCore in their program developments in other programming languages. For example, it will be very convenient for C# programs. And what is not less important, XML as a data format make it simpler to structure the information and present it in a form familiar to a programmer.
We understand that after reading this article the number of new questions which may appear, is greater than the number of answers received. But the good news is that our Viva64.com team is always ready to communicate, to discuss appearing questions and give recommendations on the use of VivaCore. Write us!
0
0
0
0