
Our website uses cookies to enhance your browsing experience.

The main purpose of the static analyzer is to detect and report errors in code - so that you can fix them afterwards. However, reporting errors is not as simple as it may seem. Those just starting out to work with static analysis - and even experienced developers - may encounter a number of problems. In this article I'll talk about these problems and how to deal with them.

Static analysis is a technology that allows to find errors and potential vulnerabilities in the source code without actually executing it. Here's an example of how this works. Not so long ago the world welcomed the LLVM 13.0.0 release, and we checked it for errors. And - sure enough - we found curious errors in this project. Here's one of them:
bool operator==(const BDVState &Other) const {
return OriginalValue == OriginalValue && BaseValue == Other.BaseValue &&
Status == Other.Status;
}The analyzer issues the following warning to the code above:
[CWE-571] There are identical sub-expressions to the left and to the right of the '==' operator: OriginalValue == OriginalValue RewriteStatepointsForGC.cpp 758
As you can see, someone made a typo in the first comparison - and wrote OriginalValue instead of Other.OriginalValue. That's a classic error in comparison methods. And it can lead to different and unpleasant results.
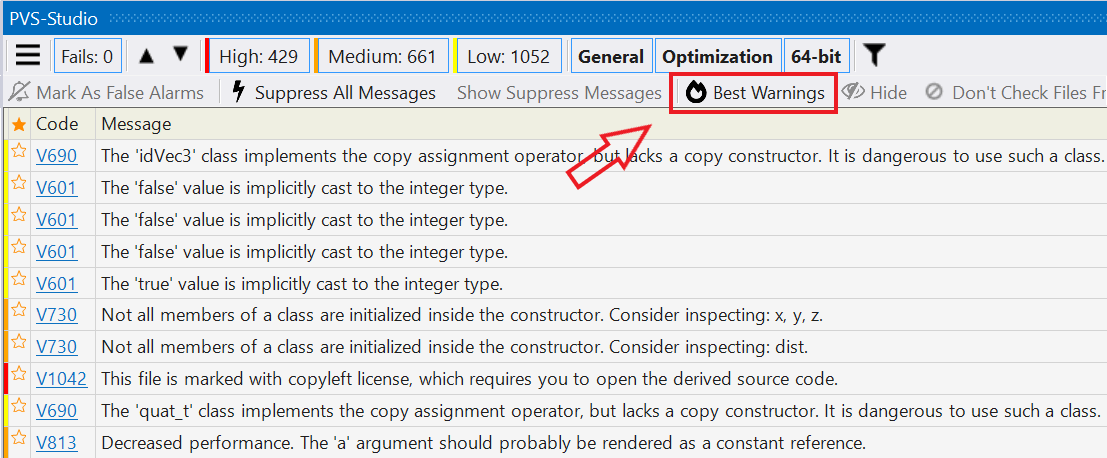
So, suppose you found out that there is a thing called static analysis and decided to try it. You download this tool, start the analysis for your project and get a result that looks approximately like this:
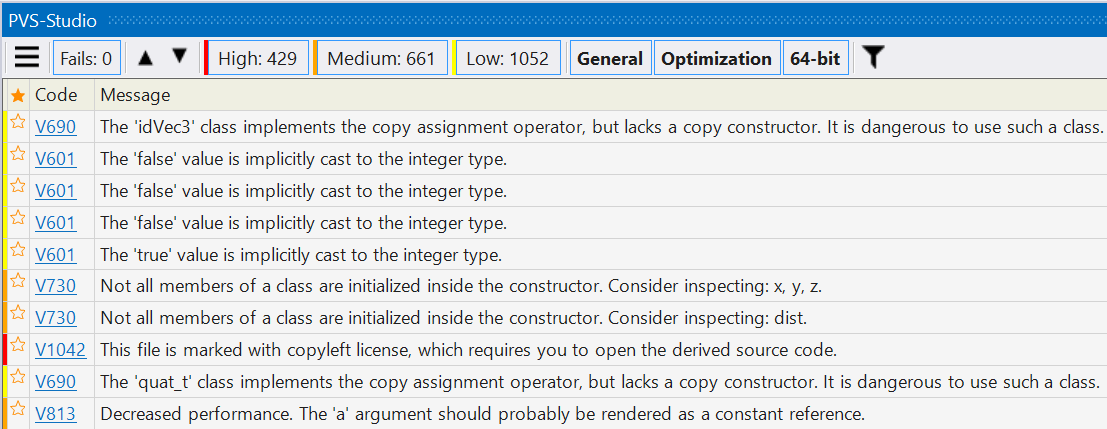
This is the PVS-Studio plugin's window in Visual Studio 2022. The window contains a set of buttons at the top, and also displays a list of warnings. What the warnings say is irrelevant right now. I want to point your attention to something else - the number of the warnings shown:
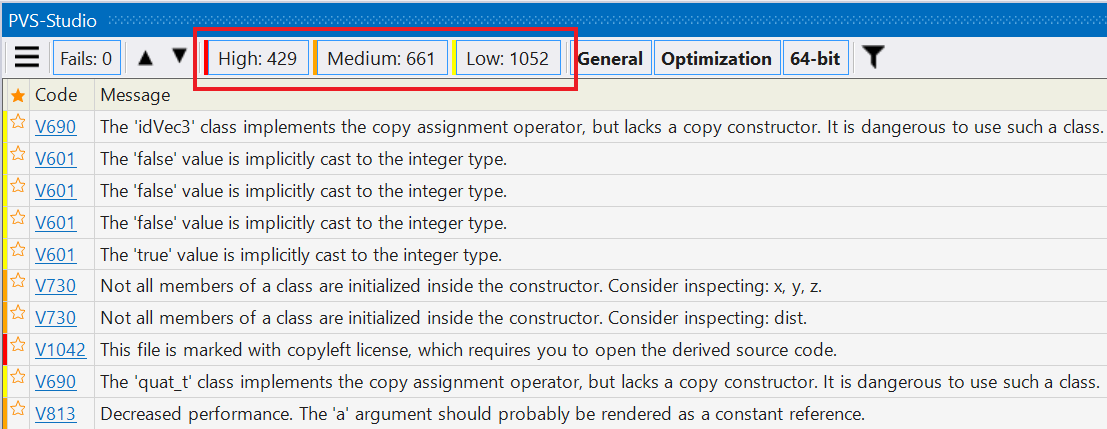
And that's where the first problem lies - the number of warnings. In this example, there are over 2000 of them. That's a lot! When someone is just testing the waters, they do not want to go through so many warnings - it's tedious to do so. Meanwhile, that list may contain a warning about a major and very real error that can shoot you in the foot in the near future and force you to spend lots of time, energy and brain cells to fix it.
Well, suppose you decide to look through that long list after all. And here you'll face problem number two - identical warnings:
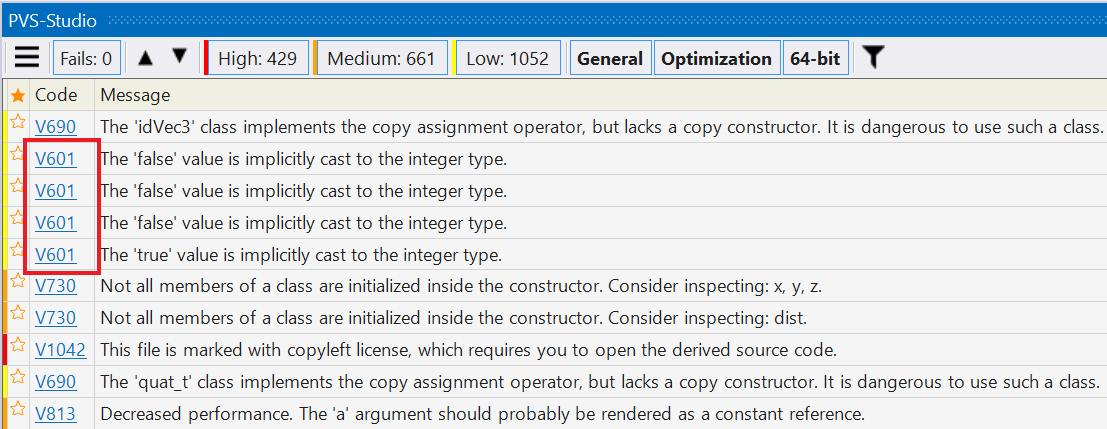
From the analyzer's perspective, everything is fine. It found many identical errors in the code and reports just that. However, right now we are talking about the first time someone uses the analyzer. What they want - is to see diversity. Looking at 4 identical warnings is uncool.
Now it's time for the third problem - and the most significant one. False positives. A false positive is a warning that reports code that does not contain an error.
Suppose the first ten warnings are false positives and the other warnings are legitimate and helpful. The person starts out looking through the warnings one by one, sees these 10 false positives, concludes this list is nonsense, and closes the report. All this while warning number 11 is an error we described at the beginning - the one that shoots you in the foot when you least expect it.
To solve the problems described above I would like to offer you a good old approach with weights. See, the static analyzer has diagnostic rules. Each responds to a specific error pattern. So first, you sit down, analyze all the diagnostics and set their initial weight. The best diagnostics get more weight, the worst ones - less weight. What's a best diagnostic? This is a diagnostic characterized by one of the following: it has the lowest chance of producing a false positive, detects a serious error, or is very peculiar. That's upon you.
However, just assigning a weight is boring. Let's take it a step further. After you record all the errors for a project, you can, for example, change these weights in some way. I'll highlight several criteria here:
To make this clearer, I'll use an example. Here's how we implemented this mechanism - we called it Best Warnings - at PVS-Studio. I'll start from the beginning.
This weight change is based upon some initial system that groups warnings. For example, we break our diagnostics up into three groups: High, Medium, and Low. High stands for the most reliable warnings, we do not alter their weight. The Medium group contains warnings of the average reliability. To these, we apply a coefficient that lowers their weight.
This group includes warnings issued for tests or autogenerated files. Sometimes the analyzer finds real errors in tests, and that's very cool. However, in most cases, warnings issued for such code are false positives because of the specifics of such code. This is why warnings for tests are better left for later. There's no need to show them to someone just starting out with an analyzer.
Sometimes one line of code triggers several diagnostics. Experience shows that such lines usually do contain an error. Consequently, it's logical to add weight for such warnings.
If a diagnostic's triggerings take up more than N% of all warnings, this usually means the diagnostic's warnings of a fairly low value. Such response is usually related to a coding style or to carelessly written macros in C or C++ code.
All categories described above solve problem number three. To address the second problem and get a variety of warnings, you need to take a diagnostic's all warnings and find the heaviest one among them. Leave its weight unchanged and decrease the weight of the remaining ones. Do the same for each diagnostic. As a result, you get a variety of warnings.
Now only the first problem remains - there are too many warnings. To address this, sort all problems by weight and show the N number of the heaviest ones. This way, you analyze the report instead of your clients and provide them the very essence of what the analyzer found.
Our Visual Studio plugins now contain a button that you can click to execute all of the above. It runs a script we created. Let's get back to the example above and run it through this mechanism:
Here's the report. Now, instead of examining it at once, we click two buttons. One:
And two:
After this, the report looks as follows:
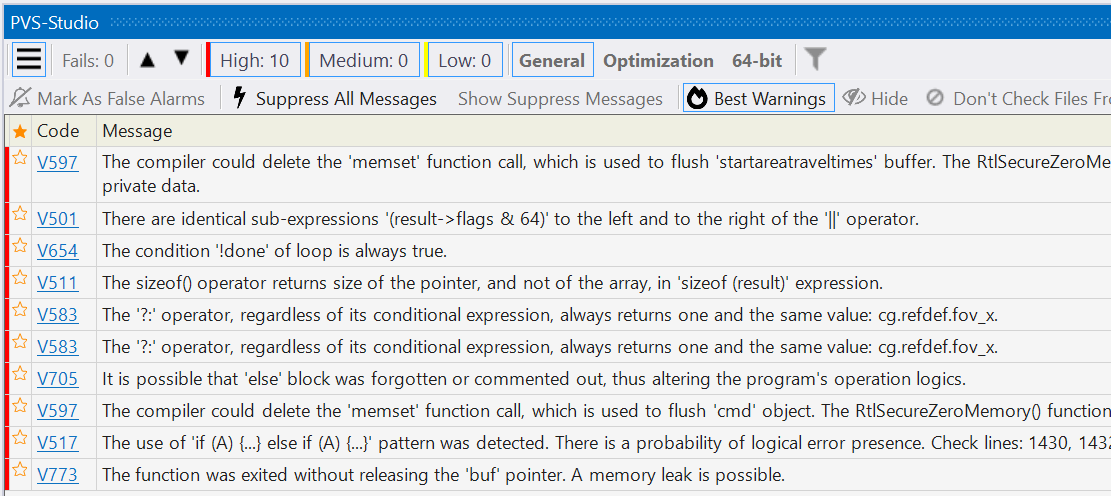
As you can see, only 10 warnings remain. They are much easier to go through than 2000 :)
We have also made sure that the list contains a variety of warnings. You can see a diversity of diagnostic codes and we decided to allow no more than 2 of the same warnings.
Taking into account all of the above, the weight mechanism solves a number of problems at once. Looking through the first report is easier, because the volume of warnings is reduced and becomes convenient to examine. The warnings become more reliable and diverse. Clients save time and can evaluate the tool faster. For example, it took me only about 10-15 minutes to install the analyzer and view the warnings.
Feeling curious? Click here to see how it works in real life!
Thank you for reading!
0
0
0
0