
Our website uses cookies to enhance your browsing experience.

Spoiler: C++ isn't faster or slower — that's not the point, actually. This article continues our good tradition of busting myths about the Rust language shared by some big-name Russian companies.
Note. The article was published on Habr.com. We translated and published the article with the copyright holder's permission. Since you are here, you might be interested in another guest article: Criticizing the Rust Language, and Why C/C++ Will Never Die. If you don't want to miss new entertaining articles on our blog — subscribe to PVS-Studio newsletter.
The previous article of this series is titled "Go is faster than Rust: benchmarked by Mail.Ru (RU)". Not so long ago, I tried to lure my coworker, a C-programmer from another department, to Rust. However, I failed, and here's why:
In 2019, I was at the C++ CoreHard conference, where I attended Anton @antoshkka Polukhin's talk on how indispensable C++ is. According to him, Rust is a young language, and it's not that fast and even not that secure.
Anton Polukhin is a representative of Russia at the C++ Standardization Committee and an author of several proposals that have been accepted into the C++ standard. He is indeed a prominent figure and authority on all things related to C++. But his talk had a few critical factual errors regarding Rust. Let's see what they are.
{{PROMO_POPULAR}}
The part of Anton's presentation (RU) that we are particularly interested in is 13:00 through 22:35.
To compare assembly outputs of the two languages, Anton picked the square function (link:godbolt) as an example:

Anton (13:35):
We get the same assembly output. Great! We've got the baseline. Both C++ and Rust produce the same output so far.
Indeed, the assembly listing of the arithmetic multiplication looks the same in both cases, but only for now. The problem is that the both of the code fragments above do different things from a semantic point of view. Sure, they both implement a square function, but for Rust the applicable range is [-2147483648, 2147483647], while for C++ it's [-46340, 46340]. How come? What kind of sorcery is this?
The magic constants (-46340 and 46340) are the largest absolute-value arguments. Their squares fit into the std::int32_t type. Anything above that would lead to undefined behavior due to the signed integer overflow. If you don't believe me, ask PVS-Studio. If your team has configured CI to check code for undefined behavior, you get the following message:
runtime error:
signed integer overflow: 46341 * 46341 cannot be represented in type 'int'
runtime error:
signed integer overflow: -46341 * -46341 cannot be represented in type 'int'In Rust, the issue of undefined behavior in arithmetic like that is literally impossible.
Let's see what Anton has to say about it (13:58):
Undefined behavior occurs because we have a signed value, and the C++ compiler assumes that signed integer values don't overflow because that would be undefined behavior. The compiler relies on this assumption to make a series of tricky optimizations. In Rust's compiler, this behavior is a documented one, but it doesn't make your life any easier. You'll get the same assembly code anyway. In Rust, it's a documented behavior, and multiplying two large positive numbers produces a negative one, which is probably not what you expected. Moreover, documenting this behavior prevents Rust from applying lots of its optimizations – they are actually listed somewhere on their website.
I'd like to learn more about optimizations that Rust can't do. Especially considering that Rust is based on LLVM, which is the same backend that Clang is based on. So, Rust has inherited "for free" and shares the most of the language-independent code transformations and optimizations with C++. The fact that the assembly listings are identical in the example above is actually just a coincidence. Due to signed overflows in C+, tricky optimizations and undefined behavior can be a lot of fun to debug. They also inspire articles like this one (RU). Let's take a closer look at it.
We have a function that computes a polynomial hash of a string with an integer overflow:
unsigned MAX_INT = 2147483647;
int hash_code(std::string x) {
int h = 13;
for (unsigned i = 0; i < 3; i++) {
h += h * 27752 + x[i];
}
if (h < 0) h += MAX_INT;
return h;
}For some strings — for "bye" in particular — and only on the server (interestingly enough, on my friend's computer everything was fine), the function would return a negative number. Why, though? If the value is negative, add MAX_INT to it to make it positive.
Thomas Pornin shows that undefined behavior is really undefined. If you raise 27752 to the power of 3, you'll see why a two-letter hash is counted correctly, while a three-letter hash is counted with some strange results.
The similar function written in Rust works correctly (link:playground):
fn hash_code(x: String) -> i32 {
let mut h = 13i32;
for i in 0..3 {
h += h * 27752 + x.as_bytes()[i] as i32;
}
if h < 0 {
h += i32::max_value();
}
return h;
}
fn main() {
let h = hash_code("bye".to_string());
println!("hash: {}", h);
}Due to the well-known reasons, this code executes differently in Debug and Release modes, and if you want to unify the behavior, you can use these function families: wrapping*, saturating*, overflowing*, and checked*.
As you can see, the documented behavior and the absence of undefined behavior due to signed overflows make life easier.
Squaring a number is a perfect example of how you can shoot yourself in the foot with just three C++ lines. At least you can do it in a fast and optimized way. While you still can avoid uninitialized memory access errors by carefully checking your code, arithmetic-related bugs appear out of the blue in "purely" arithmetic code, and there's nothing to break at first glance.
The following code is offered as an example (link:godbolt):

Anton (15:15):
Both Rust compiler and C++ compiler have compiled the application and... the bar function does nothing. Both compilers have issued warnings that something might be wrong. What am I getting at? When you hear somebody say Rust is a super cool and safe language, just know that the only safe thing about it is object lifetime analysis. UB or documented behavior that you might not expect is still there. The compiler still compiles the code that obviously doesn't make sense. Well... it's just it.
We are dealing with infinite recursion here. Again, both compilers produce the same assembly output, i.e. both C++ and Rust generate NOP for the bar function. Although, this is actually an LLVM bug.
If we derive the LLVM of the IR code with an infinite recursion, we can see the following (link:godbolt):
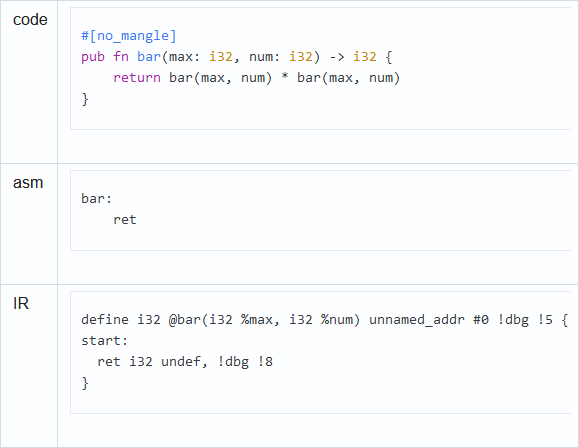
ret i32 undef is the bug generated by LLVM.
The bug has been present in LLVM since 2006. It's an important issue as you want to be able to mark infinite loops or recursions in such a way as to prevent LLVM from optimizing it down to nothing. Fortunately, things are improving. LLVM 6 was released with the intrinsic llvm.sideeffect added, and in 2019, rustc got the -Z insert-sideeffect flag, which adds llvm.sideeffect to infinite loops and recursions. Now infinite recursion is recognized as such (link:godbolt). Hopefully, the developers will soon add this flag as a default one for stable rustc as well.
In C++, infinite recursion or loops without side effects are considered undefined behavior, so this LLVM bug affects only Rust and C.
Now that we've cleared this up, let's address Anton's key statement: "The only safe thing about it is object lifetime analysis." This is a false statement because the safe subset of Rust enables you to eliminate errors related to multithreading, data races, and memory shots at compile-time.
Anton (16:00):
Let's take a look at more complex functions. What does Rust do with them? We've fixed our bar function so that it calls the foo function now. You can see that Rust has generated two extra instructions: one pushes something onto the stack and the other pops something from the stack at the end. No such thing happens in C++. Rust has taken the memory twice. That's not good.
Here's an example (link:godbolt):
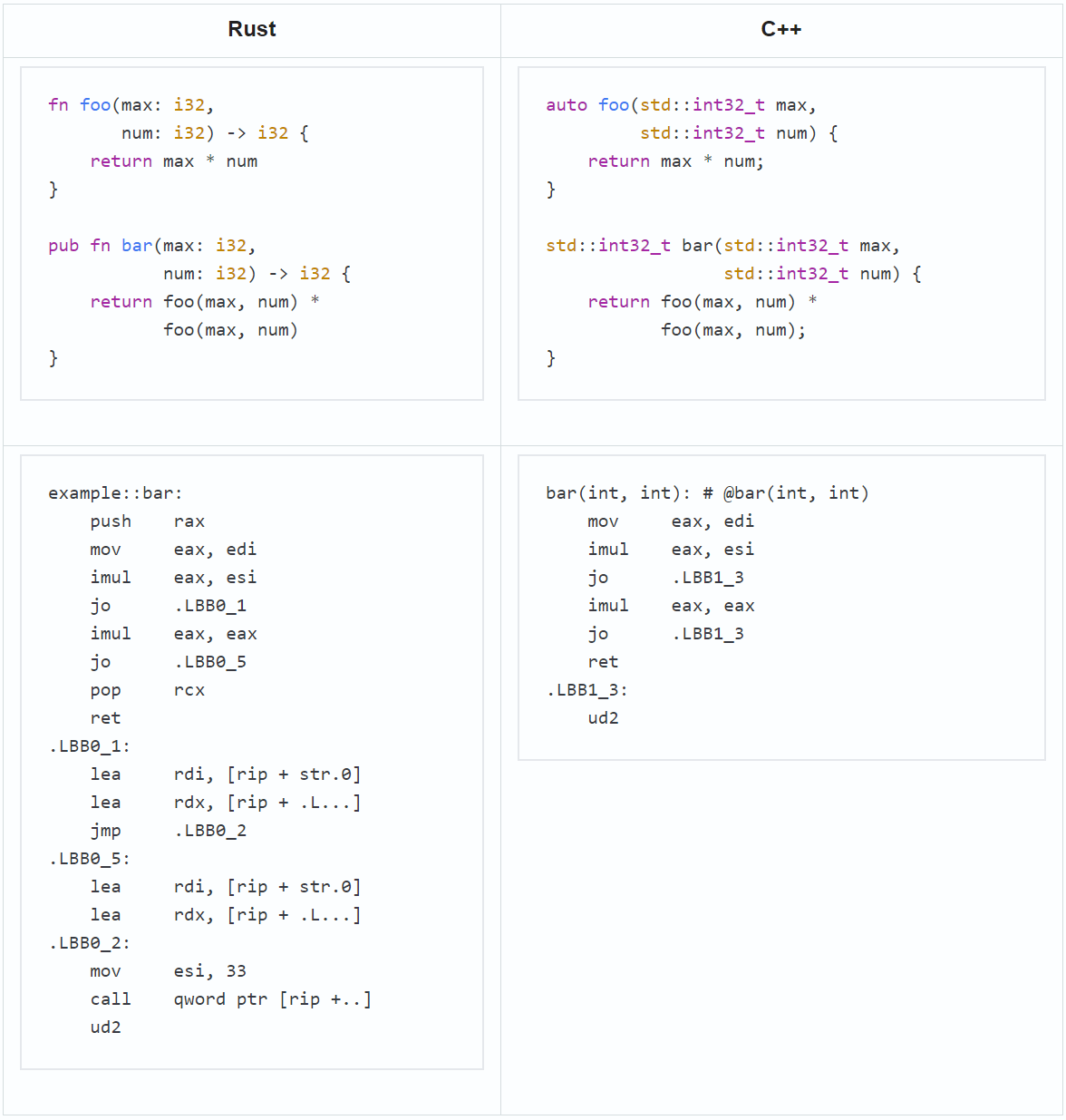
The assembler output for Rust is long, but we'll get to the bottom of this difference. In the example above, Anton uses the -ftrapv flag for C++ and -C overflow-checks=on for Rust to enable the signed overflow check. If an overflow occurs, C++ jumps to the ud2 instruction, which leads to "Illegal instruction (core dumped)", while Rust jumps to the call of the core::panicking::panic function, preparation for which takes half the listing. If an overflow occurs, core::panicking::panic outputs a nice explanation of why the program has crashed:
$ ./signed_overflow
thread 'main' panicked at 'attempt to multiply with overflow',
signed_overflow.rs:6:12
note: run with `RUST_BACKTRACE=1` environment variable to display a backtraceSo, where do these "extra" memory-consuming instructions come from? The x86-64 function call convention requires the stack to be aligned to a 16-byte boundary, while the call instruction pushes the 8-byte return address onto the stack, thus breaking the alignment. To fix that, compilers push various instructions such as push rax. It's not only Rust — C++ does that as well (link:godbolt):

Both C++ and Rust have generated identical assembly listings; both have added push rbx for the sake of stack alignment. Q.E.D.
The most curious thing is that it is actually C++ that needs deoptimization. To do this, we can add the -ftrapv argument to catch undefined behavior due to signed overflows. I showed earlier that Rust works fine even without the -C overflow-checks=on flag, so you can check the cost of correct C++ code for yourself (link:godbolt) or read this article. Besides, -ftrapv is broken in gcc since 2008.
Anton (18:10):
Rust is slightly slower than C++...
Throughout his presentation, Anton is choosing Rust code examples that compile into slightly bigger assembly code. Not only the above examples that take up memory but also the one discussed at 17:30 (link:godbolt):

It looks like all this analysis of assembly output is done to prove that more assembly code means slower language.
At the 2019 CppCon conference, Chandler Carruth gave an interesting talk titled "There Are No Zero-cost Abstractions". At 17:30, he complains that std::unique_ptr is more expensive than raw pointers (link:godbolt). To get closer to the assembly output cost of raw pointers, he has to add noexcept, rvalue references, and use std::move. Well, in Rust, the above works without any additional effort. Let's compare two code snippets and their assembly outputs. I had to do some additional tweaking with extern "Rust" and unsafe in the Rust example to prevent the compiler from inlining the calls (link:godbolt):

Rust generates less assembly code with less effort. And you don't need to give any clues to the compiler by using noexcept, rvalue references, and std::move. When you compare languages, use appropriate benchmarks. You can't just take any example you like and use it as proof that one language is slower than the other.
In December 2019, Rust outperformed C++ in the Benchmarks Game. C++ has caught up somewhat since then. However, as long as you continue to use synthetic benchmarks, the languages will continue to pull ahead of each other. I'd like to take a look at adequate benchmarks instead.
Anton (18:30):
If we take a large desktop C++ application and try to rewrite it in Rust, we'll realize that our large C++ application uses third-party libraries. And a lot of third-party libraries written in C have C headers. You can borrow and use these headers in C++, wrapping them into safer constructs if possible. But in Rust, you'd have to rewrite all those headers, or have some software to generate them from the original C headers.
Here, Anton lumps together two different issues: declaration of C functions and their subsequent use.
Indeed, declaring C functions in Rust requires you to either declare them manually or have them automatically generated. That's because they are two different programming languages. You can read more on that in my article about the Starcraft bot or take a look at the example that shows how to generate wrappers.
Fortunately, Rust has a package manager called cargo that allows you to create declarations once and share them with the world. As you might guess, people share not only raw declarations but also secure and idiomatic wrappers. As of 2020, the crates.io package registry contains about 40,000 crates.
As for using a C library, it actually takes only one line in your config:
# Cargo.toml
[dependencies]
flate2 = "1.0"Cargo takes care of compiling and linking dependency versions automatically. The interesting thing about the flate2 example is that initially it used the C library miniz written in C. However, the community later rewrote the C code in Rust, which made flate2 faster.
Anton (19:14):
All Rust checks are disabled inside unsafe blocks; it doesn't check anything within those blocks and totally relies on you having written correct code.
The topic of integrating C libraries into Rust code continues here.
Unfortunately, the idea that unsafe disables all checks is a common misconception. The Rust documentation clearly says that unsafe allows you to:
Not a word about disabling all Rust checks. If you have lifetime errors, simply adding unsafe won't help your code compile. Inside that block, the compiler continues to check types, trace variable lifetimes, check thread safety, and so on and so forth. If you'd like to learn more, we recommend you reading the article "You can't "turn off the borrow checker" in Rust".
Don't treat unsafe as a way to "do what you please". This is a clue to the compiler that you take responsibility for a specific set of invariants that the compiler itself can't check. Take raw pointer dereferencing, for example. You and I know that malloc in C returns either NULL or a pointer to an allocated block of uninitialized memory, but the Rust compiler knows nothing about this semantics. That's why, when working with a raw pointer returned by malloc, don't forget to tell the compiler, "I know what I'm doing. I've checked this one — it's not a null; the memory is correctly aligned for this data type." You take responsibility for that pointer in the unsafe block.
Anton (19:25):
Out of ten bugs I've encountered in C++ programs over the past month, three were caused by incorrect handling of C methods: forgetting to free memory, passing a wrong argument, passing a null pointer without first checking for null. A large number of issues lie in using the C code. Rust also won't help you with that at all. That's not good. Rust is supposedly much safer, but once you start using third-party libraries, be as careful as you would with C++.
According to Microsoft statistics, 70% of vulnerabilities are related to memory access security violations and other classes of errors that Rust prevents at compile-time. You physically can't make those errors in the safe subset of Rust.
On the other hand, there is the unsafe subset, which allows you to dereference raw pointers, call C functions... and do other unsafe things that could break your program if misused. Well, that's exactly what makes Rust a system programming language.
At this point, you might think that if Rust and C++ both require checking whether calls to C functions are safe, then Rust isn't much better. What makes Rust unique, however, is its capability to distinguish between safe code and potentially dangerous code, and then encapsulate the latter. And if you can't guarantee correct semantics at the current level, delegate unsafe to the calling code.
This is how you can delegate unsafe upwards:
// Warning:
// Calling this method with an out-of-bounds index is undefined behavior.
unsafe fn unchecked_get_elem_by_index(elems: &[u8], index: usize) -> u8 {
*elems.get_unchecked(index)
}The standard unsafe function, slice::get_unchecked, gets an element by index without checking for the out-of-bounds error. Since we don't check the index in the get_elem_by_index function either and pass it as-is, the function is potentially dangerous. Any access to the function requires that we explicitly specify it as unsafe (link:playground):
// Warning:
// Calling this method with an out-of-bounds index is undefined behavior.
unsafe fn unchecked_get_elem_by_index(elems: &[u8], index: usize) -> u8 {
*elems.get_unchecked(index)
}
fn main() {
let elems = &[42];
let elem = unsafe { unchecked_get_elem_by_index(elems, 0) };
dbg!(elem);
}If you pass an index that is out of bounds, you'll be accessing uninitialized memory. You can do this only in unsafe.
However, we can still use this unsafe function to build a safe version (link:playground):
// Warning:
// Calling this method with an out-of-bounds index is undefined behavior.
unsafe fn unchecked_get_elem_by_index(elems: &[u8], index: usize) -> u8 {
*elems.get_unchecked(index)
}
fn get_elem_by_index(elems: &[u8], index: usize) -> Option<u8> {
if index < elems.len() {
let elem = unsafe { unchecked_get_elem_by_index(elems, index) };
Some(elem)
} else {
None
}
}
fn main() {
let elems = &[42];
let elem = get_elem_by_index(elems, 0);
dbg!(&elem);
}The safe version will never disrupt the memory, no matter what arguments you pass to it. Let's make this clear — I'm not encouraging you to write code like that in Rust at all (use the slice::get function instead); I'm simply showing how you can move from the unsafe subset of Rust to the safe subset that still guarantees security. We could use a similar C function instead of unchecked_get_elem_by_index.
Thanks to the cross-language LTO, the call of a C function can be absolutely free:

I uploaded the project with enabled compiler flags to github. The resulting assembly output is identical to the code written in pure C (link:godbolt), but is guaranteed to be as secure as the code written in Rust.
Anton (20:38):
Suppose we have a wonderful programming language called X. It's a mathematically verified programming language. If our application is written in the X language builds, then it's mathematically proven that the application has no errors in it. Sounds great indeed, but there's a problem. We use C libraries, and when we use them from that X language, all our mathematical proof obviously breaks down.
In 2018, it has been proven that the type system, borrowing, ownership, lifetimes, and multithreading mechanisms of Rust are correct. It has also been proven that if we use semantically correct code from libraries inside unsafe and mix it with syntactically correct safe code, we get semantically correct code that doesn't allow memory disruption or data races.
It means that linking and using a crate (library) that contains unsafe's but provides correct and safe wrappers doesn't make your code unsafe.
As a real-world use of the model, its authors proved the correctness of some standard library primitives, including Mutex, RwLock, and thread::spawn. All of them use C functions. So, you can't accidentally share a variable between threads without synchronization primitives in Rust; and if you use Mutex from the standard library, the variable will always be accessed correctly even though their implementation relies on C functions. Isn't it great? Definitely so.
{{PROMO_POPULAR}}
Discussing the relative advantages of one language over the other in an unbiased way is difficult, especially when you really like one language and dislike the other. It's a common thing to see a prophet of yet another "C++ killer" show up, make strong statements without knowing much about C++, and predictably come under fire.
However, from acknowledged experts, I expect a weighted observation that at least doesn't contain serious factual errors.
Many thanks to Dmitry Kashitsin and Aleksey Kladov for reviewing this article.
0
0
0
0