
Our website uses cookies to enhance your browsing experience.
Webinar: Integrating SAST into DevSecOps - 19.03

2018 year is approaching and it's time to think about new directions for development of our PVS-Studio static analyzer. At the moment, the greatest concern for us is the Java language support. In addition, we are considering the possibility of supporting IBM RPG language. It is no less interesting for us to develop the analysis of C, C++, and C# code in terms of detecting potential vulnerabilities. Also we'd like to support the analysis of C and C++ code on the macOS platform and, finally, to complete a support for compilers from Keil and IAR. Definitely, we'll not escape anywhere from the support of a MISRA standard. A lot is listed, and the next 2018 year is not enough period of time for us for to fulfill all these purposes. So, let's discuss together our plans and choose the top-priority directions.
To begin with, let me remind you about the capacities of PVS-Studio static code analyzer that have already been realized:
Supported languages and compilers:
We briefly listed what we already have. More details can be found in the documentation. Now let's see what might appear in the new versions.
PVS-Studio analyzer can identify a large number of potential vulnerabilities (weaknesses). A new version of PVS-Studio analyzer is coming soon, where the majority of warnings will correspond with identifiers according to the classification of CWE.
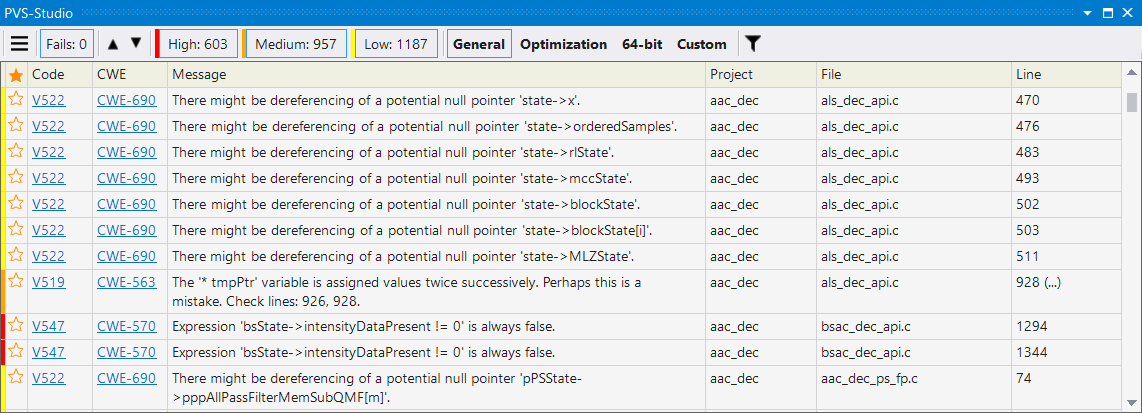
Figure N1. Column CWE is included (click on the image to enlarge).
However, this is only the first step, which we will do in the outgoing 2017. The next year with a more interesting work, related to the implementation of the search for potential vulnerabilities, is waiting for us. We're planning to make several specialized diagnostics for C, C++, and C# in this direction. For example, here is a description of one of the planned diagnostic.
I will give a description from the issues-tracker.
To begin with, we need to introduce the concept of "unreliable data". This is the data that come from outside. Examples of unreliable data:
Variable/buffer is considered to be unreliable source unless a check of values is not performed for it. Examples of checks that make data reliable (data is checked and correct):
Note 1. Whereby a check for NULL for the pointers is not considered as a check of data rightness:
char s[100];
scanf("%s", s);
if (s) // Nothing was checked here.
// The fact is that this is redundant code.
// 's' is still an unreliable buffer.Note 2. We'll need a special Data Flow mechanism for arrays and structures, which are not available in PVS-Studio yet. The fact of the matter is that the check of individual items does not make the entire buffer/structure trusted. Explanation:
unsigned char B[2];
if (B[0] < 3) // We check the first element, not the second one.
// We cannot trust the second element.
// It is needed to implement "a set of
// unchecked/checked values" for arrays.
if (B[0] < 3 && B[1] < 3) // We checked all the array.
// Now, the entire array is
// considered reliable.The most difficult thing is to think of these checks of the whole array:
int A[100];
...
for (i = 0; i < 100; ++i)
if (A[i] < 10) // we check all the array
return;When PVS-Studio begins to know about the incorrect data, it will be needed to make diagnostics, detecting their using. This will allow to detect vulnerabilities. A lot of real vulnerabilities are related to the fact that the taken byte/bytes are used without prior verification. For example, such actions are understood as the use:
Note 3. Such fucnctions as strncpy or _tcsncpy_s, (meaning function variant with 3 arguments), may form a string without a terminal null in the end. Such lines are not safe from the point of view of further functions which are waiting on input null-terminal string. For example, they cannot be passed to the strlen function.
During a couple of months we're calmly and quietly developing a Java analyzer. Unfortunately, this is happening in the background mode, because we don't have enough forces. So far it is too early to speak about it. I'd like just to note only that for Data Flow analysis we're planning to use the outputs that were implemented in the kernel of C++ analyzer.
The Java analyzer interacts with C++ core with the help of Java Native Interface (JNI). To generate the wrappers over the functions the SWIG (Simplified Wrapper and Interface Generator) is used. This lets to reuse the functionality of the C++ analyzer, as well as improve the performance.
To whet your interest, here is a couple of bugs that PVS-Studio already can identify in Java code.
JMonkeyEngine project. PVS-Studio warning: V6004 The 'then' statement is equivalent to the 'else' statement. VRMouseManager.java:139, 147
if( environment.isInVR() == false ){
Texture tex = environment.getApplication().
getAssetManager().loadTexture(texture);
mouseImage.setTexture(
environment.getApplication().getAssetManager(),
(Texture2D)tex, true);
ySize = tex.getImage().getHeight();
mouseImage.setHeight(ySize);
mouseImage.setWidth(tex.getImage().getWidth());
mouseImage.getMaterial().getAdditionalRenderState().
setBlendMode(BlendMode.Alpha);
mouseImage.getMaterial().getAdditionalRenderState().
setDepthWrite(false);
} else {
Texture tex = environment.getApplication().
getAssetManager().loadTexture(texture);
mouseImage.setTexture(
environment.getApplication().getAssetManager(),
(Texture2D)tex, true);
ySize = tex.getImage().getHeight();
mouseImage.setHeight(ySize);
mouseImage.setWidth(tex.getImage().getWidth());
mouseImage.getMaterial().getAdditionalRenderState().
setBlendMode(BlendMode.Alpha);
mouseImage.getMaterial().getAdditionalRenderState().
setDepthWrite(false);
}In the above code blocks then and else are the same. It is worth to check the code for an error, or to remove duplication.
Project RxJava. PVS-Studio warning: V6022 Expression 'idx3 > 0' is always true. JavadocWording.java:865
if (idx1 > 0 && idx2 > 0 &&
(idx3 < 0 || (idx2 < idx3 && idx3 > 0))) {
....
}Perhaps, there is no real error here, but the check idx3 > 0 is redundant. If idx2 > 0, and idx2 < idx3, then idx3 will always be greater than 0.
Not everyone knows about this language, so let's start with a brief description of it.
IBM RPG (Report Program Generator) - is a programming language whose syntax was originally similar to the command language of IBM mechanical tabulator. It was designed to facilitate the transition for engineers, serving these tabulators to the new equipment and transferring of data. It was originally implemented for the IBM 1401. It was widely used in 1960's and 1970's.

Figure 2. IBM 1401 (click on the picture to enlarge) See also Ken Ross and Paul Laughton demo the IBM 1401.
IBM continues to support language and now, as a huge amount of code is written in it, it is unprofitable to change it into other programming languages.
In RPG IV version, released in 2001, new elements of object-based programming were introduced.
A Visual RPG compiler developed by a third party vendor, provides work for Windows and GUI support. There are also implementations for OpenVMS and other, more exotic platforms.
You can read more about the language in Wikipedia: IBM RPG. In addition, we're planning to write a review article about this language.
Now we have to explain why we drew attention to this language.
One company contacted us, potentially interested in static analysis of RPG code. So we decided to look at this language, and it got us interested. As we understand a lot of code is written in this language that needs to be maintained as well as new fragments need to be added. Nevertheless, there are few specialists, familiar with this language, which makes think of additional ways to control code quality and correctness. This is the reason of the interest towards the possibility of code analysis.
We thought that analyzers for languages such as Cobol and Ada keep appearing and developing, so why not write the analyzer for RPG. Moreover, this language lacks in terms of code analyzers. For example, there is SonarRPG Analyzer, but it has only 8 diagnostics to detect errors. This definitely is not enough. I am sure we are able to offer users much more interesting diagnostics to detect various errors and typos.
We are in no hurry to take up the creation of the analyzer for IBM RPG, but we decided to make this issue public to search for potential clients. If your organization deals with IBM RPG, we'd love to communicate with you and find out your opinion about the prospects of RPG-analyzer development.
If we see that there is vivid interest towards the RPG language, we will start working in this direction in 2018.
Note. IBM RPG analyzer, if it appears, will be provided separately and will have a special price (as we know, vintage is more valuable :).

Figure 3. RPG language books are purchased (click on image to enlarge). There's only one thing standing in your way, a hero who is ready to read them.
We'd like to suggest making pre-orders and acquire licenses of the macOS version of the analyzer.
At the moment macOS version is not ready, but its creation is no big deal. You just need to do it and that's it. I think, if this issue becomes relevant, we'll adapt PVS-Studio for macOS in several months. The other thing is that we are in no hurry to do so. We're not sure that this direction has much priority than other ones.
Therefore, we would be happy to sell several licenses to ensure ourselves in a practical vivid interest from the programming community.
It is the practical interest that we appreciate the most, and we "have been through" an abstract interest and made a failed CppCat project :). We'd like to avoid making again such mistakes.
The benefits which clients will get by acquiring an unprepared PVS-Studio:
Keil and IAR companies are developing compilers for embedded systems. From time to time developers write a proposal to implement their support. There are no obstacles and a part of the work has already been done. Unfortunately, there are not enough resources to bring it all to mind, and test. I hope we can find time for Keil and IAR in 2018.
Until recently, we extremely narrowly considered the MISRA standard from such point of view - how many errors it will find. This is a wrong approach. The main point of standards such as MISRA is not to find as more bugs as possible in the project. Their purpose is to monitor the quality of the code and to warn the programmer from using potentially dangerous constructions of language.
For example, one of the MISRA rules prohibits using a goto operator. If you take and try to apply this rule to the old, big, and long-standing project, the result is likely to be disappointing from such code check. Almost certainly, there will be no errors, but you will have to rewrite a large number of algorithms to get rid of goto. This can cause more harm than good by accidentally making errors in the process of refactoring.
MISRA standard is not used this way. The application must immediately be written taking into account the rules listed in the standard. Figuratively speaking, MISRA is not the way how to fight against the existing goto, but the way how not to use these goto when writing code.
We have revised our attitude towards MISRA and we realize that it is actually needed, although it does not fit to our model "you took a big project, ran PVS-Studio and found bugs". Our potential customers want to both use the MISRA and find typos that PVS-Studio detects greatly.
We make advances to customers and have begun working on a support of standards MISRA C and MISRA C++ in PVS-Studio. By default, MISRA-warnings will be disabled. We do not want to clog the report window by warnings such as "you cannot use /* */comments, you should use //". However, at any time, a set of MISRA diagnostics can be enabled and regularly used.
As you can see, we have lots of plans for 2018. This article is written as a reason to start a discussion with our new potential users and find out what interests them most. Please, be active and write to us your opinions on the given directions. License pre-orders will have a particularly strong word :).

Thank you for your attention and we wish you a happy New 2018 Year!
0
0
0
0