
Our website uses cookies to enhance your browsing experience.

Every software product has its own origin and development history. A project may be new and small or it may have a dozen of years of commercial success behind it and include thousands of source files. When integrating a static analyzer into the development process, apart from the technical issues of tool integration as such, other important questions also arise such as: how to process analysis results correctly? should we have all the analyzer-generated warnings fixed?... In this article, we are going to talk about a new method of processing static analyzers' output.

The compiler you use acts as a standard static code analyzer. The small set of its diagnostic rules covers only the most common cases of suspicious code almost all of which are not only desirable but demanded to be fixed in most companies.
However, the compiler doesn't generate too many warnings and you won't have any troubles distinguishing a fresh one among them and fix it if necessary. Unlike that, specialized static analyzers carry numbers of diagnostic rules onboard and may generate huge amounts of warnings even on small projects.
A third-party static code analyzer is not kind of a tool every single warning of which must be fixed. Some of the diagnostics are based on heuristics and output false positives quite often. And some of the fragments they find suspicious may have been written consciously that particular way, the programmer having his own reasons for that and never meaning to fix such code.
Disabling such diagnostic rules is not a good idea. They can help you find errors that are too difficult to catch through ordinary code review. Despite false positives there is still a risk that a genuine error will reveal itself later. Then we face the question how to skip certain warnings and see only new ones.
To solve this task, you can use the warning suppression mechanism by adding a special comment at the end of a code line for the analyzer to skip this piece during the next runs. But programmers don't seem to trust this technique as it implies automatic marking of a large bulk of source code while manual marking is never an option for large projects.
Thus, users faced a need for a mechanism to suppress static code analyzers' messages in large projects; a mechanism to allow them to single out new warnings among the entire amount based only on the previous analyzer runs.
One diagnostic message contains the following data: a diagnostic name, warning type and severity level, message explanation, file name, line number and hash sums of a few adjacent lines.
To compare warnings after the source code is changed, it is necessary that all the parameters of the diagnostic message should be taken into account save for the line number as it changes unpredictably after a slightest alteration of the file.
In the PVS-Studio static analyzer, the mechanism of using this feature is implemented in the form of the dialog window "Analyzer Message Suppression" (Figure 1).
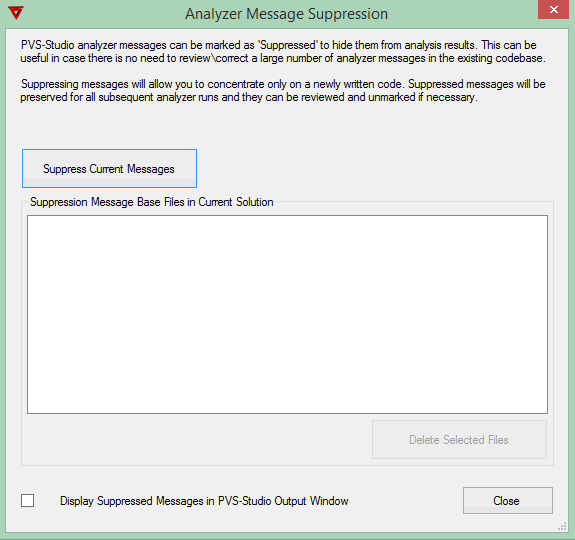
Figure 1 - Warning suppression management dialog window
The "Suppress Current Messages" button is used to do the initial marking of the messages and save the result into local *.suppress files. From that moment on, messages generated during the next checks will be compared to those contained in these files so that only new warnings are displayed in the output window of the PVS-Studio IDE plugin (Figure 2).

Figure 2 - A few new analyzer warnings
Ticking the "Display Suppressed Messages in PVS-Studio Output Window" checkbox shown in Figure 1 allows you to enable displaying filtered off messages in PVS-Studio's output window as well and change their status if necessary (Figure 3).
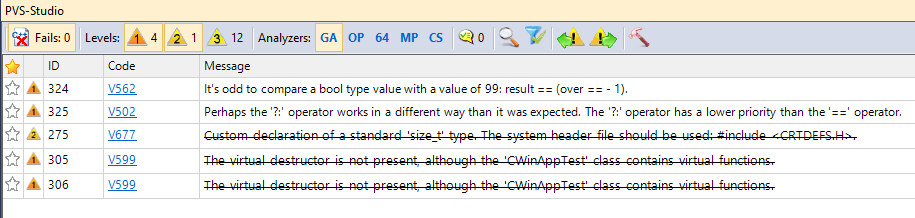
Figure 3 - The full list of analyzer warnings
The new mechanism implemented in the PVS-Studio static analyzer supplements the current method of source code marking through comments. If you've got a false warning pointing to a line in a header file included into many source files and different projects, you'd better mark this fragment with a comment once. Thanks to these features, static analysis becomes even more convenient for regular use.
0
0
0
0