
Our website uses cookies to enhance your browsing experience.

Developers of search engines like Google/Yandex and developers of static code analysis tools to some extent solve the same task. Both have to provide users with a certain selection of resources that meet users' wishes. Well, of course search engines' developers would like to confine themselves just to the button "I'm Feeling Lucky!", while developers of static code analysis tools want to generate a list of real errors only. But reality imposes constrains, as usual. Do you want to know how we fight the cruel reality while developing PVS-Studio?
OpenMP support in PVS-Studio had been dropped after version 5.20. If you have any questions, feel free to contact our support.
So, what is the task of search systems in the conditions of existing restrictions? Without pretending to fully cover this issue, I'll tell you that a search system should give several answers to a user's query (stated explicitly). That is, it should show several websites that might be of interest to a user. At the same time, it could show some advertisement as well.
From the viewpoint of static code analyzers, the task is almost the same. It is answering to the user's implicit query ("You, a smart program, show me please where I have errors in my code") that the tool should point at the code fragments in the program that most likely will be of interest to the user.
Those who dealt with static code analyzers (regardless for which language) understand that any tool produces false positives. This is a situation when there is "formally" an error judging by the code from the viewpoint of the tool, but a human sees that there is no error. Then the human perception comes into play. So, imagine the following situation.
Someone downloads a trial version of the code analyzer and launches it. It even doesn't crash (a miracle!) and manages to work for some time. It shows a list of some tens/hundreds/thousands of messages to the user. If there are just a few dozens of messages, the user will review them all. If he/she finds anything interesting, it's the reason for him/her to think of using the tool constantly and buying it. If he/she doesn't find anything interesting, he/she will soon forget of it. But if there are hundreds or thousands of messages in the list, the user will review just a few of them and draw a conclusion proceeding from what he/she has seen. That's why it is very important that relevant messages can at once "catch" the user's eye. This is the similarity between approaches to the "right top" of search engines' developers and developers of static code analyzers.
To allow PVS-Studio users to see the most interesting messages first of all, we have several tricks.
First, all the messages are categorized into levels similar to Compiler Warning Levels. Only first-level and second-level messages are shown at the first launch by default, while the third level is disabled.
Second, our diagnostics are divided into classes "General Analysis", "64-bit diagnostics" and "OpenMP diagnostics". At the same time, OpenMP and 64-bit diagnostics are also disabled, and users don't see them. It doesn't mean that they are bad, or meaningless, or buggy at all. No, it's just that you are much more likely to find the most interesting errors among errors of the "General Analysis" category. And if a user does find anything interesting there, he/she will turn on the other diagnostics and handle them if he/she needs them, of course.
Third, we are constantly fighting against false positives.
We have an internal tool that allows us to make statistic (do not confuse with "static"!) analysis of our code analyzer's output results. It allows us to estimate the following three parameters:
Let's see how we use this internal tool by the example of the Miranda IM project.
Note that this post is not about errors found in Miranda IM. If you want to see them, please refer to this post.
So, we open the analysis report (plog-file) in our internal tool, turn off the third error level and leave only the GA-analyzer (General Analysis). The error distribution is shown in Figure 1.
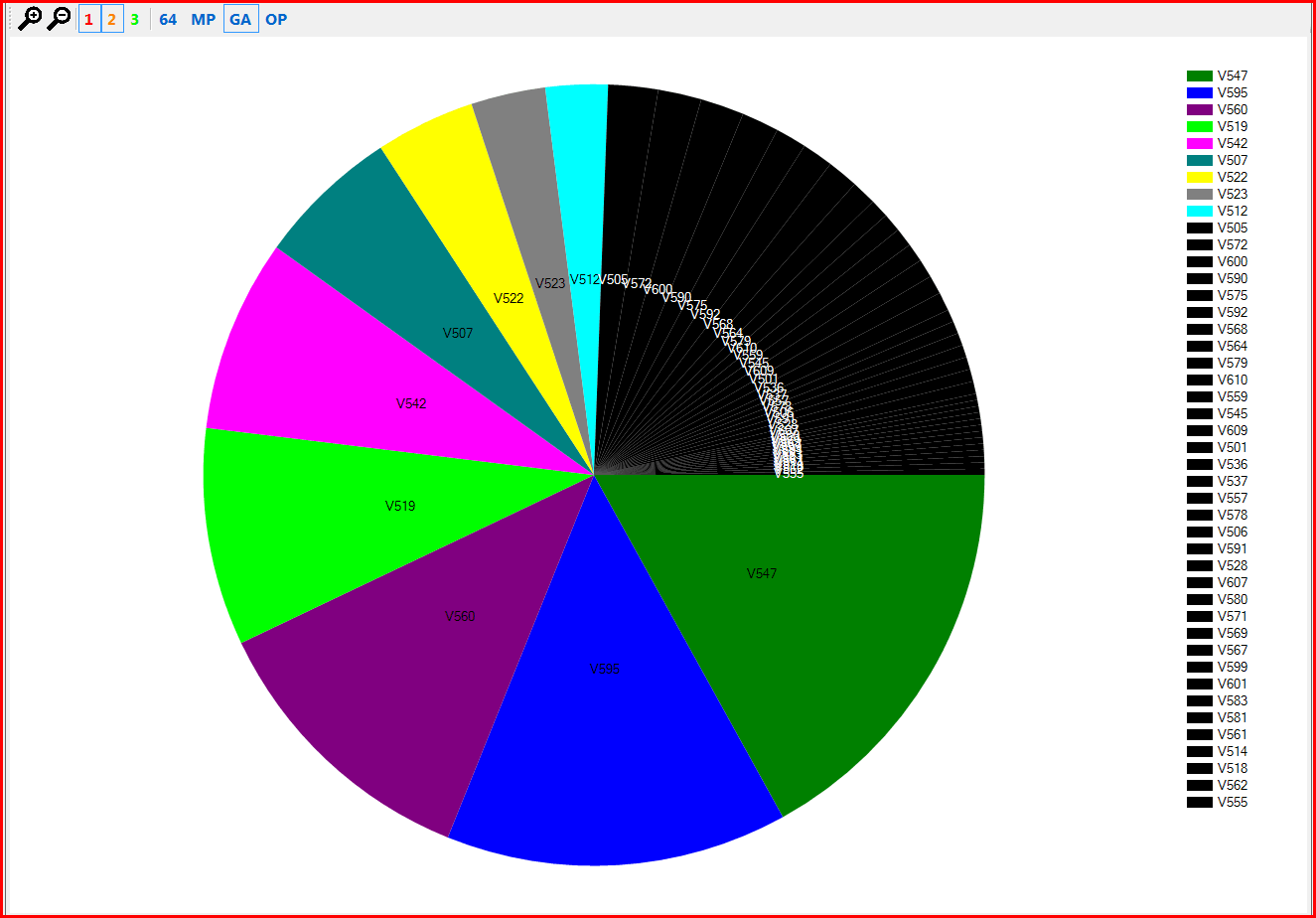
Figure 1 - Distribution of errors in the Miranda IM project.
The color sectors correspond to a more than 2.5% share of reports of a certain diagnostic out of the general amount of detected issues. The black sectors correspond to shares less than 2.5%. You can see that errors with codes V547, V595 and V560 are the most frequent. Let's keep them in mind.
In Figure 2, you can see the average number of errors of each type per file (i.e. their average density for the project).
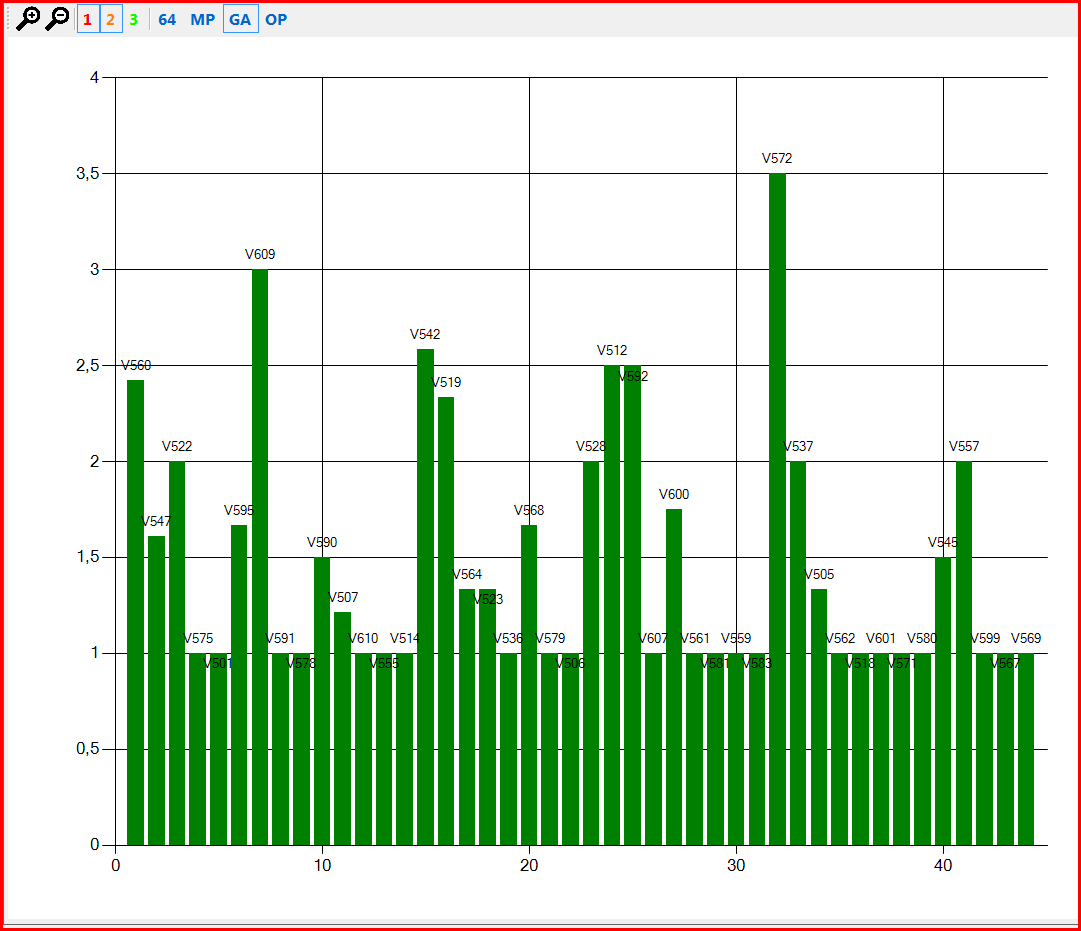
Figure 2 - Average density of errors in the Miranda IM project.
As you can see from this graph, the errors with codes V547, V595 and V560 are reported from 1.5 to 2.5 times per file. This is actually a normal value and there's no reason, as we think, to "fight" these errors regarding false positives. But the final conclusion is drawn on the basis of the third graph for these errors shown in Figure 3, Figure 4 and Figure 5.
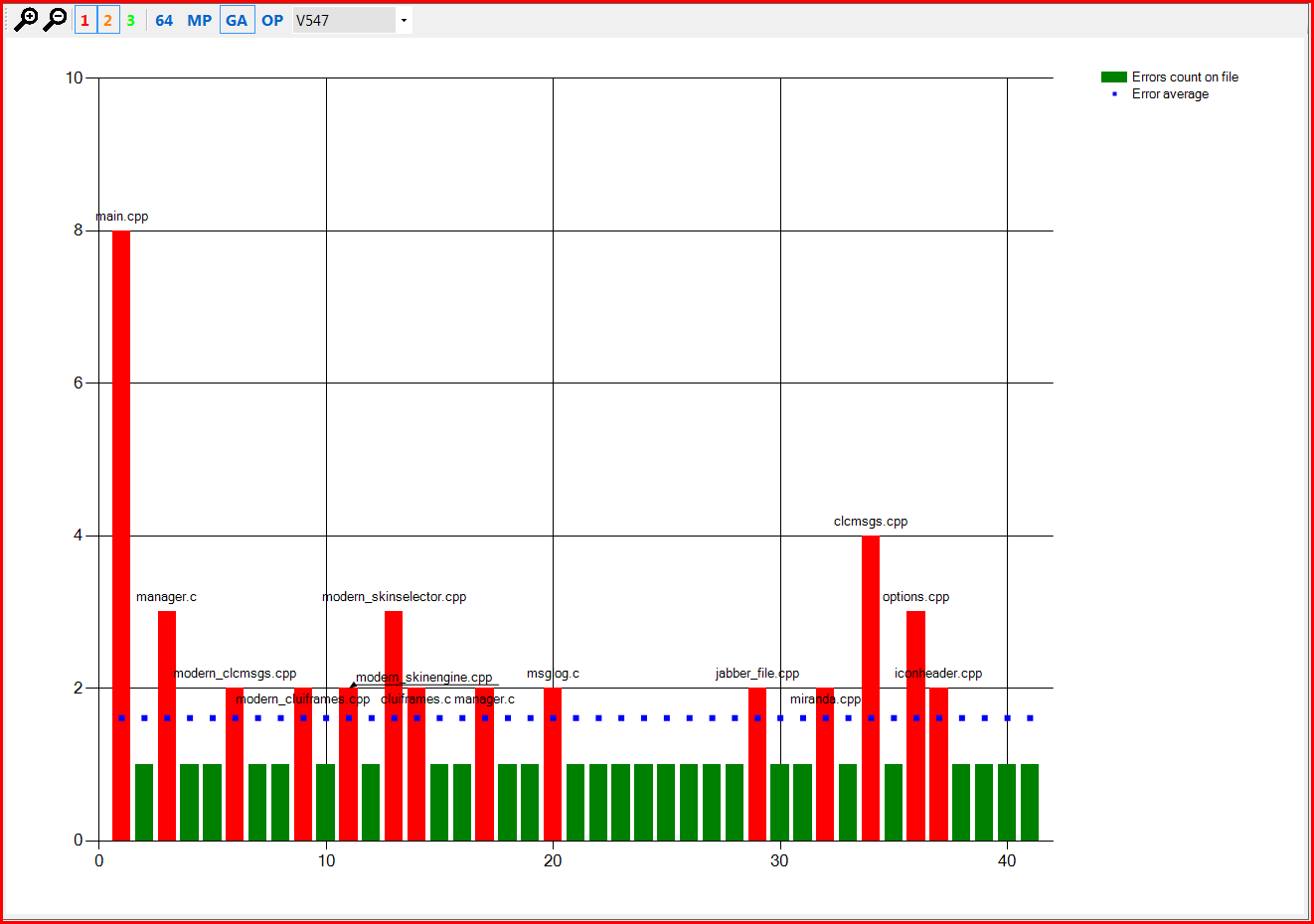
Figure 3 - Distribution of V547 errors in the Miranda IM project compared to their average density.
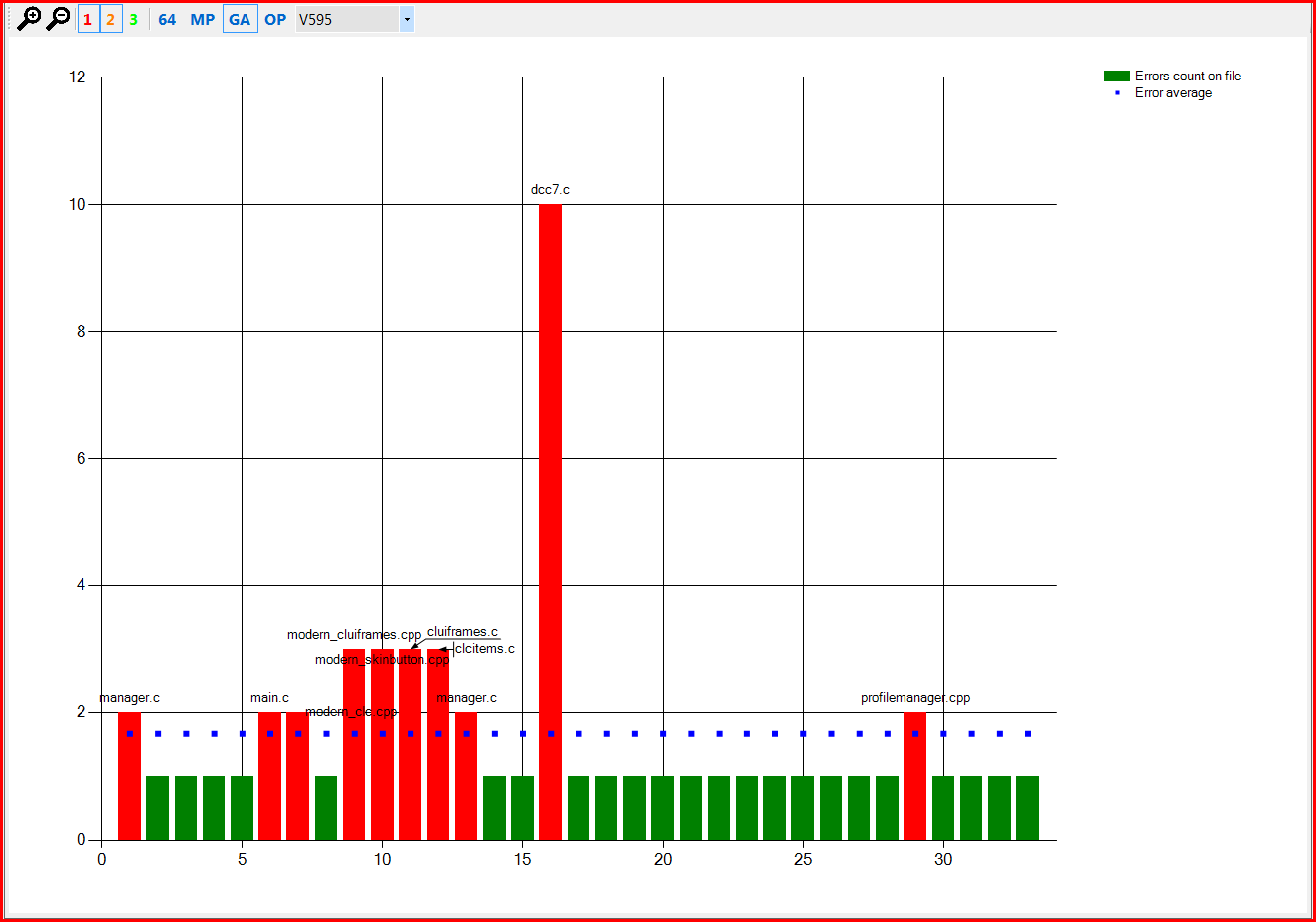
Figure 4 - Distribution of V595 errors in the Miranda IM project compared to their average density.
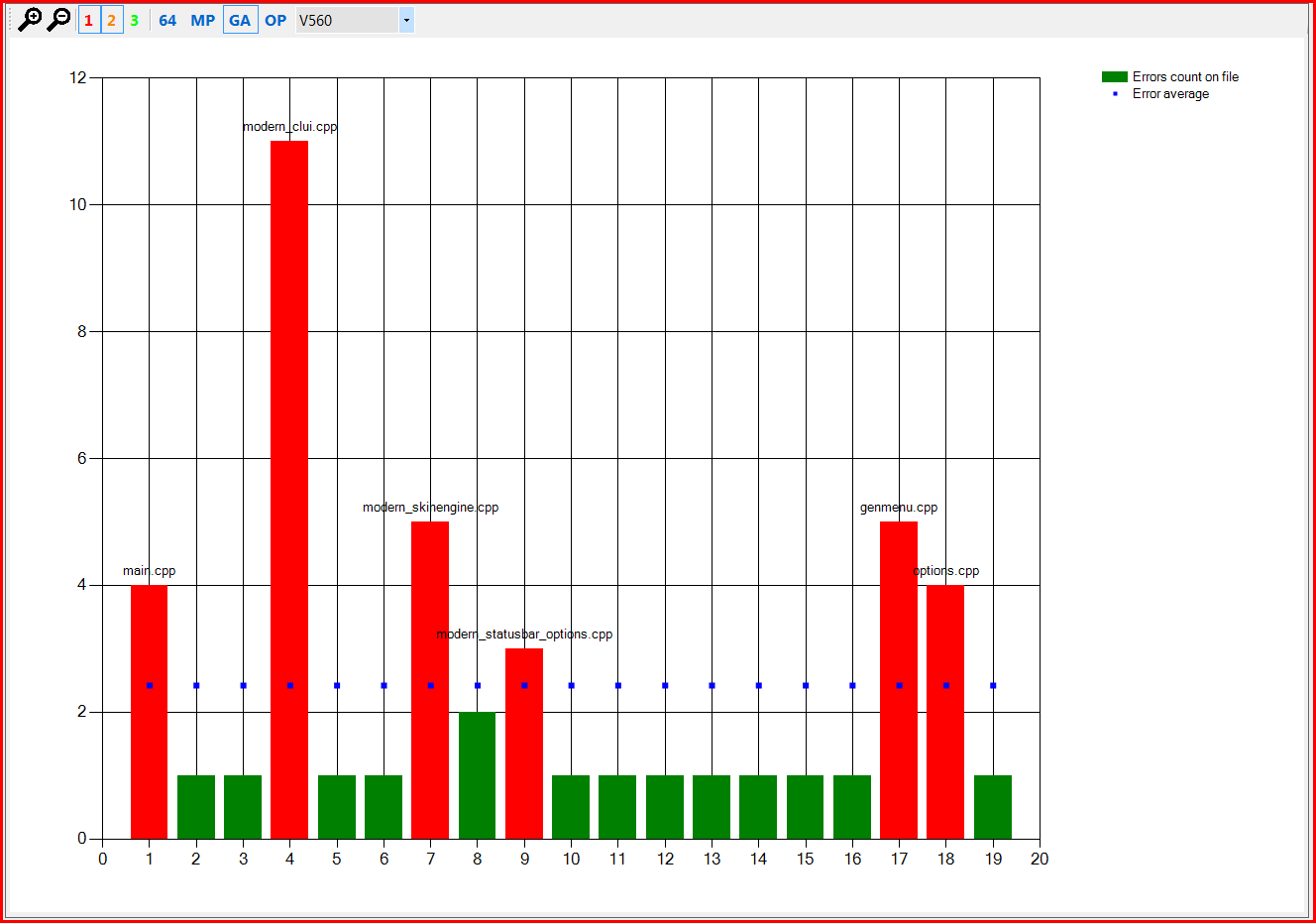
Figure 5 - Distribution of V560 errors in the Miranda IM project compared to their average density.
In Figures 3-5, names of individual files are written horizontally, and the number of times a certain error was reported for a particular file - vertically. The red columns are files where the error was reported more than the average (blue dots) number of times for this error type.
Then we study these "red" files and make a decision: if there is a false positive and it occurs quite frequently in other projects too, then we eliminate it. And if there is a real error which is, in addition, was swiftly cloned with the copy-paste technology, there's nothing to "improve".
In this post, I'm consciously omitting code samples the analyzer swore at in order not to overload the text.
In other words, after drawing a whole lot of such graphs and analyzing them, we can easily see where our analyzer misses and fix those places. It confirms an old truth that the visual representation of "boring" data allows you to have a better view of the issue being investigated.
Attentive readers have noticed one more button (OP) in the pictures besides the three standard buttons of analyzers (GA, 64, MP). OP is the abbreviation of "optimization". In PVS-Studio 4.60, we have introduced the new group of diagnostic messages referring to micro-optimizations. Diagnostics of possible micro-optimizations is quite an ambiguous feature of our analyzer. Somebody will be glad to find a place where a large object is passed into a function through copying instead of by reference (V801). Somebody will significantly save memory by decreasing structure sizes for large object arrays (V802). And somebody thinks it all is rubbish and premature optimization. Everything depends on the project type.
Anyway, analyzing the results of our tool's output, we have come to the necessity of:
That's how this new button OP has appeared in the PVS-Studio Output Window (Figure 6):
Figure 6 - OP button (optimization) has appeared in PVS-Studio 4.60.
By the way, we have also significantly reduced the number of false positives for 64-bit issues analysis in the same version.
I invite you to download the new PVS-Studio version and to check how adequate the recommendations on optimizing your code are.
Developers of static code analyzers, as well as search engine developers, are interested in making the output as adequate as possible. Both employ many methods to achieve that, including statistical analysis methods. In this post I have shown you how we achieve that when developing PVS-Studio.
I have a small question to those who dealt with (or at least played around with) PVS-Studio or any other code analyzer. Do you think a code analyzer's end user needs the graphs demonstrated in this article as an end-user tool? In other words, do you think you could learn anything useful from such diagrams if your code analyzer contained them? Or is it a tool "for internal use" only? Please share your opinion by writing to us.
0
0
0
0