
Our website uses cookies to enhance your browsing experience.

Friends, it is high time we stopped considering links only in the context of their number and buying/ selling and counting PR of the site they are laid out on. It is high time we started to take care of people and not robots. It gets more and more unbearable to work on the Internet. Farms of autogenerated sites with shittexts (ladies pardon me) are flourishing and breeding. Because of them one cannot find even technical materials not to speak of common ones. I wouldn't take it so close to heart if they had correct links. But links die like flies and when you read a post written a year earlier in a forum or blog, you have very little hope that you will be able to go anywhere by the attached links.
This article is out of date. The working mechanism with links described here is not used anymore.
I find bad links a very great problem of the contemporary Internet, although people don't speak or think about it too much. I think it is high time we started doing at least something. And we are doing something - this is what I want to tell you about in this post. I hope our example will inspire somebody who will feel a wish to take care of their users.
The number of bad links on the Internet is so great that we cannot even choose among them to show as an example. Each of you encountered this situation when you read interesting information on some topic, click an attached link with confidence and come to nowhere. What's more, the target is not always a dead site, it might be quite live - so live that it is constantly being edited and nobody cares of redirecting users coming from external resources. Well, hardly anybody cares of redirecting users from internal resources as well. A good example is articles in MSDN.
Somebody can argue that there's nothing bad that a material has been moved somewhere - you can easily find it in Google. First, even if you can, it takes you too much time. And this is a large problem. One single but useful resource moved on an administrator's whim takes time of thousands and sometimes millions of people. Each of them will have to search for the necessary material and surf links.
In other cases, it is too difficult to find the necessary material or the person who needs it cannot do this. Here are two examples when "go to Google" doesn't help.
The first example. To release a plug-in for Microsoft Visual Studio, we need to get a special PLK for each version on the Microsoft site. They had given us this key on the page http://msdn.microsoft.com/en-us/vsx/cc655795.aspx (the link is dead) for several years. A couple of months ago somebody decided that it is not right ideologically to call the section "vsx" and renamed it "vstudio". Correspondingly, the link was updated: https://msdn.microsoft.com/en-us/vstudio/cc655795.aspx. But EVERYWHERE including Microsoft sites, the links remained obsolete. Search in Google resulted in finding just an old link since the new one wasn't mentioned anywhere. Only members of the Microsoft forum helped us and gave the direct link to the new page. The question is - does anybody feel better because of the changed link? How many people all over the world had to search for the answer to this question? If you want to change a link so terribly, why not to provide for redirection?
And here is another, more emotive example. There is a book "C# for schoolchildren" published with support by Microsoft and intended for children of 12-16.
Personally I am not sure it is reasonable to study C# at this age but on the whole the book is rather good. At least it contains a lot of illustrative funny pictures.
So imagine how many efforts the authors spent to create this book. Somebody suggested that Microsoft took the advertising initiative to introduce children into C# already at school; the author wrote the book, then it was translated, an artist copied the pictures with the Russian translation and perhaps with translations to other languages as well. A whole lot of money and time was spent. And what is the result? I'm sure - no result!
I strongly doubt that a child will go further than "Part 1. Getting started" because it is written there that you must download and install Microsoft Visual C# 2008 Express Edition. I don't doubt schoolchildren's abilities. They download and install Starcraft 2 without anybody's help and know iPhone better than I. Everything is much simpler: they are asked to download the tool from the address that doesn't exist anymore.
The question is - what for did all those people get involved in creation of the book when everything crashes because of thoughtlessly moving data on the site from one place to another? I doubt that a schoolchild of thirteen will go to Google to search for a fairy-tale beast "Microsoft Visual C# 2008 Express Edition" to download it. It is 90% that study of C# will be finished at this chapter.
Yes, I may seem to criticize Microsoft. No, other sites are not better - these are only such examples.
It is very easy to spoil the whole material, a post in a blog, service, book or any other project because somebody (or yourself) may change the address of the resource you are referring to. After that the value of your work will be much lower, if not turn to zero, since your readers/users will have to waste time and nerves on searching for the necessary link themselves.
We write technical articles and often refer to various documentation, tools and posts in third-party blogs. Consequently, we also often encounter this issue when materials and articles are moved on third-party sites. For some reason, it is sites of such large companies as Microsoft, Intel and AMD that succeed in this activity. They move whole sections, so it is an absolutely unrewarding task to search for aid in articles written by Microsoft/Intel workers with the age of at least one year. Any link you click leads to nowhere. I think many programmers will understand my emotions.
I'm sure many don't care at all - if redirection to somewhere doesn't work, well, never mind. Well, it is so - for could there be so many dead links if many people cared? However, we write articles for people and not search engines. I'm proud to say this. Although we haven't earned millions of dollars yet, we can feel ourselves d'Artagnan for a moment at least.
So, it is important for us that our articles contain correct links not only to materials on our own site but to external sites as well. Consequently, we need to fix those links that start leading nowhere. The fact that we publish our articles on many other sites makes this task even harder. Of course, we cannot fix links on all of them (and sometimes it is impossible due to technical reasons).
A natural solution is to create a redirection system. I will tell you how it works in our company and perhaps somebody would like to make the same thing. Well, I even wish that somebody gets interested in it because I'm sick and tired of roads to nowhere!
The system consists of a base that stores a pair: short link - external-resource link. The user interface of link adding is rather simple and is shown in the figure below.

We simply input a link on an external resource and get a short link to add into articles, blogs and so on. If the address of the external resource is already in the base, it returns the short link created before:
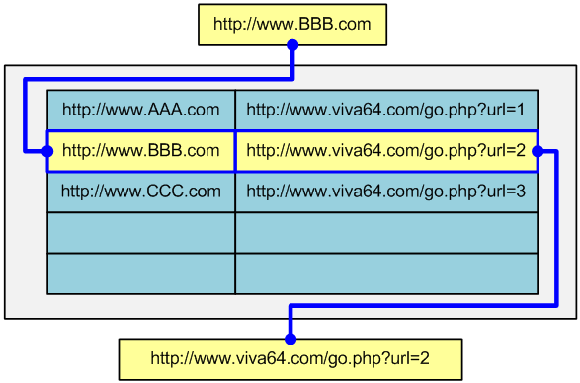
If there is no such link in the base, a new pair is created and a new short link is generated:

What the technical side is concerned, the entry is stored in the database in the links table and is a set of the following fields:
When you click the "Generate" button, a request is sent to the viva64.com site containing the address of the link to be added. The script processing the request looks something like this:
$sql = "select * from links where link='".$add_url."'";
$link = mysql_query($sql);
if(mysql_num_rows($link)){
$row = mysql_fetch_array($link,MYSQL_ASSOC);
$new_url = "http://www.viva64.com/qwerty.php?url=".$row['num'];
}
else{
$sql = "select * from links order by num desc";
$link = mysql_query($sql);
$row = mysql_fetch_array($link, MYSQL_ASSOC);
$last_num = $row['num']+1;
$sql = "insert into links (num,link) values
(".$last_num.",'".$add_url."')";
$link = mysql_query($sql);
$new_url = "http://www.viva64.com/qwerty.php?url=".$last_num;
}The script passes this address to the $add_url variable and checks if there is such an address in the database:
$sql = "select * from links where link='".$add_url."'";
$link = mysql_query($sql);If there is, the link will be simply written into the $new_url variable to call the redirection script with the address identifier received from the base:
if(mysql_num_rows($link)){
$row = mysql_fetch_array($link,MYSQL_ASSOC);
$new_url = "http://www.viva64.com/qwerty.php?url=".$row['num'];
}If there is no such an address, the system will calculate the maximum unique address identifier relying on those ones that are stored in the links table and a new entry will be added into the database with an incremented maximum identifier. After that the value of the new link is written into the $new_url variable to call the redirection script:
else{
$sql = "select * from links order by num desc";
$link = mysql_query($sql);
$row = mysql_fetch_array($link, MYSQL_ASSOC);
$last_num = $row['num']+1;
$sql = "insert into links (num,link) values
(".$last_num.",'".$add_url."')";
$link = mysql_query($sql);
$new_url = "http://www.viva64.com/qwerty.php?url=".$last_num;
}After that the user gets the redirection link whether the new address was added into the database or some of the existing addresses was generated.
The redirection script on the viva64.com site is not complex. Actually, everything it does is to accept the number of a link as a parameter, then get the link itself with this number from the base and perform redirection by the link. In the code it looks in this way:
$s = substr($HTTP_GET_VARS['url'], 0, 15);
$u = "http://www.viva64.com/";
$isConnect = mysql_connect($sqlserver,$sqluser,$sqlpassword);
if($isConnect){
$isSelectDatabase = mysql_select_db($database);
if($isSelectDatabase){
$currentLink = $s;
$sql = "SELECT * FROM links WHERE num='".$currentLink."'";
$link = mysql_query($sql);
if($link && mysql_num_rows($link)){
$row = mysql_fetch_array($link,MYSQL_ASSOC);
$u = $row['link'];
}
}
}
print Header('Location: '.$u);The task of searching for bad links is solved by means of the Fast Link Checker program. This program traverses all the site pages and tries to go by all the links found. Then the results are filtered and a letter with a list of bad links is sent by the e-mail addresses defined in advance. The program launch is automated - the links are checked once a week.
After detecting a bad link, we manually search for the material referred to by the link. It is usually easy to find the new address you may find the material by. On Microsoft, Intel and AMD sites, they are very fond of simply moving materials to other sections.
If we cannot find this or almost identical resource (what happens very rarely), we delete the link from the articles on the site. The same link that remains in articles published on third-party sites will lead to nowhere but here we cannot help it. If some material/site has disappeared, well, let it be.
When the new link is found, it is saved in the database and therefore it works on in all the articles of the site.
To change the link through the administrator interface, a request of the following kind will be sent:
UPDATE 'links' SET
'link' = 'http://msdn.microsoft.com/en-us/isv/bb190527.aspx'
WHERE
'links'.'numn = 341 LIMIT 1 ;I won't describe the principle of the system in every detail. To be frank, I'm user of this system - not developer.
I want to thank beforehand all of you who would like to make the world a bit better too.
0
0
0
0