
Though the history of 64-bit systems development makes more than a decade, the appearance of 64-bit version of OS Windows raised new problems in the sphere of development and testing applications. In the article there are considered some mistakes connected with 64-bit C/C++ code development to OS Windows. The reasons are explained according to which these mistakes didn't find their reflection in the articles devoted to the migration tasks and are unsatisfactorily detected by the majority of static analyzers.
The history of 64-bit programs is not new and makes more than a decade already [1]. In 1991 the first 64-bit microprocessor MIPS R4000 was released [2, 3]. Since that time the discussions concerning porting programs to 64-bit systems have started in forums and articles. There began a discussion of the problems related to the 64-bit programs development in C language. The following questions were discussed: which data model is better, what is long long and many others. Here, for example, is an interesting collection of messages [4] from comp.lang.c newsgroup concerning using long long type in C language, which, in its turn, was related to 64-bit systems appearance.
The C language is one of the most widespread languages and it is sensitive to the change of the digit capacity of data types. Because of its low-level features, it is necessary to constantly control the correctness of the program ported to a new system in this language. It is natural that with the appearance of 64-bit systems the developers all around the world faced the problems of providing compatibility of the old source code with the new systems again. One of the indirect evidences of the difficulty of program migration is a big number of data models which must be constantly taken into consideration. Data model is a correlation of the size of base types in a programming language. Picture 1 shows the digit capacity of types in different data models, which we will refer to further on.
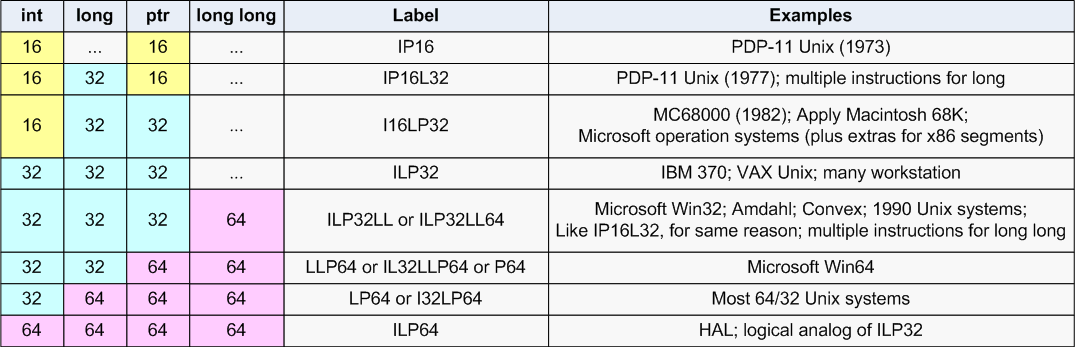
Picture 1. Data Models.
Of course, it was not the first stage of digit capacity change. That's enough to recollect the transition from 16-bit systems to 32-bit. It's natural that the acquired experience had a good influence on the stage of migration to 64-bit systems.
But the migration to 64-bit systems had its own peculiarities because of which there appeared a number of investigations and publications on these problems, for example [5, 6, 7].
Errors of the following kinds were pointed out by the authors of those times:
int x = 100000, y = 100000, z = 100000;
long long s = x * y * x;Some other more rare mistakes were also considered, but the main ones are mentioned in the list.
On the ground of the investigation of the question of verification of 64-bit code some solutions were offered that provide the diagnostics of dangerous constructions. For example, such verification was realized in Gimpel Software PC-Lint (http://www.gimpel.com) and Parasoft C++test (http://www.parasoft.com) static analyzers.
The following question arises: if 64-bit systems have existed for such a long period of time, as well as articles concerning this problem, and even program tools that provide control over dangerous constructions in the code, should we get back to this problem?
Unfortunately, yes, we should. The reason is the progress of informational technologies. And the urgency of this question is related to fast spreading of 64-bit versions of OS Windows.
The existing informational support and tools in the field of 64-bit technologies development went out of date and need fundamental reprocessing. But you will object, saying that there are many modern articles (2005-2007) in the Internet concerning the problems of 64-bit applications development in C/C++ language. Unfortunately, they turn out to be no more than retelling older articles concerning new 64-bit Windows version without taking into consideration its peculiarities and changes in technologies.
Let us start at the beginning. The authors of some articles don't take into consideration large memory capacity that became available to modern applications. Of course, the pointers were 64-bit in ancient times yet, but such programs didn't have chance to use arrays of several gigabytes in size. As a result, both in old and new articles there appeared a whole stratum of errors related to incorrect indexing of big arrays. It is practically impossible to find a description of an error similar to the following:
for (int x = 0; x != width; ++x)
for (int y = 0; y != height; ++y)
for (int z = 0; z != depth; ++z)
BigArray[z * width * height + y * width + x] = InitValue;In this example the expression "z * width * height + y * width + x", which is used for addressing, has the int type, which means that the code will be incorrect if the arrays contain more that 2 GB of elements. On 64-bit systems one should use types like ptrdiff_t and size_t for a safer indexing of large arrays. The absence of a description of errors of this kind in the article can easily be explained. In the time when the articles were written the machines with memory capacity, which makes it possible to store such arrays were practically not available. Now it becomes a common task in programming, and we can watch with a great surprise how the code that has been serving faithfully for many years stopped working correctly dealing with big data arrays at 64-bit systems.
The other stratum of problems, which has not been touched, is represented by errors related to possibilities and peculiarities of the C++ language. It also quite explicable why it happened so. During the introduction of first 64-bit systems C++ language did not exist for them or was not spread. That's why practically all the articles are concerning problems in the field of C language. Modern authors substituted C with C/C++ but they didn't add anything new.
But the absence of errors typical for C++ in the articles does not mean that they don't exist. There are errors that show up during the migration of programs to 64-bit systems. They are related to virtual functions, exceptions, overloaded functions and so on. You may get acquainted with such mistakes in the article [8] in more detail. Let us give an example related to usage of virtual functions.
class CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};Let us follow the life cycle of development of a certain application. Let us suppose that first it was developed in Microsoft Visual C++ 6.0. when WinHelp function in CWinApp class had the following prototype:
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);It was correct to override the virtual function in CSampleApp class like it is shown in the example. Then the project was ported to Microsoft Visual C++ 2005 where the prototype of the function in CWinApp class was changed so that the DWORD type changed into the DWORD_PTR type. The program will continue working correctly at a 32-bit system for the DWORD and DWORD_PTR types coincide here. The problem will show up during the compilation of the code on a 64-bit platform. There will come out two functions with identical names but with different parameters, as the result the user's code will never be activated.
Besides the peculiarities of 64-bit programs development from the point of view of C++ language there are other points to be paid attention to. For example, the peculiarities related to the architecture of 64-bit versions of Windows. We'd like to let developer know about possible problems and to recommend paying more attention to testing 64-bit software.
Now let us get back to the methods of verification of the source code using static analyzers. I think you have already guessed that everything is not so nice here as it may seem. In spite of the declared support for diagnosing the peculiarities of 64-bit code, this support at the moment does not meet the necessary conditions. The reason is that the diagnostic rules were created according to all those articles that do not take into account the peculiarities of the C++ language or processing large data arrays, that exceed 2 GB.
For Windows developers the case is somewhat worse. The main static analyzers are designed to diagnose 64-bit errors for the LP64 data model while Windows use the LLP64 data model [10]. The reason is that 64-bit versions of Windows are young and older 64-bit systems were represented by Unix-like systems with LP64 data model.
As an example let us consider the diagnostic message 3264bit_IntToLongPointerCast (port-10), which is generated by the Parasoft C++test analyzer.
int *intPointer;
long *longPointer;
longPointer = (long *)intPointer; //-ERR port-10C++test supposes that from the point of view of LP64 model this construction will be incorrect. But in the scope of data model accepted in Windows this construction will be safe.
Ok, you will say, the problems of 64-bit program versions are urgent. But how to detect all the errors?
It is impossible to give an exhaustive answer, but it is quite possible to give a number of recommendations that will make it possible to provide safe migration to 64-bit systems and to provide the necessary level of reliability.