Some means of 64-bit Windows applications performance increase are considered in the article.
People often have questions concerning 64-bit solutions performance and means of its increasing. Some questionable points are considered in this article and then some recommendations concerning program code optimization are given.
In a 64-bit environment old 32-bit application run owing to Wow64 subsystem. This subsystem emulates 32-bit environment by means of an additional layer between a 32-bit application and 64-bit Windows API. In some localities this layer is thin, in others it's thicker. For an average program the productivity loss caused by this layer is about 2%. For some programs this value may be larger. 2% are certainly not much but still we have to take into account the fact that 32-bit applications function a bit slower under a 64-bit operation system than under a 32-bit one.
Compiling of a 64-bit code not only eliminates Wow64 but also increases performance. It's related to architectural alterations in microprocessors, such as the increase in number of general-purpose registers. For an average program the expected performance growth caused by an ordinary compilation is 5-15%. But in this case everything depends upon the application and data types. For instance, Adobe Company claims that new 64-bit "Photoshop CS4" is 12% faster than its 32-bit version.
Some programs dealing with large data arrays may greatly increase their performance when expanding address space. The ability to store all the necessary data in the random access memory eliminates slow operations of data swapping. In this case performance increase can be measured in times, not in percent rate.
Here we can consider the following example: Alfa Bank has integrated Itanium 2-based platform into its IT infrastructure. The bank's investment growth resulted in the fact that the existing system became unable to cope with the increasing workload: users' service delays attained its deadline. Case analysis showed up that the system's bottleneck is not the processors' performance but the limitation of 32-bit architecture in a memory subsystem part that does not allow using efficiently more than 4 GB of the server's addressing space. The data base itself was larger than 9 GB. Its intensive usage resulted in the critical workload of input-output subsystem. Alfa Bank decided to purchase a cluster consisting of two four-processor Itanium2-based servers with 12GB of random access memory. This decision allowed to ensure the necessary level of system's performance and fault-tolerance. As explained by company representatives implementation of Itanium2-based servers allowed to terminate problems to cut costs. [1 [RU]].
We can consider optimization at three levels: microprocessor instructions optimization, code optimization on the level of high-level languages and algorithmic optimization (which takes into account peculiarities of 64-bit systems). The first one is available when we use such development tools as assembler and is too specific to be of any interest for a wide audience. For those who are interested in this theme we can recommend "Software Optimization Guide for AMD64 Processors" [2] -an AMD guide of application optimization for a 64-bit architecture. Algorithmic optimization is unique for every task and its consideration is beyond this article.
From the point of view of high-level languages, such as C++, 64-bit architecture optimization depends on the choice of optimal data types. Using homogeneous 64-bit data types allows the optimizing compiler to construct a simpler and more efficient code, as there's no need to convert 32-bit and 64-bit data inter se often. Primarily, this can be referred to variables which are used as loop counters, array indexes and for variables storing different sizes. Traditionally we use such types as int, unsigned and long to represent the above-listed types. With 64-bit Windows systems which use LLP64 [3] data model these types remain 32-bit ones. In a number of cases this results in less efficient code construction for there are some additional conversions. For instance, if you need to figure out the address of an element in an array with a 64-bit code, first you must turn the 32-bit index into a 64-bit one.
The use of such types as ptrdiff_t and size_t is more effective, as they possess optimal size for representing indexes and counters. For 32-bit systems they are scaled as 32-bit, for 64-bit systems as 64-bit (see table 1).
Table 1. Type size in 32-bit and 64-bit versions of Windows operation system.
Using ptrdiff_t, size_t and derivative types allows to optimize program code up to 30%. You can study an example of such optimization in the article "Development of resource-intensive applications in Visual C++ environment" [4]. Additional advantage here is a more reliable code. Using 64-bit variables as indexes permits to avoid overflows when we deal with large arrays having several billions of elements.
Data type alteration is not an easy task far less if the alteration is really necessary. We bring forward Viva64 static code analyzer as a tool which is meant to simplify this process. Though it specializes in 64-bit code error search, one can considerably increase code performance if he follows its recommendations on data type alteration.
After a program was compiled in a 64-bit regime it starts consuming more memory than its 32-bit variant used to do. Often this increase is almost imperceptible but sometimes memory consumption increases two times. This coheres with the following reasons:
One can often put up with ram memory consumption increase. The advantage of 64-bit systems is exactly that the amount of this memory is rather large. There's nothing bad in the fact that with a 32-bit system having 2 GB of memory a program took 300 MB, but with a 64-bit system having 8 GB of memory this program takes 400 MB. In relative units, we see that with a 64-bit system this program takes three times less available physical memory. There is no sense trying to fight this memory consumption growth. It's easier to add some memory.
But the increase of consumed memory has one disadvantage. This increase causes loss of performance. Though a 64-bit program code functions faster, extracting of large amounts of data out of memory frustrate all the advantages and even decrease performance. Data transfer between memory and microprocessor (cache) is not a cheap operation.
Let us assume that we have a program which processes a large amount of text data (up to 400 MB). It creates an array of pointers, each indicating a succeeding word in the processed text. Let the average word length be 5 symbols. Then the program will require about 80 million pointers. So, a 32-bit variant of the program will require 400 MB + (80 MB * 4) = 720 MB memory. As for a 64-bit version of the program, it will require 400 MB+ (80 MB * 8) = 1040 MB memory. This is a considerable increase which may adversely affect the program performance. And if there's no need to process gigabyte-sized texts, the chosen data structure will be useless. The use of unsigned- type indexes instead of pointers may be viewed as a simple and effective solution of the problem. In this case the size of consumed memory again is 720 MB.
One can waste considerable amount of memory altering regulations of data alignment. Let us consider an example:
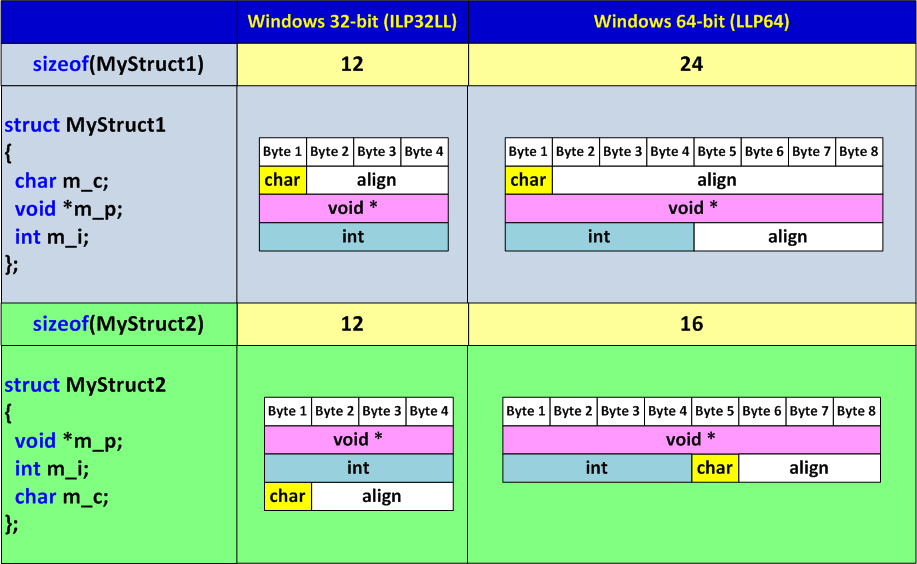
struct MyStruct1
{
char m_c;
void *m_p;
int m_i;
};Structure size in a 32-bit program is 12 bytes, and in a 64-bit one it is 24 bytes, which is not thrifty. But we can improve this situation by altering the sequence of elements in the following way:
struct MyStruct2
{
void *m_p;
int m_i;
char m_c;
};MyStruct2 structure size still equals to 12 bytes in a 32-bit program, and in a 64-bit program it is only 16 bytes. Therewith, from the point of view of data access efficiency MyStruct1 and MyStruct2 structures are equivalent. Picture 1 is a visual representation of structure elements distribution in memory.
Picture 1.
It's not easy to give clear instructions concerning order of elements in structures. But the common recommendation is the following: the objects should be distributed in the order of their size decrease.
The last point is stack memory consumption growth. Storing of larger return addresses and data alignment increases the size. Optimizing them makes no sense. A sensible developer would never create megabyte-sized objects in stack. Remember that if you are porting a 32-bit program to a 64-bit system don't forget to alter the size of stack in project settings. For instance, you can double it. On default a 32-bit application as well as a 64-bit one is assigned a 2MB stack as usual. It may turn out to be insufficient and securing makes sense.
The author hopes that this article will help in efficient 64-bit solutions development and invites you to visit www.viva64.com to learn more about 64-bit technologies. You can find lots of items devoted to development, testing and optimization of 64-bit applications. We wish you the best of luck in developing your 64-bit projects.
{kind=link}