
This article is the story how we once decided to improve our internal SelfTester tool that we apply to test the quality of the PVS-Studio analyzer. The improvement was simple and seemed to be useful, but got us into some troubles. Later it turned out that we'd better gave up the idea.

We develop and promote the PVS-Studio static code analyzer for C, C++, C# and Java. To test the quality of our analyzer we use internal tools, generically called SelfTester. We created a separate SelfTester version for each supported language. It is due to specifics of testing, and it's just more convenient. Thus, at the moment we have three internal SelfTester tools in our company for C\C++, C# and Java, respectively. Further, I'll tell about Windows version of SelfTester for C\C++ Visual Studio projects, calling it simply SelfTester. This tester was the first in line of similar internal tools, it's the most advanced and complex of all.
How does SelfTester work? The idea is simple: take a pool of test projects (we're using real open source projects) and analyze them using PVS-Studio. As a result, an analyzer log is generated for each project. This log is compared with the reference log of the same project. When comparing logs, SelfTester creates a summary of logs comparing in a convenient developer-friendly way.
After studying the summary, a developer concludes about changes in the analyzer behavior according to the number and type of warnings, working speed, internal analyzer errors, etc. All this information is very important: it allows you to be aware of how the analyzer copes with its work.
Based on the summary of logs comparison, a developer introduces changes in the analyzer core (for example, when creating a new diagnostic rule) and immediately controls the result of his edits. If a developer has no more issues to a regular log comparing, he makes a current warnings log reference for a project. Otherwise, the work continues.
So, the task of SelfTester is to work with a pool of test projects (by the way, there are more than 120 of them for C/C++). Projects for the pool are selected in the form of Visual Studio solutions. It is done so in order to additionally check the analyzer's work on various Visual Studio versions, which support the analyzer (at this point from Visual Studio 2010 to Visual Studio 2019).
Note: further I'll separate the concepts solution and project, considering a project as a part of a solution.
SelfTester's interface looks as follows:
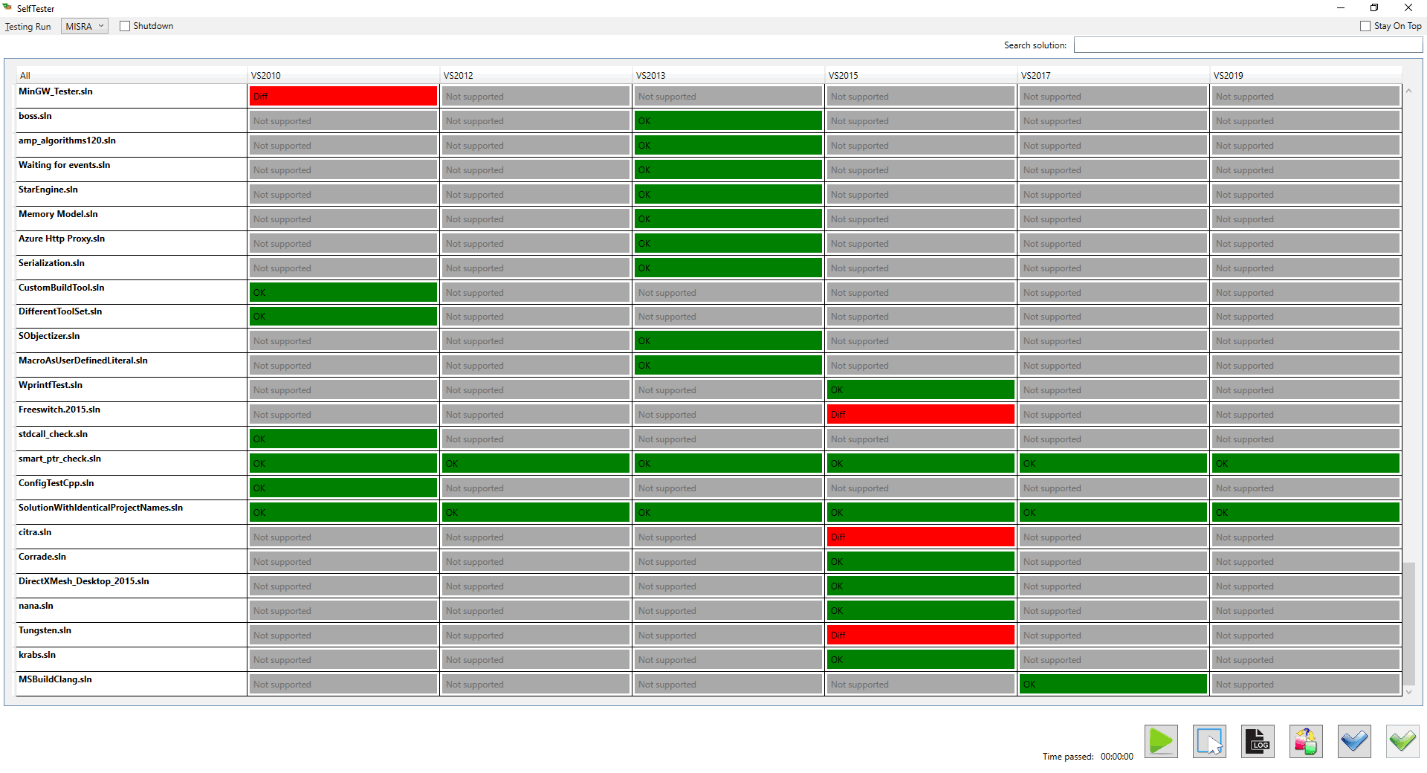
On the left there is a list of solutions, on the right - results of a check for each Visual Studio version.
Grey labels "Not supported" indicate that a solution doesn't support a chosen Visual Studio version or it wasn't converted for this version. Some solutions have a configuration in a pool, that indicates a specific Visual Studio version for a check. If a version isn't specified, a solution will be updated for all subsequent Visual Studio versions. An example of such a solution is on the screenshot - "smart_ptr_check.sln" (a check is made for all Visual Studio versions).
A green label "OK" indicates that a regular check hasn't detected differences with the reference log. A red label "Diff" indicates about differences. These labels have to be paid special attention. After clicking twice on the needed label, the chosen solution will be opened in a related Visual Studio version. A window with a log of warnings will also be open there. The control buttons at the bottom allow you to rerun the analysis of the selected or all solutions, make the chosen log (or all at once) reference, etc.
SelfTester's results are always duplicated in the html report (diffs report)
In addition to GUI, SelfTester also has automated modes for night build runs. However, the usual usage pattern repeated developer runs by a developer during the workday. Therefore, one of the most important SelfTester's characteristics is the speed of working.
Why speed matters:
It was performance speeding up that became the reason for refinements this time.
SelfTester was initially created as a multithreaded application with the ability to simultaneously test several solutions. The only limitation was that you couldn't simultaneously check the same solution for different Visual Studio versions, because many solutions need to be updated to certain versions of Visual Studio before testing. During the course of it, changes are introduced directly in files of the .vcxproj projects, which leads to errors during parallel running.
In order to make the work more efficient, SelfTester uses an intelligent task scheduler to set a strictly limited value of parallel threads and maintain it.
The planner is used on two levels. The first one is the level of solutions, it's used to start testing the .sln solution using the PVS-Studio_Cmd.exe utility. The same scheduler, but with another setting of parallelism degree, is used inside PVS-Studio_Cmd.exe (at the source files testing level).
The degree of parallelism is a parameter that indicates how many parallel threads have to be run simultaneously. Four and eight default values were chosen for the parallelism degree of the solutions and files level, respectively. Thus, the number of parallel threads in this implementation has to be 32 (4 simultaneously tested solutions and 8 files). This setting appears optimal to us for the analyzer work on an eight-core processor.
A developer can set other values of the parallelism degree himself according to his computer performance or current tasks. If a developer doesn't specify this parameter, the number of logical system processors will be chosen by default.
Note: let's further assume that we deal with the default degree of parallelism.
The scheduler LimitedConcurrencyLevelTaskScheduler is inherited from System.Threading.Tasks.TaskScheduler and refined to provide the maximum parallelism level when working over ThreadPool. Inheritance hierarchy:
LimitedConcurrencyLevelTaskScheduler : PausableTaskScheduler
{ .... }
PausableTaskScheduler: TaskScheduler
{ .... }PausableTaskScheduler allows you to pause task performance, and in addition to this, LimitedConcurrencyLevelTaskScheduler provides intellectual control of the tasks queue and scheduling their performance, taking into account the parallelism degree, the scope of the scheduled tasks and other factors. A scheduler is used when running LimitedConcurrencyLevelTaskScheduler tasks.
The process described above has a drawback: it is not optimal when dealing with solutions of different sizes. And the size of solutions in the test pool is very diverse: from 8KB to 4GB - the size of a folder with a solution and from 1 up to several thousands of source code files in each one.
The scheduler puts solutions on the queue simply one after another, without any intelligent component. Let me remind you that by default not more than four solutions can be tested simultaneously. If four large solutions are currently tested (the number of files in each is more than eight), it's assumed that we work effectively because we use as many threads as possible (32).
But let's imagine a rather frequent situation, when several small solutions are tested. For example, one solution is large and contains 50 files (maximum number of threads will be used), while other three solutions contain three, four, five files each. In this case, we'll only use 20 threads (8 + 3 + 4 + 5). We get underutilization of processor's time and reduced overall performance.
Note: in fact, the bottleneck is usually the disk subsystem, not the processor.
The improvement that is self-evident in this case is ranking of tested solutions list. We need to get optimal usage of the set number of simultaneously performed threads (32), by passing to test projects with the correct number of files.
Let's consider again our example of testing four solutions with the following number of files in each: 50, 3, 4 and 5. The task that checks a solution of three files is likely to work out the fastest. It would be best to add a solution with eight or more files instead of it (in order to use maximum from the available threads for this solution). This way, we'll utilize 25 threads at once (8 + 8 + 4 + 5). Not bad. However, seven threads are still uninvolved. And here comes the idea of another refinement, which is to remove the four threads limit on testing solutions. Because we now can add not one, but several solutions, utilizing 32 threads. Let's imagine that we have two more solutions of three and four files each. Adding these tasks will completely close the "gap" of unused threads, and there will be 32 (8 + 8 + 4 + 5 + 3 + 4) of them.
Hopefully the idea is clear. In fact, the implementation of these improvements also didn't require much effort. Everything was done in one day.
We needed to rework the task class: inheriting from System.Threading.Tasks.Task and assignment of the field "weight". We use a simple algorithm to set weight to a solution: if the number of files is less than eight, the weight is equal to this number (for example, 5). If the number is greater or equal to eight, the weight will be equal to eight.
We also had to elaborate the scheduler: teach it to choose solutions with needed weight in order to reach maximum value of 32 threads. We also had to allow more than four threads for simultaneous solutions testing.
Finally, we needed a preliminary step to analyze all solutions in the pool (evaluation using MSBuild API) to evaluate and set weight of solutions (getting numbers of files with source code).
I think after such a long introduction you've already guessed that nothing came of it.
It's good though that the improvements were simple and fast.
Here comes that part of the article, where I'm going to tell you about what "got us into many troubles" and all things related to it.
So, a negative result is also a result. It turned out that the number of large solutions in the pool far exceeds the number of small ones (less than eight files). In this case, these improvements don't have a very noticeable effect, as they are almost invisible: testing small projects takes teeny-tiny amount of time comparing to time, needed for large projects.
However, we decided to leave the new refinement as "non-disturbing" and potentially useful. In addition, the pool of test solutions is constantly replenished, so in the future, perhaps, the situation will change.
And then...
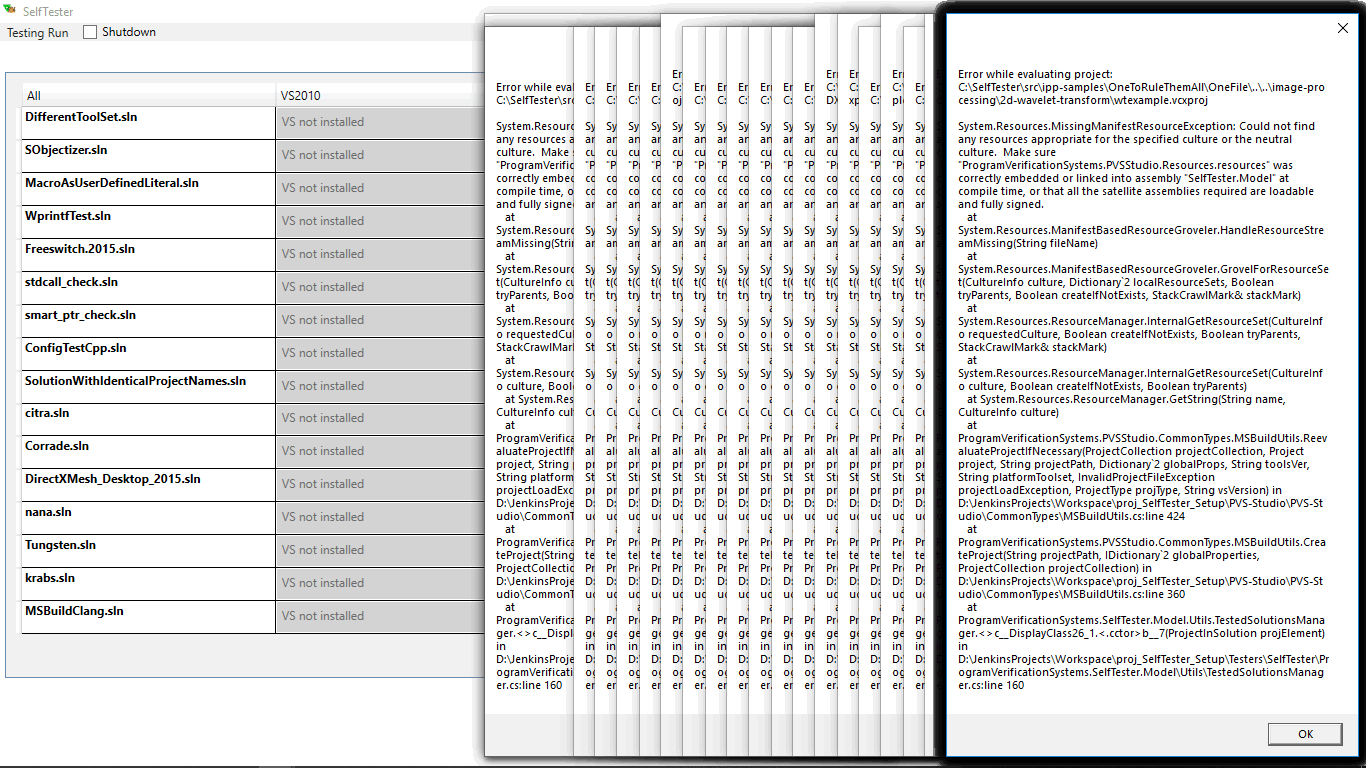
One of the developers complained about the SelfTester's crash. Well, life happens. To prevent this error from being lost, we created an internal incident (ticket) with the name "Exception when working with SelfTester". The error occurred while evaluating the project. Although a large number of windows with errors indicated the problem back in the error handler. But this was quickly eliminated, and over the next week nothing crashed. Suddenly, another user complained about SelfTester. Again, the error of a project evaluation:
This time the stack contained much useful information - the error was in the xml format. It's likely, that when handling the file of the Proto_IRC.vcxproj project (its xml representation) something happened to the file itself, that's why XmlTextReader couldn't handle it.
Having two errors in a fairly short period of time made us take a closer look at the problem. In addition, as I said above, SelfTester is very actively used by developers.
To begin with, we analyzed the last crash. Sad to say, we found nothing suspicious. Just in case we asked developers (SelfTester users) to keep an eye out and report about possible errors.
Important point: the erroneous code was reused in SelfTester. It was originally used to evaluate projects in the analyzer itself (PVS-Studio_Cmd.exe). That's why attention to the problem has grown. However, there were no such crashes in the analyzer.
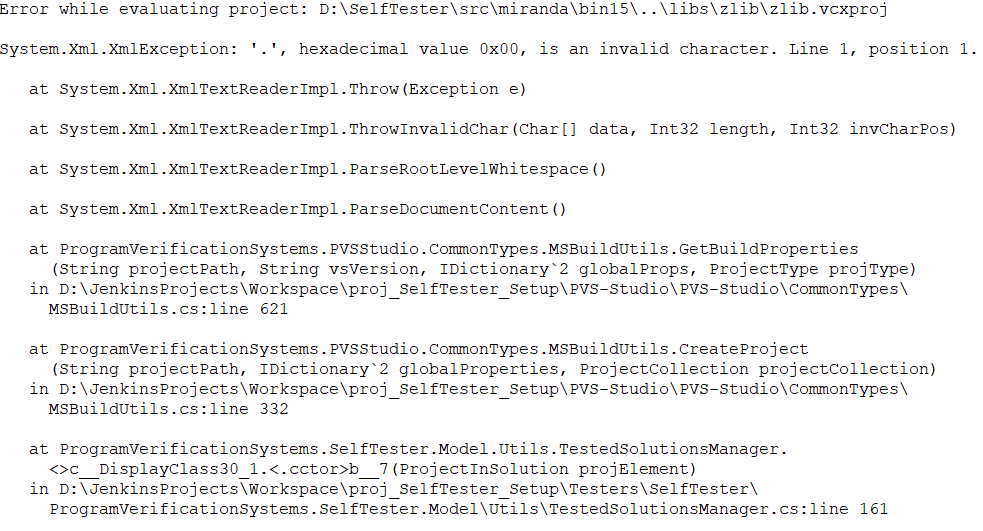
Meanwhile, the ticket about problems with SelfTester was supplemented with new errors:
XmlException again. Obviously, there are competing threads somewhere that work with reading and writing project files. SelfTester works with projects in the following cases:
Suspicion fell on the new code added for optimization (weight calculation). But its code investigation showed that if a user runs the analysis right after the start of SelfTester, the tester always correctly waits till the end of the pre-evaluation. This place looked safe.
Again, we were unable to identify the source of the problem.
All next month SelfTester continued to crash ever and again. The ticket kept filling with data, but it wasn't clear what to do with this data. Most crashes were with the same XmlException. Occasionally there was something else, but on the same reused code from PVS-Studio_Cmd.exe.
Traditionally, internal tools aren't imposed very high requirements, so we kept puzzling out SelfTester's errors on a residual principle. From time to time, different people got involved (during the whole incident six people worked on the problem, including two interns). However, we had to be distracted by this task.
Our first mistake. In fact, at this point we could've solved this problem once and for all. How? It was clear that the error was caused by a new optimization. After all, before it everything worked well, and the reused code clearly cannot be so bad. In addition, this optimization hadn't brought any benefit. So what had to be done? Remove this optimization. As you probably understand, it wasn't done. We continued to work on the problem, which we created ourselves. We continued searching for the answer: "HOW???" How does it crash? It seemed to be written correctly.
Our second mistake. Other people got involved in solving the problem. It's a very, very big mistake. Not only didn't it solve the problem but also required additional wasted resources. Yes, new people brought new ideas, but it took a lot of working time to implement (for nothing) these ideas. At some point, we had our interns writing test programs emulating evaluation of one and the same project in different threads with parallel modification of a project in another project. It didn't help. We only found out that MSBuild API was thread-safe inside, which we've already known. We also added mini dump auto saving when the XmlException exception occurs. We had someone who was debugging all this. Poor guy! There were discussions, we did other needless things.
Finally, out third mistake. Do you know how much time has passed from the moment the SelfTester problem occurred to the point when it was solved? Well, you can count yourself. The ticket was created on 17/09/2018 and closed on 20/02/2019. There were more than 40 comments! Guys, that's a lot of time! We allowed ourselves to be busy for five months with THIS. At the same time we were busy supporting Visual Studio 2019, adding the Java language support, introducing MISRA C/C++ standard, improving the C# analyzer, actively participating in conferences, writing a bunch of articles, etc. All these activities received less time of developers because of a stupid error in SelfTester.
Folks, learn from our mistakes and never do like this. We won't either.
That's it, I'm done.
Okay, it was a joke, I'll tell you what was the problem with SelfTester :)
Fortunately, there was a person among us with clear-eyed view (my colleague Sergey Vasiliev), who just looked at the problem from a very different angle (and also - he got a bit lucky). What if it's ok inside the SelfTester, but something from the outside crashes the projects? Usually we had nothing launched with SelfTester, in some cases we strictly controlled the execution environment. In this case, this very "something" could be SelfTester itself, but a different instance.
When exiting SelfTester, the thread that restores project files from references, continues to work for a while. At this point, the tester might be launched again. Protection against the simultaneous runs of several SelfTester instances was added later and now looks as follows:
But at that point we didn't have it.
Nuts, but true - during almost six months of torment no one paid attention to it. Restoring projects from references is a fairly fast background procedure, but unfortunately not fast enough not to interfere with the re-launch of SelfTester. And what happens when we launch it? That's right, calculating the weights of solutions. One process rewrites .vcxproj files while another tries to read them. Say hi to XmlException.
Sergey found out all this when he added the ability to switch to a different set of reference logs to the tester. It became necessary after adding a set of MISRA rules in the analyzer. You can switch directly in the interface, while the user sees this window:
After that, SelfTester restarts. And earlier, apparently, users somehow emulated the problem themselves, running the tester again.
Of course, we removed (that is, disabled) the optimization created earlier. In addition, it was much easier than doing some kind of synchronization between re-starts of the tester by itself. And everything started to work perfectly, as before. And as an additional measure, we added the above protection against the simultaneous launch of the tester.
I've already written above about our main mistakes when searching for the problem, so enough of self-flagellation. We're human beings, so we might be wrong. It is important to learn from your own mistakes and draw conclusions. The conclusions from this case are quite simple:
That's it, this time I'm definitely done. Thank you for reading up to the end. I wish you bugless code!
{kind=link}
{kind=link}