
Мы используем куки, чтобы пользоваться сайтом
было удобно.

После прочтения этой статьи вы будете обладать знаниями для создания своего собственного статического анализатора для C# кода, благодаря ему вы сможете найти потенциальные ошибки и уязвимости в исходном коде своих и не только проектов. Заинтригованы? Что ж, давайте начнём.

Сначала мы рассмотрим, как можно сделать свой статический анализатор из шаблонов, предлагаемых Visual Studio, не вдаваясь в детали Roslyn API. Это позволит быстро получить работающее приложение и хотя бы примерно посмотреть, что могут анализаторы.
И уже после этого мы несколько детальнее рассмотрим Roslyn API, а также различные средства, позволяющие проводить более глубокий и сложный анализ.
Уверен у многих разработчиков имеется пара ошибок, которые они или их знакомые часто допускают при написании кода. Скорее всего вам бы хотелось иметь инструмент, который без вашего участия находил подобные ошибки. Такие инструменты имеются и называются статические анализаторы.
Статический анализатор - это автоматический инструмент поиска потенциальных ошибок и уязвимостей в исходном коде программ без ее непосредственного запуска.
Однако, что делать, если существующие анализаторы не могут найти то, что вам хочется? Ответ прост - написать свою собственную утилиту или даже целый анализатор. В этом плане C# программистам значительно повезло, потому что благодаря Roslyn каждый может создать свой статический анализатор. Именно этим мы и займемся далее в статье.
Вся наша дальнейшая разработка статического анализатора будет базироваться на .NET Compiler Platform aka Roslyn. Именно за счёт возможностей, которые предоставляет эта платформа, мы за считанные минуты можем создавать свои инструменты для статического анализа, используя C#. Слово "статический" в нашем контексте означает, что код, который будет анализироваться, не нужно запускать на исполнение.
Так как наш анализатор будет основан на Roslyn, нам следует установить .NET Compiler Platform SDK для Visual Studio. Один из способов, как мы можем это сделать, – открыть Visual Studio Installer и во вкладке "Workloads" выбрать "Visual Studio extension development".

После того, как мы выполнили установку необходимого toolset'а, мы можем приступить к созданию анализатора.
Открываем Visual Studio, нажимаем на "Create a new project", далее выбираем язык C#, в качестве платформы указываем Windows, а в типе проекта выбираем Roslyn. После этого мы должны увидеть три шаблона проектов, из которых нас интересуют два: "Analyzer with Code Fix (.NET Standard)" и "Standalone Code Analysis Tool".

Поочередно изучим каждый из этих шаблонов.
После того как мы создали новый проект с использованием шаблона "Analyzer with Code Fix (.NET Standard)", нас встречает solution с пятью проектами внутри.

Сейчас наше основное внимание будет уделено первому проекту с названием TestAnalyzer. Это, собственно, и есть проект, где будет находиться основная логика нашего статического анализатора. Открываем файл TestAnalyzerAnalyzer.cs. В нём уже находится пример простого правила для статического анализатора. Суть этого правила – просматривать все имена типов (классов) в исходном коде и подчёркивать их зелёной волнистой линией, если в имени типа присутствуют символы нижнего регистра. Помимо этого, если навести курсор на имя типа, отмеченного зелёной волнистой линией, мы увидим знакомый символ лампочки. Он предложит нам автоматически исправить название типа и привести все его символы к верхнему регистру:

Самый простой способ увидеть описанное выше вживую (этот же принцип можно использовать и для отладки) – запустить новый экземпляр VS, в который уже будет встроено наше тестовое диагностическое правило. Для этого отметим TestAnalyzer.vsix как запускаемый проект и запустим приложение. После этого будет открыто окно с так называемым экспериментальным экземпляром Visual Studio. В этом экземпляре VS уже будет добавлено наше диагностическое правило. Интегрируется оно с помощью установленного VSIX расширения, имеющего имя нашего тестового анализатора.

Далее в запущенном экземпляре VS создадим новый консольный проект. В нем мы увидим, что имя класса Program подчёркнуто зелёной волнистой линией – это работает наше диагностическое правило, так как имя класса содержит символы нижнего регистра.
Давайте теперь создадим новый проект типа "Standalone Code Analysis Tool". На деле это проект обычного консольного приложения со ссылками на необходимые DLL для проведения анализа:
Из файла Program.cs можно удалить все методы кроме Main.
Давайте напишем статический анализатор таким образом, чтобы, к примеру, он мог находить операторы if, где истинная и ложная ветви полностью совпадают. Вы скажете, что подобных ошибок никто не совершает? Удивительно, но это достаточно распространённый паттерн – взгляните на список подобных ошибок, найденных в open source проектах.
Допустим, нас не устраивает, если в коде встречается подобный фрагмент:
public static void MyFunc1(int count)
{
if (count > 100)
{
Console.WriteLine("Hello world!");
}
else
{
Console.WriteLine("Hello world!");
}
}Поэтому мы сделаем так, чтобы при обнаружении подобного кода анализатор записывал в лог-файл номер строки и полный путь до исходного файла. Перейдем к написанию кода:
static void Main(string[] args)
{
if (args.Length != 2)
return;
string solutionPath = args[0];
string logPath = args[1];
StringBuilder warnings = new StringBuilder();
const string warningMessageFormat =
"'if' with equal 'then' and 'else' blocks is found in file {0} at line {1}";
MSBuildLocator.RegisterDefaults();
using (var workspace = MSBuildWorkspace.Create())
{
Project currProject = GetProjectFromSolution(solutionPath, workspace);
foreach (var document in currProject.Documents)
{
var tree = document.GetSyntaxTreeAsync().Result;
var ifStatementNodes = tree.GetRoot()
.DescendantNodesAndSelf()
.OfType<IfStatementSyntax>();
foreach (var ifStatement in ifStatementNodes)
{
if (ApplyRule(ifStatement))
{
int lineNumber = ifStatement.GetLocation()
.GetLineSpan()
.StartLinePosition.Line + 1;
warnings.AppendLine(String.Format(warningMessageFormat,
document.FilePath,
lineNumber));
}
}
}
if (warnings.Length != 0)
File.AppendAllText(logPath, warnings.ToString());
}
}Так как в данном случае мы имеем консольное приложение, а не плагин для VS, нашему анализатору нужно указать путь до самого solution файла, который мы собираемся анализировать. Для получения solution используется класс MSBuildWorkspace и метод OpenSolutionAsync. В свою очередь, класс Solution содержит в себе свойство Projects, в котором хранятся сущности проектов. В моём случае я создал новый solution с одним проектом консольного приложения. Поэтому для получения сущности одного проекта я написал следующий метод:
static Project GetProjectFromSolution(String solutionPath,
MSBuildWorkspace workspace)
{
Solution currSolution = workspace.OpenSolutionAsync(solutionPath)
.Result;
return currSolution.Projects.Single();
}При обзоре шаблона проекта "Analyzer with Code Fix" мы не изменяли предоставленный код шаблона, но сейчас мы сами хотим написать правило, согласно которому будет работать наш статический анализатор. В связи с этим необходимо разъяснить несколько теоретических моментов.
Сам Roslyn хранит представления исходных файлов в виде деревьев. Взглянем на следующий пример кода:
if (number > 0)
{
}Roslyn представит его в виде дерева со следующей структурой:

Синим на рисунке изображены узлы дерева. В нашем случае с ними и пойдёт дальнейшая работа. У Roslyn подобные деревья представлены объектами типа SyntaxTree. Как можно видеть из рисунка, узлы дерева различаются и каждый из них представлен своим типом. Например, узел IfStatement у Roslyn представлен объектом класса IfStatementSyntax. Все узлы в своей иерархии наследования берут начало от класса SyntaxNode, а уже потом дополняют его какими-то специфическими для себя свойствами и методами. К примеру, класс IfStatementSyntax содержит свойство с названием Condition (в свою очередь, являющееся узлом типа ExpressionSyntax), что является вполне логичным для объекта, представляющего условную конструкцию if.
Проводя работу с нужными нам узлами дерева, мы можем составлять логику для правил, по которым будет работать наш статический анализатор. К примеру, для того чтобы определить, в каких IfStatement в проекте истинная и ложная ветви полностью совпадают, необходимо совершить следующие действия:
Исходя из описанного выше алгоритма, можно написать метод ApplyRule:
static bool ApplyRule(IfStatementSyntax ifStatement)
{
if (ifStatement?.Else == null)
return false;
StatementSyntax thenBody = ifStatement.Statement;
StatementSyntax elseBody = ifStatement.Else.Statement;
return SyntaxFactory.AreEquivalent(thenBody, elseBody);
}В результате мы смогли написать правило, которое позволит нам больше не беспокоиться об ошибках копипаста в if-else ветвлениях.
На мой взгляд, свой выбор стоит основывать на том, что вам необходимо получить от анализатора.
Если вы пишете статический анализатор, который должен следить за соблюдением code style'а, принятого в вашей компании, то здесь, очевидно, больше подходит проект типа "Analyzer with Code Fix". Ведь ваш анализатор будет удобно интегрирован в среду VS как расширение, и разработчики будут видеть результаты его работы прямо при написании кода. К тому же, с помощью API от Roslyn вы сможете реализовать отображение подсказок (как следует изменить код) и даже его автоматическое исправление.
Проект типа "Standalone Code Analysis Tool" стоит выбирать в том случае, если вы планируете использовать анализатор как отдельное приложение (в противовес всегда работающему анализатору в виде расширения в VS). Скажем, если вы хотите встроить его в ваш CI процесс и тестировать проекты на выделенном сервере. Также в пользу выбора этого типа проекта может играть тот факт, что анализатор в виде расширения для VS будет существовать внутри процесса devenv.exe, являющегося 32-битным, а это накладывает серьёзные ограничения на объём используемой памяти. Анализатору в виде отдельного приложения такие ограничения нестрашны. Однако не следует забывать и про Visual Studio 2022, которую Microsoft обещает сделать 64-битной. Соответственно, упомянутые выше ограничения на потребление памяти не должны быть страшны, если вы будете делать анализатор под эту версию IDE.
Информация в данной статье поможет быстро написать свой статический анализатор, который будет решать ваши проблемы. Если же вы хотите не просто решать свои частные задачи, а планируете выявлять широкий спектр дефектов в коде, то вам придется потратить много времени и сил, чтобы изучить и научиться применять такие технологии как анализа потока данных, символьные вычисления, аннотирование методов и так далее. Только после этого ваш анализатор, сможет соперничать с платными аналогами и станет полезен большому количеству программистов. Если же вы не хотите тратить столько времени и сил на это, то можете воспользоваться одним из уже существующих статических анализаторов. Их достаточно много: как коммерческих, так и бесплатных: List of tools for static code analysis. Чтобы представить возможности таких инструментов, можно обратиться, например, к статье "ТОП-10 ошибок, найденных в C#-проектах за 2020 год"
Помимо этого, не надо забывать, что подобные анализаторы могут предоставлять часть своего функционала через дополнительные расширения для различных IDE. Ведь это удобно, если плагин позволяет запускать анализатор без необходимости сворачивания редактора и запуска отдельного приложения или даёт возможность просмотра результатов анализа прямо в IDE.
Итак, мы изучили шаблоны, которые предоставляет Visual Studio для создания статического анализатора кода. Теперь же более займёмся рассмотрением Roslyn API, чтобы мы могли эффективно и правильно его использовать. Первое, с чем нам необходимо познакомится - синтаксическое дерево.
На основе исходного кода для каждого .cs файла строится своё синтаксическое дерево. Одно из представлений этого дерева можно увидеть в окне Syntax Visualizer. Если вы уже установили .NET Compiler Platform SDK для вашей Visual Studio, то найти это окно можно во вкладке View -> Other Windows -> Syntax Visualizer.

Это очень полезный инструмент, особенно для тех, кто только начинает знакомиться со структурой дерева и типами элементов, представленных в нём. При перемещении по коду в редакторе Visual Studio, Syntax Visualizer будет переходить на соответствующий фрагменту кода элемент дерева и подсвечивать его. Также это окно показывает некоторые свойства для текущего выделенного элемента. Например, на скриншоте, приведённом выше, для выделенного элемента MethodDeclaration мы можем видеть его конкретный тип: MethodDeclarationSyntax.
Для ещё более наглядной визуализации дерева можно вызвать контекстное меню на выбранном элементе в окне Syntax Visualizer и нажать "View Directed Syntax Graph". В результате откроется окно с визуализацией синтаксического дерева, построенного для выбранного элемента:
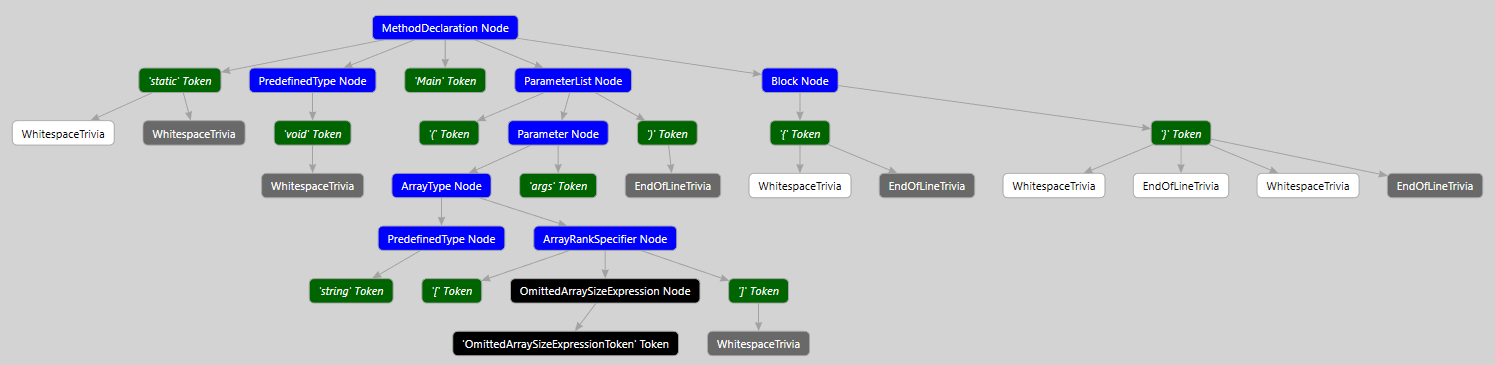
Если вы не видите данного элемента в контекстном меню, то вам следует установить редактор DGML. Установить его можно через Visual Studio Installer. Откройте Visual Studio Installer, напротив нужного экземпляра VS выберите More -> Modify. Затем перейдите на вкладку Individual Component -> Code tools -> DGML editor.
Однако, даже у этого полезного инструмента имеется пара нюансов:
Ранее в статье уже было показано синтаксическое дерево, которое построит Rolsyn для C# кода:
if (number > 0)
{
}
Из рисунка видно, что дерево состоит из элементов, представленных четырьмя цветами. На самом деле, все элементы деревьев можно разделить на 3 группы:
Рассмотрим каждый тип элемента дерева более подробно.
Syntax nodes (далее узлы) представляют синтаксические конструкции, такие как объявления, операторы, выражения и т. д. Основная работа, происходящая при анализе кода, приходится на обработку узлов. Базовым типом узлов является абстрактный класс SyntaxNode. Каждый узел, представляющий ту или иную конструкцию языка, имеет свой тип, унаследованный от SyntaxNode. Он определяет ряд свойств, упрощающих работу с деревом. Вот некоторые из типов вместе с соответствующими им конструкциями языка:
Например, класс IfStatementSyntax помимо функционала, который был унаследован от класса SyntaxNode, имеет такие полезные свойства, как Condition (узел, представляющий условие оператора), Statement (узел, представляющий тело оператора if) и Else (узел, представляющий блок else).
Сам абстрактный класс SyntaxNode предоставляет в распоряжение разработчика методы, общие для всех узлов. Вот некоторые из них:
Помимо этого, в классе определен ряд свойств. Одно из наиболее часто использующихся среди них - Parent, содержащее ссылку на родительский узел.
При создании правила на основе шаблона проекта "Standalone Code Analysis Tool" мы получали узлы (типа IfStatementSyntax), с которыми работали путём обращения к корню дерева и последующего LINQ запроса для отбора всех узлов необходимых нам для анализа. Существует более элегантное решение –использование класса CSharpSyntaxWalker. CSharpSyntaxWalker – это абстрактный класс, который при вызове метода Visit будет осуществлять обход переданного ему узла и его узлов-потомков. CSharpSyntaxWalker обходит дерево в глубину, при этом для каждого встреченного узла вызывается соответствующий типу узла виртуальный метод. Например, для экземпляра типа ClassDeclarationSyntax будет вызван метод VisitClassDeclaration, принимающий узел этого типа в качестве параметра. Наша же задача заключается в том, чтобы создать класс, наследуемый от класса CSharpSyntaxWalker, и переопределить нужный нам метод, вызываемый при посещении той или иной конструкции языка C#.
public class IfWalker : CSharpSyntaxWalker
{
public StringBuilder Warnings { get; } = new StringBuilder();
const string WarningMessageFormat =
"'if' with equal 'then' and 'else' blocks is found in file {0} at line {1}";
static bool ApplyRule(IfStatementSyntax ifStatement)
{
if (ifStatement.Else == null)
return false;
StatementSyntax thenBody = ifStatement.Statement;
StatementSyntax elseBody = ifStatement.Else.Statement;
return SyntaxFactory.AreEquivalent(thenBody, elseBody);
}
public override void VisitIfStatement(IfStatementSyntax node)
{
if (ApplyRule(node))
{
int lineNumber = node.GetLocation()
.GetLineSpan()
.StartLinePosition.Line + 1;
Warnings.AppendLine(String.Format(WarningMessageFormat,
node.SyntaxTree.FilePath,
lineNumber));
}
base.VisitIfStatement(node);
}
}Обратите внимание, что переопределённый метод VisitIfStatement внутри себя вызывает метод base.VisitIfStatement. Это необходимо потому, что базовые реализации Visit-методов запускают обход дочерних узлов. Если же вам необходимо прекратить обход дочерних узлов, то базовую реализацию этого метода вызывать не стоит при переопределении метода.
Создадим какой-нибудь метод, который будет запускать обход дерева нашим экземпляром класса IfWalker:
public static void StartWalker(IfWalker ifWalker, SyntaxNode syntaxNode)
{
ifWalker.Warnings.Clear();
ifWalker.Visit(syntaxNode);
}И вот как в данном случае будет выглядеть наш метод Main:
static void Main(string[] args)
{
string solutionPath = @"D:\Test\TestApp.sln";
string logPath = @"D:\Test\warnings.txt";
MSBuildLocator.RegisterDefaults();
usng (var workspace = MSBuildWorkspace.Create())
{
Project project = GetProjectFromSolution(solutionPath, workspace);
foreach (var document in project.Documents)
{
var tree = document.GetSyntaxTreeAsync().Result;
var ifWalker = new IfWalker();
StartWalker(ifWalker, tree.GetRoot());
var warnings = ifWalker.Warnings;
if (warnings.Length != 0)
File.AppendAllText(logPath, warnings.ToString());
}
}
}Какой именно способ использовать для получения узлов для анализа, решать вам. Будет ли это LINQ запрос или переопределение методов класса CSharpSyntaxWalker, которые будут вызываться при посещении определенных C# узлов, зависит только от того, что больше подходит вам под текущие задачи. На мой взгляд, переопределять методы обхода класса CSharpSyntaxWalker стоит тогда, когда в анализаторе будет много диагностических правил. Если утилита для анализа совсем простая и нацелена на обработку одного конкретного типа узла, то можно воспользоваться LINQ запросом, чтобы собрать все необходимые C# узлы.
Syntax tokens (далее – лексемы) являются терминалами грамматики языка. Лексемы представляют собой элементы, которые не подлежат дальнейшему разбору – идентификаторы, ключевые слова, специальные символы. В ходе анализа кода напрямую с ними приходится работать куда реже, чем с узлами дерева. При анализе лексемы используются, например, для получения их текстового представления или же проверки типа лексемы. Лексемы являются листами дерева, то есть у них нет дочерних узлов. Кроме этого, лексемы являются экземплярами структуры SyntaxToken, то есть не наследуются от SyntaxNode. Однако, как и узлы лексемы могут иметь syntax trivia, которые описываются в одном из следующих разделов статьи.
Основными свойствами структуры SyntaxToken являются:
Создадим простое диагностическое правило, в котором будут использоваться syntax tokens. Это правило будет срабатывать, если имя метода начинается не с заглавной буквы:
class Program
{
const string warningMessageFormat =
"Method name '{0}' does not start with capital letter " +
"in file {1} at {2} line";
static void Main(string[] args)
{
if (args.Length != 2)
return;
string solutionPath = args[0];
string logPath = args[1];
StringBuilder warnings = new StringBuilder();
MSBuildLocator.RegisterDefaults();
using (var workspace = MSBuildWorkspace.Create())
{
Project project = GetProjectFromSolution(solutionPath, workspace);
foreach (var document in project.Documents)
{
var tree = document.GetSyntaxTreeAsync().Result;
var methods = tree.GetRoot()
.DescendantNodes()
.OfType<MethodDeclarationSyntax>();
foreach (var method in methods)
{
if (ApplyRule(method, out var methodName))
{
int lineNumber = method.Identifier
.GetLocation()
.GetLineSpan()
.StartLinePosition.Line + 1;
warnings.AppendLine(String.Format(warningMessageFormat,
methodName,
document.FilePath,
lineNumber));
}
}
}
}
if (warnings.Length != 0)
File.WriteAllText(logPath, warnings.ToString());
}
static bool ApplyRule(MethodDeclarationSyntax node, out string methodName)
{
methodName = node.Identifier.Text;
return methodName.Length != 0 && !char.IsUpper(methodName[0]);
}
}В этом правиле для выяснения того, что имя метода не начинается с заглавной буквы используется свойство Identifier класса MethodDeclarationSyntax. В этом свойстве хранится лексема, у которой производится проверка первого символа ее текстового представления.
Syntax trivia (дополнительная синтаксическая информация) – это такие элементы дерева, как комментарии, директивы препроцессора, а также различные элементы форматирования (пробелы, символы перевода строки). Эти узлы дерева не являются потомками класса SyntaxNode. Элементы syntax trivia не попадут в IL-код. Однако они представлены в синтаксическом дереве. Благодаря этому из имеющегося дерева можно получить полностью идентичный исходному код вместе со всеми элементами, содержащимися во всех экземплярах структуры SyntaxTrivia. Это свойство дерева называется full fidelity. Элементы syntax trivia всегда относятся к какой-нибудь лексеме. Разделяют Leading trivia и Trailing trivia. Leading trivia – предшествующая лексеме дополнительная синтаксическая информация. Trailing trivia – дополнительная синтаксическая информация, следующая за лексемой. Все элементы дополнительной синтаксической информации имеют тип SyntaxTrivia. Для определения того, чем конкретно является элемент (пробел, однострочный комментарий, многострочный комментарий и пр.), используется перечисление SyntaxKind в связке с методом Kind и IsKind.
Взгляните на следующий код:
#if NETCOREAPP3_1
b = 10;
#endif
//Comment1
a = b;Вот как будет выглядеть directed syntax graph для приведённого кода:
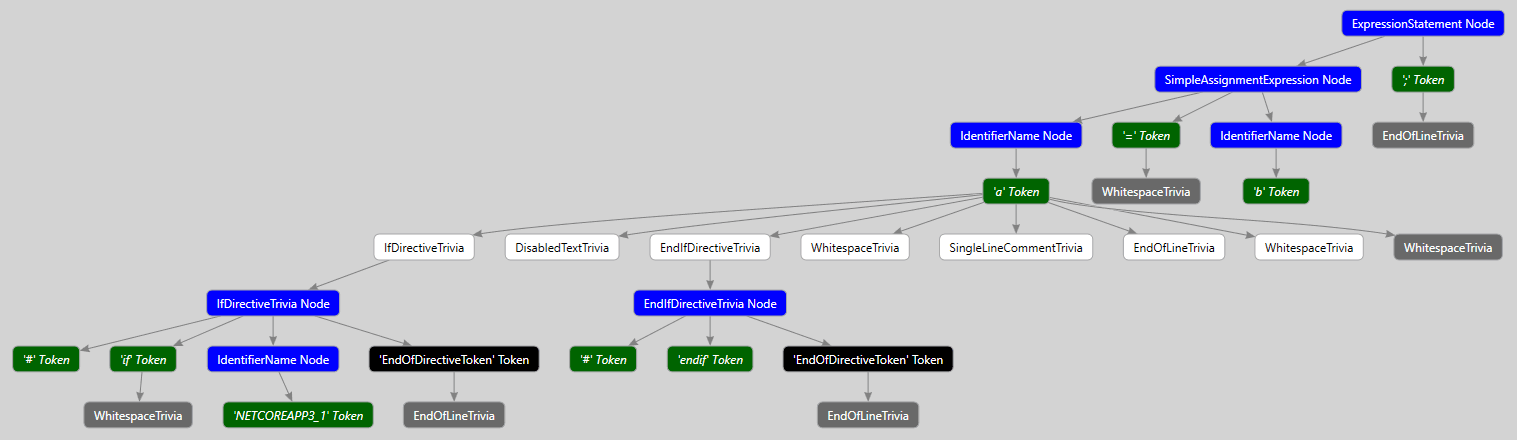
Можно видеть, что к лексеме 'a' относятся такие syntax trivia, как директивы препроцессора #if NETCOREAPP3_1 и #endif, сам текст внутри этих директив, символы пробела и конца строки, а также однострочный комментарий. Лексема '=' имеет только один прикреплённый к ней элемент syntax trivia – символ пробела. А к лексеме ';' относится символ конца строки.
Кроме диагностических правил, основанных на анализе узлов дерева, также возможно создавать правила, которые будут анализировать элементы syntax trivia. Допустим, в компании появилось новое правило для стандарта кодирования: не писать комментарии, длина которых превышает 130 символов. Мы решили проверить наш проект на наличие подобных "запрещённых" комментариев с помощью простенького анализатора, который опирается на разбор элементов syntax trivia. Структура кода получившегося правила почти идентична коду правила, которое мы создали на основе шаблона проекта "Standalone Code Analysis Tool". Только теперь вместо метода DescendantNodes вызывается метод DescendantTrivia (ведь сейчас нам нужны комментарии). И далее отбираются только те SyntaxTrivia, тип которых либо SingleLineCommentTrivia, либо MultiLineCommentTrivia, либо SingleLineDocumentationCommentTrivia:
....
var comTriv = tree.GetRoot().DescendantTrivia()
.Where(n => n.IsKind(SyntaxKind.SingleLineCommentTrivia)
|| n.IsKind(SyntaxKind.
SingleLineDocumentationCommentTrivia)
|| n.IsKind(SyntaxKind.MultiLineCommentTrivia));
....Также были добавлены новые форматные сообщения SingleLineCommentFormatMessage и MultiLineCommentFormatMessage для однострочных и многострочных комментариев соответственно:
const string PleaseBreakUpMessage = "Please, break up it on several lines.";
string SingleLineCommentFormatMessage =
"Length of a comment at line {0} in file {1} exceeds {2} characters. "
+ PleaseBreakUpMessage;
string MultiLineCommentFormatMessage =
"Multiline comment or XML comment at line {0} in file {1} contains "
+ "individual lines that exceeds {2} characters."
+ PleaseBreakUpMessage;И последнее, что изменилось, это метод ApplyRule:
void ApplyRule(SyntaxTrivia commentTrivia, StringBuilder warnings)
{
const int MaxCommentLength = 130;
const string PleaseBreakUpMessage = ....;
string SingleLineCommentFormatMessage = ....;
string MultiLineCommentFormatMessage = ....;
switch (commentTrivia.Kind())
{
case SyntaxKind.SingleLineCommentTrivia:
case SyntaxKind.SingleLineDocumentationCommentTrivia:
{
if (commentTrivia.ToString().Length > MaxCommentLength)
{
int line = commentTrivia.GetLocation().GetLineSpan()
.StartLinePosition.Line + 1;
string filePath = commentTrivia.SyntaxTree.FilePath;
var message = String.Format(SingleLineCommentFormatMessage,
line,
filePath,
MaxCommentLength);
warnings.AppendLine(message);
}
break;
}
case SyntaxKind.MultiLineCommentTrivia:
{
var listStr = commentTrivia.ToString()
.Split(new string[] { Environment.NewLine },
StringSplitOptions.RemoveEmptyEntries
);
foreach (string str in listStr)
{
if (str.Length > MaxCommentLength)
{
int line = commentTrivia.GetLocation().GetLineSpan()
.StartLinePosition.Line + 1;
string filePath = commentTrivia.SyntaxTree.FilePath;
var message = String.Format(MultiLineCommentFormatMessage,
line,
filePath,
MaxCommentLength);
warnings.AppendLine(message);
}
}
break;
}
}
}Теперь метод ApplyRule проверяет, что длина строки однострочного комментария не превышает 130 символов, для многострочных же проверяется каждая отдельная строка комментария. Если условие выполняется, то в warnings добавляется соответствующее сообщение.
В результате метод Main, предназначенный для поиска комментариев, где строки превышают длину в 130 символов, имеет такой код:
static void Main(string[] args)
{
string solutionPath = @"D:\Test\TestForTrivia.sln";
string logPath = @"D:\Test\warnings.txt";
MSBuildLocator.RegisterDefaults();
using (var workspace = MSBuildWorkspace.Create())
{
StringBuilder warnings = new StringBuilder();
Project project = GetProjectFromSolution(solutionPath, workspace);
foreach (var document in project.Documents)
{
var tree = document.GetSyntaxTreeAsync().Result;
var comTriv = tree.GetRoot()
.DescendantTrivia()
.Where(n =>
n.IsKind(SyntaxKind.SingleLineCommentTrivia)
|| n.IsKind( SyntaxKind
.SingleLineDocumentationCommentTrivia)
|| n.IsKind(SyntaxKind.MultiLineCommentTrivia));
foreach (var commentTrivia in comTriv)
ApplyRule(commentTrivia, warnings);
}
if (warnings.Length != 0)
File.AppendAllText(logPath, warnings.ToString());
}
}Кроме комментариев, также возможно написать правило, ищущее директивы препроцессора. Для определения содержания директив препроцессора в узле можно воспользоваться все тем же методом IsKind:
methodDeclaration.DescendantTrivia()
.Any(trivia => trivia.IsKind(SyntaxKind.IfDirectiveTrivia));До этого мы проводили анализ исходных файлов, полностью опираясь на синтаксическое дерево и обход его элементов. Во многих случаях для того, чтобы проводить глубокий анализ, обхода одного синтаксического дерева недостаточно. Тут на сцену выходит такое понятие, как семантическая модель. Семантическая модель (объект типа SemanticModel) получается из компиляции с использованием синтаксического дерева. Для этого используется метод Compilation.GetSemanticModel, принимающий в качестве обязательного параметра объект типа SyntaxTree.
Семантическая модель предоставляет информацию о различного рода сущностях, таких как методы, локальные переменные, поля, свойства и т. п. Для получения корректной семантической модели нужно, чтобы проект мог быть скомпилирован без ошибок.
Итак, для получения семантической модели нам нужен экземпляр класса Compilation. Один из способов получения объекта компиляции – вызов метода GetCompilationAsync у экземпляра класса Project (про получение и использование экземпляра этого класса рассказывалось ранее в статье):
Compilation compilation = project.GetCompilationAsync().Result;Для получения самой семантической модели следует вызвать метод GetSemanticModel у объекта компиляции и передать ему объект типа SyntaxTree:
SemanticModel model = compilation.GetSemanticModel(tree);Другим способом получения семантической модели является вызов метода Create у класса CSharpCompilation (в последующих примерах кода мы используем именно его).
Семантическая модель предоставляет доступ к так называемым символам (symbols), которые в свою очередь позволяют получать необходимую для анализа информацию о самой сущности (будь то свойство, метод или ещё что-то). Символы можно разделить на две категории:
Каждый символ содержит информацию о том, в каком типе и в каком пространстве имён определён конкретный элемент. Можно узнать, где именно был определён тот или иной элемент: в исходном коде, к которому есть доступ, или во внешней библиотеке. Помимо этого, можно получить информацию о том, является ли анализируемый элемент статическим, виртуальным и т. п. Вся эта информация предоставляется через функционал базового интерфейса ISymbol.
В качестве примера использования семантической модели рассмотрим случай, когда для проведения анализа нам нужно понять, является ли вызываемый метод переопределённым, то есть был ли он помечен модификатором override при объявлении. Как раз в этом случае нам и понадобится символ:
static void Main(string[] args)
{
string codeStr =
@"
using System;
public class ParentClass
{
virtual public void Mehtod1()
{
Console.WriteLine(""Hello from Parent"");
}
}
public class ChildClass: ParentClass
{
public override void Method1()
{
Console.WriteLine(""Hello from Child"");
}
}
class Program
{
static void Main(string[] args)
{
ChildClass childClass = new ChildClass();
childClass.Mehtod1();
}
}";
static SemanticModel GetSemanticModelFromCodeString(string codeString)
{
SyntaxTree tree = SyntaxFactory.ParseSyntaxTree(codeStr);
var msCorLibLocation = typeof(object).Assembly.Location;
var msCorLib = MetadataReference.CreateFromFile(msCorLibLocation);
var compilation = CSharpCompilation.Create("MyCompilation",
syntaxTrees: new[] { tree }, references: new[] { msCorLib });
return compilation.GetSemanticModel(tree);
}
var model = GetSemanticModelFromCodeString(codeStr);
var methodInvocSyntax = model.SyntaxTree.GetRoot()
.DescendantNodes()
.OfType<InvocationExpressionSyntax>();
foreach (var methodInvocation in methodInvocSyntax)
{
var methodSymbol = model.GetSymbolInfo(methodInvocation).Symbol;
if (methodSymbol.IsOverride)
{
//Apply your additional logic for analyzing method.
}
}
}Метод GetSemanticModelFromCodeString парсит строку C# кода переданную в параметре и получает синтаксическое дерево для неё. После создается объект типа CSharpCompilation, который является результатом компиляции синтаксического дерева, полученного из строки кода codeStr. Для проведения компиляции вызывается метод CSharpCompilation.Create. В этот метод передается массив синтаксических деревьев (исходный код, который надо скомпилировать) и ссылки на библиотеки. Для компиляции строки кода codeStr необходима ссылка только на библиотеку базовых классов языка C# - mscorlib.dll. После при помощи вызова метода CSharpCompilation.GetSemanticModel возвращается объект семантической модели. Семантическая модель используется для получения структуры SymbolInfo для узла, соответствующего вызову метода. Для этого у объекта модели зовется метод GetSymbolInfo, в который передается узел. После у объекта структуры SymbolInfo вызывается свойство Symbol, которое возвращает объект символа, содержащий семантическую информацию об узле, переданном в метод GetSymbolInfo. Получив символ, мы можем обратиться к его свойству IsOverride и определить, помечен ли метод модификатором override.
Кто-нибудь из читателей может предложить другой вариант того, как можно определить, является ли метод переопределённым без использования семантической модели:
....
var methodDeclarsSyntax = model.SyntaxTree.GetRoot()
.DescendantNodes()
.OfType<MethodDeclarationSyntax>();
....
foreach(var methodDeclaration in methodDeclarsSyntax)
{
var modifiers = methodDeclaration.Modifiers;
bool isOverriden =
modifiers.Any(modifier => modifier.IsKind(SyntaxKind.OverrideKeyword));
}Такой способ тоже работает, но в меньшем количестве случаев. Например, если объявление метода было сделано не в исходном файле, для которого было получено синтаксическое дерево, то мы не сможем получить декларацию для нужного нам метода. Ещё более показательным является случай, когда вызываемый метод объявлен во внешней библиотеке – здесь без использования семантической модели уже никак не обойтись.
Существует ряд производных типов, из которых можно получать более специфическую информацию об объекте. К таким интерфейсам относятся IFieldSymbol, IPropertySymbol, IMethodSymbol и прочие. Приведя объект ISymbol к более специфичному интерфейсу, нам станут доступны свойства специфичные для данного интерфейса.
Например, используя приведение к интерфейсу IFieldSymbol, можно обратиться к полю IsConst и таким образом узнать, является ли узел константным полем. А если использовать интерфейс IMethodSymbol, то можно, например, узнать, возвращает ли метод какое-либо значение.
Для символов определено свойство Kind, возвращающее элементы перечисления SymbolKind. С помощью этого свойства можно узнать, с чем мы сейчас работаем: локальным объектом, полем, свойством, сборкой и пр. Также в большинстве случаев значение свойства Kind соответствует конкретному типу символа. Как раз это особенность и используется в коде ниже:
static void Main(string[] args)
{
string codeStr =
@"
public class MyClass
{
public string MyProperty { get; }
}
class Program
{
static void Main(string[] args)
{
MyClass myClass = new MyClass();
myClass.MyProperty;
}
}";
....
var model = GetSemanticModelFromCodeString(codeStr);
var propertyAccessSyntax = model.SyntaxTree.GetRoot().DescendantNodes()
.OfType<MemberAccessExpressionSyntax>()
.First();
var symbol = model.GetSymbolInfo(propertyAccessSyntax).Symbol;
if (symbol.Kind == SymbolKind.Property)
{
var pSymbol = (IPropertySymbol)symbol;
var isReadOnly = pSymbol.IsReadOnly; //true
var type = pSymbol.Type; // System.String
}
}После приведения символа к IPropertySymbol, мы можем обратиться к свойствам, которые помогают получить дополнительную информацию. Опять же, для простоты примера обращение к свойству MyProperty происходит в том же исходном файле, где находится его объявление, а значит, информацию о том, что у свойства нет сеттера, можно получить и без использования семантической модели. Если объявление свойства находится в другом файле или библиотеке, то обращение к семантической модели уже является неизбежным.
В тех случаях, когда необходимо получить информацию о типе объекта, представляемого узлом, можно воспользоваться интерфейсом ITypeSymbol. Для его получения используется метод GetTypeInfo объекта типа SemanticModel. Вообще этот метод возвращает структуру TypeInfo, содержащую 2 важных свойства:
Приведём пример того, как можно получить тип свойства, которому присваивается значение:
static void Main(string[] args)
{
string codeStr =
@"
public class MyClass
{
public string MyProperty { get; set; }
public MyClass(string value)
{
MyProperty = value;
}
}";
....
var model = GetSemanticModelFromCodeString(codeStr);
var assignmentExpr = model.SyntaxTree.GetRoot().DescendantNodes()
.OfType<AssignmentExpressionSyntax>()
.First();
ExpressionSyntax left = assignmentExpr.Left;
ITypeSymbol typeOfMyProperty = model.GetTypeInfo(left).Type;
}Используя интерфейс ITypeSymbol, возвращаемый этими свойствами, можно получить всю интересующую информацию о типе. Эта информация извлекается за счёт обращения к свойствам, некоторые из которых приведены ниже:
Обращение к помощи семантической модели при проведении анализа имеет свою цену. Дело в том, что операции обхода по дереву быстрее, чем операция получения семантической модели. Поэтому для получения различных символов для узлов, принадлежащих к одному синтаксическому дереву, имеет смысл получать семантическую модель только один раз, а затем уже при необходимости обращаться к одному и тому же экземпляру класса SemanticModel.
В качестве дополнительной информации об использовании семантической модели также рекомендую воспользоваться следующими ресурсами:
Ну что же, думаю, представленной здесь информации хватит для того, чтобы начать полноценное изучение возможностей Roslyn и даже написать какой-нибудь несложный (а может даже и сложный?) статический анализатор. Несомненно, для создания серьёзных инструментов потребуется учесть множество различных нюансов и узнать гораздо больше как о статическом анализе в целом, так и о Roslyn. Данная же статья, я надеюсь, будет отличным помощником в начале вашего пути.
Для более подробного изучения Roslyn API советую изучить документацию на сайте Microsoft. Если же вы хотите улучшить, исправить или изучить исходный код этого API, то добро пожаловать в его GitHub репозиторий. Поверьте, улучшать и исправлять в его API можно еще многое - вот, например, статья "Проверяем исходный код Roslyn", в которой при помощи статического анализатора PVS-Studio проверили его исходники и нашли немало ошибок.
0
0
0
0